Таблицы маршрутизации
Статья про таблицу маршрутизации — тема, обещанная около четырех лет тому назад. На самом деле, давно нужно было про нее написать, но никак не мог решиться и только сейчас делаю попытку.
Манипуляции с таблицей маршрутизации позволяют тонко настраивать работу ваших сетей. Чаще всего это не нужно, но иногда требуется сделать что-то необычное, особенно, когда на комрьютере несколько адаптеров, и тогда приходится браться за таблицы маршрутизации.
Просмотр таблицы маршрутизации
Приведу вывод команды route print на моем стаионарном компьютере:
| Сетевой адрес | Маска сети | Адрес шлюза | Интерфейс | Метрика |
|---|---|---|---|---|
| 0.0.0.0 | 0.0.0.0 | 192.168.1.1 | 192.168.1.100 | 20 |
| 127.0.0.0 | 255.0.0.0 | On-link | 127.0.0.1 | 306 |
| 127.0.0.1 | 255.255.255.255 | On-link | 127.0.0.1 | 306 |
| 127.255.255.255 | 255.255.255.255 | On-link | 127.0.0.1 | 306 |
| 192.168.1.0 | 255.255.255.0 | On-link | 192.168.1.100 | 276 |
| 192.168.1.100 | 255.255.255.255 | On-link | 192.168.1.100 | 276 |
| 192.168.1.255 | 255.255.255.255 | On-link | 192.168.1.100 | 276 |
| 244.0.0.0 | 240.0.0.0 | On-link | 127.0.0.1 | 306 |
| 244.0.0.0 | 240.0.0.0 | On-link | 192.168.1.100 | 276 |
| 255.255.255.255 | 255.255.255.255 | On-link | 127.0.0.1 | 306 |
| 255.255.255.255 | 255.255.255.255 | On-link | 192.168.1.100 | 276 |
Вот так мы можем просмотреть таблицы маршрутизации. Попробуем описать, что все это означает. Каждая строчка опреедляет, куда отправлять какие пакеты. То есть для диапазона, задаваемого значениями в колонках «сетевой адрес» и «маска сети» создается сетевой маршрут. Например, адрес 192.168.0.1 и маска 255.255.255.0 означают, что имеется в виду диапазон 192.168.0.*. Маска всегда имеет вид, когда вначале стоят 255, в конце — нули, а последним ненулевым числом может быть степень двойки минус один. Например, для маски 255.255.127.0 и того же адреса 192.168.0.1 диапазон будет чуть шире, в него войдут и адреса вида 192.168.1.*. Чтобы описать это точнее, надо представить все числа в двоичном виде, но это не является целью статьи.
Итак, если мы определились с диапазоном, мы должны понять, куда же компьютер будет направлять пакеты, если они предназначены адресам из этого диапазона. Начнем с четвертой колонки. Она определяет тот адаптор, на который нужно отправлять пакеты. Например, в данном случае, в ней встречаются 192.168.1.100 — это адрес моей сетевой карты и 127.0.0.1 — так называемая обратная петля. Пакеты «на этот адаптор» компьютер даже не будет пытаться отправлять куда-либо. Если бы у меня была активна другая карта, например, WiFi, то в четвертой колонке встречался бы и е адрес.
Третья колонка определяет «шлюз» — тот маршрутизатор, которому нужно послать эти пакеты. В случае, когда там написано «On-link», имеется в виду, что никаких маршрутизаторов не нужно — адрес и так находится в прямой досягаемости. Последняя колонка — метрика. Она определяет предпочтение для маршрута, когда есть варианты. Строчки с наименьшей метрикой предпочтительны при совпадении диапазонов.

Итак, давайте разберем описанные маршруты. На самом деле, самой важной является в данном случае первая строчка. Она говорит, что для любого адреса (адрес 0.0.0.0 с маской 0.0.0.0 задает полный диапазон) есть маршрут с использованием моей сетевой карты, и направить можно эти пакеты по адресу 192.168.1.1. Последний адрес является моим роутером, что все и объясняет. Любой адрес, который компьютер не сможет найти где-то рядом, он направит на роутер и предоставит тому с ним разбираться.
Поговорим про остальное. Три строчки про 127 — системные, связаны с тем, что эти адреса всегда должны возвращаться на сам компьютер. Адреса диапазона 192.168.1.* являются локальной сетью, 192.168.1.100 — вообще наш адрес, 192.168.1.255 — специальный адрес для широковещательных пакетов в локальной сети. Адреса 244.0.0.0 — тоже специальные зафиксированные адреса для широкого вещания, а две последние строчки определяют сами адаптеры.
Но этот случай достаточно неинтересный. Посмотрим на таблица на моем роутере. Внешний вид будет немного другой, поскольку на нем Линукс, и я вывожу соответствующие таблицы командой route -n.
| Destination | Gateway | Genmask | Flags | Metric | Ref | Use | Iface |
|---|---|---|---|---|---|---|---|
| 10.0.20.43 | 0.0.0.0 | 255.255.255.255 | UH | 0 | 0 | 0 | ppp0 |
| 192.168.1.0 | 0.0.0.0 | 255.255.255.0 | U | 0 | 0 | 0 | br0 |
| 10.22.220.0 | 0.0.0.0 | 255.255.255.0 | U | 0 | 0 | 0 | vlan1 |
| 10.0.0.0 | 10.22.220.1 | 255.224.0.0 | UG | 0 | 0 | 0 | vlan1 |
| 127.0.0.0 | 0.0.0.0 | 255.0.0.0 | U | 0 | 0 | 0 | lo |
| 0.0.0.0 | 10.0.20.43 | 0.0.0.0 | UG | 0 | 0 | 0 | ppp0 |
Заметим сразу, что колонки немного изменились. На всех мы останавливаться не будем, существенной измененной колонкой является последняя — вместо IP-адреса адаптора мы указываем его имя. Здесь lo — это «петля» (никуда не отправлять), br0 — внутренняя сеть, ppp0 — внешняя, vlan0 — установленное vpn-содениение. Итак, разберем строчки. Также в колонке с флагами буква G означает Gateway — шлюз, а H — Host, наш компьютер.
Последняя строчка — шлюз по умолчанию. Любой пакет мы может отправить на адрес 10.0.20.43. Что интересно, это — наш собственный адрес, полученный при установке VPN — соединения! Так всегда получается, когда установлено VPN-соединения, пакет, в первую очередь отправляем своему виртуальному интерфейсу, где он инкапсулируется в другой пакет, который пойдет до реального шлюза. Естественно, в таблицах маршрутизации этого не видно. Также к описанию этого соединения относится и первая строчка.
Настоящий шлюз мы видим в третей строчке — адресы диапазона 10.22.220.* отправляются на vlan1, шлюз, предоставленный провайдером, коммуникатор, с которым мы соединены сетевым кабелем напрямую. Вторая строчка говорит о том, что адреса диапазона 192.168.1.* — это локальная сеть, и пакеты к ним нужно отправлять внутрь, а не вовне. Пятая — обычная информация про «локальные адреса».
Команды таблицы маршрутизации
Я ничего не сказал про предпоследнюю строчку. А она самая интересная, ведь я ее добавил руками. В чем ее смысл? Адреса диапазона 10.1-32.*.* я отправляю на шлюз 10.22.220.1. Пакеты на эти адреса не пойдут в интернет, а останутся в локалке провайдера. Да, пакеты на диапазон 10.22.220. и так идут туда, но этого мало. Так я не получаю полноценного доступа к локальным ресурсам.
В случае Windows такой маршрут в таблицы маршрутизации был бы добавлен командой route -p add 10.0.0.0 mask 255.224.0.0 10.22.220.1. -p означает, что маршрут постоянный, он не должен удаляться после перезагрузки компьютера.
Статья и так уже получилась намного длинней обычных статей этого блога, так что я заканчиваю. Пишите свои вопросы здесь, а если же вы хотите разобрать какие-то спицифические случаи настройки, лучше обращайтесь на нашем форуме.
Команды маршрутизаторов Cisco
Базовая настройка работы маршрутизатора начинается с осуществления действий, выполняемых в режиме настройки роутера. Ниже мы разберем базовые команды для настройки маршрутизатора компании Cisco, а также примеры их применения. Стоит отметить, что роутеры этого бренда имеют много отличительных особенностей, касающихся настройки, однако их популярность требует от сетевого администратора и других специалистов владеть перечнем команд, требующихся наиболее часто.

Команды маршрутизатора для начальной настройки
Чтобы перейти в режим конфигурирования устройства, следует прописать команду configure terminal. При этом нужно задать такие параметры:
- Имя роутера: Router(config)# hostname
- Пароль для входа в режим администрирования: Router(config)# enable secret password
- Пароль для консольного входа:
- Код удаленного доступа (Telnet/SSH):
- Шифрование паролей:
- Предупреждение о несанкционированном подключении – выводится в виде баннера при активации подключения к маршрутизатору: Router(config)# banner motd delimiter message delimiter
- Сохранение:
Базовые команды для настройки маршрутизатора Cisco
Разберем пример, в котором покажем команды для настройки маршрутизатора Cisco. Возьмем роутер, обозначенный R1 и проведем его первичную настройку.
Начнем с команд:
В силу того, что привилегированный режим позволяет управлять настройками роутера на правах администратора, доступ к нему должен быть надежно защищен. Поэтому шифрованию следует уделять особое внимание.
С этой целью можно применить следующую цепочку команд:
Таким образом, мы защитим режимы пользователя и администратора, активируем Telnet/SSH и надежно защитим все пароли шифрованием.
Следующим шагом будет настройка баннера, предупреждающего о юридической ответственности за несанкционированный вход. Баннер имеет название Message of the Day и говорит о том, что лишь авторизованные лица имеют доступ к маршрутизатору. Введем следующие команды:
Команды маршрутизатора Cisco для настройки интерфейса
После первичной настройки следует продолжить конфигурировать роутер. Слеующий этап – настройка интерфейсов, которая выполняется для предоставления доступа к устройству для других пользователей. Маршрутизаторы Cisco оснащаются различными интерфейсами. Например, в модели ISR 4321 два интерфейса:
- GigabitEthernet 0/0/0;
- GigabitEthernet 0/0/1.
Настройка интерфейсов проводится посредством ввода команд:
После активации порта вы увидите уведомление об этом в консольном окне.
Команда Description не является обязательной для активации интерфейса, но ею лучше не пренебрегать. Текстовая длина данной команды равна 240 символам. Если речь идет о ликвидации неполадок в работе производственных сетей, информация о типе сетевого подключения будет полезной. Это может быть, например, если необходимо подключить интерфейс к провайдеру. Здесь необходимо будет ввести внешнее соединение и информацию о контакте.
Включение интерфейса (по аналогии включения питания) задается командой no shutdown. При подключении роутера к другому устройству появится физическая связь. Также команда будет полезна в следующих ситуациях:
- работа в режиме конфигурации;
- диагностика либо настройка новых интерфейсов;
- проблемы, возникающие в отношении интерфейсов (в этом случае можно использовать shut или no shut).
Команды маршрутизатора Cisco для работы с интерфейсами – пример настройки
На роутере R1 активируем подключенные порты. Настройка портов будет проведена следующим образом:
После этого мы получим мэсэнджи о том, что порты подключены.

Проверка настроек портов
Базовые и наиболее целевые команды маршрутизатора для проверок портов имеют следующий вид:
- show ip interface brief;
- show ipv6 interface brief.
Покажем на примере:
Работа с таблицей маршрутизации роутера
Взаимодействие с флэш-памятью и NVRAM
Для роутеров Cisco актуальны три программы:
- ROM монитор для загрузки и отладки;
- Boot ROM;
- система во флэш – установленная самостоятельно.
Параметры записаны в NVRAM. Оперативная память предназначена для сохранности данных, при этом выполнение IOS идет из ROM. При работе с IOS 9.1 важно знать, что пароль здесь задается командой enable password , но никак не enable secret . Просмотр флэша выполняется с помощью команды show flash all . В командной строке выглядит это следующим образом:
Посмотреть записи флэш: show flash err . Копирование информации из флэш на tftp делаем с помощью copy flash tftp . Здесь мы получим мэсэндж о том, что нужно ввести имя сервера, изначальное и результирующее имена файла (файл с правами 666).
