Настройка групп доступности Always On в SQL Server
 26.02.2020
26.02.2020
 insci
insci
 SQL Server, Windows Server 2019
SQL Server, Windows Server 2019
 комментариев 5
комментариев 5
В этой статье мы рассмотрим пошаговую установку и настройку групп доступности Always On в SQL Server в Windows Server 2019, рассмотрим сценарии отработки отказов и ряд других смежных вопросов.
“Always On Availability Groups” или “Группы доступности Always On” это технология для обеспечения высокой доступности в SQL Server. Always On появились в релизе Microsoft SQL Server 2012.
Особенности групп доступности Always On в SQL Server
Для чего могут использоваться группы доступности SQL Server?
- Высокая доступность MS SQL и автоматическая отработка отказа;
- Балансировка нагрузки select запросов между узлами (вторичные реплики могут быть доступны для чтения);
- Резервное копирование с вторичных реплик;
- Избыточность данных. Каждая реплика хранит копии баз данных группы доступности.
Always On работает на платформе Windows Server Failover Cluster (WSFC). WSFC обеспечивает мониторинг узлов участвующих в группе доступности и может осуществлять автоматическую отработку отказа посредством голосования между узлами. Начиная с MS SQL Server 2017 появилась возможность использовать Always On без WSFC, в том числе на Linux системах. При построении кластера на Linux можно использовать Pacemaker как альтернативу WSFC.
Always On доступен в Standard редакции, но с некоторыми ограничениями:
- Лимит на 2 реплики (основную и вторичную);
- Вторичная реплика не может быть использована для read доступа;
- Вторичная реплика не может быть использована для резервного копирования MS SQL;
- Поддержка только 1 базы данных на группу доступности.
В редакции Enterprise ограничений нет.
Разберемся в терминологии:
- Группу доступности Always ON – это набор реплик и баз данных;
- Реплика – это экземпляр SQL Server находящийся в группе доступности. Реплика может быть основная (primary) и вторичная (secondary). Каждая реплика может содержать одну или более баз данных.
В основе Always On лежит WSFC. Каждый узел группы доступности должен быть членом отказоустойчивого кластера Windows. Каждый экземпляр SQL Server может иметь несколько групп доступности. В каждой группе доступности может быть до 8 вторичных реплик.
При отказе основой реплики, кластер проголосует за новую основную реплику и Always On переведёт одну из вторичных реплик в статус основной. Так как при работе с Always On пользователи соединяются с прослушивателем кластера (или Listener, то есть специальный IP адрес кластера и соответствующее ему DNS имя), то возможность выполнять write запросы полностью восстановится. Прослушиватель также отвечает за балансировку select запросов между вторичными репликами.
Настройка Windows Server Failover Cluster для Always On
Прежде всего нам нужно настроить отказоустойчивый кластер на всех узлах, которые будут участвовать в Always On.
- 2 виртуальных машины на Hyper-V с Windows Server 2019;
- 2 экземпляра SQL Server 2019 редакции Enterprise;
- Hostname узлов – testnode1 и testnode2. Имя экземпляров node1 и node2.
В Server Manager добавляем роль Failover Clustering, или установите компонент с помощью PowerShell:
Install-WindowsFeature –Name Failover-Clustering –IncludeManagementTools
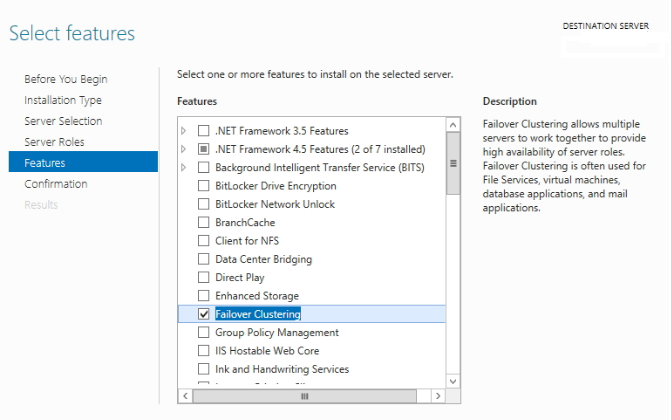
Установка автоматическая, ничего настраивать пока не нужно. После окончания установки запустите оснастку Failover Cluster Manager (FailoverClusters.SnapInHelper.msc).
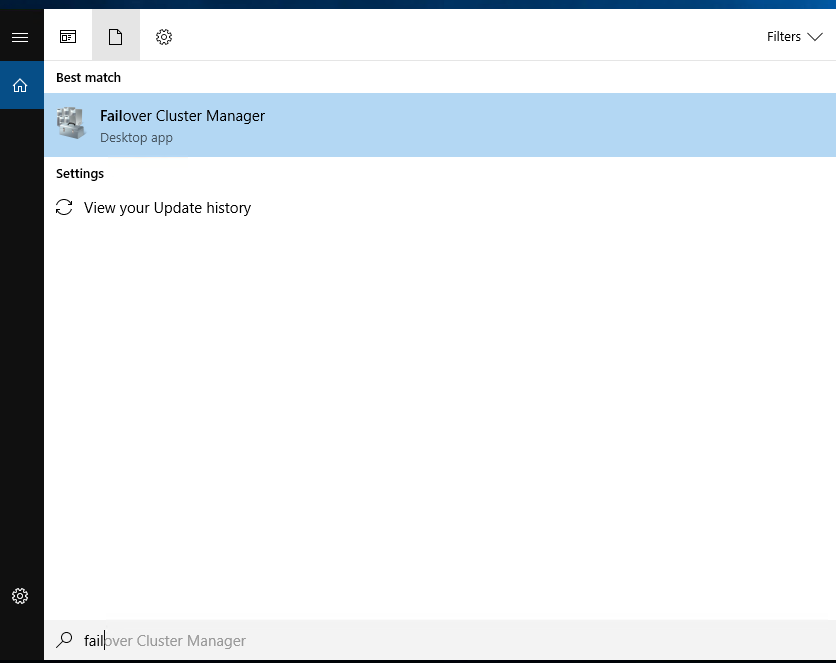
Создаём новый кластер.
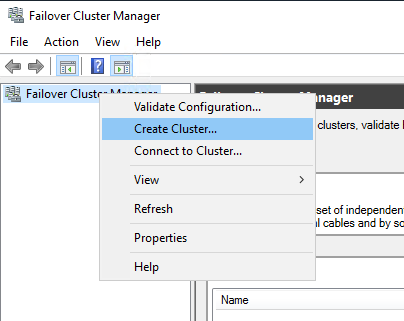
Добавляем имена серверов, которые будут участвовать в кластере.
Дальше мастер предлагает пройти тесты. Не отказываемся, выбираем первый пункт.
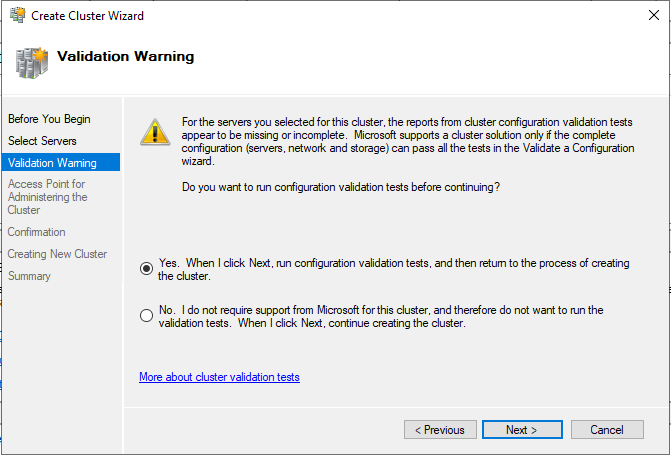
Указываем имя кластера, выбираем сеть и IP адрес кластера. Имя кластера автоматически появится в DNS, прописывать его специально не нужно. В моём случае имя кластера – ClusterAG.
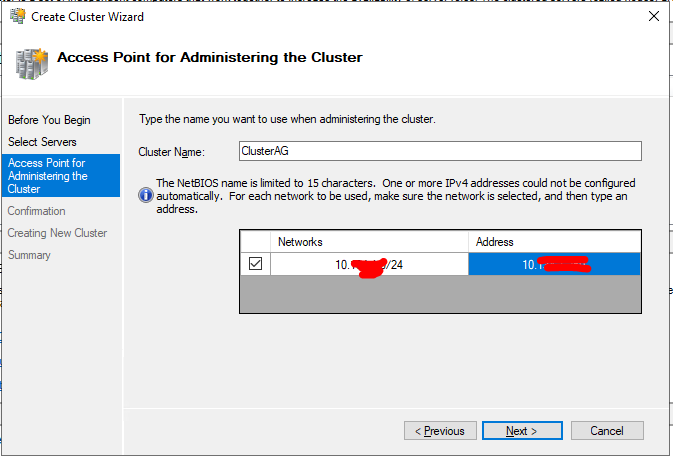
Убираем чебокс “Add all eligible storage to the cluster”, так как диски мы сможем добавить позже.
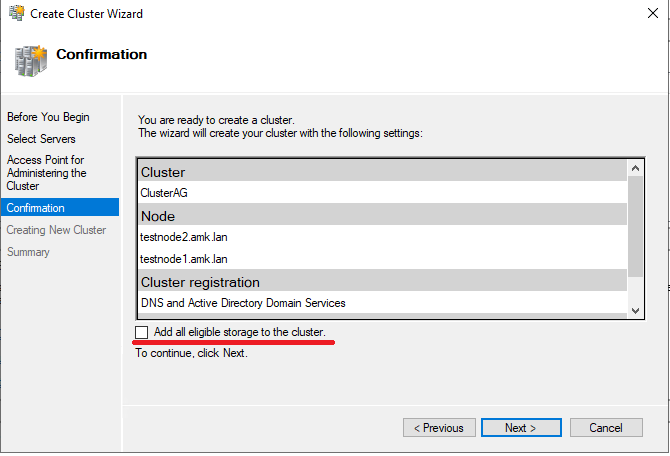
Узлов в кластере всего 2, поэтому необходимо настроить Cluster Quorum. Кворум кластера — это “решающий голос”. Например, если один из узлов кластера становится недоступен, кластеру необходимо определить какие узлы на самом деле доступны и могут видеть друг друга. Кворум нужен для согласованности кластера (Cluster -> More Actions -> Configure Cluster Quorum Settings).
Выберите тип кворума со свидетелем (quorum witness).
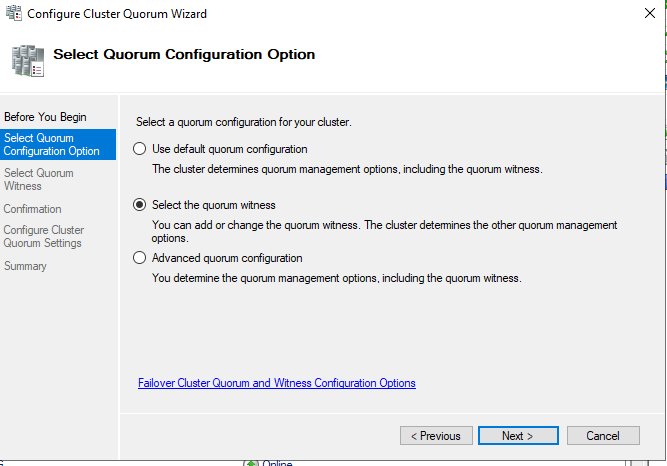
Затем выбираем тип свидетеля – сетевая папка (file share witness).
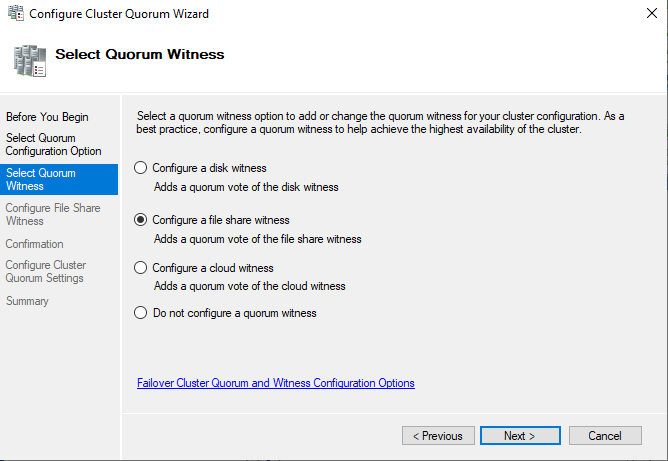
Укажите UNC путь к сетевой папке. Эту директорию нужно создать самостоятельно, и она обязательно должна быть на сервере, который не участвует в кластере.