Делаем копию настроек параметров на tftp: copy startup-config/running-config tftp
Проверка, записан ли файл на TFTP сервер.
Загрузка настроек с TFTP: copy tftp startup-config/running-config.
При копировании из TFTP во флэш ( copy tftp flash ) важно, чтоб было достаточно свободной памяти. Если выполнение IOS проводится из flash, то проводится новая загрузка. Затем сохраняем конфигурацию copy run start . Для загрузки из ROM IOS в регистре конфигурации задается значение 0-0-0-1.
Показать регистр конфигурации: show version (в основном, это загрузочные настройки роутера: дата последней загрузки, версия IOS, название файла IOS, модель маршрутизатора, объем памяти на flash и оперативной). Команду можно писать сокращенно sh ver .
Проверка контрольной суммы проводится вводом verify flash .
Еще раз выполнить файл конфигурации: configure memory .
Очистка конфигурации: erase startup .
Показать текущую/загрузочную конфигурацию: show run/start .
В NVRAM будут сохранены только несовпадающие со значением по умолчанию параметры. Значения по умолчанию могут отличаться для различных версий. При неполадках удобно использовать сохраненный на TFTP и загруженный с него файл конфигурации, IOS.
Debug также представляет полезные команды для настройки маршрутизатора. Здесь вы сможете посмотреть подробные данные, касающиеся конкретного протокола, службы, приложения. К примеру, debug ip route сообщит о появлении нового или удалении старого маршрута из роутера.
Основы компьютерных сетей. Тема №9. Маршрутизация: статическая и динамическая на примере RIP, OSPF и EIGRP

Всем привет! Спустя продолжительное время возвращаемся к циклу статей. Долгое время мы разбирали мир коммутации и узнали о нем много интересного. Теперь пришло время подняться чуть повыше и взглянуть на сторону маршрутизации. В данной статье поговорим о том, зачем нужна маршрутизация, разберем отличие статической от динамической маршрутизации, виды протоколов и их отличие. Тема очень интересная, поэтому приглашаю всех-всех к прочтению.
P.S. Возможно, со временем список дополнится.
В предыдущих статьях мы разбирали отличия сетевых устройств. А именно, чем коммутатор отличается от маршрутизатора (можно почитать здесь и здесь). То есть коммутатор в классическом понимании — это устройство, которое получает Ethernet-кадры на одном интерфейсе и передает эти кадры на другие интерфейсы, базируясь на заголовках и своей таблицы коммутации. Работает коммутатор канальном уровне.
Маршрутизаторы работают аналогично. Только оперируют IP-пакетами. И работают на сетевом уровне. Хочу заметить, что есть коммутаторы и маршрутизаторы, которые работают и на более высоких уровнях, но мы сейчас говорим о классических устройствах.
Встает вопрос. Почему мы не можем просто коммутировать весь трафик? И зачем требуются IP-адреса и маршрутизация. Ведь что MAC-адреса, что IP-адреса уникальны у каждого сетевого устройства (ПК, телефон, сервер и т.д.). Сейчас отвечу более развернуто. 
На рисунке представлены 2 коммутатора, к которым подключено по 250 пользователей. Соответственно, чтобы обеспечить связность между всеми участниками, коммутаторы должны знать MAC-адреса всех участников сети. То есть таблица каждого коммутатора будет содержать 500 записей. Это уже не мало.
А если представить, что таким образом будет работать Интернет, в котором миллиарды устройств? Следовательно нужно искать выход. Проблема коммутации заключается в том, что она плохо масштабируется. И тяжело соблюдать иерархию.
Теперь посмотрим на эту ситуацию с точки зрения маршрутизации. 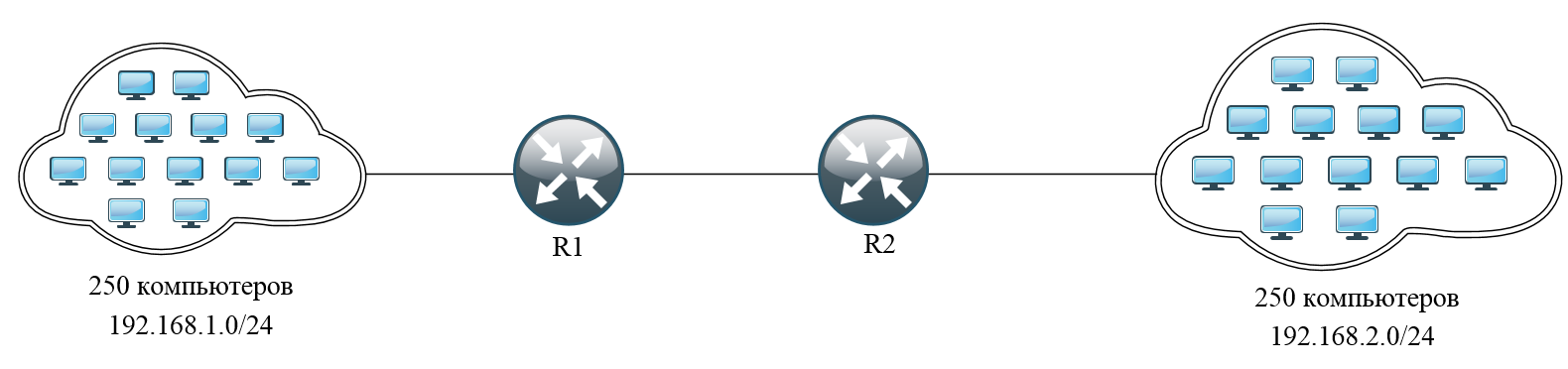
Здесь вводится понятие IP-адресации. Слева сеть 192.168.1.0/24 соединенная с левым маршрутизатором (R1), а справа сеть 192.168.2.0/24 соединенная с правым маршрутизатором (R2), соответственно. R1 знает, что добраться до сети 192.168.2.0 можно через соседа R2 и наоборот R2 знает, что добраться до сети 192.168.1.0 можно через соседа R1. Тем самым 500 записей в таблице коммутации заменяются одной в таблице маршрутизации. Во-первых это удобно, а во-вторых экономит ресурсы. Вдобавок к этому, можно соблюдать иерархичность, при построении.
Теперь поговорим о том, как таблица маршрутизации заполняется. Как только маршрутизатор включается «с коробки», он создает таблицу маршрутизации. Но самостоятельно он туда может записать только информацию о сетях, с которыми он связан напрямую (connected).
Покажу на примере в CPT:

Добавляю маршрутизатор с пустой конфигурацией. Дожидаюсь загрузки и смотрю таблицу маршрутизации:
Сейчас таблица есть, но она пустая из-за того, что не подключен ни один из интерфейсов и не заданы IP-адреса. Соберем схему. 
Зададим IP-адресах на интерфейсах маршрутизатора:
И посмотрим, что изменилось в таблице маршрутизации:
В таблице появились 2 записи. Маршрутизатор автоматически добавил подсети, в которых находятся его интерфейсы. Сверху есть коды, показывающие каким образом маршрут был добавлен.
Настроим обе рабочие станции и проверим связность: 
Теперь детально рассмотрим, что происходит с пакетом, когда он попадает на маршрутизатор. 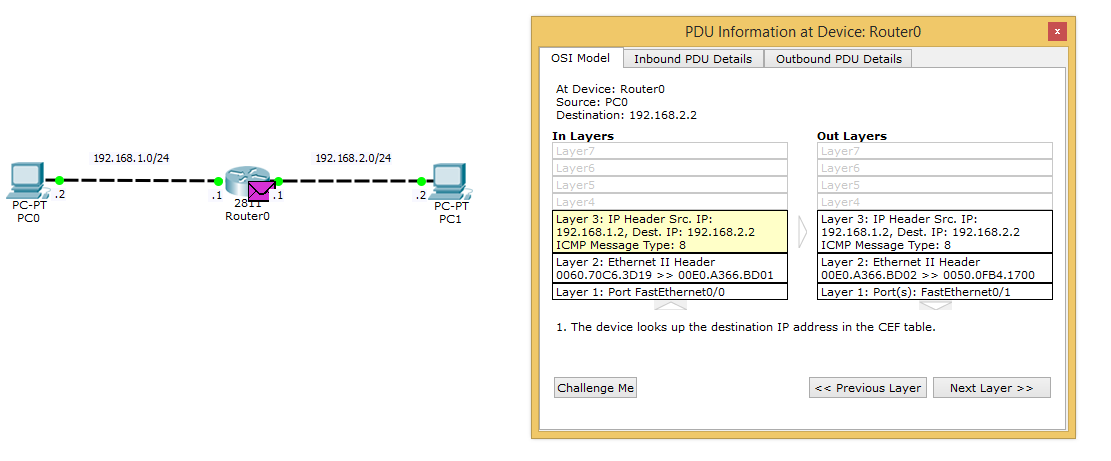
Пакет приходит. Маршрутизатор сразу читает IP-адрес назначения в заголовке и сверяет его со своей таблицей. 
Находит совпадение, изменяет TTL и отправляет на нужный интерфейс. Соответственно, когда ответный пакет придет от PC1, он проделает аналогичную операцию.
То есть отличие в том, что маршрутизатор принимает решение исходя из своей таблицы маршрутизации, а коммутатор из таблицы коммутации. Единственное, что важно запомнить: и у коммутатора, и у маршрутизатора есть ARP-таблица. Несмотря на то, что маршрутизатор работает с 3 уровнем по модели OSI и читает заголовки IP-пакетов, он не может игнорировать работу стека и обязан работать на канальном и физическом уровне. В свою ARP-таблицу он записывает соотношения MAC-адреса к IP-адресу и с какого интерфейса к нему можно добраться. Причем ARP-таблица у каждого сетевого устройства своя. Пишу команду show arp на маршрутизаторе:
Как только PC0 отправил ICMP до PC1 и пакет дошел до маршрутизатора, он увидел в заголовках IP-пакета адрес отправителя (PC0) и его MAC-адрес. Он добавляет его в ARP-таблицу. Следующее, что он видит — это IP-адрес получателя. Он не знает, куда отправлять пакет, так как в его ARP-таблице нет записи. Но видит, что адрес получателя из той же сети, что и один из его интерфейсов. Тогда он запускает ARP с этого интерфейса, чтобы получить MAC-адрес запрашиваемого хоста. Как только приходит ответ, он заносит информацию в ARP-таблицу.
Это базовый пример того, как работает маршрутизация. Прикладываю ссылку на скачивание.
Усложним немного схему. 