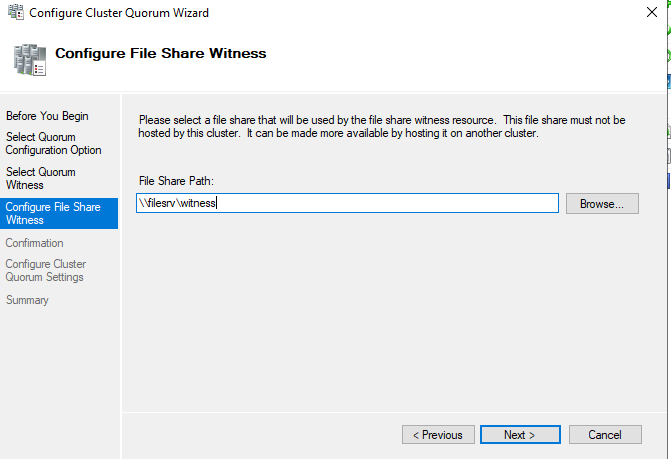
При настройке кластера вы можете получить ошибку:
Скорее всего это значит, что у пользователя из-под которого работает кластер нет прав на эту сетевую папку. По-умолчанию кластер работает из-под локального пользователя. Вы можете дать права на эту папку всем компьютерам кластера, либо сменить аккаунт для службы кластера и раздать права ему.
На этом базовая конфигурация кластера закончена. Убедимся, что DNS кластера прописан и отдаёт правильный IP
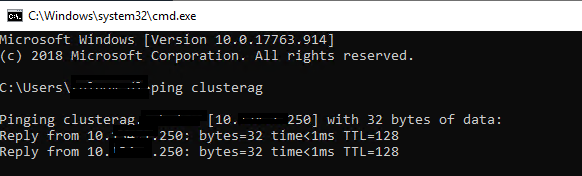
Настройка Always On в MS SQL Server
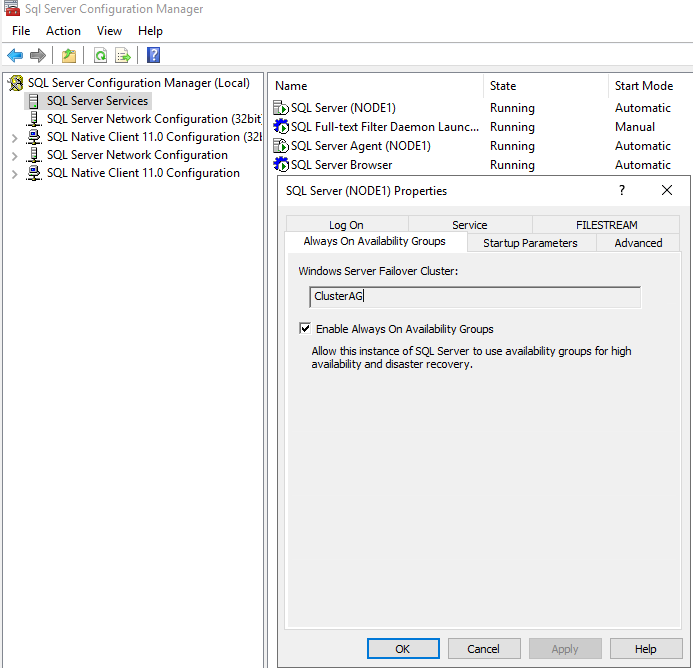
После стандартной установки экземпляра SQL Server вы можете включить и настроить группы доступности Always On. Их нужно включить в SQL Server Configuration Manager в свойствах экземпляра. Как видно на скриншоте, SQL Server уже определил, что он является участником кластера WSFC. Поставьте чекбокс “Enable Always On Availability Groups” и перезагрузите службу экземпляра MSSQL. Выполните те же действия на втором экземпляре.
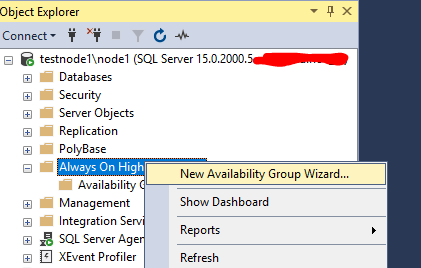
В SQL Server Management Studio щелкните по узлу “Always On High Availability” и запустите мастер настройки группы доступности (New Availability Group Wizard).
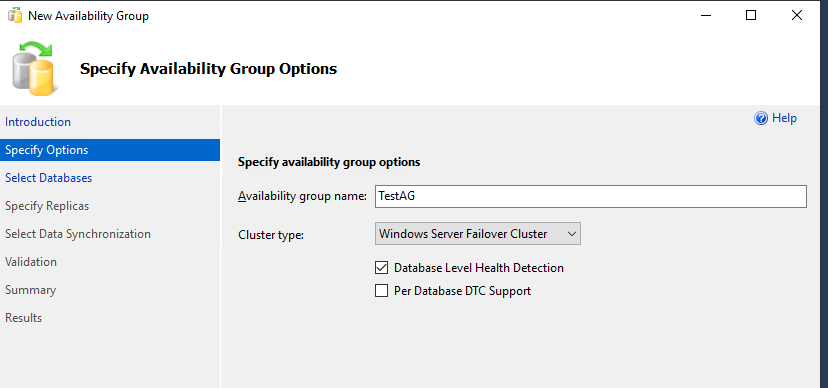
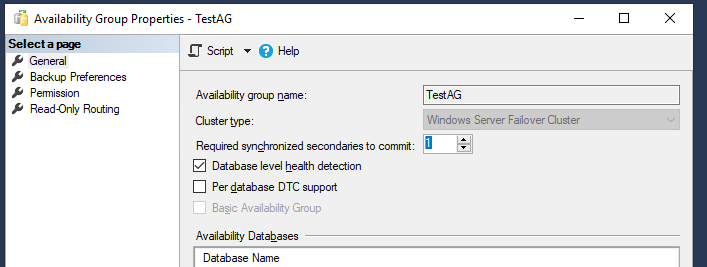
Укажите имя группы доступности Always On и выберите опцию “Database Level Health Detection”. С этой опцией Always On сможет определять, когда база данных находится в нездоровом состоянии.
Выберите базы данных SQL Server, которые будут участвовать в группе доступности Always On.
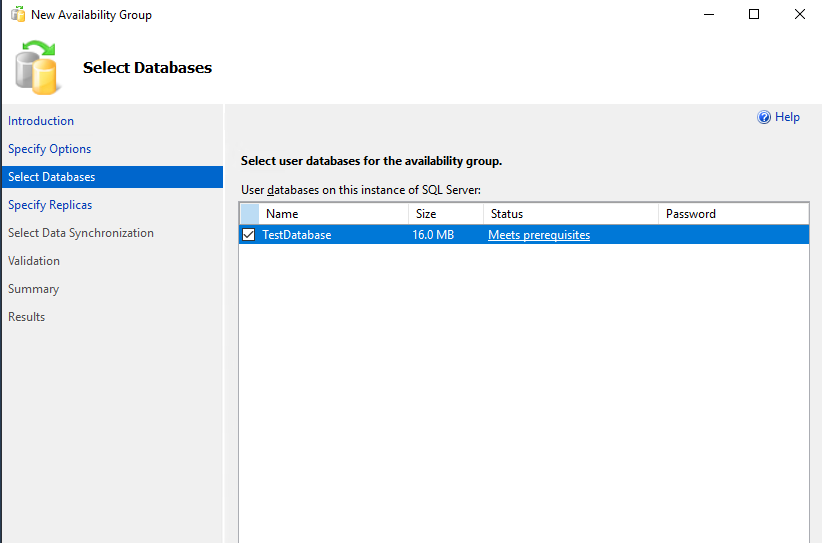
Нажмите “Add Replica…” и подключитесь к второму серверу SQL. Таким образом можно добавить до 8 серверов.
- Initial Role – роль реплики на момент создания группы. Может быть Primary и Secondary;
- Automatic Failover – если база данных станет недоступна, Always On переведёт primary роль на другую реплику. Отмечаем чекбокс;
- Availability Mode – возможно выбрать Synchronous Commit или Asynchronous Commit. При выборе синхронного режима, транзакции, поступающие на primary реплику, будут отправлены на все остальные вторичные реплики с синхронным режимом. Primary реплика завершит транзакцию только после того, как реплики запишут транзакцию на диск. Таким образом исключается возможность потери данных при сбое primary реплики. При асинхронном режиме основная реплика сразу записывает изменения, не дожидаясь ответа от вторичных реплик;
- Readable Secondary – параметр задающий возможность делать select запросы к вторичным репликам. При значении yes, клиенты даже при соединении без ApplicationIntent=readonly смогут получить read-only доступ;
- Required synchronized secondaries to commit – число синхронизированных вторичных реплик для завершения транзакции. Нужно выставлять в зависимости от количества реплик, я поставлю 1. Имейте в виду, что, если вторичных синхронизированных реплик станет меньше указанного числа (например, при аварии), базы данных группы доступности станут недоступны даже для чтения.
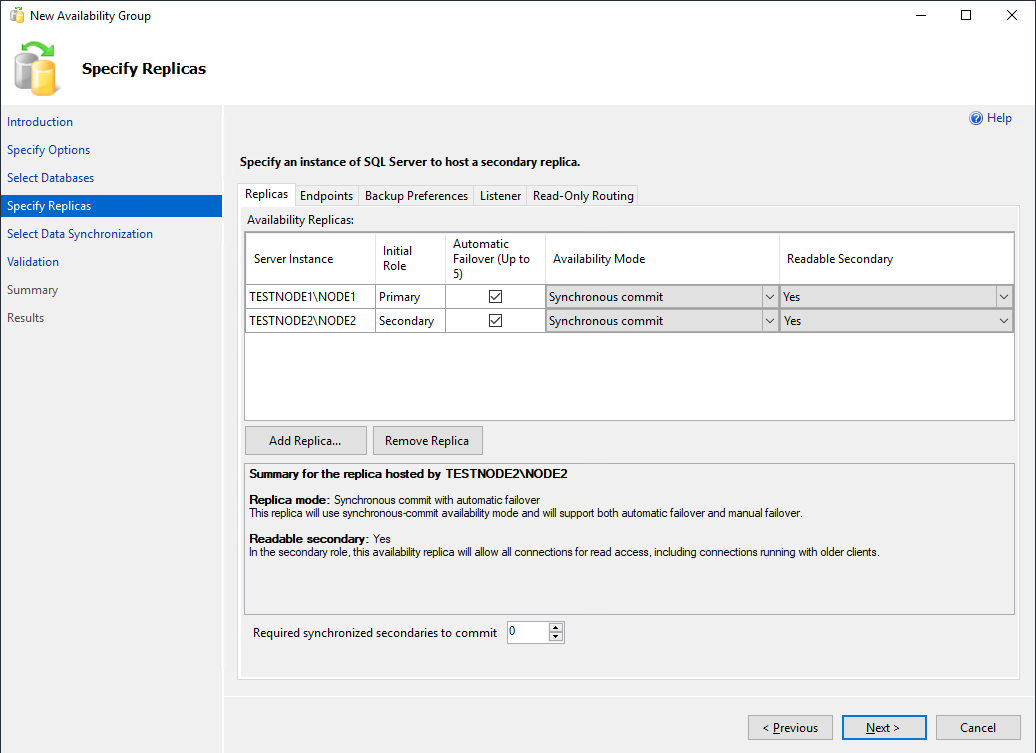
Вкладку Endpoints не трогаем.
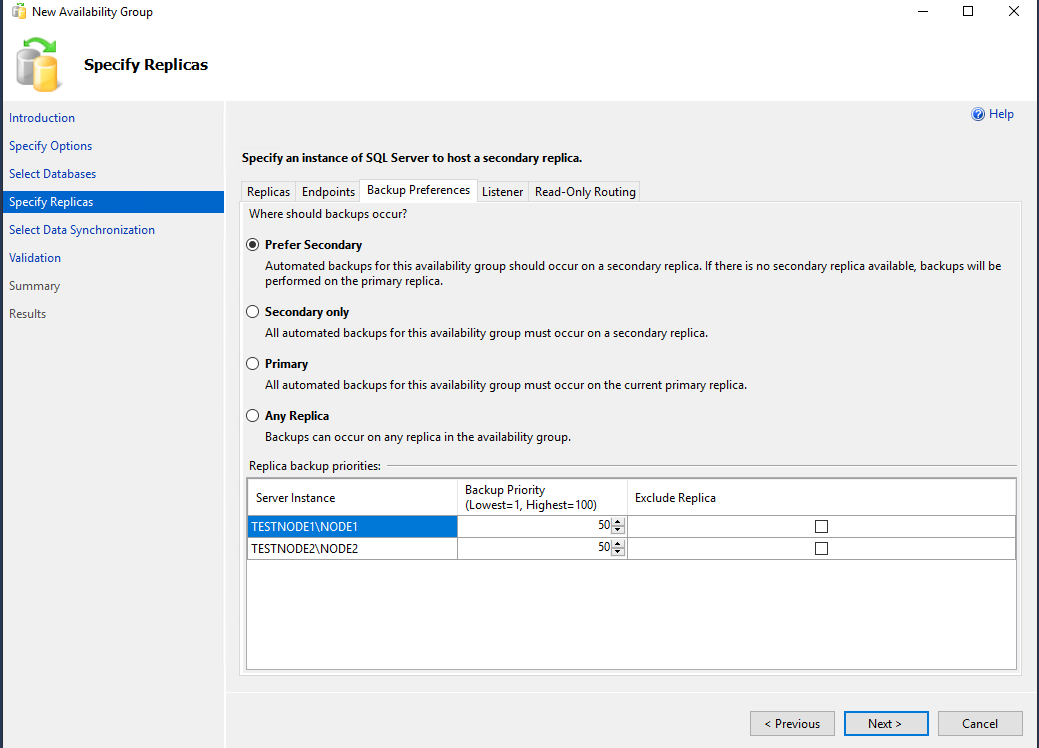
На вкладке Backup Preferences можно выбрать откуда будут делаться бекапы. Оставляем всё по умолчанию – Prefer Secondary.
Указываем имя слушателя группы доступности (availability group listener), порт и IP адрес.
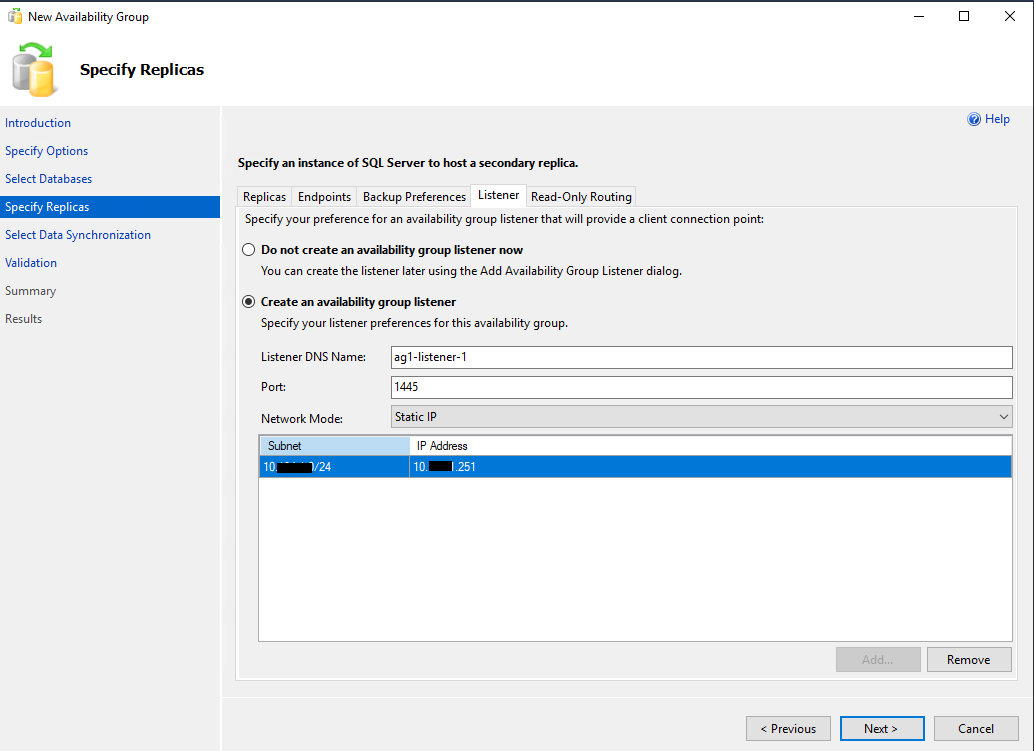
Вкладку Read-Only Routing оставляем без изменений.
Выбираем каким образом будут синхронизироваться реплики. Я оставляю первый пункт – автоматическую синхронизацию (Automatic seeding).
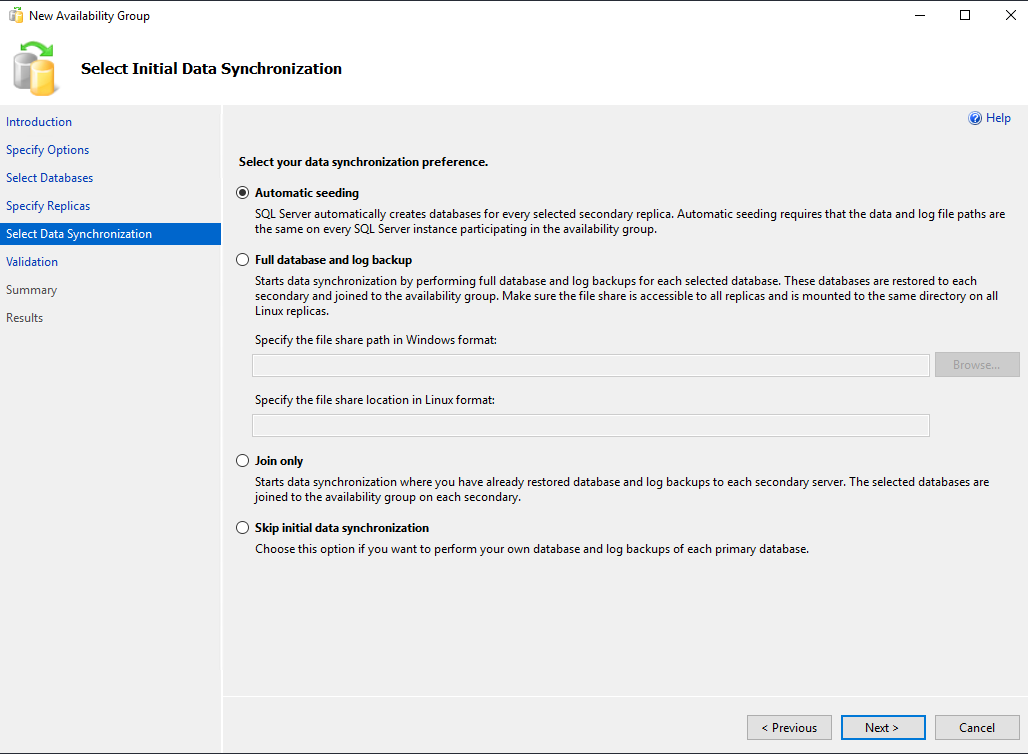
После этого ваши настройки должны пройти валидацию. Если ошибок нет, нажмите Finish для применения изменений.
В моём случае все тесты прошли успешно, но после установки на шаге Results, мастер сообщил об ошибке при создании слушателя группы доступности. В логах кластера была такая ошибка:
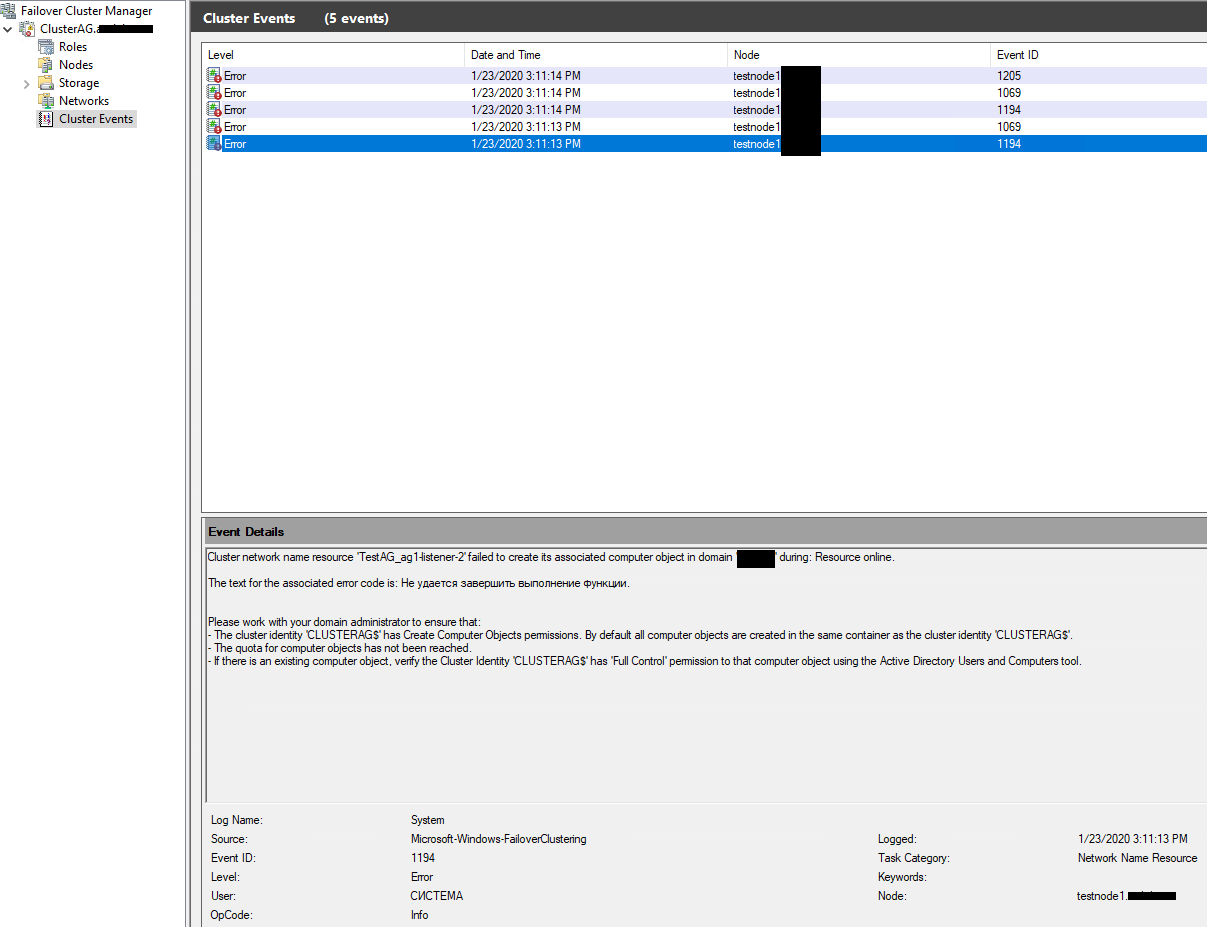
Это означает, что у кластера недостаточно прав для создания слушателя. В документации написано, что достаточно дать разрешение на создание объектов типа “компьютер” объекту вашего кластера. Проще всего это сделать через делегирование полномочий в AD (или, быстрый но плохой вариант — временно добавить объект CLUSTERAG$ в группу Domain Admins).
Так как группа доступности у меня создалась, а слушатель нет, я добавил его вручную. Вызываем контекстное меню на группе доступности и жмем Add Listener…
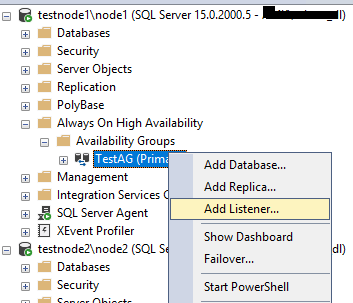
Укажите IP адрес, порт и DNS имя слушателя.
Проверьте, что Listener появился во разделе доступных слушателей группы Always On.
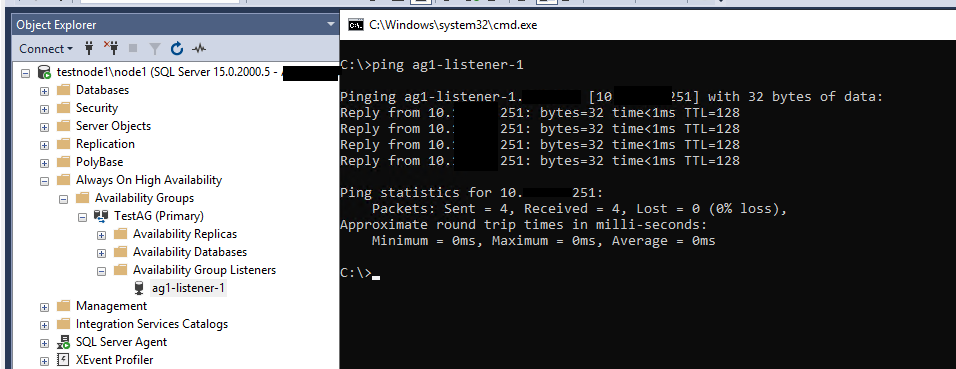
На этом базовая настройка группы доступности Always On закончена.