На ней представлены 2 рабочие станции и 3 маршрутизатора. Не буду заострять внимание на том, как прописать IP-адрес на интерфейс, а лишь покажу итоговую конфигурацию:

Все устройства сконфигурированы. Теперь проверим связность между PC0 и PC1: 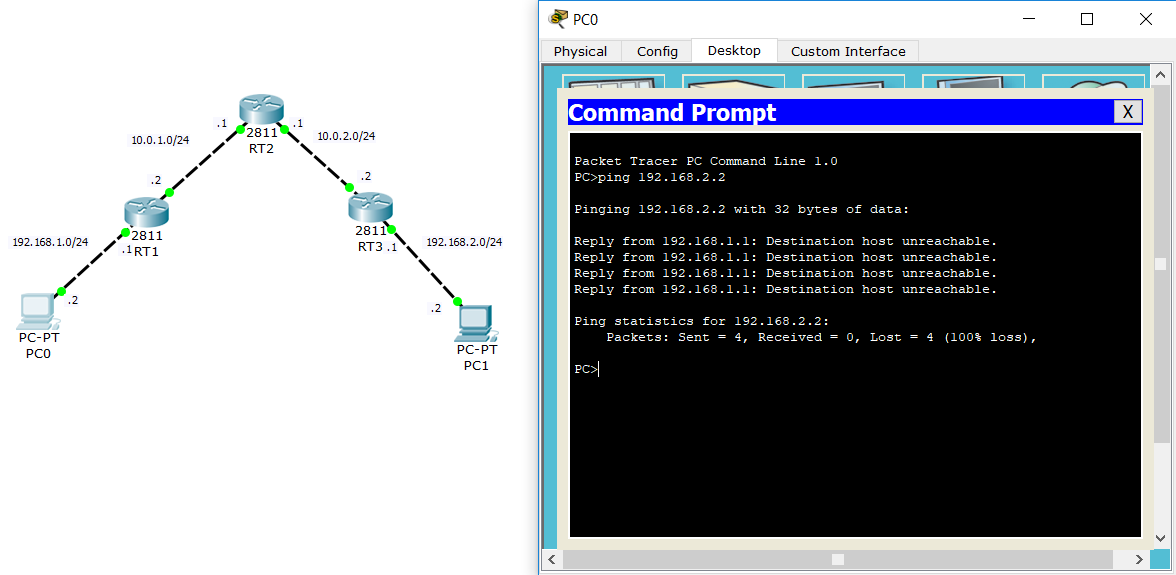
В консоли PC0 вылезает сообщение о недоступности узла. Но ведь все адреса прописаны и добраться можно. В чем же проблема? Переходим в режим симуляции и копаем глубже:
/>
PC0 формирует ICMP-сообщение. Смотрит на IP-адрес назначения и понимает, что получатель находится в другой сети. Соответственно передать надо своему основному шлюзу, а дальше пускай сам разбирается. 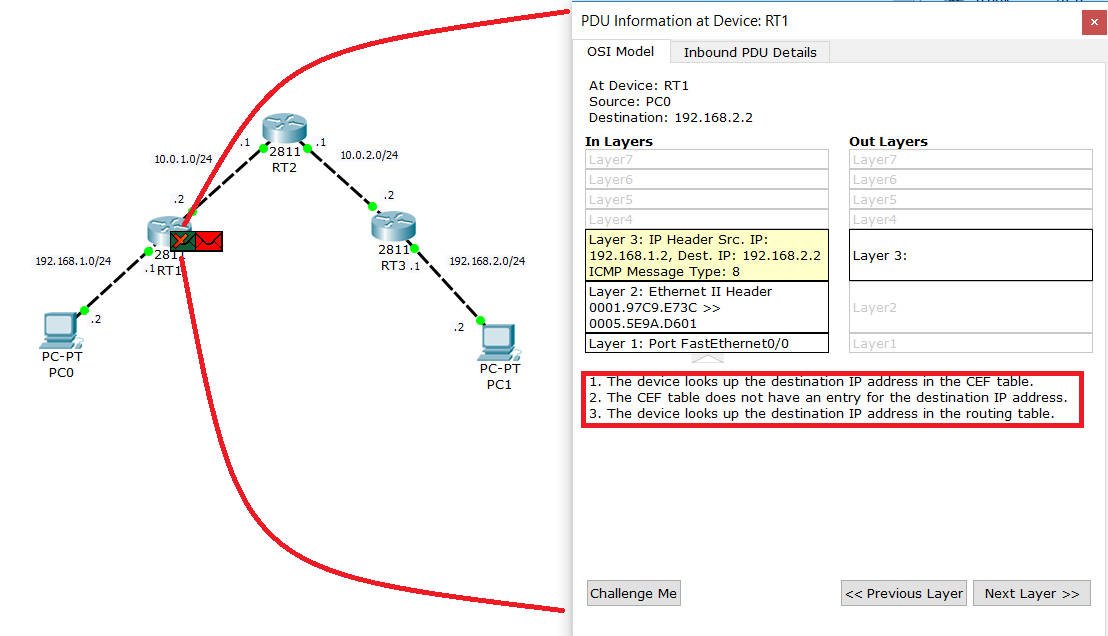
Пакет доходит до RT1. Смотрит в Destination IP и сравнивает со своей таблицей маршрутизации.
И вуаля. Совпадений нет. А значит RT1 понятия не имеет, что делать с этим пакетом. 
Но так просто отбросить его не может, так как надо уведомить того, кто это послал. Он формирует ответный ICMP с сообщением «Host Unreachable». 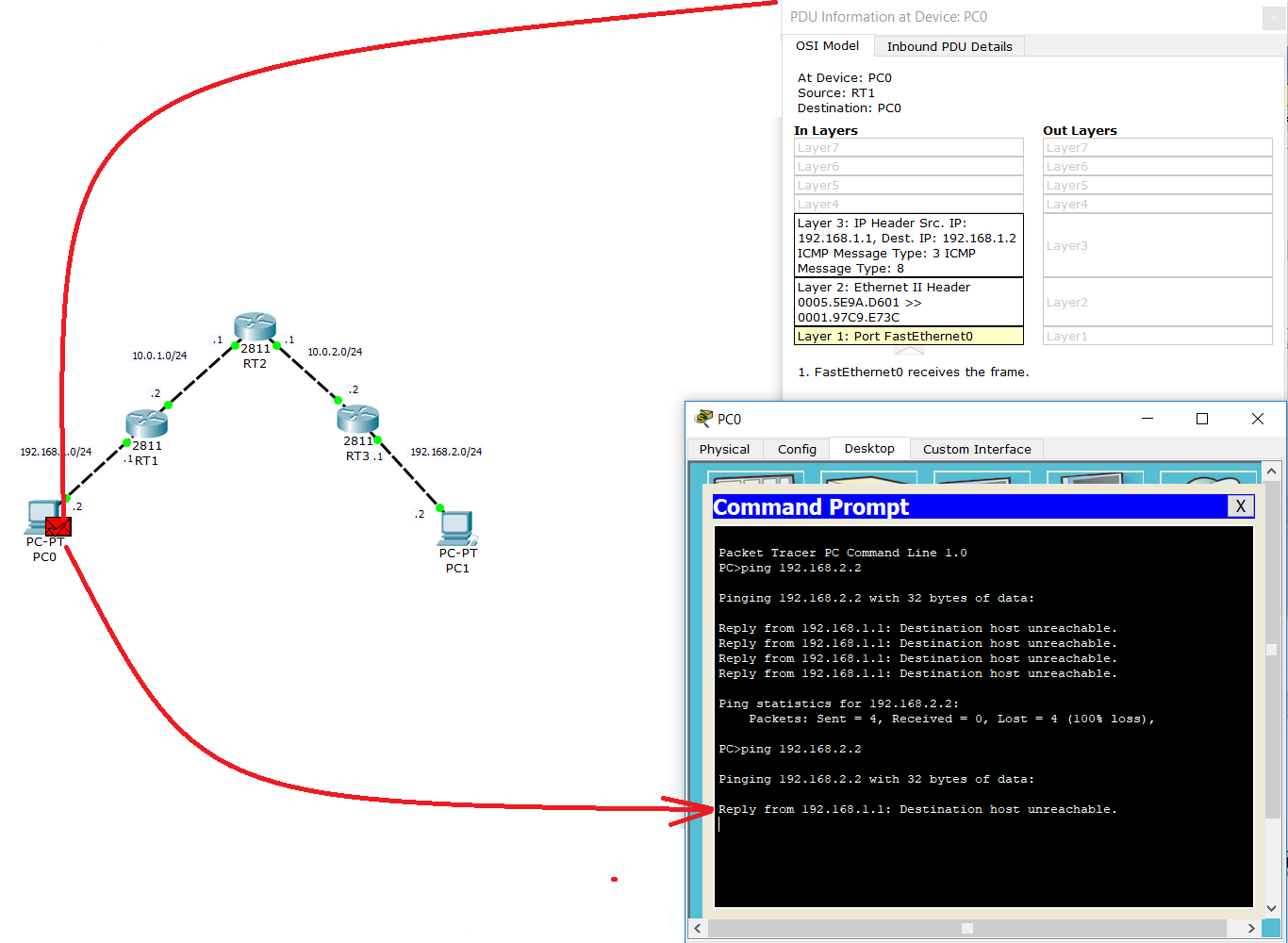
Как только пакет доходит до PC0, в консоли высвечивается сообщение «Reply from 192.168.1.1: Destination host unreachable.». То есть RT1 (192.168.1.1) говорит о том, что запрашиваемый хост недоступен.
Выход из ситуации следующий: нужно «сказать» сетевому устройству, как добраться до конкретной подсети. Причем это можно сделать вручную или настроить все сетевые устройства так, чтобы они переговаривались между собой. Вот на этом этапе маршрутизация делится на 2 категории:
- Статическая маршрутизация
- Динамическая маршрутизация
Начнем со статической. В качестве примера возьмем схему выше и добьемся связности между PC0 и PC1. Так как первые проблемы с маршрутизацией начались у RT1, то перейдем к его настройке:
Маршрут прописывается командой ip route. Синтаксис прост: «подсеть» «маска» «адрес следующего устройства».
После можно набрать команду show ip route и посмотреть таблицу маршрутизации:
Появился статический маршрут (о чем свидетельствует код S слева). Здесь много различных параметров и о них я расскажу чуть позже. Сейчас задача прописать маршруты на всех устройствах. Перехожу к RT2:
Обратите внимание, что маршрут прописан не только в 192.168.2.0/24, но и 192.168.1.0/24. Без обратного маршрута полноценной связности не будет.
Остался RT3:
Маршруты на всех устройствах прописаны, а значит PC0 сможет достучаться до PC1 и наоборот PC1 до PC0. Проверим: 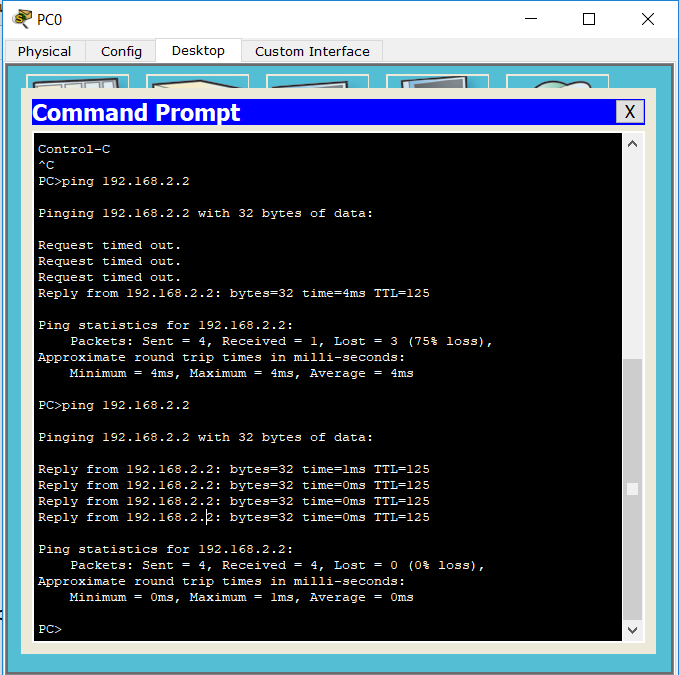
Обратите внимание на то, что первые 3 запроса потерялись по тайм-ауту (не Unreachable). Это так CPT эмулирует работу ARP. По сути эти 3 потерянных пакета — это следствие того, что каждый маршрутизатор по пути запускал ARP-запрос до своего соседа. В итоге после всех работ PC0 успешно пингует PC1. Проверим обратную связь: 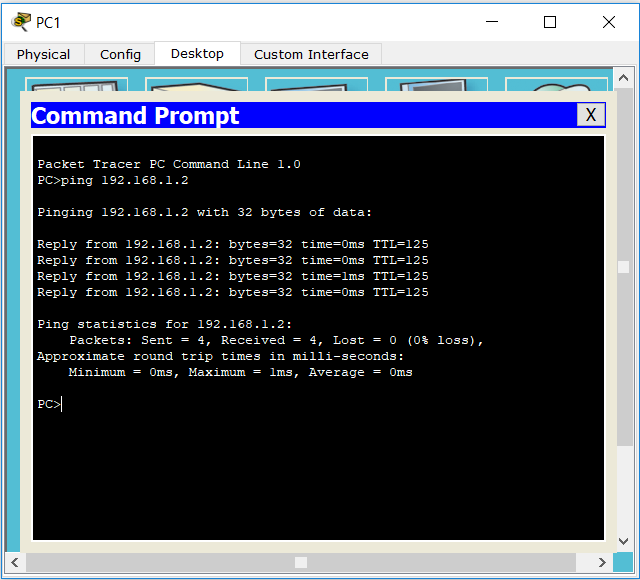
И с этой стороны все прекрасно.