Always On: проверка работы, автоматическая отработка отказа
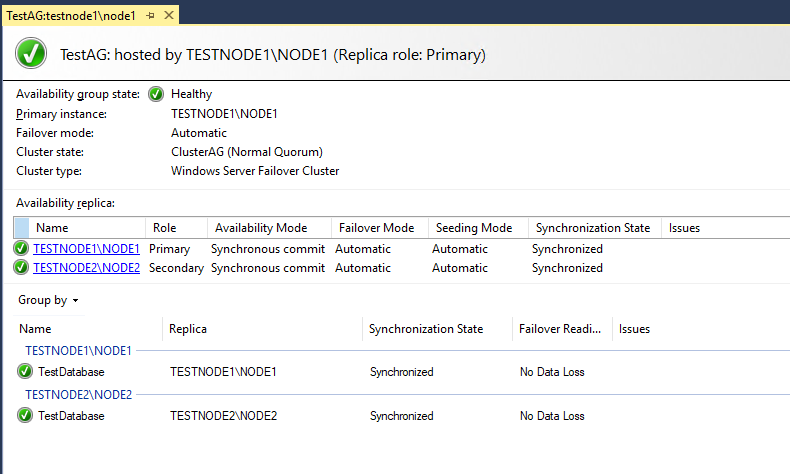
Посмотрим на панель мониторинга групп доступности (Show Dashboard).
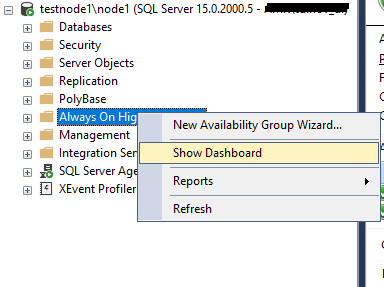
Все OK, группа доступности создана и работает.
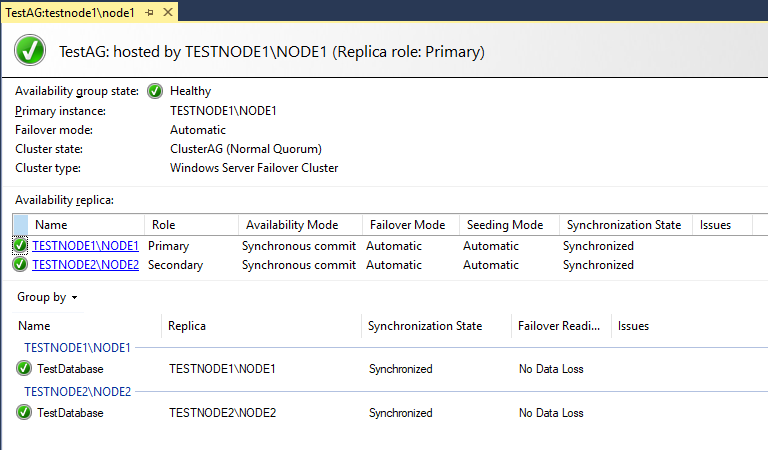
Попробуем перевести основную роль на экземпляр node2 в ручном режиме. Щелкните ПКМ по группе доступности и выберите Failover.
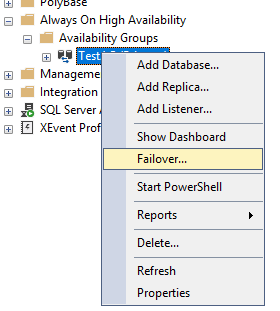
Стоит обратить внимание на пункт Failover Readiness. Значение No data loss значит, что потеря данных при переходе исключена.
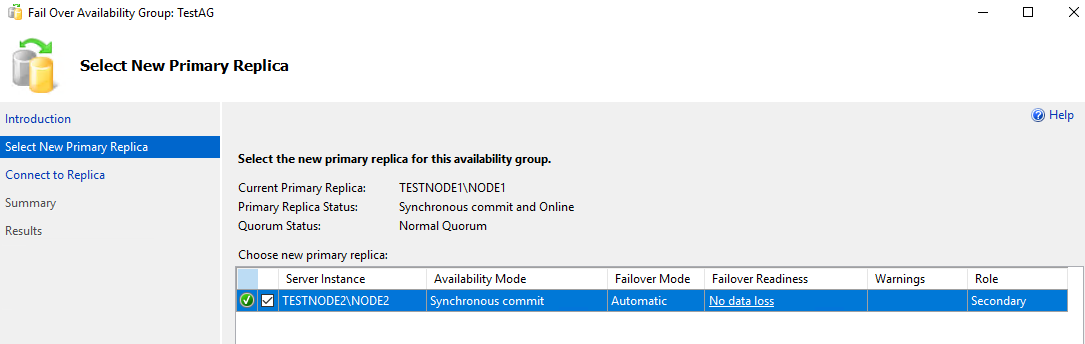
Соединяемся с node2.
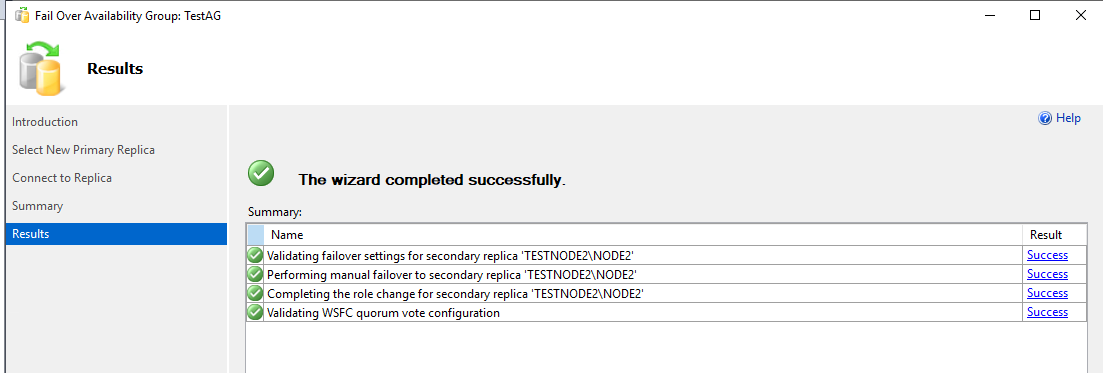
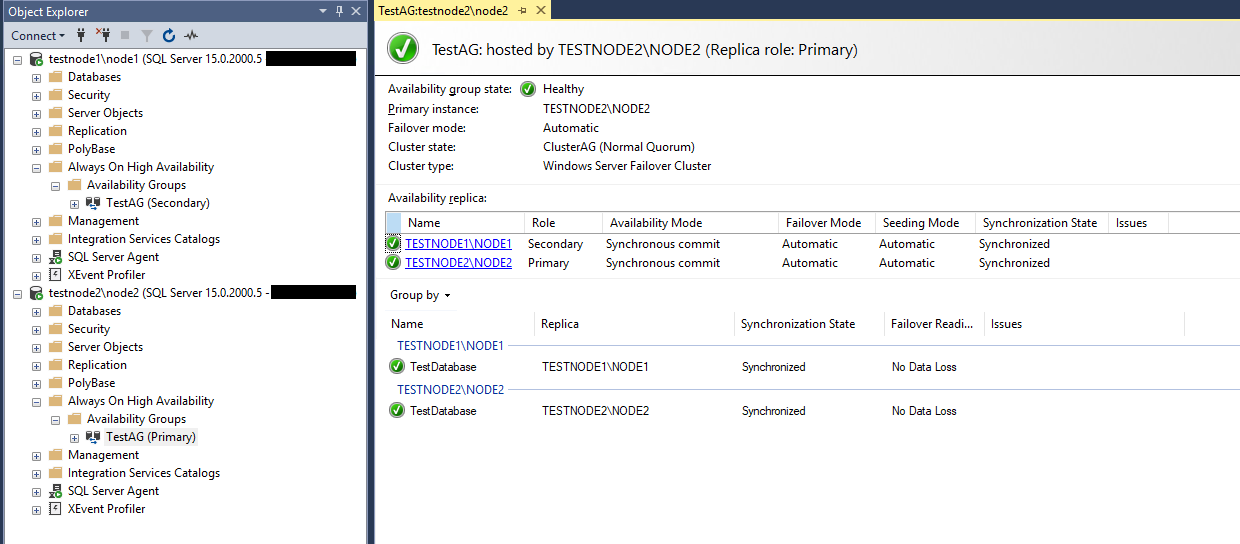
Проверяем, что node2 стал основной репликой в группе доступности (Primary Instance).
Убедимся, что слушатель работает как надо. В SSMS укажите DNS имя слушателе и порт через запятую: ag1-listener-1,1445
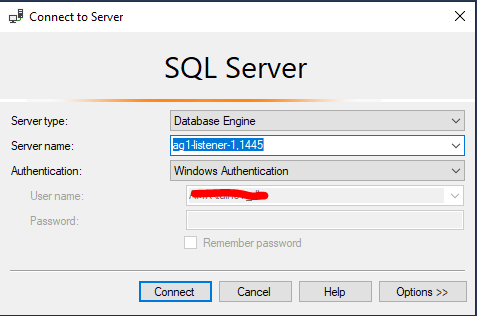
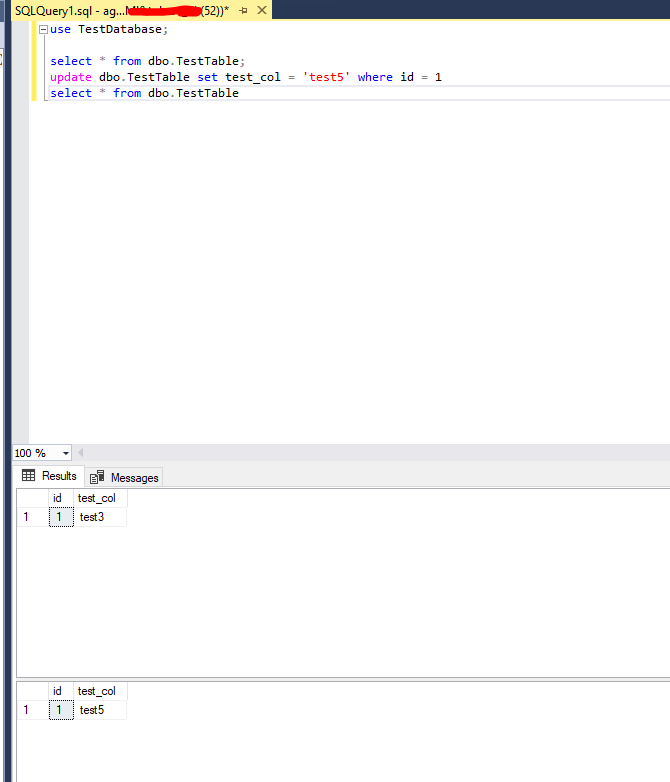
Сделаем простые insert, select и update запросы в нашу базу SQL Server.
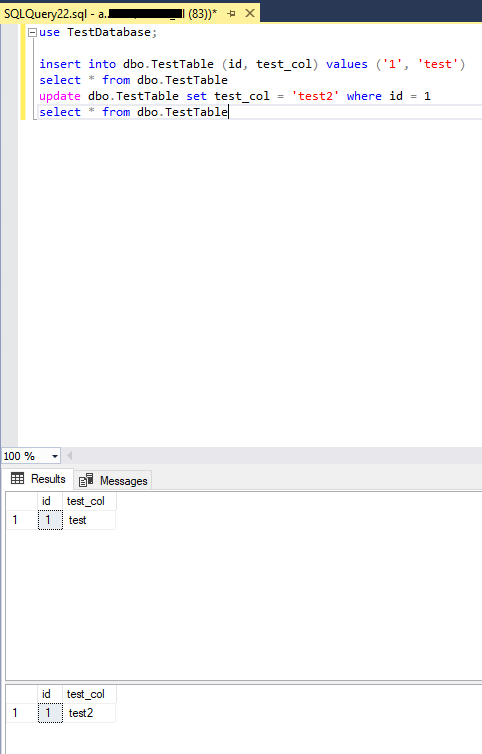
Теперь проверим автоматическую отработку отказа основной реплики. Просто завершите процесс sqlservr.exe на TESTNODE2.
Проверяем состояние группы доступности на оставшемся узле – TESTNODE1\NODE1.