Ссылка на скачивание.
Теперь на примере таблицы R3 объясню, что она из себя представляет:
Коды (они же легенды) показывают, каким методом данный маршрут попал в таблицу. Их тут много и заострять внимание на все нет смысла (так как ныне не используются). Остановимся на двух — C(connected) и S(static).
Как только мы прописываем IP-адрес и активируем интерфейс, подсеть, к которой он принадлежит, автоматически попадает в таблицу маршрутизации. Поэтому справа от этой строки подписано directly connected и интерфейс, привязанный к этой подсети. Тоже самое с подсетью 192.168.2.0/24. А вот со статически заданным адресом чуть по другому. Подсеть 192.168.1.0/24 не напрямую подсоединена к текущему маршрутизатору, а доступна через 10.0.2.1. А вот этот next-hop уже принадлежит к 10.0.2.0/24 (которая напрямую доступна). Таким образом можно добраться до удаленной подсети, через знакомую сеть. Это может показаться немного запутанным, но именно так работает логика маршрутизатора. Тут еще можно заметить, что в строчке со статическим маршрутом присутствует запись [1/0]. Я чуть позже объясню что это, когда будет разбираться динамическая маршрутизация. Просто на фоне ее эти цифры сразу обретут смысл. А сейчас важно просто запомнить, что первое число — это административная дистанция, а второе — метрика.
Теперь перейдем к разделу динамической маршрутизации. Начну сразу с картинки:
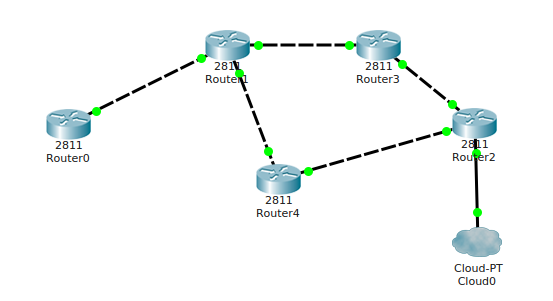
И сразу вопрос: В чем сложность этой схемы? На самом деле ни в чем, до того момента, пока не придется это все настраивать. Сейчас мы умеем настраивать статическую маршрутизацию. И за n-ое количество времени поднимем сеть и она будет работать. А теперь несколько но:
- На одном из маршрутизаторов появилась новая подсеть. Это значит, что нужно на всех маршрутизаторах вручную прописать маршрут до нее.
- Допустим мы из Router0 ходили до Cloud0 по цепочке 0 -> 1 -> 3 -> 2 -> Cloud0. Теперь внезапно сгорел/умер/украли Router3. Соответственно не было запасного пути и доступ до Cloud0 закрыт. Сеть стоит и компания не может работать. Тут придется подрываться и переписать цепочку по 0 -> 1 -> 4 -> 2 -> Cloud0. То есть нет никакого резерва. Если сеть падает, то без админа ничего не решить. Сеть не может сама перестроиться.
- Ну и еще один аргумент, почему строить сеть исключительно на статических маршрутах — зло и не практично. Это, конечно, масштабируемость. Практически любая компания рано или поздно растет, расширяется и сетевых узлов становится все больше. А значит, в конечном итоге, сеть со статическими маршрутами начнет превращаться в ад для сетевого инженера.
Вот на помощь как раз приходит динамическая маршрутизация. Она оперирует двумя очень созвучными понятиями, но совершенно разными по смыслу:
- Routing protocols (протоколы маршрутизации) — это как раз те протоколы, о которых чуть ниже поговорим. При помощи этих протоколов, роутеры обмениваются маршрутной информацией и строят топологию.
- Routed protocols (маршрутизируемые протоколы) — это как раз те протоколы, которые мы маршрутизируем. В данном случае — это IPv4, IPv6.
Протоколы динамической маршрутизации делятся на 2 категории:
- IGP (interior gateway protocols) — внутренние протоколы маршрутизации (RIP, OSPF, EIGRP). Гости этого выпуска.
- EGP (external gateway protocols) — внешние протоколы маршрутизации (на сегодня BGP).
Отличий в них много, но самые главные — IGP запускается внутри одной автономной системы (считайте компании), а EGP запускается между автономными системами (то есть это маршрутизация в Интернете. При помощи него автономные системы связываются между собой). Сейчас представитель EGP остался один — это BGP. Я не буду долго на нем останавливаться, так как он выходит за рамки CCNA. Да и по нему лучше делать отдельную статью, чтобы не смешивать и так довольно емкий материал.
Теперь про IGP. Это прозвучит смешно, но и они делятся на несколько категорий:
- Distance-Vector (дистанционно-векторные)
- Hybrid or Advanced Distance Vector (гибридные или продвинутые дистанционно-векторные)
- Link-State (протокол состояния канала)
Начну с дистанционно-векторного. Он, на мой взгляд, самый простой для понимания.
Название ему такое дали не с проста. Дистанция показывает расстояние до точки назначения. Дальностью оперирует такой показатель, как метрика (о чем я упоминал выше). Вектор показывает направление до точки назначения. Это может быть выходной интерфейс, IP-адрес соседа.
Мне этот протокол напоминает дорожный указатель. То есть по какому направлению идти и какое расстояние до точки назначения.
Теперь покажу на практике, как он работает и по ходу детально разберем.
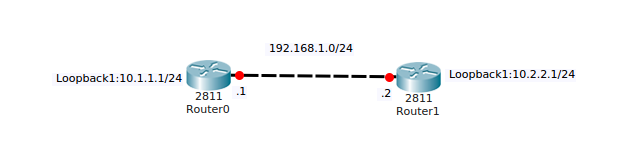
Чтобы не загромождать статью однообразными настройками, я заранее сконфигурировал устройства. А именно прописал IP-адреса и включил интерфейсы. Оставлю под спойлерами настройки:
Router0#show running-config
Building configuration.
Current configuration : 622 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router0
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.1.1.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.1.1 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
no ip address
duplex auto
speed auto
shutdown
!
interface Vlan1
no ip address
shutdown
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Router1#show running-config
Building configuration.
Current configuration : 622 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router1
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.2.2.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.1.2 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
no ip address
duplex auto
speed auto
shutdown
!
interface Vlan1
no ip address
shutdown
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Единственное, что может показаться новым — это Loopback интерфейсы. Он практически не отличается от других интерфейсов, за исключением того, что не представлен физически и к нему ничего нельзя воткнуть. Он программно создан внутри самого устройства. Такой интерфейс есть и на многих ОС, как Windows и Linux-подобных. На примере он используется для того, чтобы не рисовать множество маршрутизаторов со своими подсетями.
Сейчас таблицы маршрутизации выглядят следующим образом:
То есть у каждого в таблице маршрут общий с соседом (192.168.1.0/24) и недоступный другому соседу (10.1.1.0 и 10.2.2.0 соответственно).
Теперь для связности 2 маршрутизатора должны обменяться своими маршрутными информациями. И вот тут поможет протокол RIP.
Переключаю PT в режим симуляции и перехожу к настройкам:
Router0:
Сразу оговорюсь, что протокол RIP (также как EIGRP и OSPF) не анонсирует подсети таким образом. Он включает протокол на данном интерфейсе. То есть нельзя анонсировать то, что устройство не знает. И замечу, что включена вторая версия протокола и отключено автосуммирование. Изначально RIP был придуман для сетей с классовой адресацией. Поэтому суммирование он выполняет по тем же правилам, что не корректно в применении к бесклассовой. После перехода на бесклассовую адресацию, нужно было изменить работу протокола RIP. И вот во второй версии помимо подсети, передается еще и маска. 
На схеме сразу же оба маршрутизатора что-то сгенерировали:
Первый пакет: 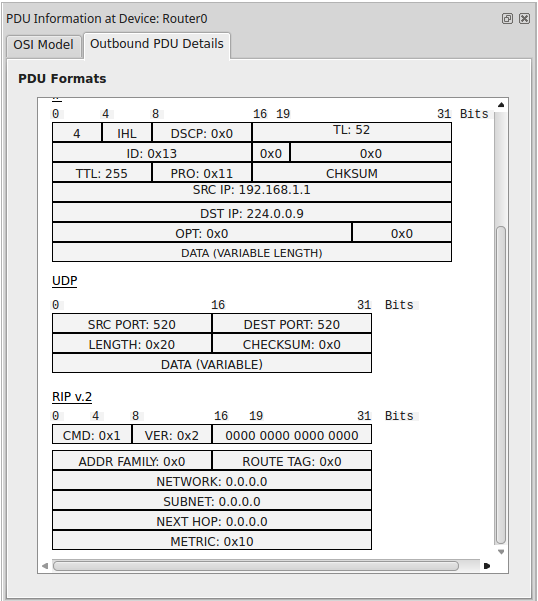
Это первый пакет, который генерирует роутер, при включении RIP. Тут важный аспект, что ничего не анонсируется и метрика = 16. (0x10 в шестнадцатиричном значение = 16 в десятичном).
Второй пакет: 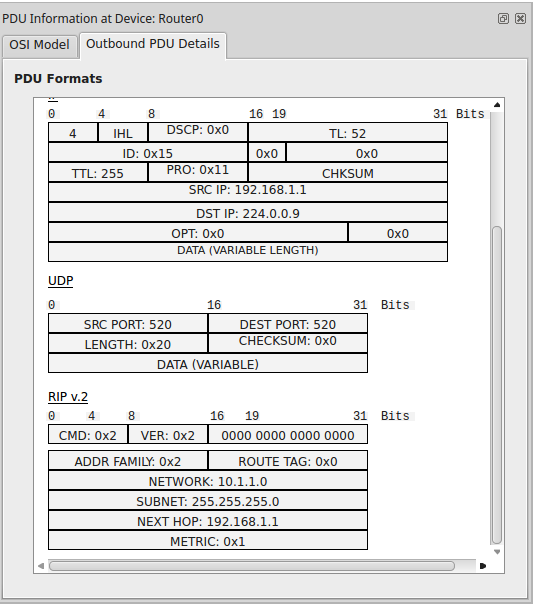
А вот этот пакет уже несет полезную информацию.
1) ADDR FAMILY: 0x2 — означает IP протокол. В большинстве случаев это поле не меняется.
2) NETWORK: 10.1.1.0 — подсеть, которая анонсируется.
3) SUBNET: 255.255.255.0 — маска
4) NEXT HOP: 192.168.1.1 — следующий узел для достижимости анонсированной подсети.
5) METRIC: 0x1 — стоимость пути (в данном случае 1).
С обратной стороны придет точно такой же анонс (только будет соответствующая подсеть, nexthop).
В итоге после получения анонсов, таблицы у обоих роутеров будут выглядеть следующим образом:
В таблице появилась пометка с кодом R. То есть получен по протоколу RIP.
Если пустить пинги:
Анонсируемые подсети достижимы. Еще важный аспект, при работе с протоколами маршрутизации — это просмотр сформированной базы. Таблица маршрутизации — это конечный итог, куда заносится маршрут. Посмотреть базу можно командой show ip rip database:
Эта команда полезна, когда маршруты никак не заносятся в таблицу, при этом вроде как RIP включен и настроено все верно. Если маршрута нет в базе, значит он никак не попадет в таблицу и тут надо копать глубже. У циски, к счастью, есть хороший инструмент для дебага, который позволяет практически моментально понять, что происходит. В CPT он урезан и многое не показать, но на реальных железках, он прекрасен.
Например:
Посмотрим, что происходит в RIP:
Сейчас все хорошо. Видно, что приходят/уходят апдейты и записи обновляются. Из за того, что дебажный инструмент обширен, лучше явно указывать что нужно ловить (как представлено выше). Иначе можно достаточно хорошо пригрузить устройство. Важно помнить про команду undebug all. Она отключает весь дебаг на устройстве.
Ссылка на скачивание лабы. Можете добавить еще один маршрутизатор к существующей схеме и связать их через RIP.
Теперь усложним схему и посмотрим в чем преимущество динамической маршрутизации. 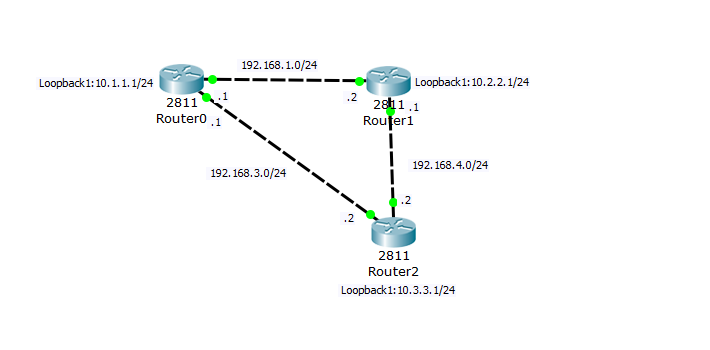
Добавился Router2, который соединен с ранее созданными маршрутизаторами и анонсирует подсеть 10.3.3.0/24.
Настраиваются аналогично предыдущему примеру. Поэтому покажу только конфигурации:
Router0#show running-config
Building configuration…
Current configuration: 736 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router0
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.1.1.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.1.1 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
ip address 192.168.3.1 255.255.255.0
duplex auto
speed auto
!
interface Vlan1
no ip address
shutdown
!
router rip
version 2
network 10.0.0.0
network 192.168.1.0
network 192.168.3.0
no auto-summary
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Router1#show running-config
Building configuration…
Current configuration: 736 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router1
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.2.2.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.1.2 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
ip address 192.168.4.1 255.255.255.0
duplex auto
speed auto
!
interface Vlan1
no ip address
shutdown
!
router rip
version 2
network 10.0.0.0
network 192.168.1.0
network 192.168.4.0
no auto-summary
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Router2#show running-config
Building configuration…
Current configuration: 736 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router2
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.3.3.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.3.2 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
ip address 192.168.4.2 255.255.255.0
duplex auto
speed auto
!
interface Vlan1
no ip address
shutdown
!
router rip
version 2
network 10.0.0.0
network 192.168.3.0
network 192.168.4.0
no auto-summary
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Итого на Router0 мы имеем следующую таблицу маршрутизации:
Из новых маршрутов — это 10.3.3.0/24, который доступен через 192.168.3.2 (т.е. Router2). И второй маршрут — это 192.168.4.0/24, который доступен через 192.168.1.2 (т.е. Router1) и 192.168.3.2 (т.е. Router2).
Вот в тех случаях, когда маршруты от разных устройств до одной подсети приходят с одинаковой метрикой, оба заносятся в таблицу. Такой случай называют балансировкой или ECMP (Equal-cost multi-path routing).
Если пройтись по нему через traceroute:
То есть меняется next-hop по очереди. Сама тема балансировки заслуживает отдельного внимания, т.к. у балансировки есть несколько стратегий по выбору оптимального пути. Случай, когда балансировка работает по очереди, как в нашем случае — называют Round-Robin.
Посмотрим базу RIP на Router0:
То есть нет никакого запасного маршрута, на случай выхода из строя 192.168.3.2. Теперь переключаю в режим симуляции и смотрю, что произойдет, если отключить на Router0 интерфейс fa0/1:
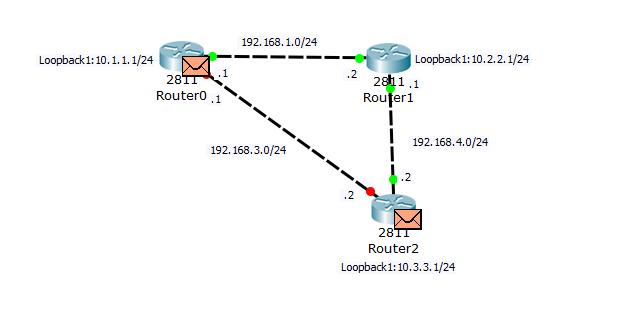
Видим, что отключился линк на Router0 и Router2. И сразу оба устройства генерируют сообщения:
Router0: 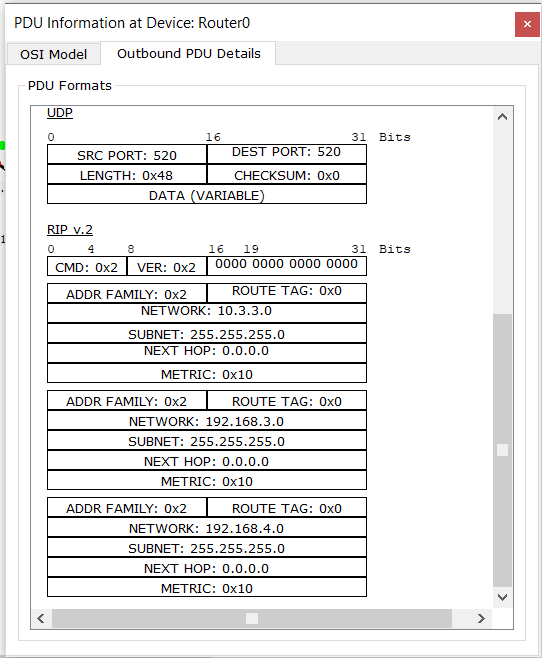
Router1: 
Сразу сообщают, что данные маршруты теперь недостижимы. Делают они это, при помощи метрики, которая становится равной 16. Исторически так сложилось, что протокол RIP был рассчитан на работу с 15 транзитными участками. В то время никто не подразумевал, что сеть может быть настолько большой:-). Называется этот механизм Poison Reverse.
Таким образом сосед, получивший такой апдейт должен удалить этот маршрут из таблицы.
Вот, что происходит на Router1: 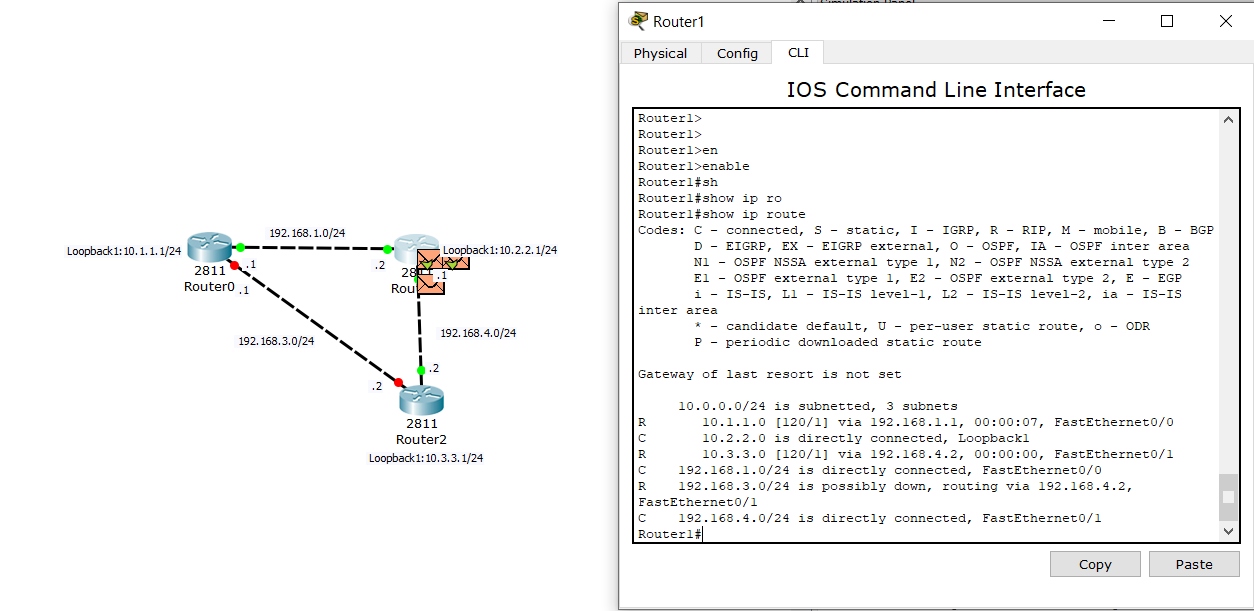
И самое интересное, что после этого Router1 отправит Router0 следующее: 
То есть я больше не знаю о 192.168.3.0/24.
На данный момент таблица на Router0 выглядит следующим образом:
То есть знает о своих подсетях и тех, что анонсировал Router1.
Двигаемся дальше: 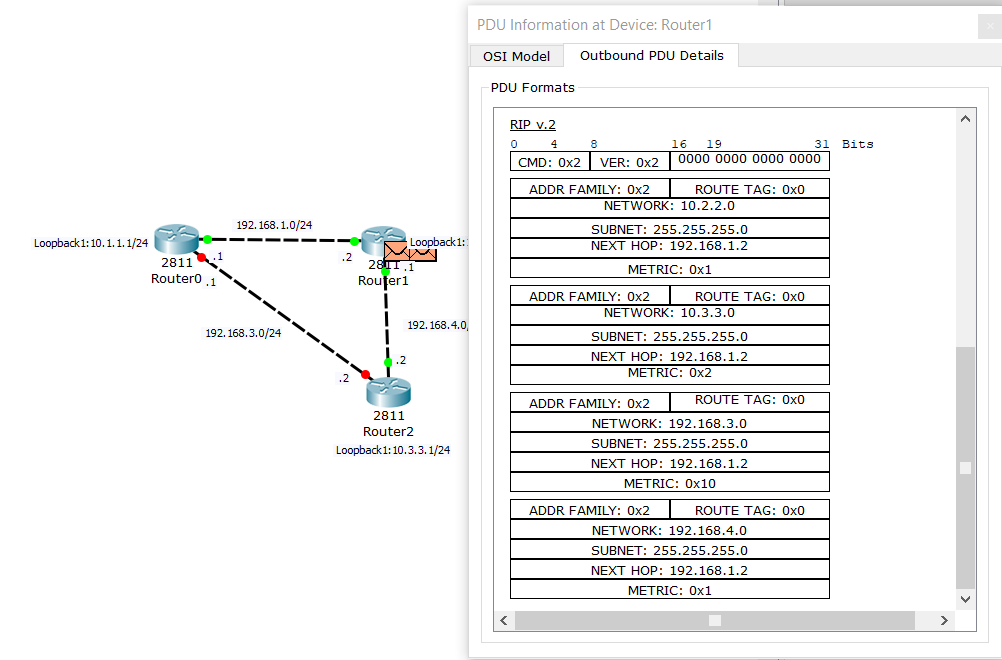
Видим, что Router1 генерирует пакет с кучей подсетей и отправляет соседям. В том числе там подсеть 10.4.4.0.
И в таблице Router0 теперь:
Замечу, что в таблице она записана с метрикой 2. Потому что данный маршрут направлен не напрямую от соседа, породившего его, а через транзитный маршрутизатор, который добавил 1.
Проверим доступность:
Пинги проходят, а через traceroute видим, что пакет сначала попадает на Router1, а дальше маршрутизируется на Router2.