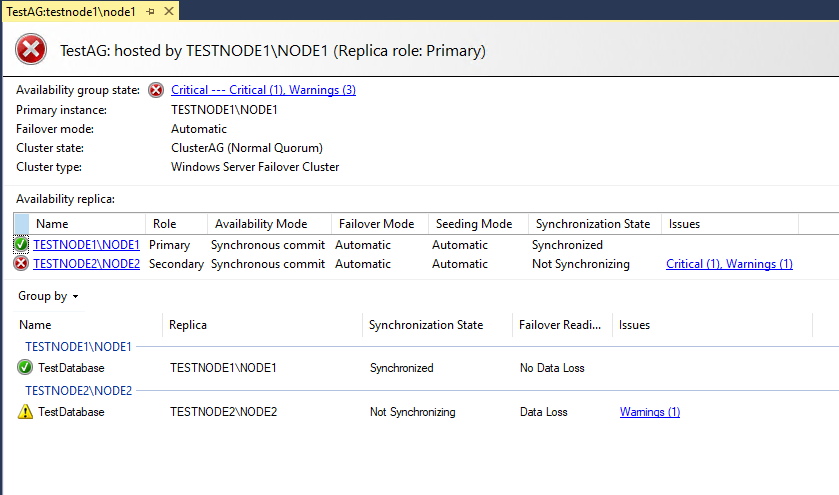
Кластер автоматически перевёл статус реплики testnode1\node1 в primary, так как testnode2\node2 стал недоступен.
Проверим состояние слушателя, потому что соединения клиентов будут поступать именно на него.
В моём случае я успешно соединился со слушателем, но при доступе к базе данных появилась ошибка

Эта ошибка возникла из-за параметра “Required synchronized secondaries to commit”. Так как при настройке мы выставляли это значение в 1, Always On не даёт подключиться к базе данных, потому что у нас осталась всего одна primary реплика.
Установим это значение в 0 и попробуем снова.
Включаем testnode2 и проверяем статус группы.
Статус Primary реплики остался у testnode1, а testnode2 стал вторичной репликой. Данные, которые мы меняли на testnode1 при выключенной testnode2 успешно синхронизировались после включения машины.
На этом тестирование закончено. Мы убедились всё работает корректно и при критическом сбое данные останутся доступны для read/write доступа.
Группы доступности Always On достаточно просты в настройке. Если перед вами стоит задача построить отказоустойчивое решение на базе SQL Server, то группы доступности отлично справятся с этой задачей.
С выпуском SQL Server 2017 и SQL Server 2019 в SQL Server Management Studio 18.x появились настройки Always On, которые раньше были доступны только через T-SQL, поэтому рекомендуется пользоваться последней версией SSMS.
![]() Предыдущая статья Следующая статья
Предыдущая статья Следующая статья ![]()
Что такое SQL Server AlwaysOn? Отличия FCI и AG
SQL Server AlwaysOn — распространенный термин, упоминаемый в различных источниках, но что он действительно означает? В этом совете мы поясним термин SQL Server AlwaysOn и его две основные технологии.
SQL Server AlwaysOn — это маркетинговый термин, который относится к решению с высокой доступностью и аварийным восстановлением, которое было введено при запуске SQL Server 2012.
Если говорить конкретнее, SQL Server AlwaysOn состоит из двух технологий:
- Экземпляры отказоустойчивого кластера(AlwaysOn FCI)
- Группы доступности AlwaysOn (AlwaysOn AG)
Хотя эти технологии имеют сходства, такие как требование отказоустойчивой кластеризации Windows Server (WSFC) в качестве основы для ее реализации, каждая из них является отдельной технологией под зонтиком AlwaysOn.
Экземпляры отказоустойчивого кластера(AlwaysOn FCI)
AlwaysOn FCI требует общего хранилища, такого как iSCSI или Fibre Channel SAN, к которому могут обращаться все узлы в кластере. Существует также возможность использования сторонних инструментов репликации данных, которые могут помочь в требованиях к хранению в случае отсутствия общего хранилища или если вы хотите организовать хранилище на виртуальных машинах или на облаке.
FCI поддерживает многоузловую кластеризацию в подсетях, которая облегчает отказоустойчивость экземпляров SQL Server в центрах обработки данных, но для этого требуется репликация данных в общем хранилище в каждом из центров обработки данных.
AlwaysOn FCI доступен как на SQL Server Standard, так и на Enterprise Edition, но накладывает ограничения на стандартную версию SQL Server, например ограничение на 2 узла.
Когда вы устанавливаете SQL Server, вы выбираете опцию «Новый отказоустойчивый кластер SQL».
Реализация одного сайта с двумя узлами AlwaysOn FCI (с использованием режима кворума Node и Disk Majority) изображена ниже.

Режим кворума помогает определить, какие узлы доступны и какой узел должен быть основным узлом. Благодаря тому, что задействован другой компьютер / объект, он может определить, не потеряна ли связь между машинами, должен ли происходить переход на другой ресурс. Ниже приведены общие примеры режима кворума, которые могут использоваться в конфигурации AlwaysOn FCI.
- Node Majority (большинство узлов)
- Node and Fileshare Majority (большинство узлов и файловый ресурс)
- Node and (symmetrical) Disk Majority (большинство узлов и диск (симметричное хранилище)
Симметричное хранилище подразумевает кластерный диск, который используется совместно всеми узлами WSFC. Это позволяет общему хранилищу быть доступным для всех потенциальных отказоустойчивых узлов в кластере WSFC.
Группы доступности AlwaysOn
AlwaysOn AG не требуют общего дискового хранилища для сервера, на котором размещен SQL Server. Эта технология высокой доступности SQL Server является функцией Enterprise. Это означает, что вы не можете настроить SQL Server Standard Edition на использование AlwaysOn AG с версиями до SQL Server 2016. Теперь есть возможность создать базовую группу доступности со стандартной версией SQL Server 2016, о которой мы расскажем ниже.
Когда вы устанавливаете SQL Server, вы выбираете опцию “Автономная установка нового SQL”
Реализация AlwaysOn AG для HA и DR (с использование режима кворума Node Majority ) показана ниже.

Ниже приведены несколько распространенных примеров режима кворума, используемых в конфигурации AlwaysOn AG.
- Node Majority
- Node and Fileshare Majority
- Node and (Asymmetric) Disk Majority — асимметричное хранилище
Асимметричное хранилище подразумевает, что кластерный диск используется только между подмножеством узлов. Возможность асимметричного диска была впервые представлена на Windows Server 2008. Она позволяет настроить дискретный диск и доступ только для узлов на одном сайте, как правило, на основном.
Новые возможности в SQL Server 2016
Теперь, когда вы поняли различия между AlwaysOn FCI и AlwaysOn AG, поговорим о двух дополнительных разновидностях AlwaysOn AG, представленных SQL Server 2016:
- Базовые группы доступности (AlwaysOn BAG)
- Распределенные группы доступности AlwaysOn DAG)
Базовые группы доступности (AlwaysOn BAG)
Функция AlwaysOn теперь включена в стандартную версию SQL Server 2016 Standard, но она называется AlwaysOn BAG. Она создается и управляется аналогично AG, но, по сравнению с более продвинутым AlwaysOn AG на SQL Server Enterprise Edition, AlwaysOn BAG может использовать только подмножество функций. Пример ограничения — BAG позволяет только иметь две реплики (первичную и вторичную).
AlwaysOn BAG обеспечивает поддержку отказоустойчивости только для одной базы данных, заменяя зеркальное отображение базы данных, которое устарело.
Распределенные группы доступности (AlwaysOn DAG)
AlwaysOn DAG — это слабосвязанные группы AG. AlwaysOn DAG работает поверх двух разных AG, что означает, что они находятся на двух разных WSFC с собственным кворумом и управлением голосованием.
Такая конфигурация позволяет использовать вторичные реплики AG географически удаленно от первичных. Примером использования может быть включение рабочих нагрузок только для чтения для удаленных регионов, избегая при этом любой потенциальной сетевой проблемы на вторичном сайте, которая может повлиять на основной сайт.

Характеристики AlwaysOn FCI и AlwaysOn AG
Каждая из этих двух технологий отличается своей целью. Можно комбинировать AlwaysOn FCI и AlwaysOn AG. Для бизнес-требований может потребоваться локальная высокая доступность в центре обработки данных с использованием AlwaysOn FCI и переадресация сбоя центра обработки данных с использованием AlwaysOn AG. Это просто означает, что решение будет состоять из комбинации общего хранилища и неразделенного хранилища при реализации.
Если вам интересно, какое решение реализовать, приведенная ниже таблица суммирует сходство и различия в характеристиках между SQL Server AlwaysOn FCI и решениями AlwaysOn AG в качестве руководства при оценке SQL Server AlwaysOn
AlwaysOn FCI для HA и DR
AlwaysOn AG для HA и DR
Решение с совместным хранилищем
Решение с неразделенным хранилищем
Уровень экземпляра HA
Лог-серверы, задания агента SQL, сертификаты и другие объекты уровня экземпляра SQL Server находятся в тактическом режиме после отказа
Уровень базы данных HA (может быть одной или нескольких баз данных)
Ручное добавление логинов, заданий агента SQL, сертификатов и других объектов уровня экземпляра SQL Server ко всем вторичным репликам
Защита на уровне экземпляра без избыточности данных
Каждая группа вторичных баз данных AG является избыточной копией первичной
Есть Активные \ пассивные узлы. Нет концепции вторичной базы данных.
Реплика DR может быть активной вторичной для резервного копирования, только для чтения.
Приложение подключается через имя виртуального сервера
Приложение подключается через имя прослушивателя AG
Не поддерживает избыточную копию данных, следовательно, не защищает от сбоя подсистемы ввода-вывода
Защита от сбоя подсистемы ввода-вывода, то есть Автоматический ремонт страницы
Никаких особых требований в отношении моделей восстановления базы данных
Базы данных в AG должна быть в модели восстановления FULL
Другие примечания, касающиеся обоих решений
- Каждое развертывание AlwaysOn — это развертывание WSFC
- И FCI, и AG могут охватывать несколько центров обработки данных, но реализованы по разному.
- Решения могут быть реализованы на физических системах SQL Server или работающих под управлением виртуальных машин
Резюме
Простое упоминание SQL Server AlwaysOn не несет в себе конкретики, оно подразумевает либо AlwaysOn FCI, либо AlwaysOn AG.
AlwaysOn! = Экземпляры отказоустойчивого кластера SQL Server! = Группы доступности
Name already in use
sql-docs / docs / database-engine / availability-groups / windows / overview-of-always-on-availability-groups-sql-server.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
What is an Always On availability group?
This article introduces the [!INCLUDEssHADR] concepts that are central for configuring and managing one or more availability groups in [!INCLUDEssnoversion]. For a summary of the benefits offered by availability groups and an overview of [!INCLUDEssHADR] terminology, see Always On Availability Groups (SQL Server).
An availability group supports a replicated environment for a discrete set of user databases, known as availability databases. You can create an availability group for high availability (HA) or for read-scale. An HA availability group is a group of databases that fail over together. A read-scale availability group is a group of databases that are copied to other instances of SQL Server for read-only workload. An availability group supports one set of primary databases and one to eight sets of corresponding secondary databases. Secondary databases are not backups. Continue to back up your databases and their transaction logs on a regular basis.
[!TIP]
You can create any type of backup of a primary database. Alternatively, you can create log backups and copy-only full backups of secondary databases. For more information, see Active Secondaries: Backup on Secondary Replicas (Always On Availability Groups).
Each set of availability database is hosted by an availability replica. Two types of availability replicas exist: a single primary replica. which hosts the primary databases, and one to eight secondary replicas, each of which hosts a set of secondary databases and serves as a potential failover targets for the availability group. An availability group fails over at the level of an availability replica. An availability replica provides redundancy only at the database level for the set of databases in one availability group. Failovers are not caused by database issues such as a database becoming suspect due to a loss of a data file or corruption of a transaction log.
The primary replica makes the primary databases available for read-write connections from clients. The primary replica sends transaction log records of each primary database to every secondary database. This process — known as data synchronization — occurs at the database level. Every secondary replica caches the transaction log records (hardens the log) and then applies them to its corresponding secondary database. Data synchronization occurs between the primary database and each connected secondary database, independently of the other databases. Therefore, a secondary database can be suspended or fail without affecting other secondary databases, and a primary database can be suspended or fail without affecting other primary databases.
Optionally, you can configure one or more secondary replicas to support read-only access to secondary databases, and you can configure any secondary replica to permit backups on secondary databases.
SQL Server 2017 introduced two different architectures for availability groups. Always On availability groups provide high availability, disaster recovery, and read-scale balancing. These availability groups require a cluster manager. In Windows, the failover clustering feature provides the cluster manager. In Linux, you can use Pacemaker. The other architecture is a read-scale availability group. A read scale availability group provides replicas for read-only workloads but not high availability. In a read-scale availability group, there’s no cluster manager, as failover cannot be automatic.
Deploying [!INCLUDEssHADR] for HA on Windows requires a Windows Server Failover Cluster (WSFC). Each availability replica of a given availability group must reside on a different node of the same WSFC. The only exception is that while being migrated to another WSFC cluster, an availability group can temporarily straddle two clusters.
In an HA configuration, a cluster role is created for every availability group that you create. The WSFC cluster monitors this role to evaluate the health of the primary replica. The quorum for [!INCLUDEssHADR] is based on all nodes in the WSFC cluster regardless of whether a given cluster node hosts any availability replicas. In contrast to database mirroring, there’s no witness role in [!INCLUDEssHADR].
[!NOTE]
For information about the relationship of SQL Server Always On components to the WSFC cluster, see Windows Server Failover Clustering (WSFC) with SQL Server.
The following illustration shows an availability group that contains one primary replica and four secondary replicas. Up to eight secondary replicas are supported, including one primary replica and four synchronous-commit secondary replicas.
To add a database to an availability group, the database must be an online, read-write database that exists on the server instance that hosts the primary replica. When you add a database, it joins the availability group as a primary database, while remaining available to clients. No corresponding secondary database exists until backups of the new primary database are restored to the server instance that hosts the secondary replica (using RESTORE WITH NORECOVERY). The new secondary database is in the RESTORING state until it is joined to the availability group. For more information, see Start Data Movement on an Always On Secondary Database (SQL Server).
Joining places the secondary database into the ONLINE state and initiates data synchronization with the corresponding primary database. Data synchronization is the process by which changes to a primary database are reproduced on a secondary database. Data synchronization involves the primary database sending transaction log records to the secondary database.
[!IMPORTANT]
An availability database is sometimes called a database replica in [!INCLUDEtsql], PowerShell, and SQL Server Management Objects (SMO) names. For example, the term «database replica» is used in the names of the Always On dynamic management views that return information about availability databases: sys.dm_hadr_database_replica_states and sys.dm_hadr_database_replica_cluster_states. However, in SQL Server Books Online, the term «replica» typically refers to availability replicas. For example, «primary replica» and «secondary replica» always refer to availability replicas.
Each availability group defines a set of two or more failover partners known as availability replicas. Availability replicas are components of the availability group. Each availability replica hosts a copy of the availability databases in the availability group. For a given availability group, the availability replicas must be hosted by separate instances of [!INCLUDEssNoVersion] residing on different nodes of a WSFC cluster. Each of these server instances must be enabled for Always On.
A given instance can host only one availability replica per availability group. However, each instance can be used for many availability groups. A given instance can be either a stand-alone instance or a [!INCLUDEssNoVersion] failover cluster instance (FCI). If you require server-level redundancy, use Failover Cluster Instances.
Every availability replica is assigned an initial role-either the primary role or the secondary role, which is inherited by the availability databases of that replica. The role of a given replica determines whether it hosts read-write databases or read-only databases. One replica, known as the primary replica, is assigned the primary role and hosts read-write databases, which are known as primary databases. At least one other replica, known as a secondary replica, is assigned the secondary role. A secondary replica hosts read-only databases, known as secondary databases.
[!NOTE]
When the role of an availability replica is indeterminate, such as during a failover, its databases are temporarily in a NOT SYNCHRONIZING state. Their role is set to RESOLVING until the role of the availability replica has resolved. If an availability replica resolves to the primary role, its databases become the primary databases. If an availability replica resolves to the secondary role, its databases become secondary databases.
The availability mode is a property of each availability replica. The availability mode determines whether the primary replica waits to commit transactions on a database until a given secondary replica has written the transaction log records to disk (hardened the log). [!INCLUDEssHADR] supports two availability modes-asynchronous-commit mode and synchronous-commit mode.
Asynchronous-commit mode
An availability replica that uses this availability mode is known as an asynchronous-commit replica. Under asynchronous-commit mode, the primary replica commits transactions without waiting for acknowledgment from asynchronous-commit secondary replicas to harden their transaction logs. Asynchronous-commit mode minimizes transaction latency on the secondary databases but allows them to lag behind the primary databases, making some data loss possible.
Synchronous-commit mode
An availability replica that uses this availability mode is known as a synchronous-commit replica. Under synchronous-commit mode, before committing transactions, a synchronous-commit primary replica waits for a synchronous-commit secondary replica to acknowledge that it has finished hardening the log. Synchronous-commit mode ensures that once a given secondary database is synchronized with the primary database, committed transactions are fully protected. This protection comes at the cost of increased transaction latency. Optionally, SQL Server 2017 introduced a required synchronized secondaries feature to further increase safety at the cost of latency when desired. The REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT feature can be enabled to require a specified number of synchronous replicas to commit a transaction before a primary replica is allowed to commit.
Types of failover
Within the context of a session between the primary replica and a secondary replica, the primary and secondary roles are potentially interchangeable in a process known as failover. During a failover, the target secondary replica transitions to the primary role, becoming the new primary replica. The new primary replica brings its databases online as the primary databases, and client applications can connect to them. When the former primary replica is available, it transitions to the secondary role, becoming a secondary replica. The former primary databases become secondary databases and data synchronization resumes.
Three forms of failover exist-automatic, manual, and forced (with possible data loss). The form or forms of failover supported by a given secondary replica depends on its availability mode, and, for synchronous-commit mode, on the failover mode on the primary replica and target secondary replica, as follows.
Synchronous-commit mode supports two forms of failover-planned manual failover and automatic failover, if the target secondary replica is currently synchronized with the primary replica. The support for these forms of failover depends on the setting of the failover mode property on the failover partners. If failover mode is set to «manual» on either the primary or secondary replica, only manual failover is supported for that secondary replica. If failover mode is set to «automatic» on both the primary and secondary replicas, both automatic and manual failover are supported on that secondary replica.
Planned manual failover (without data loss)
A manual failover occurs after a database administrator issues a failover command and causes a synchronized secondary replica to transition to the primary role (with guaranteed data protection) and the primary replica to transition to the secondary role. A manual failover requires that both the primary replica and the target secondary replica are running under synchronous-commit mode, and the secondary replica must already be synchronized.
Automatic failover (without data loss)
An automatic failover occurs in response to a failure that causes a synchronized secondary replica to transition to the primary role (with guaranteed data protection). When the former primary replica becomes available, it transitions to the secondary role. Automatic failover requires that both the primary replica and the target secondary replica are running under synchronous-commit mode with the failover mode set to «Automatic». In addition, the secondary replica must already be synchronized, have WSFC quorum, and meet the conditions specified by the flexible failover policy of the availability group.
[!IMPORTANT]
SQL Server Failover Cluster Instances (FCIs) do not support automatic failover by availability groups, so any availability replica that is hosted by an FCI can only be configured for manual failover.
[!NOTE]
Note that if you issue a forced failover command on a synchronized secondary replica, the secondary replica behaves the same as for a planned manual failover.
Under asynchronous-commit mode, the only form of failover is forced manual failover (with possible data loss), typically called forced failover. Forced failover is considered a form of manual failover because it can only be initiated manually. Forced failover is a disaster recovery option. It is the only form of failover that is possible when the target secondary replica is not synchronized with the primary replica.
You can provide client connectivity to the primary replica of a given availability group by creating an availability group listener. An availability group listener provides a set of resources that is attached to a given availability group to direct client connections to the appropriate availability replica.
An availability group listener is associated with a unique DNS name that serves as a virtual network name (VNN), one or more virtual IP addresses (VIPs), and a TCP port number. For more information, see Availability Group Listeners, Client Connectivity, and Application Failover (SQL Server).
[!TIP]
If an availability group possesses only two availability replicas and is not configured to allow read-access to the secondary replica, clients can connect to the primary replica by using a database mirroring connection string. This approach can be useful temporarily after you migrate a database from database mirroring to [!INCLUDEssHADR]. Before you add additional secondary replicas, you will need to create an availability group listener for the availability group and update your applications to use the network name of the listener.
Active secondary replicas
[!INCLUDEssHADR] supports active secondary replicas. Active secondary capabilities include support for:
Performing backup operations on secondary replicas
The secondary replicas support performing log backups and copy-only backups of a full database, file, or filegroup. You can configure the availability group to specify a preference for where backups should be performed. It is important to understand that the preference is not enforced by SQL Server, so it has no impact on ad-hoc backups. The interpretation of this preference depends on the logic, if any, that you script into your back jobs for each of the databases in a given availability group. For an individual availability replica, you can specify your priority for performing backups on this replica relative to the other replicas in the same availability group. For more information, see Active Secondaries: Backup on Secondary Replicas (Always On Availability Groups).
Read-only access to one or more secondary replicas (readable secondary replicas)
Any secondary availability replica can be configured to allow only read-only access to its local databases, though some operations aren’t fully supported. This will prevent read-write connection attempts to the secondary replica. It is also possible to prevent read-only workloads on the primary replica by only allowing read-write access. This will prevent read-only connections from being made to the primary replica. For more information, see Active Secondaries: Readable Secondary Replicas (Always On Availability Groups).
If an availability group currently possesses an availability group listener and one or more readable secondary replicas, [!INCLUDEssNoVersion] can route read-intent connection requests to one of them (read-only routing). For more information, see Availability Group Listeners, Client Connectivity, and Application Failover (SQL Server).
The session-timeout period is an availability-replica property that determines how long connection with another availability replica can remain inactive before the connection is closed. The primary and secondary replicas ping each other to signal that they’re still active. Receiving a ping from the other replica during the timeout period indicates that the connection is still open, and that the server instances are communicating. On receiving a ping, an availability replica resets its session-timeout counter on that connection.
The session-timeout period prevents either replica from waiting indefinitely to receive a ping from the other replica. If no ping is received from the other replica within the session-timeout period, the replica times out. Its connection is closed, and the timed-out replica enters the DISCONNECTED state. Even if a disconnected replica is configured for synchronous-commit mode, transactions won’t wait for that replica to reconnect and resynchronize.
The default session-timeout period for each availability replica is 10 seconds. This value is user-configurable, with a minimum of 5 seconds. Generally, we recommend that you keep the time-out period at 10 seconds or greater. Setting the value to less than 10 seconds creates the possibility of a heavily loaded system declaring a false failure.
[!NOTE]
In the resolving role, the session-timeout period does not apply because pinging does not occur.
Automatic page repair
Each availability replica tries to automatically recover from corrupted pages on a local database by resolving certain types of errors that prevent reading a data page. If a secondary replica cannot read a page, the replica requests a fresh copy of the page from the primary replica. If the primary replica cannot read a page, the replica broadcasts a request for a fresh copy to all the secondary replicas and gets the page from the first to respond. If this request succeeds, the unreadable page is replaced by the copy, which usually resolves the error.
Создание группы доступности AlwaysON на основе кластера Failover
Коротко о главном: каждый узел группы доступности должен быть членом отказоустойчивого кластера Windows. Каждый экземпляр SQL Server может иметь несколько групп доступности. В каждой группе доступности может быть до 8 вторичных реплик.
Что это и зачем требуется
Группы доступности AlwaysOn — это решение высокой доступности и аварийного восстановления, является альтернативой зеркальному отображению баз данных на уровне предприятия. Если БД не справляется с потоком запросов или есть опасения, что при сбое на сервере пропадут ценные данные, есть смысл использовать это решение. Группы доступности AlwaysOn могут отвечать за выполнение сразу двух задачи: высокий уровень доступности обеспечивает бесперебойную работу системы, а нагрузка по чтению из БД частично выполняется на репликах.
Создание группы доступности может понадобиться, если вам необходимо:
Создать избыточную доступность баз данных (в этом случае рекомендуем располагать ноды в геоудалённых дата-центрах, т.к. избыточная доступность предполагает доступность БД при любых технических неполадках на любой из нод);
Увеличить быстродействие ответов баз данных по принципу горизонтального расширения (в этом случае одна нода в кластере является мастером, осуществляющей операции записи и чтения, остальные ноды работают в режиме слушателей и позволяют считывать данные при запросах обращения)
При отказе основой реплики, кластер проголосует за новую основную реплику и Always On переведёт одну из вторичных реплик в статус основной. Так как при работе с Always On пользователи соединяются с прослушивателем кластера (или Listener, то есть специальный IP-адрес кластера и соответствующее ему DNS-имя), то возможность выполнять write-запросы полностью восстановится. Прослушиватель также отвечает за балансировку select-запросов между вторичными репликами.
Подготовка инфраструктуры
Сначала необходимо создать виртуальную машину и пользователей. В VDC создаем 3 ВМ, даём имена согласно ролей, выполняем настройки кастомизации.

После этого переходим к этапу настройки контроллера домена. Устанавливаем роли AD, DNS, Failover Cluster.