То есть видно очевидное преимущество динамического протокола маршрутизации над статическими. При падении линка и наличии резервного пути, топология сама перестроилась. На сегодняшний день мало кто использует данный протокол. И на это есть множество причин. Одна из них — это количество транзитных маршрутов. Вдобавок ко всему — это время сходимости. По умолчанию все маршрутизаторы отправляют друг другу апдейты каждые 30 секунд. Если обновление не приходит в течении 180 секунд, маршрут помечается, как Invalid. А как время простоя доходит до 240 секунд, он удаляется. Конечно таймеры можно подкрутить. Но проблема еще в том, что в большой сети, при наличии проблемы где-нибудь по середине, апдейт с одного конца до другого может просто-напросто не дойти. Хотя он доступен. Есть еще одна проблема. RIP хранит только лучший маршрут. Поэтому когда отключился линк, маршрут пропал и резервного пути не было. А значит, пока никто из соседей не проанонсирует подсеть, она будет недоступной. Это очень ощутимо для сетей, в которых простой стоит дорого. В связи с этим были придуманы протоколы, у которых время сходимости выше и есть резервные пути. О них и поговорим. Хочу также отметить, что RIP — протокол не плохой (уж явно лучше, чем использование только статических маршрутов в растущей сети). Поэтому изучение лучше начать с него. Таким образом концепция динамической маршрутизации уляжется лучше. Да что тут говорить, если Cisco сначала убрала RIP из своих экзаменов, а теперь снова включила.
Теперь перейдем к EIGRP. Если RIP уже давно является открытым протоколом, то EIGRP был проприетарным и работал только на устройствах Cisco. Но в 2016 году Cisco решила все же открыть его, оставив авторство за собой. Ссылка на RFC7868.
Cisco называет его гибридным (имея в виду, что он взял что-то от Distance-Vector, а что-то от Link-State). В отличии от RIP он работает более «умно». В том плане, что у него есть резервные маршруты и он «хранит некую топологию сети» (хотя это верно очень частично).
Оперирует он 3-мя таблицами:
1) EIGRP Neighbor Table: Здесь представлены все напрямую соединенные соседи (то есть кто Next-Hop и с какого интерфейса к нему добраться).
2) EIGRP Topology Table: Здесь представлены все изученные маршруты от соседей (с точкой назначения и метрикой)
3) Global Routing Table: Общая для всех таблица и сюда попадают лучшие маршруты из предыдущей таблицы.
Соберем топологию и запустим на ней EIGRP. Попутно буду рассказывать, что происходит, чтобы совместить минимум теории с максимумом практики.
Топологию возьмем ту же, что и с RIP. На ней настроены все IP-адреса, подняты интерфейсы, но не запущен протокол маршрутизации.
Router0#show running-config
Building configuration…
Current configuration: 635 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router0
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.1.1.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.1.1 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
ip address 192.168.3.1 255.255.255.0
duplex auto
speed auto
!
interface Vlan1
no ip address
shutdown
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Router1#show running-config
Building configuration…
Current configuration: 635 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router1
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.2.2.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.1.2 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
ip address 192.168.4.1 255.255.255.0
duplex auto
speed auto
!
interface Vlan1
no ip address
shutdown
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Router2#show running-config
Building configuration…
Current configuration: 635 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router2
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.3.3.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.3.2 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
ip address 192.168.4.2 255.255.255.0
duplex auto
speed auto
!
interface Vlan1
no ip address
shutdown
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Сейчас в маршрутных таблицах роутеров только Connected подсети.
Переходим в настройки EIGRP.
Как описал выше, при включении EIGRP, ему присваивается номер AS. И он должен совпадать на всех соседях. В настройках анонса сети теперь добавляется wildcard маска. Если не вдаваться в подробности — это обратная запись маски (т.е. 0.0.0.255 — это 255.255.255.0). И отключение автосуммирования (наследие классовых сетей).
В итоге видим следующую картину: 
Посмотрим, что сгенерировал Router0: 
Видим кучу полей и попробуем разобраться, что в них. Мы помним, что RIP был не самым надежным вариантом. Он не понимал какой номер пакета, не было механизма отслеживания, подтверждения и прочего. Да и плюс нижестоящий протокол был UDP, который тоже не имеет механизма надежности. EIGRP вообще работает сразу поверх IP (не используя механизмы транспортного уровня). Поэтому все механизмы по отслеживанию ложатся на его поля.
Из важного: появились флаги, SEQ. NUM (номер отправляемого пакета), ACK.NUM (подтверждение на принятый пакет), номер автономной системы (заданный при создании), и параметры K. Вот тут остановлюсь. В RIP метрика считалась тривиально. Пакет пришел, добавляю единицу и передаю дальше. В EIGRP метрика считается исходя из K значений:
1) K1 — bandwidth (или пропускная способность)
2) K2 — load (загруженность)
3) K3 — delay (задержка)
4) K4 — reliability (надежность)
5) K5 — MTU (Maximum Transmission Unit).
Но как правило, при расчете используются только K1 и K3.
Формула таким образом выглядит:
.
Запоминать ее наизусть не надо. Просто важно понимать, как происходит расчет метрики.
Вот, что происходит, когда пакет доходит до Router0:
К сожалению CPT наглухо тормозит от количества пакетов, поэтому покажу, что происходит в непосредственно таблицах Router0 (в остальных будет аналогично. Поэтому покажу на одном). А после подробно покажу процесс установления соседства в режиме дебага между двумя маршрутизаторами:
1) Neighbor Table:
Из важного. Здесь показан сосед, интерфейс (за которым он находится), hold (таймер, по истечении которого, произойдет разрыв соседства. При получении пакета от соседа, он повышается), uptime (как долго живет соседство), SRTT (время между отправкой и подтверждением), RTO (интервал между отправкой) и номер пакета.
2) Router0#show ip eigrp topology
Тут все просто. Если все хорошо с полученным маршрутом, то он становится Passive. О других полях и их значениях расскажу чуть позже. Сейчас достаточно того, что в данной таблице все хорошо. Из нового — вводится понятие Successor. Successor-ом выбирается тот, у кого наименьшая стоимость до конкретной подсети. Сейчас на каждый маршрут по одному Successor-у и только на маршрут 192.168.4.0 их два. Причем они оба выбраны Successor-ами из за одинаковой метрики (следовательно будет работать балансировка). Теперь обращу внимание на странные числа у каждого Successor-а.
EIGRP при расчете метрики оперирует 2-мя понятиями: Advertised Distance и Feasible Distance. Оба рассчитываются той страшной формулой:
1) Advertised Distance — это анонс стоимости от соседа. То есть сколько стоит от него (соседа) и до точки назначения.
2) Feasible Distance — это стоимость от самого роутера до точки назначения. То есть — это Adverticed Distance + стоимость линка до соседа.
Возьмем для примера запись от маршрута 10.2.2.0:
Число 128256 — это Advertised Distance, а 156160 — это Feasible Distance.
Соответственно, чем меньше Feasible Distance, тем выгоднее маршрут и такой сосед объявляется Successor-ом. После записи о количестве successors, всегда пишется какая FD была выбрана.
На текущий момент он работает приблизительно также, как и RIP. Только почему то метрика стала сложнее и добавилось больше таблиц. Но вот у EIGRP есть несколько фокусов в кармане. Один из них — это Feasible Successor (не путать с Feasible Distance). Это как раз тот самый резервный путь на случай отказа Successor. Сейчас у нас нет резервного пути (например до маршрута 10.2.2.0). Если падает 192.168.1.2, этот маршрут теряется до момента, пока о нем не расскажет другой сосед. Но мы прекрасно знаем, что о нем может рассказать Router2 (пусть и с худшей метрикой). Но EIGRP все же основан на неких правилах, что не позволяет ему так сделать. А правило заключается в следующем:
.
То есть стоимость анонсируемая от Feasible Successor (потенциально backup-роутера) должна быть меньше, чем Feasible Distance Successor (то есть полная стоимость через основного).
Звучит тяжело, но если проще. Взять тот же маршрут 10.2.2.0. Через него FD = 156160. Значит AD от Feasible Successor должна принять любое число меньшее 156160. Причем не важно сколько стоит линк от текущего роутера до соседа (хоть 1000000). Главное, чтобы backup-сосед анонсировал с меньшей метрикой, чем successor. Это правило используется для предотвращения петель.
Чтобы понять, как это работает, внесем изменения в топологию.
Сейчас на Router0 таблица топологии выглядит следующим образом:
Маршрут до 10.2.2.0/24 доступен через 192.168.1.2, что верно, так как Router1 его породил и так добраться быстрее всего. Поэтому Router2 не сможет проанонсировать лучше, так как его AD будет всегда выше.
Теперь переведем скорость интерфейсов между Router0 и Router1 на 10Мбит/с. Таким образом ухудшим канал, и внесем изменения в пересчет топологии.
Таким образом на Router0:
Видим, что до 10.2.2.0 теперь 2 пути, но Successor выбирается тот, у кого FD выгоднее. А выгоднее, через 192.168.3.2 (то есть Router2), так как у него скорость интерфейсов 100Мбит/с, хоть и преодолеть придется 2 хопа. А теперь обратим внимание, почему попали 2 записи в этот маршрут.
А потому что AD у 192.168.1.2 лучше, чем FD у 192.168.3.2 (128256<158720).
И в таблицу маршрутизации попадет маршрут через выбранного Successor-а, то есть 192.168.3.2:
Для теста отказоустойчивости, запустим пинг на 1000 пакетов и в этот момент поотключаем основной канал через 192.168.3.2:
Как видно, линк падал, но пакеты не прекращали ходить. Тем самым резервирование отрабатывало. Это одна из фишек EIGRP.
Вторая фишка — это неэквивалентная балансировка. Как помним, обычная балансировка работает, если 2 маршрута приходят с абсолютно одинаковой метрикой. EIGRP же умеет балансировать маршрутами с разной метрикой.
Проверим на существующей топологии. На Router0 имеем следующее:
Topology Table:
Route Table:
То есть сейчас мы имеем два маршрута до 10.2.2.0/24, но используем всего один (наилучший, исходя из метрики). Чтобы правило заработало, нужно изменить множитель метрики (или с англ. variance).
Правило его работы следующее:
. Иначе говоря стоимость полного пути запасного маршрута должна быть «искусственно» меньше основного.
Сейчас ситуация следующая:
Значит нужно метрику 158720 умножить настолько, чтобы она стала больше 179200. Умножать можно только на целое число, поэтому выберем 2.
Оба маршрута попали в таблицу маршрутизации. Теперь проверим, что балансировка действительно работает:
Балансировка работает.
Ссылка на собранную EIGRP топологию.
И ссылка на топологию с измененной скоростью и балансировкой. Если EIGRP не совсем уложился в голове (а это нормальное явление, если изучаете его впервые), то лучше самому собрать топологию, ориентируясь на статью.
Теперь рассмотрим, как происходит соседство в режиме дебага. Если вы дошли сюда с самой первой статьи и принцип хождения пакетов понятен, то лучше уже учиться со включенным дебагом. В рабочих условиях не будет такого инструмента, чтобы красиво смотреть на пакеты и придется пользоваться другими методами. К счастью, если это циска — то решение с дебагом отличное. Единственное — важно включать не все режимы, а только необходимые. Можно, конечно, отзеркалировать порт и просниффать через wireshark. Но не всегда есть физический доступ к железке.
Итак, топология: 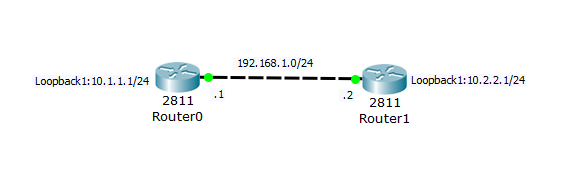
Я просто удалил Router2, отключил интерфейсы, которые были соединены с ним и удалил анонсы маршрутов из EIGRP.
Теперь включаю дебаг на Router0 и наблюдаю:
И еще, что стоит упомянуть — это типы EIGRP сообщений. Их 5:
1) Hello — эти пакеты отправляются на мультикастовый адрес 224.0.0.10 ближайшим соседям. Подтверждения в ответ не требуют. Нужны только для идентификации и своего рода keepalive механизмом.
2) Update — содержат маршрутную информацию. Как только обнаруживаются соседи, маршрутизатор сразу отправляет им данный пакет. После чего соседи заполняют таблицу EIGRP топологии. Может отправляться по мультикастовому адресу или юникастовому. Эти пакеты требуют ответа.
3) Query — пакет запроса потерянного маршрута. То есть когда маршрутизатор теряет запись об этом маршруте и не имеет запасного пути к нему. Может отправляться одному через unicast или группе соседей через multicast.