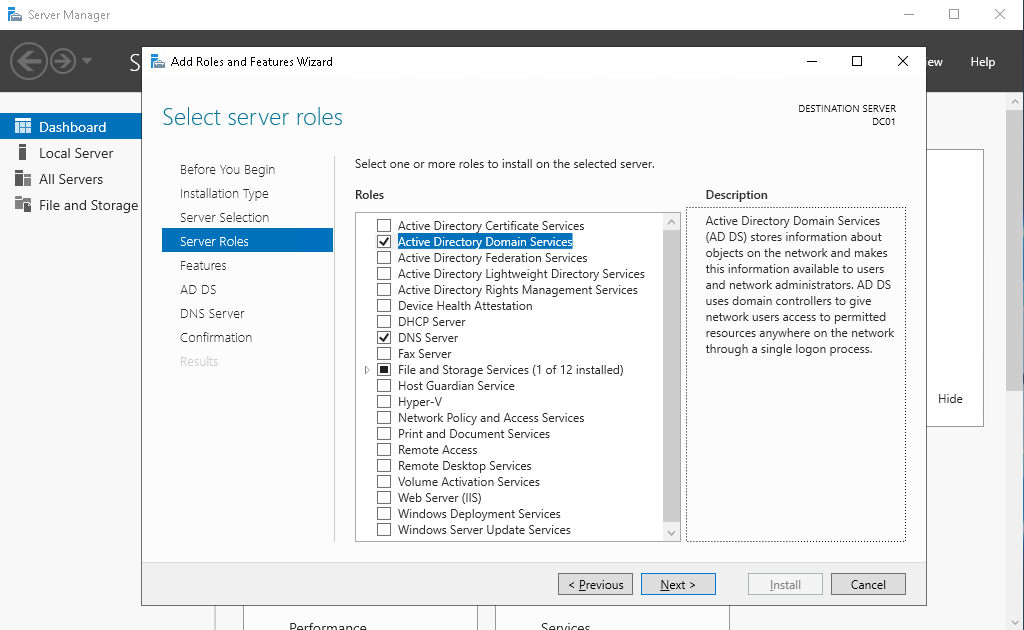
Устанавливаем роль контроллера домена

Создаём в AD компьютеры ND01 и ND02.
На ВМ ND01 и ND02 ставим компонент Failover Cluster
Теперь переходим к созданию кластера отказоустойчивости. На контроллере домена DC01 создаём кластер отказоустойчивости и добавляем в него наши ноды.
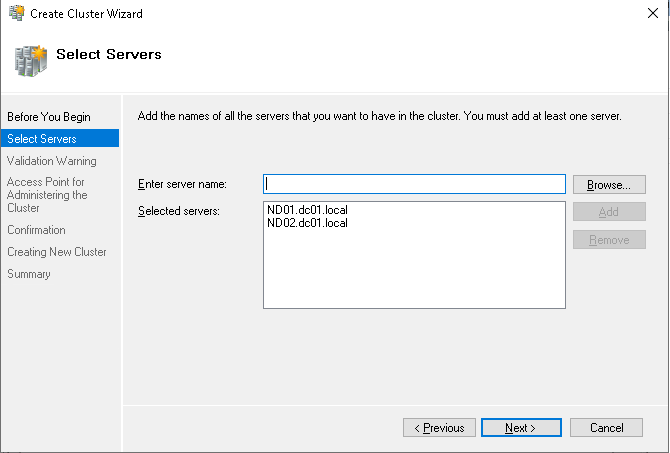
Даём имя кластеру.
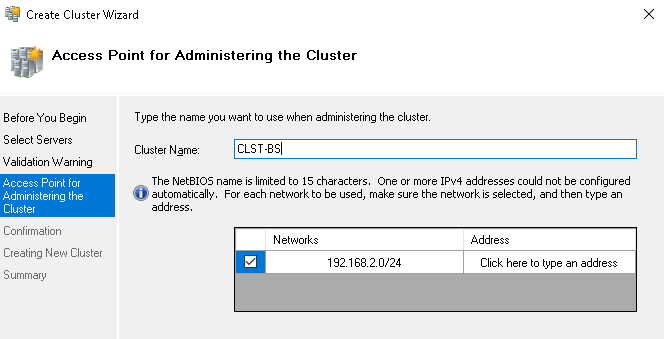
При создании кластера снимаем галочку с добавления массивов в каталог. Эту настройку можно сделать позже.
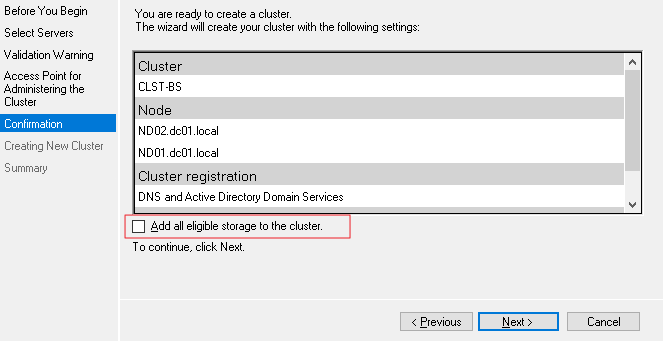
Создание кластера завершено.
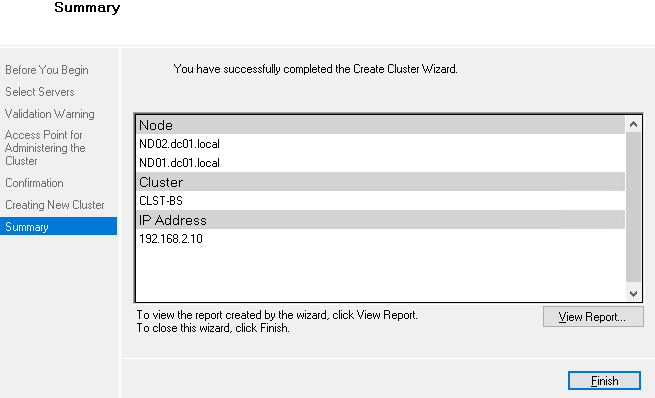
Создание свидетеля (Quorum Witness Share)
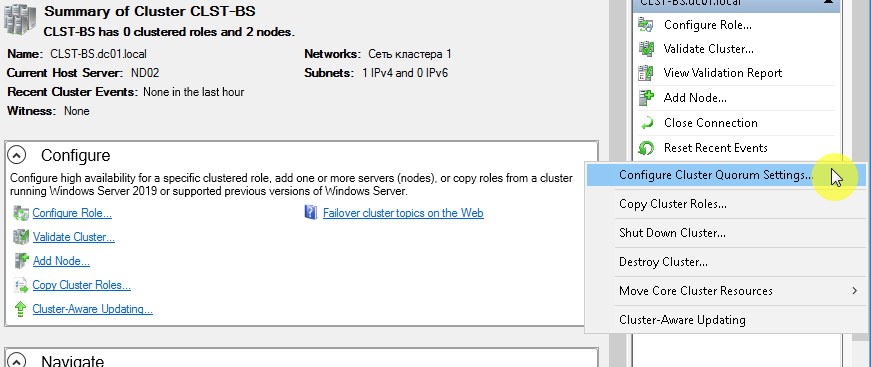
Переходим к настройке кворума. Для этого выбираем пункты, которые указаны на скриншоте.
В конфигурации свидетеля кворума указываем file share.


После этого необходимо создать директорию на сервере, не участвующем в кластере, но имеющим общую сеть с кластером. После создания такой директории и добавления шары для доступа к ней нод из кластера, в настройке свидетеля нужно указать UNC путь.
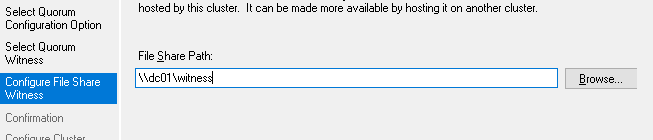
Если после создания свидетеля у вас возникнет ошибка как на примере ниже,

…то в этом случае необходимо проверить настройки прав доступа к сетевой директории, указанной в настройках свидетеля.
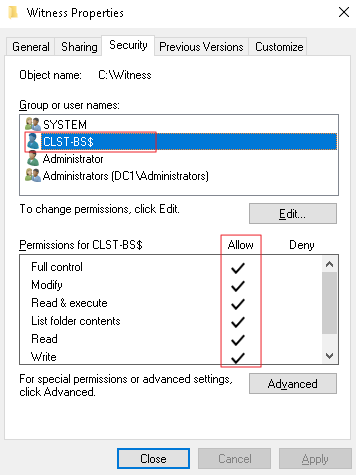
Переходим к установке MS SQL 2015 Enterprise на ноды в кластере. Перед установкой модуля необходимо отключить брандмауэр на работу в доменной сети на всех ВМ, участвующих в кластере.
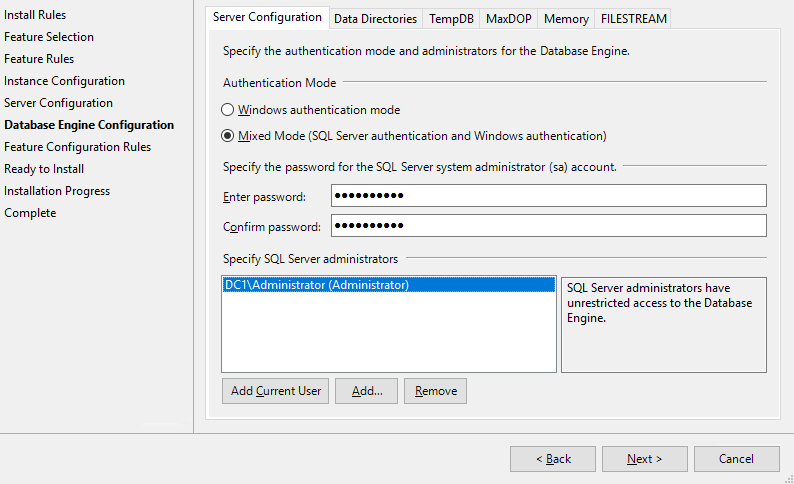
Устанавливаем MS SQL в standalone режиме, без дополнительных модулей. При выборе пользователя для примера берём Администратора доменной сети. Для боевых серверов рекомендуем сделать отдельного пользователя. Наверное, не нужно объяснять, почему это важно.
Затем необходимо установить SQL Management Studio на обе ноды в кластере.
Добавление тестовой базы данных в MSSQL
На ноде ND01 устанавливаем тестовый образец базы данных. Имя тестовой БД будет Bike-Store. Тестовая БД взята отсюда.
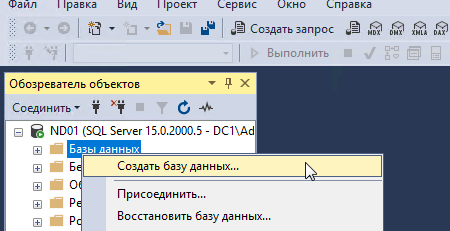
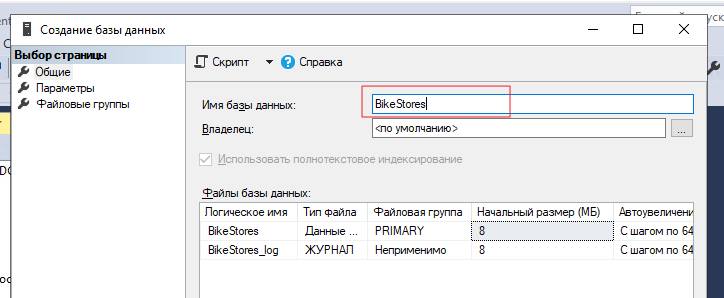
После установки БД выделяем созданную базу данных, после чего выбираем файл БД при помощи комбинации Ctrl+O.
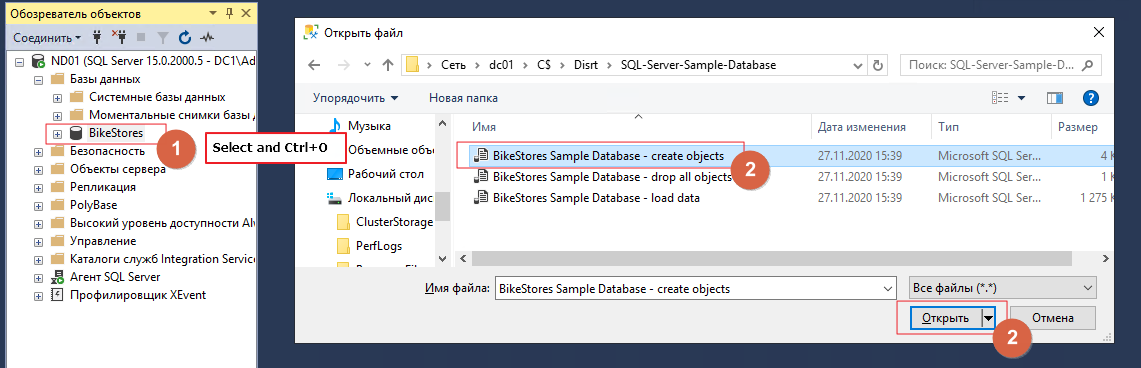
После открытия файла нажимаем «Выполнить»
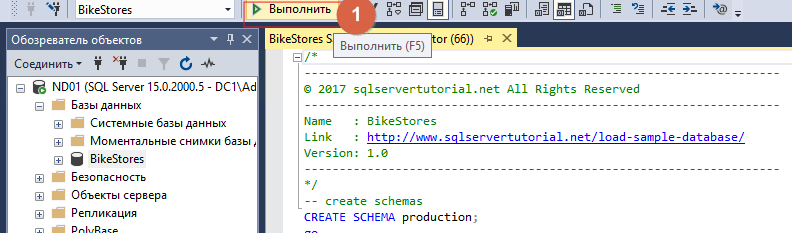
Когда добавили новую базу, необходимо наполнить её. Для этого открываем файл BikeStores Sample Database — load data.sql и добавляем его таким же методом. В конце операции должно появиться сообщение, что «Запрос успешно выполнен».