4) Reply — ответ на Query-запрос. Данный пакет всегда отправляется на unicast-адрес (то есть тому, кто его запросил). Требует подтверждения.
5) ACK — используется для подтверждения Update, Query и Reply пакетов. Всегда отправляется на unicast-адрес.
Помните топологию EIGRP с множеством кодов? Так вот эти коды и отображают состояние и отправляемое сообщение на каждый из маршрутов. Вот так в принципе работает EIGRP.
Переходим к последнему протоколу — это OSPF (англ. Open Shortest Path First). Относится он к группе link state или протокол состояния канала. Если RIP с EIGRP работали более-менее похоже, то OSPF работает совершенно по другому. Если дистанционно-векторные протоколы сравнивались с дорожными указателями, то протоколы состояния канала можно сравнить с дорожным навигатором. В этом как раз и отличие. OSPF сначала строит карту сети, а потом выбирает лучший путь. Да, таким образом он более ресурсозатратный протокол, нежели его коллеги, но на текущий момент это не столь критично, как было лет 25-30 назад.
Итак. Почему Link-State:
1) Link — интерфейс маршрутизатора.
2) State — его состояние и как он подключен к соседям.
Оперирует они:
1) LSA (от англ. link-state advertisements) — это как раз таки объявления, которыми они обмениваются между собой. Ниже их разберем.
2) LSDB (от англ. link-state database) — как раз эти LSA формируют базу. Или ту самую карту сети.
Тут встает вопрос. А хорошо ли то, что каждый маршрутизатор обменивается своей информацией с каждым соседом?!
Представим топологию: 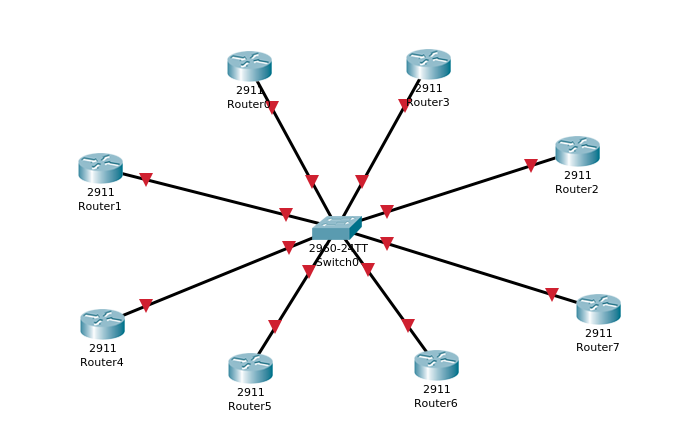
Что если каждый маршрутизатор будет отсылать маршрут каждому из своих соседей?! Мы получим огромный флуд трафика. При этом один и тот же анонс будет зеркалироваться… Подумали в свое время инженеры и решили, что эффективнее держать одного маршрутизатора, которому все остальные будут отсылать уведомления, а он будет ответственным за весь флуд. Тем самым смысл тот же, только трафика будет меньше. А чтобы не случилось ситуации, когда «главный» умирает и вся сеть останавливается, придумали держать запасного маршрутизатора, который, в случае «смерти» основного, возьмет его обязанности на себя.
Маршрутизатор, который берет роль основного на себя, называется DR (от англ. Designated Router), а запасной маршрутизатор называется BDR (от англ. Backup Designated Router).
Такая логика работает автоматически в сетях с множественным доступом, которой и является Ethernet. Если у вас сеть точка-точка (пусть даже Ethernet и соединены друг с другом напрямую), то DR и BDR выбирать не обязательно, так как всего 2 участника (но в Ethernet они все же будут выбраны). Но никто не мешает вам изменить логику OSPF и прописать каждого соседа вручную. Только зачем?)
Так вот после того, как LSDB заполнена, каждый маршрутизатор начинает высчитывать самый выгодный маршрут до каждой подсети. Использует он для этого алгоритм SPF (от англ. Shortest Path First). Лучший подсчитанный маршрут попадает в таблицу маршрутизации.
Давайте перейдем к практике и по ходу разбираться.
Есть схема: 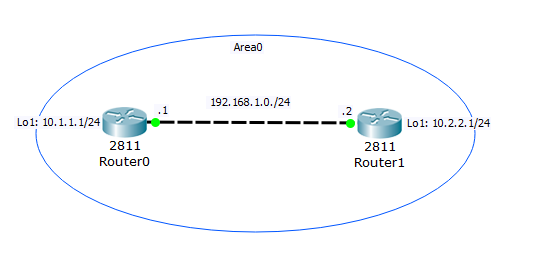
Схема самая простая. Единственное, что новое — это очерчена зона. Я специально ее нарисовал. Дело в том, что OSPF обязательно нужно указывать зону для которой включается протокол. Это сделано для того, чтобы снизить нагрузку в расчетах пути. Как я говорил ранее, протокол появился достаточно давно и для того времени производительность играла большую роль. Сейчас тоже принято делить на зоны. Но сейчас это делается для снижения не нужного трафика.
Зоной по-умолчанию всегда выбирается нулевая. Ее еще называют backbone зоной и не с проста. Если у вас в сети много различных зон, то соединены они должны быть через нулевую. То есть нельзя перейти из 11-ой в 25-ую зону напрямую. Обязательно нужно пройти через нулевую, а из нулевой проследовать в требуемую. Единственный случай, когда можно пройти из зоны в зоны, миновав нулевую — это использование Virtual Link. Почитать о ней можно здесь.
Сейчас у нас 2 маршрутизатора в нулевой зоне. На маршрутизаторах настроены IP-адреса и создан Loopback. Ниже под спойлерами конфиги.
Router0#show running-config
Building configuration…
Current configuration: 622 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router0
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.1.1.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.1.1 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
no ip address
duplex auto
speed auto
shutdown
!
interface Vlan1
no ip address
shutdown
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Router1#show running-config
Building configuration…
Current configuration: 622 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router1
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.2.2.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.1.2 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
no ip address
duplex auto
speed auto
shutdown
!
interface Vlan1
no ip address
shutdown
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Теперь включаю OSPF для интерфейсов FastEthernet0/0 и Loopback1 обоих роутеров:
Конфигурация простая. Указывается подсеть, wildcard маска и номер зоны. После видим сообщения:
Соседство, судя по сообщению установилось. Но, если обратить внимание, то почему то соседство выбрано между адресами из Loopback интерфейсов. Это на самом деле не адрес, а идентификатор или Router ID. Если в самом процессе он явно не указывается, то выбирается автоматически. Если настроены Loopback интерфейсы, то выбирается наибольший IP-адрес из них. Если Loopback не настроены, то выбирается наибольший IP-адрес из обычного физического интерфейса. У нас Loopback был настроен, а значит он и будет выбран RID.
Так как процессы на обоих роутерах одинаковые, покажу на примере Router0:
Так как соседство установлено, посмотрим список соседей.
Видим 10.2.2.1 (Router1). Статус Full (чуть ниже расскажу и об этом), роль BDR (то есть Router0 выбран DR). Его физический IP-адрес и с какого интерфейса доступен.
Теперь посмотрим на базу данных OSPF:
Подробное ее содержание изучается в курсе CCNP Route, поэтому расскажу вкратце. Есть несколько типов LSA-сообщений. В нашей схеме используются только Type1 (Router) и Type2(Network). Первое генерится каждым маршрутизатором в пределах зоны и дальше зоны не уходит. Второй тип генерируется DR-ом и содержит адрес DR и инфу о всех маршрутизаторах в зоне.
Например, так выглядит Type1 с консоли Router0:
То есть LSA каждого маршрутизатора, в которых он сообщает о своих сетях.
А вот так Type2:
То есть как раз адрес DR (кому отправлять свои LSA и список маршрутизаторов в зоне).
И теперь можно посмотреть на таблицу маршрутизации:
Видим букву O (это значит, что маршрут получен из той же зоны, что и данный маршрутизатор). Можно заметить, что в таблицу записан с маской /32. Это потому что адрес из Loopback интерфейса и обычно такие адреса служат для всяких RID и прочих идентификаторов. Это не подсеть, а значит нет смысла анонсировать с тем же префиксом, что и сам интерфейс. Но такое поведение работает не на всех цисках. Поэтому тут надо быть внимательнее. Рядом видим привычную административную дистанцию (у циски это 110, но можно поменять) и метрику, которая равна 2-ум. Здесь метрика считается проще, чем у EIGRP. Формула:
.
Reference Bandwidth — это некое заданное число (здесь по-умолчанию 100). Оно прошито внутри логики и меняется командой auto-cost reference-bandwidth число в настройках OSPF процесса.
А вот Interface Bandwidth берется ровно такое, какая пропускная способность у интерфейса. На нашем интерфейсе это 100, поэтому метрика = 1. Так как Router1 анонсирует уже с метрикой 1, то накладывая свою стоимость в 1-цу, получаем 2.
OSPF для меня в свое время менялся в сложности понимания. Сначала казалось все легко, включил и все работает. Дальше, когда начинаешь углубляться в структуру LSA и как происходит формирование и расчет, теряешься. А после понимания, он снова становится легким. Его понимание приходит только после практики. Поэтому можете потренироваться на этой топологии. Ссылка на нее.
Пару слов по балансировке. Здесь она строго эквивалентная. Нельзя делать, как в EIGRP. Всего в кандидатах может быть до 16 маршрутов, но в таблицу попадут только 4.
Если предыдущая схема понятна, то двигаемся дальше. Добавим еще один маршрутизатор и соединим их, при помощи коммутатора: 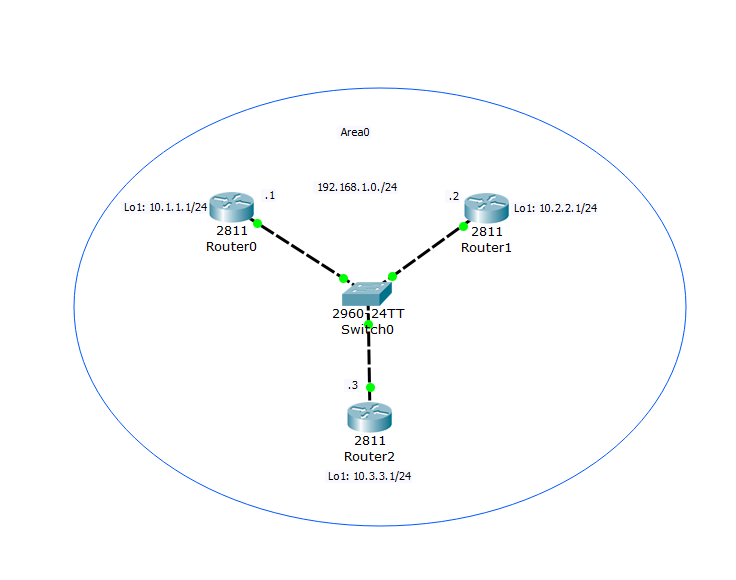
Я взял за основу предыдущую, адреса все те же самые, включен OSPF. На Router2 также включен OSPF и настроены адреса согласно схеме. Теперь смотрим, что произошло со стороны того же Router0. Ввожу команду просмотра соседей:
И вижу нового соседа, но с пометкой DROTHER. Это значит, что маршрутизатор Router2 (новый) не является DR или BDR. Обратите внимание, что DR (Router0) установил Full соседство со всеми соседями.
Ввожу нового игрока на поле — Router3: 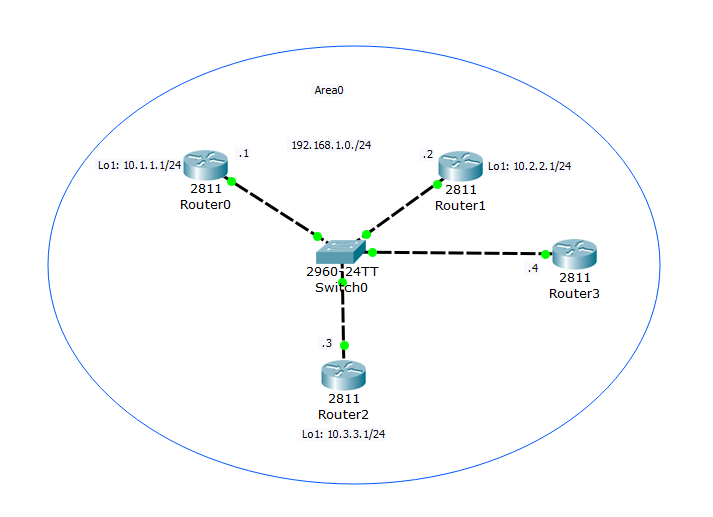
Единственное, что у него настроено — это IP-адрес 192.168.1.4/24 на FastEthernet 0/0 и включен OSPF. Он тут для наглядности.
Со стороны Router0:
Так как нет адреса на Loopback интерфейсе и не задан вручную RID, выбран адрес с физического интерфейса. А теперь переходим к Router2 и смотрим на его список соседей:
Видим, что с ним у него не Full отношения, а 2Way. Почему не Full? На этом остановлюсь и расскажу про процесс установления соседства. В хорошо работающей сети процесс соседства происходит настолько быстро, что все состояния вы не успеете увидеть. Я только опишу их, для общего понимания:
1) Down — это самый старт, когда маршрутизатор еще не предпринял попытку соседства и ничего в ответ не получает.
2) Init — маршрутизатор переходит в это состояние после отправки Hello-сообщения, до момента получения ответа.
3) 2-WAY — маршрутизатор переходит в это состояние, если получает ответный Hello и видит внутри него свой RID. Это как раз момент установления соседства. В сетях множественного доступа (типа Ethernet) это состояние конечное между «не DR/BDR» маршрутизаторами. Как раз в этом состоянии осталось соседство между Router2 и Router3.
4) ExStart — это состояние выбора DR/BDR. Маршрутизатор с наилучшим RID берет на себя эту роль. Он начинает первым процесс обновления LSDB у всех соседей.
5) Exсhange — состояние, в котором маршрутизаторы отправляют друг другу состояние своих LSDB.
6) Loading — если маршрутизатор видит, что в присланном сообщении есть подсеть, о которой он не знает, он запрашивает информацию о ней. И вот пока запрашиваемая инфа не дойдет до него, он будет висеть в этом состоянии.
7) Full — конечное состояние. Наступает оно в том случае, когда LSDB между соседями синхронизировано.
Стоит упомянуть, что в OSPF есть таймеры соседства. Нужно для того, чтобы узнать жив ли сосед или пора исключить его. Поэтому каждые 10 секунд маршрутизаторы отсылают друг другу Hello-пакеты, чтобы подтвердить свое существование. Если в течении 40 секунд от соседа ничего не поступало, соседство с ним разрывается.
Посмотреть на таймеры и другие параметры интерфейса, на котором включен OSPF, можно командой show ip ospf interface:
Если интересно, как происходит весь процесс установления соседства, откройте топологию по ссылке. Переключитесь в режим симуляции и перезагрузите один из маршрутизаторов. Все сразу особого смысла нет. Скорее быстрее заглючит CPT, нежели получиться разобраться.
И последнее, что стоит рассмотреть из раздела OSPF — это Multiarea OSPF (или многозонный OSPF). 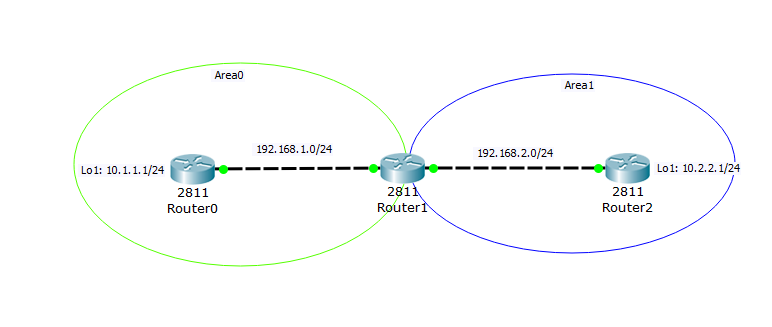
Теперь есть 3 маршрутизатора. Router0 находится в нулевой зоне, Router1 в 0-ой и 1-ой зоне и Router2 в 1-ой зоне. Конфигурация проста. Я оставлю ее под спойлерами:
Router0#show running-config
Building configuration…
Current configuration: 734 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router0
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.1.1.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.1.2 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
no ip address
duplex auto
speed auto
shutdown
!
interface Vlan1
no ip address
shutdown
!
router ospf 1
log-adjacency-changes
network 192.168.1.0 0.0.0.255 area 0
network 10.1.1.0 0.0.0.255 area 0
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Router1#show running-config
Building configuration…
Current configuration: 693 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router1
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface FastEthernet0/0
ip address 192.168.1.1 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
ip address 192.168.2.1 255.255.255.0
duplex auto
speed auto
!
interface Vlan1
no ip address
shutdown
!
router ospf 1
log-adjacency-changes
network 192.168.1.0 0.0.0.255 area 0
network 192.168.2.0 0.0.0.255 area 1
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Router2#show running-config
Building configuration…
Current configuration: 734 bytes
!
version 12.4
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname Router2
!
!
!
!
!
!
!
!
ip cef
no ipv6 cef
!
!
!
!
!
!
!
!
!
!
!
!
spanning-tree mode pvst
!
!
!
!
!
!
interface Loopback1
ip address 10.2.2.1 255.255.255.0
!
interface FastEthernet0/0
ip address 192.168.2.2 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
no ip address
duplex auto
speed auto
shutdown
!
interface Vlan1
no ip address
shutdown
!
router ospf 1
log-adjacency-changes
network 192.168.2.0 0.0.0.255 area 1
network 10.2.2.0 0.0.0.255 area 1
!
ip classless
!
ip flow-export version 9
!
!
!
!
!
!
!
line con 0
!
line aux 0
!
line vty 0 4
login
!
!
!
end
Отличие от предыдущих схем только в том, что для Router1 и Router2 добавляется другой номер зоны, при включении.
Если посмотреть таблицу маршрутизации c Router0:
То добавились маршруты OIA (или OSPF inter area). То есть маршрут из другой зоны. Если посмотреть базу:
Здесь появился Summary LSA или Type3. Его генерирует маршрутизатор, который находится на границе двух зон. Такой маршрутизатор называют пограничным или ABR (от англ. Area Border Gateway).
Если посмотреть на него поглубже:
То можно заметить, что анонсирует его 192.168.2.1 (это RID Router1).
Если же посмотреть на таблицу маршрутизации со стороны ABR (т.е. Router1):
То для него все маршруты помечены O. Все потому что он находится в обеих зонах и для него они локальны.
А если посмотреть базу:
То тут их больше. Все потому, что у него представлены эти LSA на каждую зону, а также он генерирует Type3 в обе стороны. Для самостоятельного ознакомления лабу можно скачать по данной ссылке.
Таким образом OSPF можно делить на зоны. То есть маршрутизатор видит соседей в своей зоне и просчитывает лучший путь сам. А вот межзоннные маршруты (Type3) диктует ABR. Поэтому на границу чаще ставят производительные маршрутизаторы. На самом деле EIGRP и OSPF уж очень много всего умеют. И заслуживают отдельных статей. Более подробно они разбираются уже в топиках CCNP. Так что для основ достаточно.
В итоге мы разобрались с маршрутизацией и встает вопрос: что использовать? Однозначного ответа тут нет. Если у вас вся сеть построена на цисках, то можно выбирать EIGRP. Если у вас сеть мультивендорная, то тут однозначно OSPF. Да, циска вроде как открыла стандарт, но относительно старые железки (не циски) не получат поддержку этого протокола, да и не на всех новых его внедрят. Более того, могу сказать, что даже в сетях построенных исключительно на цисках, выбирают OSPF. Аргументируя это тем, что OSPF более гибок в настройке, нежели EIGRP. Да и нельзя быть уверенным, что в какой то момент придется ставить сетевое устройство другого вендора. А значит внедрение такого устройства пройдет безболезненно и без перенастройки всей сети.
Подводя итоги, можно сказать, что это самая долгая статья из всех, что я писал. Все потому, что писал я ее больше 2-х лет. Постоянно что-то стопорило ее написание, а когда садился, то не мог сконцентрироваться и написать больше 2-х предложений. Но теперь она написана и можно спокойно выдохнуть. Ее как раз не хватало для основ компьютерных сетей, ведь предыдущие статьи концентрировались в большинстве на L2 уровне. Столь длительное написание привело к тому, что циска уже меняет программу своего экзамена. А значит некоторые темы, которые я хотел далее осветить, уже не актуальны. Поэтому я уберу из содержания будущие темы и буду выкладывать статьи, исходя из актуальности.
Таблица маршрутизации
Таблица маршрутизации — таблица, состоящая из сетевых маршрутов и предназначенная для определения наилучшего пути передачи сетевого пакета. Каждая запись в таблице маршрутизации состоит, как правило, из таких полей:
- адрес сети назначения (destination);
- маска сети назначения (netmask, genmask);
- адрес шлюза (gateway), за исключением тех случаев, когда описывается в маршрут непосредственно доступную (directly connected) сеть, в этом случае вместо адреса шлюза обычно указываются 0.0.0.0;
- метрика маршрута (не всегда).
Пример таблицы маршрутизации (ОС Linux):
При отправке сетевого пакета, операционная система смотрит, по какому именно маршруту он должен быть отправлен, основываясь на таблице маршрутизации. Как правило, выбирается наиболее конкретный (то есть, с наболее длинной сетевой маской) маршрут из тех, которые соответствуют адресу отправителя. Если ни один из маршрутов не подходит, пакет уничтожается, а его отправителю возвращается ICMP-сообщение No route to host.
[править] Просмотр таблицы маршрутизации
Таблица маршрутизации в UNIX просматривается командой
В Linux это можно сделать также при помощи команд route и ip.
А также напрямую просмотрев файл /proc/net/route:
Таблица маршрутизации в устройствах Cisco ASA:
В Android (как и в любом Linux):
[править] Модификация таблицы маршрутизации
Изменение записей в таблице маршрутизации может выполняться администратором системы вручную или специальным программным обеспечением, известным как демон маршрутизации.
В момент начальной загрузки системы таблица маршрутизации пуста, и пополняется потом, по мере загрузки системы и её дальнейшей работы.
[править] В маршрутизаторах Cisco
По умолчанию (пока маршрутизатор не настроен) таблица маршрутизации пуста. Источников заполнения её может быть несколько:
- непосредственно присоединенные сети — появляются в таблице маршрутизации после того как на интерфейсах маршрутизатора назначаются адреса и интерфейс находится в состоянии up;
- статические маршруты — создаются вручную администратором;
- маршруты протоколов динамической маршрутизации — с помощью этих протоколов маршрутизаторы сообщают друг другу об известных им маршрутах и заполняют таблицу.
Для того чтобы сравнить различные маршруты в одну и ту же сеть назначения полученные из одного источника, используется метрика маршрута. Маршрут с лучшей метрикой помещается в таблицу.
Если маршрутизатор получает информацию об одном и том же получателе или сети получателя из разных источников, то ему необходимо каким-то образом выбрать какой именно маршрут поместить в таблицу. Для этого используется administrative distance.
Administrative distance (AD) — это число, присвоенное каждому из возможных источников маршрутов, которое является некой степенью доверия к источнику. В таблицу маршрутизации попадет маршрут от того источника у которого меньше значение AD. AD имеет только локальное значение и никак не влияет на принятие решения на других маршрутизаторах.
Например, у непосредственно присоединенных сетей значение AD — 0, у статических — 1, OSPF — 110.
Это значит, что если маршрутизатор получит информацию об одной и той же сети от всех трех источников, то выберет он непосредственно присоединенный маршрут. По умолчанию статические маршруты всегда выигрывают у маршрутов протоколов динамической маршрутизации.
Значения AD для маршрутизаторов Cisco указаны на странице Маршрутизация в Cisco.