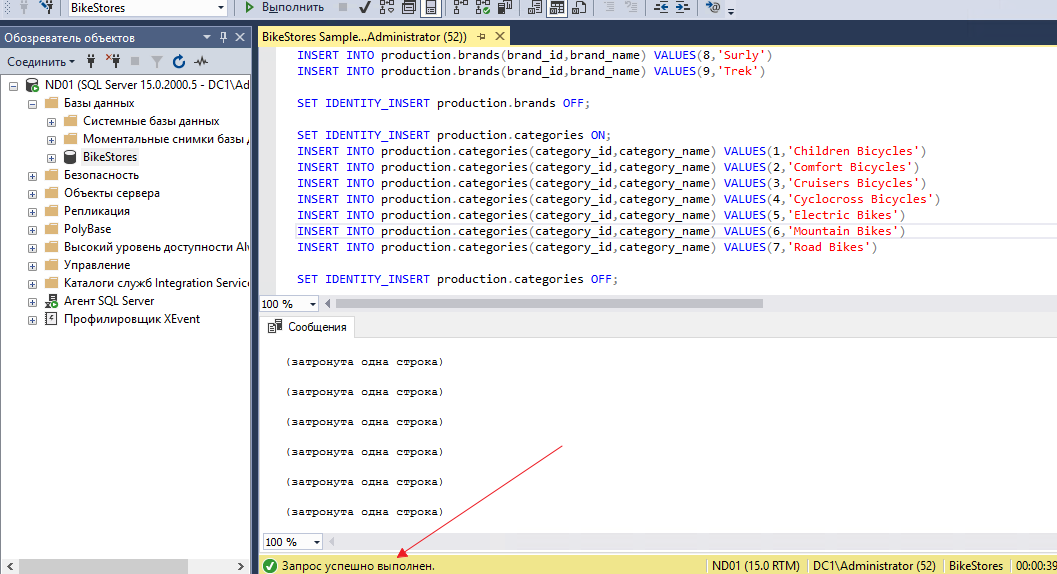
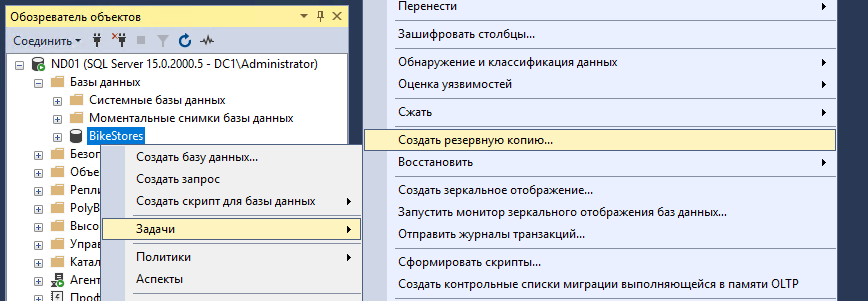
Важно! Перед развертыванием группы доступности обязательно делаем резервную копию БД, в противном случае не получится создать группу доступности
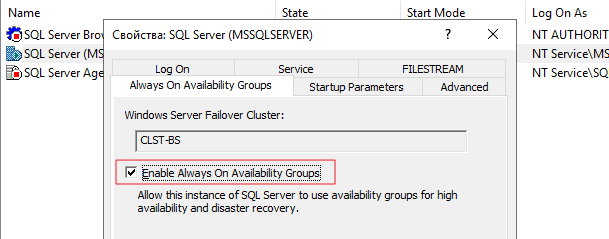
Настройка Always On в MS SQL Server
Для каждой ноды необходимо включить поддержку схемы AlwaysON в SQL Server Configuration Manager в свойствах экземпляра.
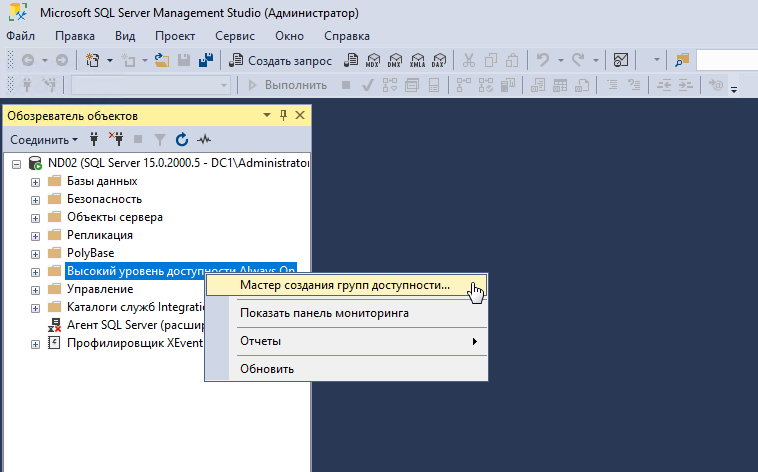
На ноде ND01 В SQL Server Management Studio выберите узел «Always On High Availability» и запустите мастер настройки группы доступности (New Availability Group Wizard).
Присваиваем имя нашей группе доступности: BikeStores-AG
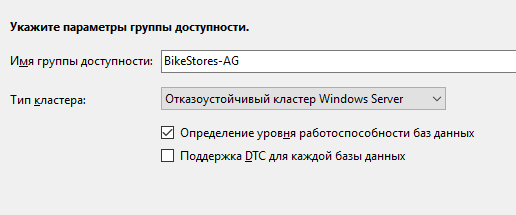
Нажмите «Добавить реплику» и подключитесь к второму серверу SQL. Таким образом можно добавить до 8 серверов.
Ключевые параметры
Исходная роль – роль реплики на момент создания группы. Может быть Primary и Secondary;
Автоматический переход – если база данных станет недоступна, Always On переведёт primary роль на другую реплику. Отмечаем чекбокс;
Режим доступности – возможно выбрать Synchronous Commit или Asynchronous Commit. При выборе синхронного режима транзакции, поступающие на primary реплику, будут отправлены на все остальные вторичные реплики с синхронным режимом. Primary реплика завершит транзакцию только после того, как реплики запишут транзакцию на диск. Таким образом исключается возможность потери данных при сбое primary реплики. При асинхронном режиме основная реплика сразу записывает изменения, не дожидаясь ответа от вторичных реплик;
Вторичная реплика для чтения – параметр, задающий возможность делать select-запросы к вторичным репликам. При значении yes, клиенты даже при соединении без ApplicationIntent=readonly смогут получить read-only доступ;
Для фиксации требуются синхронизированные получатели – число синхронизированных вторичных реплик для завершения транзакции. Нужно выставлять в зависимости от количества реплик. Имейте в виду, что, если вторичных синхронизированных реплик станет меньше указанного числа (например, при аварии), базы данных группы доступности станут недоступны даже для чтения.
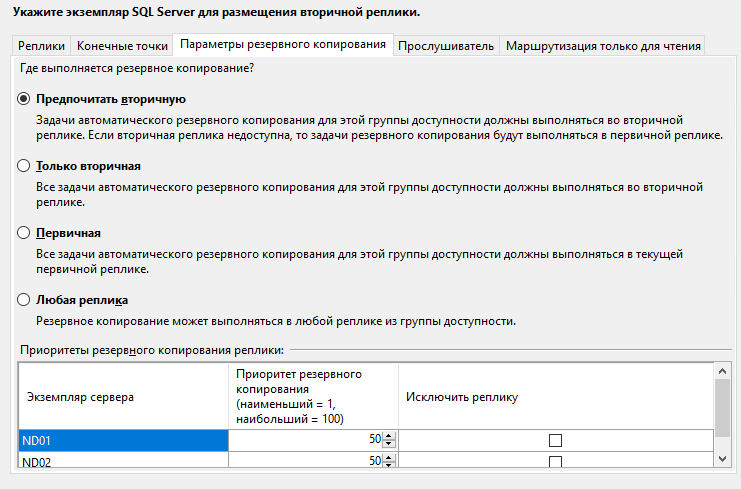
На вкладке Параметры резервного копирования можно выбрать откуда будут делаться бекапы. Оставляем всё по умолчанию – Предпочитать вторичную.
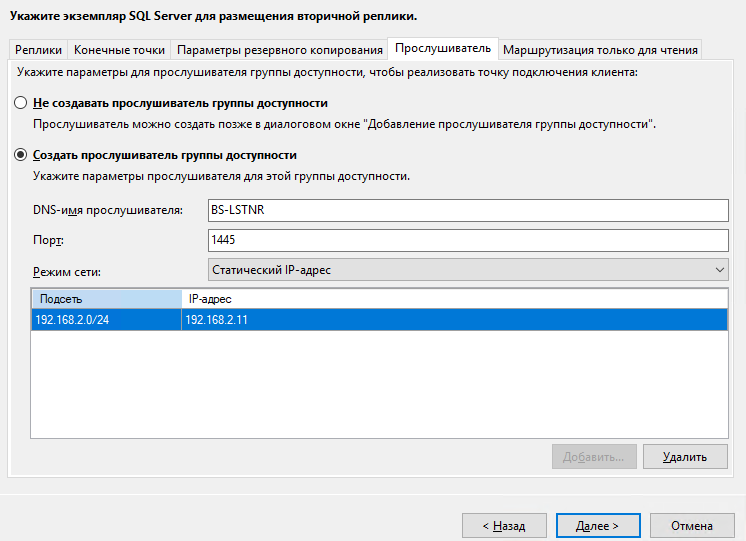
Указываем имя слушателя группы доступности, порт и IP-адрес.
Если все тесты во время окончания прошли успешно, то нажимаем кнопку «Далее».

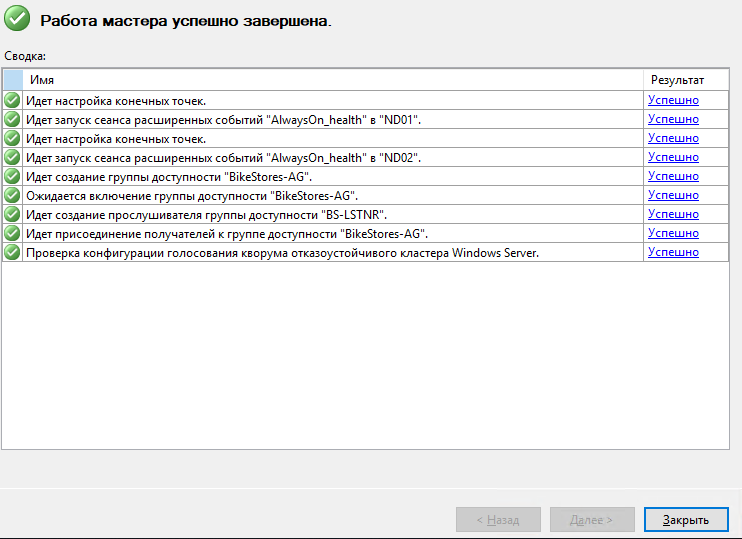
На этом первичная настройка группы доступности AlwaysON завершена. Вы можете провести тесты отказоустойчивости, попеременно отключая каждую ноду в кластере, а также давая простые запросы select, insert.
Надеемся, наша инструкция по создании групп доступности поможет вам обеспечить надлежащий уровень работоспособности вашей ИТ-инфраструктуры. В дальнейшем мы планируем выпустить и другие варианты сценариев. Если вам интересны какие-то нюансы – напишите о них в комментариях. Спасибо за внимание!
В России стартовала распродажа «Киберпонедельник-2021». Мы тоже решили принять участие в этой акции, и на три дня открыли бесплатный доступ к видеокурсу «Управление виртуальным дата центром и сетями в vCloud Director (VMware)» специально для тех, кто хочет разобраться в этой теме и научиться управлять облачной инфраструктурой.
В результате вы и ваши сотрудники сможете эффективнее использовать облачные платформы и больше не будете не путаться при работе с виртуальными машинами.
Курс уже получил 91 оценок от 366 студентов, средняя оценка — 4,5. Сейчас он снова бесплатно доступен на Udemy! Регистрируйтесь и учитесь!
Что ещё интересного есть в блоге Cloud4Y
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу.