SQL Server Statistics and how to perform Update Statistics in SQL

This article gives a walk-through of SQL Server Statistics and different methods to perform SQL Server Update Statistics.
Introduction
SQL Server statistics are essential for the query optimizer to prepare an optimized and cost-effective execution plan. These statistics provide distribution of column values to the query optimizer, and it helps SQL Server to estimate the number of rows (also known as cardinality). The query optimizer should be updated regularly. Improper statistics might mislead query optimizer to choose costly operators such as index scan over index seek and it might cause high CPU, memory and IO issues in SQL Server. We might also face blocking, deadlocks that eventually causes trouble to the underlying queries, resources.
Options to view SQL Server statistics
We can view SQL Server statistics for an existing object using both SSMS and the T-SQL method.
SSMS to view SQL Server Statistics
Connect to a SQL Server instance in SSMS and expand the particular database. Expand the object ( for example, HumanResources.Employee), and we can view all available statistics under the STATISTICS tab.
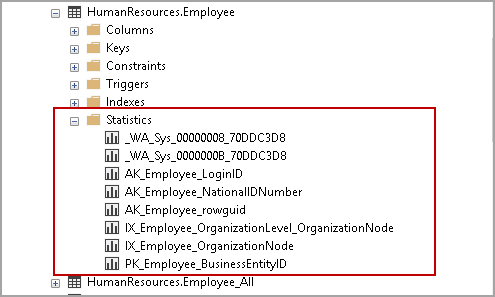
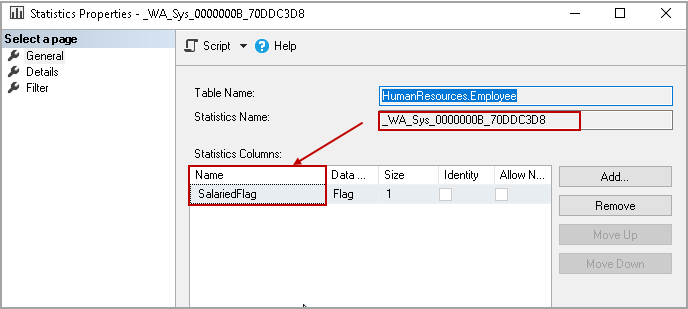
We can get details about any particular statistics as well. Right-click on the statistics and go to properties.
It opens the statistics properties and shows the statistics columns and last update date for the particular statistics.
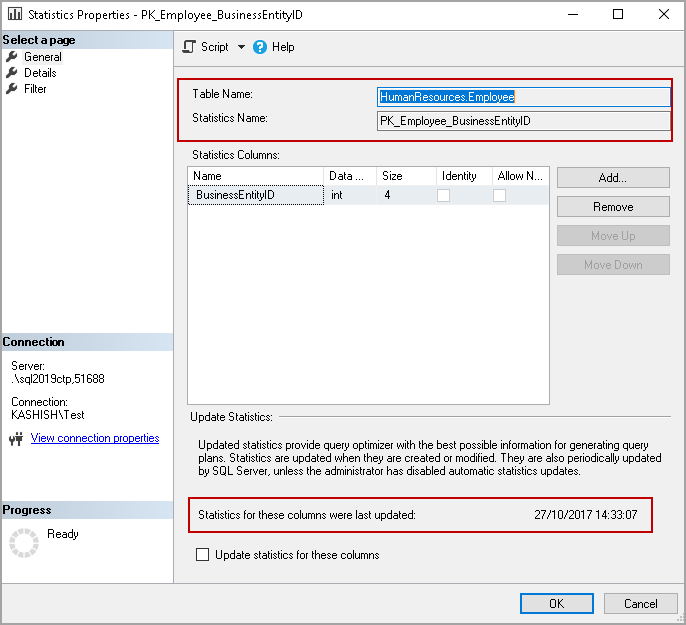
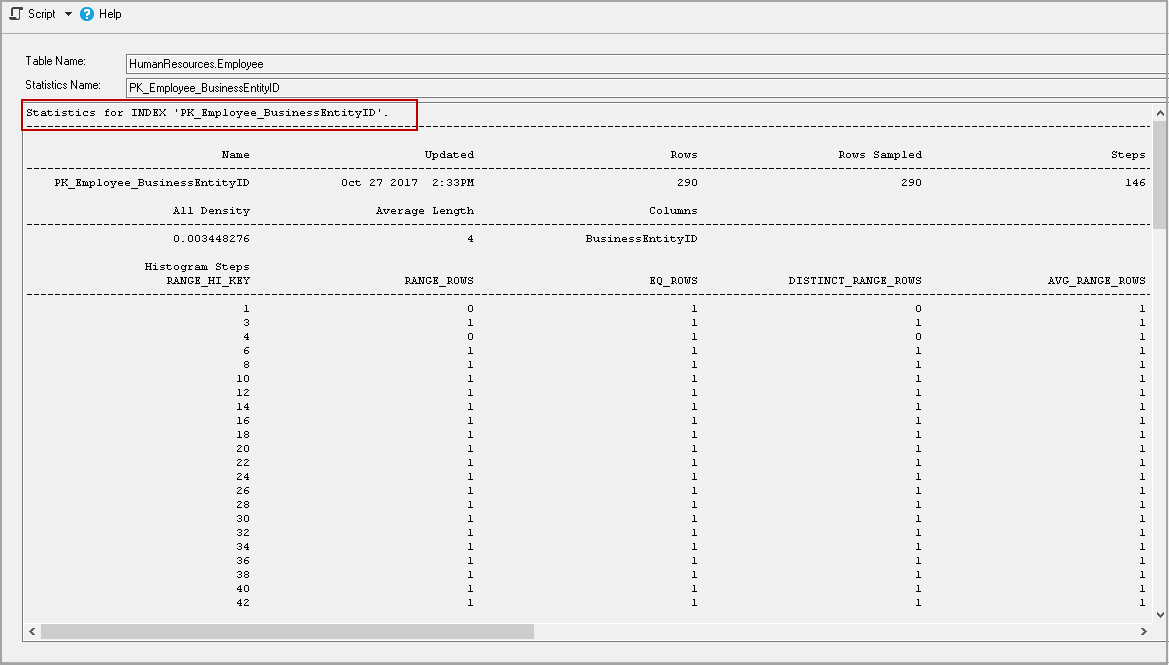
Click on the Details, and it shows the distribution of values and the frequency of each distinct value occurrence (histogram) for the specified object.
T-SQL to view SQL Server Statistics
We can use DMV sys.dm_db_stats_properties to view the properties of statistics for a specified object in the current database.
Execute the following query to check the statistics for HumanResources.Employee table.

- Stats_ID: It is the unique ID of the statistics object
- Name: It is the statistics name
- Last_updated: It is the date and time of the last statistics update
- Rows: It shows the total number of rows at the time of the last statistics update
- Rows_sampled: It gives the total number of sample rows for the statistics
- Unfiltered_rows: In the screenshot, you can see both rows_sampled and unfiltered_rows value the same because we did not use any filter in the statistics
- Modification_counter: It is a vital column to look. We get the total number of modifications since the last statistics update
The different methods to perform SQL Server update Statistics
SQL Server provides different methods at the database level to update SQL Server Statistics.
Right-click on the database and go to properties. In the database properties, we can view statistics options under the Automatic tab.
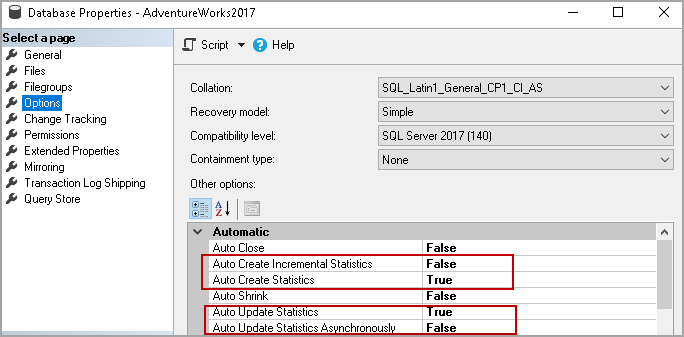
Auto Create Statistics
SQL Server automatically creates statistics on the individual columns for the query predicate to improve the cardinality estimate and prepare a cost-effective execution plan.
Auto Create Statistics name starts with _WA
Use the following query to identify statistics auto-created by SQL Server.

Auto-created SQL Server statistics are single column statistics
Auto Create Incremental Statistics
Starting from SQL Server 2014, we have a new option Auto-Create Incremental Statistics. SQL Server requires scanning the entire table for SQL Server update statistics, and it causes issues for the large tables. It is also valid for a table with partitioning as well. We can use this feature to update only the partition that we require to update. By default, Auto Create Incremental is disabled for individual databases. You can go through Introducing SQL Server Incremental Statistics for Partitioned Tables to get more knowledge on incremental statistics.
Auto Update Statistics
We regularly perform DML operations such as insert, update, delete and such operations change the data distribution or histogram value. Due to these operations, statistics might be out of date, and it might cause issues with the query optimizer efficiency. By default, the SQL Server database has an option Auto Update Statistics true.
With this Auto Update Statistics option, query optimizer updates the SQL Server update statistics when the statistics are out of date. SQL Server uses the following method to update statistics automatically.
SQL Server 2014 or before
Number of rows at the time of statistics creation
Auto Update Statistics
Update statistics for every 500 modifications
Update statistics for every 500 + 20 percent modifications
For the large tables, we require to update 20% of a row to auto-update the statistics. For example, a table with 1 million rows requires 20,000 rows updates. It might not be suitable for the query optimizer to generate an efficient execution plan. SQL Server 2016 onwards, it uses dynamic statistics update threshold, and it adjusts automatically according to the number of rows in the table.
Threshold = √((1000)*Current table cardinality)
For example, a table with one million rows we can use the formula to calculate the number of updates after which SQL Server will automatically update statistics.
Threshold = √(1000*1000000) = 31622
SQL Server updates the statistics after the approx. 31622 modifications in the object.
- Note: the database compatibility level should be 130 or above to use this dynamic threshold statistics calculations.
Auto Update Statistics Asynchronously
SQL Server uses synchronous mode to update the statistics. If query optimizer finds out of date statistics, it updates the SQL Server Statistics first and then prepares the execution plan according to the recently updated statistics.
If we enable the Auto Update Statistics Asynchronously, SQL Server does not wait to update the statistics. Instead, it executes the query with existing statistics and initiates update statistics requests’ in parallel. The next executed query takes the benefit of the updated statistics. Since SQL Server does not wait for the updated statistics, we also call it Asynchronous mode statistics.
Manually Update Statistics
In the previous section, we learned that SQL Server automatically updates the out-of-date statistics. We can also manually update the statistics for improving the query execution plan and performance on a requirement basis. We can use the UPDATE STATISTICS or Sp_Update stored procedure to update SQL Server statistics.
Let’s use the UPDATE STATISTICS command and its various options to update SQL Server statistics.
Name already in use
azure-docs.ru-ru / articles / synapse-analytics / sql-data-warehouse / sql-data-warehouse-tables-statistics.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents
Copy raw contents
Copy raw contents
Статистика таблиц для выделенного пула SQL в Azure синапсе Analytics
В этой статье вы найдете рекомендации и примеры создания и обновления статистики оптимизации запросов для таблиц в выделенном пуле SQL.
Для чего используется статистика?
Чем более выделенный пул SQL знает о ваших данных, тем быстрее она может выполнять запросы к ней. После загрузки данных в выделенный пул SQL сбор статистики по данным является одним из наиболее важных вещей, которые можно выполнить для оптимизации запросов.
Оптимизатор запросов выделенного пула SQL является оптимизатором на основе затрат. Он сравнивает стоимость разных планов запроса, а затем выбирает план с наименьшей стоимостью. В большинстве случаев он выбирает план, который выполняется быстрее всего.
Например, если оптимизатор вычислит, что дата, указанная в фильтре запроса, вернет одну строку, будет выбран один план. Если он вычислит, что выбранная дата вернет 1 000 000 строк, будет возвращен другой план.
Автоматическое создание статистики
Если параметр Database AUTO_CREATE_STATISTICS включен, выделенный пул SQL анализирует входящие запросы пользователей на отсутствие статистики.
Если она отсутствует, оптимизатор запросов создает статистику по отдельным столбцам в предикате запроса или условии соединения, чтобы улучшить оценку кратности для плана запроса.
[!NOTE] Автоматическое создание статистики в настоящее время включено по умолчанию.
Чтобы проверить, настроен ли выделенный пул SQL, AUTO_CREATE_STATISTICS настроить, выполнив следующую команду:
Если в выделенном пуле SQL не настроен AUTO_CREATE_STATISTICS, рекомендуется включить это свойство, выполнив следующую команду:
Эти инструкции активируют автоматическое создание статистики:
- SELECT
- INSERT SELECT
- CTAS
- UPDATE
- DELETE
- EXPLAIN, если они содержат операцию соединения или обнаружено наличие предиката.
[!NOTE] Автоматическое создание статистики не выполняется для временных и внешних таблиц.
Автоматическое создание статистики выполняется синхронно, поэтому, если статистика для столбцов отсутствует, возможно небольшое замедление выполнения запросов. Время создания статистики для одного столбца зависит от размера таблицы.
Чтобы избежать ощутимого замедления, убедитесь, что сначала создается статистика, выполняя рабочую нагрузку теста производительности перед профилированием системы.
[!NOTE] Создание статистики будет зарегистрировано в sys.dm_pdw_exec_requests в другом контексте пользователя.
При автоматическом создании статистики используется следующий формат: WA_Sys<8-разрядный идентификатор столбца в шестнадцатеричном формате>_<8-разрядный идентификатор таблицы в шестнадцатеричном формате>. Вы можете просмотреть статистику, которая уже была создана, выполнив команду DBCC SHOW_STATISTICS :
Table_name — это имя таблицы, содержащей статистику для вывода. Эта таблица не может быть внешней таблицей. Аргумент target — имя целевого индекса, статистики или столбца, для которого нужно отобразить статистические данные.
Лучше всего обновлять статистику в столбцах дат каждый день, когда добавляются новые даты. Каждый раз, когда новые строки загружаются в выделенный пул SQL, добавляются новые даты загрузки или даты транзакций. Эти дополнения изменяют распределение данных и делают статистику устаревшей.
Статистика по столбцу страны или региона в таблице клиентов может никогда не обновляться, так как распределение значений обычно не изменяется. Если предположить, что распределение между клиентами постоянно, добавление новых строк в вариант таблицы не изменит распределение данных.
Однако если выделенный пул SQL содержит только одну страну или регион, и вы перенесете данные из новой страны или региона, что приведет к хранению данных из нескольких стран или регионов, необходимо обновить статистику по столбцу страна или регион.
Ниже приведены рекомендации по обновлению статистики.
| Частота обновления статистики | Консервативная: Ежедневно После загрузки или преобразования данных |
| Выборка | Если менее 1 млрд строк, используйте выборку по умолчанию (20 %). Если строк более 1 000 000 000, используйте выборку в 2 %. |
Один из первых вопросов, задаваемых при устранении неполадок запроса: Актуальна ли статистика?
На этот вопрос невозможно ответить, исходя только из возраста данных. Актуальный объект статистики может быть старым, если исходные данные существенно не менялись. Если количество строк или распределение значений для столбца значительно изменяется, то в этот момент необходимо обновить статистику.
Динамическое административное представление не позволяет определить, изменились ли данные в таблице с момента последнего обновления статистики. Следующие два запроса могут помочь определить, устарела ли статистика.
Запрос 1: Найдите разницу между числом строк из статистики (stats_row_count) и фактическим числом строк (actual_row_count).
Запрос 2: Выясните возраст статистики, проверив время последнего обновления статистики в каждой таблице.
[!NOTE] Если распределение значений для столбца существенно изменилось, то статистику необходимо обновить, независимо от времени ее последнего обновления.
Для столбцов даты в выделенном пуле SQL, например, обычно требуется частое обновление статистики. Каждый раз, когда новые строки загружаются в выделенный пул SQL, добавляются новые даты загрузки или даты транзакций. Эти дополнения изменяют распределение данных и делают статистику устаревшей.
И наоборот, статистика по столбцу пола в таблице клиентов может никогда не обновляться. Если предположить, что распределение между клиентами постоянно, добавление новых строк в вариант таблицы не изменит распределение данных.
Если выделенный пул SQL содержит только один пол, а новое требование дает несколько пола, то необходимо обновить статистику по столбцу пола.
Дополнительные сведения можно получить в общем руководстве по статистике.
Реализация управления статистикой
Часто рекомендуется расширять процесс загрузки данных, чтобы гарантировать, что статистика будет обновлена в конце нагрузки, чтобы избежать/сокращать блокировку или состязание за ресурсы между параллельными запросами.
Загрузка данных происходит, когда таблицы часто меняют свой размер и (или) распределение значений. Загрузка данных — это логическое место для реализации некоторых процессов управления.
Ниже приведены основные принципы обновления статистики.
- Убедитесь, что для каждой загружаемой таблицы обновляется по крайней мере один объект статистики. Тогда при обновлении статистики обновляется информация о размере таблицы (число строк и страниц).
- Сосредоточьтесь на столбцах, участвующих в предложениях JOIN, GROUP BY, ORDER BY и DISTINCT.
- Рекомендуется чаще обновлять столбцы «с возрастающим порядком ключа», например даты транзакций, потому что эти значения не будут включены в гистограмму статистики.
- Рекомендуется реже обновлять столбцы со статическим распределением.
- Помните, что каждый объект статистики обновляется последовательно. Просто реализовать UPDATE STATISTICS <TABLE_NAME> может быть не идеальным решением, особенно для обширных таблиц с большим количеством объектов статистики.
Дополнительные сведения см. в разделе об оценке кратности.
Примеры: Создание статистики
Эти примеры показывают, как использовать различные параметры для создания статистики. Параметры, которые можно использовать для каждого столбца, зависят от характеристик данных и того, как столбец будет использован в запросах.
Создание одностолбцовой статистики с параметрами по умолчанию
Чтобы создать одностолбцовую статистику, достаточно указать имя объекта статистики и имя столбца.
В этом синтаксисе все параметры используются по умолчанию. По умолчанию при создании статистики используется выборка 20 процентов таблицы.
Создание одностолбцовой статистики путем проверки всех строк
В большинстве случаев достаточно использовать частоту выборки по умолчанию, 20 процентов. Однако вы можете настроить частоту выборки.
Для выборки всей таблицы используйте следующий синтаксис:
Создание одностолбцовой статистики с указанием размера выборки
В качестве альтернативы можно указать размер выборки в процентах:
Создание одностолбцовой статистики только для некоторых строк
Можно также создать статистику для части строк в таблице. Это называется отфильтрованной статистикой.
Например, отфильтрованную статистику можно использовать при планировании запроса определенной секции большой секционированной таблицы. Создавая статистику только по значениям секции, можно повысить точность статистики и, таким образом, увеличить производительность запросов.
Этот пример создает статистику по диапазону значений. Значения можно легко определить для сопоставления с диапазоном значений в секции.
[!NOTE] Чтобы оптимизатор запросов рассмотрел возможность использования отфильтрованной статистики, когда выбирает план распределенного запроса, запрос должен быть в пределах определения объекта статистики. Если взять приведенный выше пример, предложение WHERE запроса должно указать значения col1 от 2000101 до 20001231.
Создание одностолбцовой статистики со всеми параметрами
Можно также комбинировать параметры. В приведенном ниже примере создается отфильтрованный объект статистики с настраиваемым размером выборки:
Полные справочные сведения см. в статье CREATE STATISTICS (Transact-SQL).
Создание многостолбцовой статистики
Для создания объекта статистики с несколькими столбцами используйте предыдущие примеры, но укажите больше столбцов.
[!NOTE] Гистограмма, используемая для оценки количества строк в результатах запроса, доступна только для первого столбца, указанного в определении объекта статистики.
В этом примере гистограмма создана для product_category. Статистика между столбцами вычисляется по product_category и product_ .
Так как между product_category и product_sub_category настроена корреляция, объект статистики с несколькими столбцами может быть полезен, когда к этим столбцам обращаются одновременно.
Создание статистики для всех столбцов в таблице
Один из способов создать статистику — выполнить команды CREATE STATISTICS после создания таблицы.
Использование хранимой процедуры для создания статистики по всем столбцам в пуле SQL
Выделенный пул SQL не имеет системных хранимых процедур, эквивалентного sp_create_stats в SQL Server. Эта хранимая процедура создает объект статистики по одному столбцу для каждого столбца в пуле SQL, который еще не имеет статистики.
Следующий пример поможет приступить к проектированию пула SQL. Вы можете адаптировать код в соответствии со своими нуждами.
Чтобы создать статистику для всех столбцов в таблице с помощью параметров по умолчанию, выполните хранимую процедуру.
Чтобы создать статистику по всем столбцам в таблице с помощью FULLSCAN, вызовите эту процедуру.
Чтобы создать выборочную статистику для всех столбцов в таблице, введите 3 и процент выборки. В этой процедуре используется частота выборки в 20%.
Примеры: Обновите статистику
Чтобы обновить статистику, можно:
- Обновить один объект статистики. Указать имя объекта статистики, который вы хотите обновить.
- Обновить все объекты статистики для таблицы. Указать имя таблицы, а не один объект статистики.
Обновление одного указанного объекта статистики
Для обновления указанного объекта статистики используйте следующий синтаксис:
Обновляя определенные объекты статистики, можно свести к минимуму затраты времени и ресурсов на управление статистикой. Это требует некоторых усилий, чтобы выбрать наиболее подходящие объекты статистики для обновления.
Обновление всей статистики для таблицы
Ниже показан простой метод обновления всех объектов статистики для таблицы.
Инструкцию UPDATE STATISTICS легко использовать. Просто помните, что она обновляет всю статистику для таблицы и, следовательно, может выполнять больше работы, чем необходимо. Если производительность не является проблемой, это самый простой и наиболее полный способ гарантировать актуальность статистики.
[!NOTE] При обновлении всей статистики для таблицы выделенный пул SQL выполняет проверку для выборки таблицы для каждого объекта статистики. Если таблица большого размера и содержит много столбцов и статистики, может оказаться эффективнее обновлять отдельные данные статистики по необходимости.
Сведения о реализации UPDATE STATISTICS процедуры см. в разделе временные таблицы. Метод реализации слегка отличается от процедуры CREATE STATISTICS , описанной выше, но результат одинаков.
Полный синтаксис см. в разделе Обновление статистики.
Существует несколько системных представлений и функций, которые можно использовать для поиска информации о статистике. Например, можно узнать, устарел ли объект статистики, воспользовавшись функцией stats-date, чтобы посмотреть, когда статистика была в последний раз создана или обновлена.
Представления каталога для статистики
Вот какие системные представления показывают информацию о статистике:
| Представление каталога | Описание |
|---|---|
| sys.columns | Одна строка для каждого столбца. |
| sys.objects | Одна строка для каждого объекта в базе данных. |
| sys.schemas | Одна строка для каждой схемы в базе данных. |
| sys.stats | Одна строка для каждого объекта статистики. |
| sys.stats_columns | Одна строка для каждого столбца в объекте статистики. Ссылается на sys.columns. |
| sys.tables | Одна строка для каждой таблицы (включая внешние таблицы). |
| sys.table_types | Одна строка для каждого типа данных. |
Системные функции для статистики
Эти системные функции полезны для работы со статистикой:
| Системная функция | Описание |
|---|---|
| STATS_DATE | Дата последнего обновления объекта статистики. |
| DBCC SHOW_STATISTICS | Сводная и подробная информация о распределении значений согласно объекту статистики. |
Сочетание столбцов и функций статистики в одном представлении
Это представление содержит столбцы, относящиеся к статистике, и результаты функции STATS_DATE().
Примеры DBCC SHOW_STATISTICS()
DBCC SHOW_STATISTICS() отображает данные, хранящиеся в объекте статистики. Эти данные состоят из трех частей:
- Заголовок
- Вектор плотности
- Гистограмма
Заголовок метаданных о статистике. Гистограмма отображает распределение значений в первом ключевом столбце объекта статистики. Вектор плотности измеряет корреляцию между столбцами.
[!NOTE] Выделенный пул SQL вычисляет оценку количества элементов с помощью любого из данных в объекте статистики.
Отображение заголовка, плотности и гистограммы
Этот простой пример показывает все три части объекта статистики.
Отображение одной или нескольких частей DBCC SHOW_STATISTICS()
Если вы заинтересованы только в просмотре определенных частей, используйте предложение WITH и укажите, какие части требуется показать:
Отличия DBCC SHOW_STATISTICS()
Инструкция DBCC SHOW_STATISTICS () более строго реализована в выделенном пуле SQL по сравнению с SQL Server:
- Недокументированные возможности не поддерживаются.
- Нельзя использовать Stats_stream.
- Нельзя соединить результаты для определенных подмножеств данных статистики. Например, STAT_HEADER JOIN DENSITY_VECTOR.
- Невозможно задать NO_INFOMSGS для подавления сообщений.
- Нельзя использовать квадратные скобки вокруг имен статистики.
- Нельзя использовать имена столбцов для идентификации объектов статистики.
- Пользовательская ошибка 2767 не поддерживается.
Для дальнейшего повышения производительности запросов ознакомьтесь с разделом Мониторинг рабочей нагрузки с помощью динамических административных представлений.
Для чего используется статистика ms sql
Секционированные таблицы и индексы SQL Server 2005 (продолжение)
Секционированные Таблицы в SQL Server 2005
В то время как усовершенствования SQL Server 7.0 и SQL Server 2000 значительно улучшили производительность секционированных представлений, они не упрощали их администрирования, разработки или развертывания. Все таблицы, на основе которых строилось секционированное представление, создавались и управлялись по отдельности. Разработка приложений становилась проще за счет того, что разработчику уже не приходилось обращаться непосредственно к базовым таблицам, однако администрирование было затруднено, поскольку приходилось управлять каждой отдельной таблицей, входящей в состав секционированного представления, и его ограничениями целостности. Из-за сложностей управления, разделение таблиц зачастую использовалось только тогда, когда данные нужно было «заархивировать» или загрузить. Операции добавления/удаления из доступной только на чтение таблицы (read-only) были слишком дорогостоящими — они занимали время, место в журнале транзакций, и часто создавали блокировки.
Кроме того, поскольку предшествующие стратегии секционирования требовали, чтобы разработчик создавал индивидуальные таблицы и индексы и затем объединял их посредством представления, оптимизатору запросов требовалось проверить достоверность и определить планы исполнения для каждой секции (поскольку индексы могли измениться). Поэтому время оптимизации запроса в SQL Server 2000 зачастую линейно возрастает с увеличением количества секций, входящих в представление, чего не происходит в SQL Server 2005, где каждая секция по определению имеет одни и те же индексы.
К примеру, разберем случай, когда текущий месяц OLTP-данных (Online Transaction Processing), должен быть перемещен в конце месяца в OLAP-таблицу. Самая последняя таблица (предназначенная для запросов read-only) — это одиночная таблица с одним кластерным и двумя некластерными индексами; массовая загрузка (bulk load) 1GB данных (в уже проиндексированную и действующую таблицу) создает блокировки с текущими пользователями помимо того, что таблица и/или индексы становятся фрагментированным и/или блокированными. Кроме того, процесс загрузки займет существенное время, поскольку таблица и индексы должны обслуживаться по мере поступления каждой строки. Есть способы, позволяющие ускорить bulk load, однако, они могут непосредственно затронуть всех остальных пользователей, таким образом, принося в жертву возможность параллельной работы ради скорости исполнения. Если бы эти данные добавлялись в недавно созданную (пустую) таблицу, то вначале могла бы произойти загрузка данных (в т.ч. параллельная загрузка), а затем построение индексов (возможно, также параллельное). Зачастую вы смогли бы достигать 10-ти кратного (или еще большего) преимущества от использования данного подхода. Фактически, загружая в неиндексированную таблицу (heap — кучу), Вы можете воспользоваться преимуществом многопроцессорной системы, загружая параллельно многочисленные файлы данных или многочисленные «фрагменты» одного и того же файла (заданные начальными и конечными строками). В любом из выпусков SQL Server секционирование позволяет Вам управлять таблицами на более высоком уровне, не обязывая Вас хранить все данные в одном месте — с сильно фрагментированными индексами и отсутствием реального управления любым аспектом поведения на более высоком уровне. Функциональная стратегия секционирования могла быть достигнута в предыдущих выпусках, путем динамического создания и удаления таблиц и модифицирования UNION-представлений. Однако в SQL Server 2005 решение более изящно: Вы можете просто «включить» («switch in») недавно-наполненную секцию(и), как дополнительную секцию к существующей схеме секционирования, либо «выключить» («switch out») любую старую секцию(и). Процесс «включения/выключения» секций занимает незначительное время, и может быть даже ускорен за счет применения параллельной загрузки данных (bulk loading) и параллельного создания индексов. Что еще более важно, секция управляется из-за пределов таблицы, таким образом, во время добавления новой секции на действующую таблицу не оказывается никакого воздействия. В результате, добавление секции происходит за считанные секунды.
Еще лучше обстоят дела в случае, если данные необходимо удалить. Если база данных нуждается только в «sliding window» («скользящее окно») наборе данных, то, когда новые данные будут готовы к переселению (например, в текущий месяц), тогда самые старые данные (например, данные того же месяца за предыдущий год) смогут быть удалены. В этом случае, Вы, вероятно, добьетесь улучшения производительности от использования секционирования на несколько порядков. Поскольку это может показаться неправдоподобным, давайте рассмотрим имеющиеся тут отличия.
Когда все данные находится в одной единственной таблице, удаление 1GB данных (самых старых данных) требует построчной манипуляции данными и связанными с ними индексами. Процесс удаления данных приводит к существенной log-активности и не позволяет усекать журнал транзакций до конца удаления (помните, что удаление — это отдельная auto-commit транзакция; тем не менее, Вы можете управлять размером транзакции, выполняя множественное удаление в одной транзакции там, где только возможно), а также требуется [потенциально очень] больший журнал транзакций. Чтобы удалить такое же количество данных, удаляя определенную секцию из секционированной таблицы, все, что надо сделать — это «выключить» секцию (что является операцией над метаданными), и затем удалить или усечь автономную таблицу.
А кроме того, знаете ли Вы, что использование файловых групп (filegroups) совместно с секциями является идеальным механизмом секционирования? Файловые группы позволяют Вам размещать отдельные таблицы на различных физических дисках. Если отдельная таблица располагается в нескольких файлах, благодаря использованию filegroups, то тогда фактическое расположение данных предсказать невозможно. В системах, которые не допускают параллельной обработки данных, SQL Server, благодаря применению файловых групп, улучшает производительность за счет использования всех дисков более равномерно и поэтому конкретное размещение данных в них не является столь принципиальным.
На Рисунке 2 представлена файловая группа, состоящая из трех файлов. В ней располагаются две таблицы: Orders и OrderDetails. Когда данные таблиц размещаются в файловой группе, SQL Server пропорционально заполняет файлы файловой группы, захватывая в них необходимое дисковое пространство для своих объектов экстентами (кусками по 64 Kb, что равно 8 страницам данных по 8 Kb). В момент создания таблиц Orders и OrderDetails файловая группа будет пуста. Когда приходит новый заказ, в таблице Orders создается соответствующая запись, и по одной записи в таблице OrderDetails для каждого заказанного товара. SQL Server выделяет один экстент для таблицы Orders в File1, и затем еще один экстент для таблицы OrderDetails в File2. По всей вероятности, таблица OrderDetails будет расти быстрее, чем таблица Orders, и поэтому следующие несколько экстентов будут выделены для нее: следующий экстент для таблицы OrderDetails будет располагаться в файле File3. На приведенном ниже рисунке продемонстрировано размещение экстентов данных таблиц Orders и OrderDetails в файловой группе.
Рисунок 2. Пропорциональное заполнение файлов
SQL Server и дальше продолжит балансировать (уравновешивать) размещение всех объектов в пределах этой файловой группы. Наряду с тем, что SQL Server получает выгоду от использования большего количества дисков для данной операции, это не так оптимально с точки зрения управления или перспективы обслуживания (лишние неудобства), или для ситуации, когда модели использования достаточно предсказуемы (и обособлены).
В SQL Server 2005 секционированная таблица может быть спроектирована (используя «функции» и «схемы») таким образом, чтобы строки, имеющие одинаковый ключ секционирования, размещались бы в строго указанном месте. Функция секционирования определяет границы секций и то, в какую секцию должно быть занесено первое значение. В случае LEFT-функции, первое значение будет являться верхней границей в первой секции. В случае RIGHT-функции, первое значение будет являться нижней границей во второй секции. Мы еще рассмотрим подробно особенности функций секционирования дальше в этой статье. Как только функция определена, может быть создана схема секционирования для того, чтобы определить физическое расположение секций в базе данных. Если несколько таблиц используют одну и ту же функцию (но не обязательно одну и ту же схему), строки, имеющие один и тот же ключ секционирования, будут располагаться на диске вместе. Этот принцип называется выравниванием. Выравнивая строки нескольких таблиц по ключу секционирования, SQL Server может (если оптимизатор запросов предпочтет) работать только с необходимыми группами данных (в каждой из таблиц). Для того чтобы выровняться, две секционированные таблицы или два индекса должны иметь некоторое соответствие между их соответствующими секциями. Они должны использовать «эквивалентные» функции секционирования и быть связаны по столбцам секционирования. Две функции секционирования могут использоваться для выравнивания данных, если:
обе функции секций используют одинаковое количество аргументов и секций.
ключ секционирования, используемый в каждой функции, имеет одинаковый тип (включая длину, точность и масштаб (если допускается), и collation (если допускается)).
граничные значения эквивалентны (включая критерии границы LEFT/RIGHT).
Внимание! Даже если две функции секционирования рассчитаны на выравнивание данных, ваши таблицы могут остаться не выровненными из-за не выровненных индексов, если они не секционированы по тем же столбцам, что и таблицы.
Локализация (Collocation) — более строгая форма выравнивания, когда два выровненных объекта объединены с предикатом equi-объединения (inner), где equi-объединение производится по столбцу секционирования. Это становится важным в контексте запроса, подзапроса или другой подобной конструкции, где могут встретиться предикаты equi-объединения. Локализация эффективна, поскольку запросы, объединяющие таблицы по столбцам секционирования, выполняются тогда значительно быстрее. Возьмем, например, таблицы Orders и OrderDetails, описанные выше. Вместо того чтобы заполнять файлы пропорционально, Вы можете создать схему секционирования, которая разнесет БД по трем файловым группам. Вы определяете таблицы Orders и OrderDetails таким образом, чтобы они использовали одну и ту же схему. Связанные данные (по ключу секционирования) будут помещены в один и тот же файла, таким образом, изолируя необходимые для объединения данные. Когда связанные строки из нескольких таблиц секционированы по одному и тому же принципу, SQL Server может объединять секции, не имея необходимости рыться во всей таблице или нескольких секциях (если к таблицам применялись разных функций секционирования) для сопоставления строк. В этом случае, объекты не просто выровнены, они, как говорится, являются выровненным хранилищем, поскольку связанные данные располагаются в одних и тех же файлах.
Следующий рисунок демонстрирует, как два объекта могут использовать одну и ту же схему секционирования, когда все строки данных с одинаковым ключом секционирования окажутся в одной и той же файловой группе. Когда связанные данные выровнены, SQL Server 2005 может эффективно работать с большими наборами данных параллельно. Все данные о продажах за январь (как для Orders, так и для OrderDetails) будут располагаться в первой файловой группе, данные за февраль — во второй файловой группе и т.д.
Рисунок 3. Таблицы выровненных хранилищ
SQL Server поддерживает секционирование, основанное на диапазонах. Таблицы, так же как и индексы могут использовать одну и ту же схему для лучшего выравнивания. Хорошее проектирование способно значительно улучшить производительность системы, но что, если использование данных все время меняется? Что, если потребуется дополнительная секция? Простота администрирования при добавлении и удалении секций, а также управления секциями извне секционированной таблицы была главной целью при разработке SQL Server 2005.
SQL Server 2005 упростил секционирование для администрирования, разработки и развертывания, а также для понимания. Вот некоторые из усовершенствований в производительности и управляемости:
Упрощается разработка и реализация больших таблиц, которые должны быть разделены для улучшения производительности.
Данные загружаются в новую секцию существующей секционированной таблицы с минимальным нарушением доступа к данным в остальных секциях.
Данные загружаются в новую секцию существующей секционированной таблицы со скоростью, равной скорости загрузки данных в новую пустую таблицу.
Архивирование и/или удаление части секционированной таблицы минимально воздействует на оставшуюся часть таблицы.
Поддерживается «переключение» секций в/из секционированной таблицы.
Обеспечивается лучшее масштабирование и параллелизм для чрезвычайно больших операций над несколькими связными таблицами.
Улучшается производительность всех секций.
Уменьшается время оптимизации запроса, поскольку каждая секция не должна быть оптимизирована отдельно.
Определения и терминология
Чтобы создавать секции в SQL Server 2005, Вам необходимо познакомиться с несколькими новыми понятиями, терминами и синтаксисом. В предыдущих выпусках SQL Server таблица была всегда физическим и логическим понятием, теперь в SQL Server 2005 для Секционированных Таблиц и Индексов у вас есть на выбор несколько вариантов того, как и где хранить таблицу. В SQL Server 2005, таблицы и индексы могут быть созданы с точно таким же синтаксисом, как и в предыдущих релизах — как простая табличная структура, помещенная в DEFAULT filegroup или определенную пользователем файловую группу (user-defined filegroup). Кроме того, в SQL Server 2005 таблица и индексы также могут быть основаны на схеме секционирования. Схема секционирования отобразит объект на одну или возможно несколько файловых групп. Для определения того, какие данные где размещать, схема секционирования использует функцию секционирования. Функция секционирования определяет алгоритм, используемый для маршрутизации строк, а схема связывает секции с их соответствующим физическим местоположением (т.е. файловой группой). Другими словами, таблица по-прежнему является логическим понятием, но её физическое расположение на диске может радикально отличаться от более ранних выпусков SQL Server; таблица может иметь схему.
Диапазонные секции — это табличные секции, описанные определенными и настраиваемыми диапазонами данных. Границы диапазонных секций выбираются разработчиком, и могут быть изменены, если изменится модель использования данных. Как правило, эти диапазоны основываются на дате или на упорядоченных группировках данных.
Основное применение диапазонных секций — архивирование данных, поддержка принятия решений (когда зачастую необходимы только определенные диапазоны данных, например, только заданный месяц или квартал), и объединение OLTP и DSS (Decision Support System — система поддержки принятия решений), где использование данных меняется в течение всего жизненного цикла записи базы данных. Самое большое преимущество новой технологии (особенно для архивирования и обслуживания) состоит в способности манипулировать крайне специфичными диапазонами данных. Диапазонные секции архивируют старые данные и загружают новые чрезвычайно быстро. Секции диапазона лучше всего подходят для ситуации, когда доступ к данным осуществляется для поддержки принятия решений и основывается на больших диапазонах данных. В этом случае Вы заботитесь о том, где конкретно расположены данные, так чтобы обращение велось только к подходящим секциям. Когда появляются новые бизнес — данные, Вы естественно захотите добавлять их — легко и быстро.
Создание диапазонных секций несколько усложнено, поскольку вам потребуется определить граничные условия для каждой секции. Еще вы должны будете создать схему, отображающую каждую секцию на файловую(ые) группу(ы). Тем не менее, они часто имеют совместимый шаблон, так что, будучи однажды определены, они, вероятно, будут легки в программной поддержке (см. рис. 4).
Рисунок 4: Диапазонная секционированная таблица — 12 Секций.
Определение ключа секционирования
Первый шаг в секционировании таблиц и индексов состоит в определении «ключа». Ключ секционирования — это столбец(ы) таблицы, который удовлетворяет определенным критериям. Функция секционирования определяет тип данных, на котором базируется логическое разделение данных. Физическое размещение данных определено схемой секционирования. Другими словами, схема отображает данные на файловые группы, которые в свою очередь отображают данные на конкретные файлы. Для этого схема всегда использует функцию — если функция определяет пять секции, тогда схема должна использовать пять файловых групп. Однако совсем не обязательно, чтобы все файловые группы были разными; тем не менее, Вы получите больший выигрыш в производительности, если будете использовать систему из нескольких дисков, предпочтительно многопроцессорную. При использовании схемы вы определяете столбец, который будет выступать в качестве аргумента для функции секционирования.
Данные в диапазонных секциях разделены логически. Фактически, секции данных в действительности не могут быть сбалансированы вообще. Однако использование данных навязывает диапазонную секцию, поскольку модель использования этой таблицы определяет специальные границы для анализа (иначе называемые «диапазонами»). Ключ секционирования для диапазонной функции может состоять только из одного столбца, и функция секционирования будет включать всю область данных, даже если эти данные недопустимы для таблицы. Другими словами, границы определены для каждой секции, но первая и последняя секции позволят включать бесконечно малые (первая) и бесконечно большие (последняя) значения. Для секций должны быть заданы ограничения целостности CHECK для реализации Ваших бизнес-правил и обеспечения целостности данных (т.е. ограничения области данных конечным, а не бесконечным диапазоном). Диапазонные секции идеальны, когда обслуживание и администрирование требуют архивирования больших диапазонов данных на регулярной основе, и когда запросы обращаются к большим массивам данных — но только в пределах нескольких диапазонов.
Использование статистики оптимизатором запросов Microsoft SQL Server 2005
Microsoft SQL Server 2005 собирает статистику по индексам и полям данных, хранимых в базе. Эта статистика используется оптимизатором запроса SQL Server при выборе оптимального плана исполнения запросов на выборку или обновление данных. В этой статье описывается то, какие данные собираются сервером, где они хранятся, и какие команды нужно использовать для обновления и удаления статистики. По умолчанию, SQL Server 2005 создает и обновляет статистику автоматически, когда решит, что это будет полезным. В этой статье описано, как можно изменять заданные по умолчанию значения конфигурации сбора статистики на разных уровнях (столбец, таблица и база данных).
Статистика в SQL Server 2005
Microsoft SQL Server 2005 собирает статистику для отдельных столбцов или для набора столбцов. Статистика используется оптимизатором запросов для оценки селективности выражений, определяя, таким образом, объём промежуточных и конечных выборок. Хорошие статистические данные позволяют оптимизатору точно оценивать стоимость разных планов исполнения запроса, и выбирать наиболее хороший план. Вся информация об одном объекте статистики хранится в нескольких столбцах одной записи таблицы sysindexes, и в большом бинарном объекте статистики statblob, хранящемся в одной из внутренних таблиц. Кроме того, информация о статистике может быть найдена в новых представлениях метаданных sys.stats и sys.indexes.
Обзор механизмов сбора статистики
SQL Server 2005 имеет много обслуживающих статистику механизмов. Самый важный из них — это возможность автоматически создавать и обновлять статистику. Этот механизм задействуется по умолчанию в SQL Server 2005 и SQL Server 2000. Приблизительно 98 % инсталляций SQL Server 2000 оставляют задействованным механизм автоматического обновления статистики, что принято считать хорошей практикой. В большинстве приложений баз данных, разработчики и администраторы могут положиться на автоматическое создание и обновление статистики, которое в достаточной мере обеспечивает всестороннюю и точную статистику данных, по которой оптимизатор запросов SQL Server 2005 выбирает хорошие планы исполнения, и в то же время снижаются затраты на разработку и администрирование. Если же Вам нужно в большей мере управлять созданием и обновлением статистики, чтобы получить боле соответствующие Вашим нуждам планы исполнения запросов, или более тонко управлять сбором статистики, Вы можете использовать ручное создание и обновление статистики.
Важным новшеством с точки зрения обеспечения высокой производительности приложений баз данных является возможность асинхронного обновления статистики в автоматическом режиме. Это помогает повысить предсказуемость времени отклика на запрос в высокопроизводительных системах.
В SQL Server 2005 имеются следующие возможности работы со статистикой:
implicitly create and update statistics — фоновое создание и обновление статистики с заданной по умолчанию частотой обновления (в командах SELECT, INSERT, DELETE и UPDATE, использование столбца в условии WHERE или в JOIN приводит к созданию или обновлению статистики, если это необходимо, и при условии, что включено автоматическое обновление).
manually create and update statistics — ручное управление статистикой, с заданной частотой обновления и удаления (CREATE STATISTICS, UPDATE STATISTICS, DROP STATISTICS, CREATE INDEX, DROP INDEX).
manually create statistics in bulk — ручное создание статистики для всех столбцов во всех таблицах базы данных (sp_createstats).
manually update all existing statistics — ручное обновление статистики во всей базе данных (sp_updatestats).
list statistics objects — просмотр существующих объектов статистики таблицы или базы данных (sp_helpstats, представления каталога sys.stats, sys.stats_columns)
display descriptive information about statistics objects — просмотр описаний объектов статистики (DBCC SHOW_STATISTICS)
enable and disable automatic creation and update of statistics — включение/выключение автоматического создания и обновления статистики для всей базы данных или для определенной таблицы или объекта статистики (опции ALTER DATABASE: AUTO_CREATE_STATISTICS и AUTO_UPDATE_STATISTICS; sp_autostats; и опции NORECOMPUTE: CREATE STATISTICS и UPDATE STATISTICS)
enable and disable asynchronous automatic update of statistics — включение/выключение автоматического, асинхронного обновления статистики (ALTER DATABASE, опция AUTO_UPDATE_STATISTICS_ASYNC)
Кроме того, SQL Server Management Studio позволяет в графическом интерфейсе просматривать и управлять объектами статистики, которые можно просматривать в Проводнике Объектов в специальной папке под каждым объектом таблицы.
Новшества в статистике SQL Server 2005
В SQL Server 2005 применено множество влияющих на статистику новшеств, которые позволяют оптимизатору запросов улучшить выбор плана исполнения запроса за счёт анализа более широкого диапазона запросов, или же предоставить возможность более тонко управлять сбором статистики. Можно выделить следующие новшества:
String summary statistics: частота распределения подстрок при анализе символьных полей. Помогает оптимизатору лучше оценивать селективность условий с оператором LIKE.
Asynchronous auto update statistics: асинхронное, автоматическое обновление статистики, в операторе ALTER DATABASE опция AUTO_UPDATE_STATISTICS_ASYNC появилась в SQL Server 2005 и отключена по умолчанию. Когда опция задействуется, SQL Server 2005 автоматически обновляет статистику в фоновом режиме. При этом запрос, который привёл к обновлению статистики, ничего не блокирует, и используется уже накопленная статистика. Всё это позволяет обеспечить большую предсказуемость времени отклика запроса для некоторых типов рабочей нагрузки.
Computed column statistics: статистика по вычисляемым полям может собираться вручную или автоматически (это было частично реализовано в SQL Server 2000, но было не документировано).
Large object support: поддержка больших объектов, таких как столбцы типов: ntext, text и image, а так же новых типов данных: nvarchar(max), varchar(max) и varbinary(max), которые теперь также могут быть определены как столбцы, по которым собирается статистика.
Improved statistics loading framework: улучшенная статистика загруженных структуру позволяет оптимизатору лучше, чем в SQL Server 2000, получать статистику внутренних механизмов, позволяя охватить все относящиеся к статистике аспекты, за счёт чего повышается качество результата и соответственно оптимизации и производительности.
Increased ability to automatically create statistics on computed columns: за счёт появления возможности автоматического создания статистики по вычисляемым полям, выполняемого в SQL Server 2005 при необходимости и при условии, что запрос содержит эквивалент выражения вычисляемого поля, также можно получить существенный выигрыш в качестве такой статистики.
Minimum sample size: минимальный размер выборки установлен в 8 мегабайт при исчислении данных, или он приравнивается к размеру таблицы, если она меньше этого размера.
Increased limit on number of statistics: увеличено предельное число статистик, т.е. число объектов статистики, столбцов для одной таблицы, теперь оно равно 2000, и ещё 249 индексных статистик могут быть добавлены, делая общее число объектов статистических данных на таблицу равным 2249.
Enhanced DBCC SHOW_STATISTICS output: Расширение возможностей DBCC SHOW_STATISTICS позволяет теперь отображать имена объектов статистики, что позволяет избегать двусмысленности.
Statistics auto update is now based on column modification counters: автоматическое обновление статистики теперь основано на счётчике column modification counters. В SQL Server 2000, обновление статистики определялось по номеру изменений строки. Теперь, изменения отслеживаются на уровне столбца, и автоматическое обновление статистики можно предотвратить для тех столбцов, для которых не было зафиксировано достаточно изменений.
Statistics on internal tables: статистика по внутренним таблицам собирается для таблиц, перечисленных в sys.internal_tables, включая XML и полнотекстовые индексы, очереди брокера сервисов и запросы к таблицам оповещений.
Single rowset output for DBCC SHOW_STATISTICS: единый отчёт по набору строк для DBCC SHOW_STATISTICS предоставляет возможность вывести единый заголовок, вектор плотности и гистограмму для набора строк. Это позволяет упростить разработку автоматов обработки результатов исполнения DBCC SHOW_STATISTICS.
Statistics on up-to 32 columns: с 16 до 32 было увеличено число столбцов в объекте статистики.
Statistics on partitioned tables: статистика по секциям таблиц теперь поддерживается и для секционированных таблиц, появившихся в SQL Server 2005. Гистограммы поддерживаются потаблично (не посекционно).
Parallel statistics gathering for fullscan: для статистики, собранной во время полного сканирования, создание одного объекта статистики может распараллеливаться как для секционированных, так и для обычных таблиц.
Improved recompiles and statistics creation in case of missing statistics: стали лучше учитываться такие моменты, как перекомпиляция и создание статистики в случае её отсутствия, в режиме автоматического создания или при неудачах сбора статистики. При последующем применении плана исполнения, созданного без статистики, статистика создаётся автоматически, запрос исполняется, и план перекомпилируется. Состояние отсутствия статистики не хранится. Для получения дополнительной информации, обратитесь к статье: Batch Compilation, Recompilation, and Plan Caching Issues in SQL Server 2005.
Improved recompilation logic and statistics update for empty tables: улучшена логика рекомпиляции и обновления статистики для пустых таблиц. Изменение от 0 до > 0 строк в таблице приводит к рекомпиляции запроса и обновлению статистики. Для получения дополнительной информации, обратитесь к статье: Batch Compilation, Recompilation, and Plan Caching Issues in SQL Server 2005.
Clearer and more consistent display of histograms: стали более понятными и менее противоречивыми показания гистограмм. Внесены улучшения в DBCC SHOW_STATISTICS, из-за которых гистограммы теперь всегда предварительно масштабируются, а уже потом сохраняются в каталогах.
Inferred date correlation constraints: добавлены ограничения дедуктивной корреляции дат, с которыми, через опцию базы данных DATE_CORRELATION_OPTIMIZATION, можно заставить SQL Server учитывать информацию о корреляции полей типа datetime между парами таблиц, связанных внешним ключом. Эта информация используется для того, чтобы иметь возможность определять для небольшого числа запросов подразумеваемые для них предикаты. Эта информация не используется непосредственно для оценки селективности или оценочной стоимости для оптимизатора, так что это не является статистикой в строгом смысле, но это она очень близка к статистике, являясь вспомогательной информацией, обычно помогающей получать лучший план запроса.
sp_updatestats: в SQL Server 2005 эта процедура обновляет только те статистические данные, которые требуют обновления, основываясь при этом на информации из rowmodctr в системном представлении sys.sysindexes, устраняя, таким образом, ненужные обновления для не изменяемых элементов. Для баз данных, у которых уровень совместимости установлен в 90 и выше, sp_updatestats использует для UPDATE STATISTICS установки соответствующие автоматическому режиму для любых индексов или статистик.
Также в новой версии есть и некоторые другие, менее значительные изменения в поведении механизмов сбора статистики. В частности, поле statblob в sys.sysindexes теперь всегда устанавливается в NULL, а сам statblob хранится в скрытой, внутренней таблице каталога.
В этой главе определяются термины, применяемые при описании статистики SQL Server 2005:
statblob: статистический Binary Large Object (BLOB), т.е. большой, бинарный статистический объект. Этот объект хранится во внутреннем представлении каталога sys.sysobjvalues.
String Summary: резюме строки — это такая форма статистики, которая описывает частоту распределения подстрок в поле записи. Используется для оценки селективности предикатов LIKE. Хранится в statblob для поля записи.
sysindexes: системное представление каталога sys.sysindexes, которое содержит информацию о таблицах и индексах.
Predicate: предикат — это условие, которое оценивается как истина или ложь. Предикаты используются в предложении WHERE или в JOIN запросов к базе данных.
Selectivity: селективность — это доля строк в получаемом предикатом наборе данных, которые удовлетворяют условию этого предиката. Также встречаются более сложные определения селективности, необходимые для оценки числа строк, вовлечённых в объединения, DISTINCT и другие операторы. Например, SQL Server 2005 оценивает селективность предиката «Sales.SalesOrderHeader.OrderID = 43659» в базе данных AdventureWorks как 1/31465 = 0.00003178.
Cardinality estimate: оценка числа элементов, позволяет определить объём результирующего набора. Например, если таблица T имеет 100000 строк, а запрос содержит предикат отбора: T.a = 10, и гистограмма показывает селективность T.a = 10 — 10 %, то оценка количества элементов в той доли строк T, которую нужно обработать запросом будет: 10 % * 100000, и равна 10000 строк.
LOB: большой объект, обычно имеет типы: image, text, ntext, varchar(max), nvarchar(max), varbinary(max).
ССЫЛКИ НА СТАТЬИ
Статьи на русском языке
Версионная эпидемия Visual Studio 2005
Поль Тюрро
C-sharp: Этот год обещает стать очень интересным для разработчиков программного обеспечения в связи с ожидающимся в начале ноября выходом Visual Studio 2005. На днях я посетовал на участь разработчиков ПО для Windows. Как уже отмечалось в статье «It’s All..
MS SQL 2005: оконные функции
Иван Бодягин
MSSQLServer: Ввиду того, что в следующей версии MS SQL Server, выход которой ожидается в 2005 году, нововведений просто безумное количество, слона приходится есть по частям. Данный кусочек посвящен новой функциональности называемой «оконные функции».
Обмен данными между хранимыми процедурами с помощью временных таблиц. Преимущества и недостатки
Oleg Aksenov
MSSQLServer: Зачем это нужно. Простой пример: есть процедура, возвращающая набор данных по списку идентификаторов с дополнительными атрибутами (столбцами). Процедура одна (очень удобно), а вот список может формироваться по-разному.
О Windows Server 2003 SP1
Поль Тюрро
Выпуск Windows Server 2003 Service Pack 1 (SP1) во многих отношениях не менее значим для Windows 2003, чем выпуск Windows XP SP2 для XP.
XML Web-службы в Microsoft SQL Server 2005
Алексей Ширшов
MSSQLServer: Компания Microsoft делает все, чтобы превратить SQL Server в полноценный сервер приложений, который на сегодня не может считаться таковым без поддержки XML Web-служб. Можно сказать, что подобная поддержка присутствовала в SQL Server 2000.
Радикальное изменение планов Microsoft относительно Reporting Services
Брайан Моран
MSSQLServer: На прошедшем в Орландо (шт. Флорида) мероприятии Microsoft TechEd представители Microsoft сообщили о радикальном изменении планов, касающихся лицензирования SQL Server Reporting Services и Report Builder.
SQL Server 2005: как вызвать веб-сервис
Кейт Браун
MSSQLServer: В сегодняшнем посте Кейт пояснил причину: SQL Server накладывает серьёзные ограничения на загрузку сборок из файловой системы. Это и логично: если уж сборки хранятся ВНУТРИ базы данных, то включать в рассмотрение какие-то посторонние сборки из.
Оптимизация — ваш злейший враг
Dr. Joseph M. Newcomer
Достаточно квалифицированный программист вряд ли напишет очень неэффективный код. По крайней мере, неосознанно. Оптимизация — это то, чем вы занимаетесь, когда текущая производительность вас не устраивает. Иногда оптимизировать легко.
Проблемы 4го сервиспака..
Ivan’s Blog
MSSQLServer: При установке вышеупомянутой версии возникает несколько проблем, известной ошибки с AWE я не буду касаться, она уже обсуждена где только можно, а вот остальные две проблемы пожалуй описать стоит….
Многоликий класс CultureInfo — .NET-приложения станут дружелюбнее к пользователю
Майкл Каплан
C-sharp: Класс CultureInfo — один из наиболее широко используемых в Microsoft .NET Framework. Объекты этого типа применяются при загрузке ресурсов, форматировании, синтаксическом разборе, изменении регистра букв, сортировке и других преобразованиях, выполн.
Блог IT-консультанта
Мои личные наработки из IT — области (программирование на .NET, MS SQL Server, управление проектами и многое другое). На случай важных переговоров и просто так.
воскресенье, 6 октября 2013 г.
Подробная статистика использования индексов в MS SQL Server 2008/2012
Одна из задач, которую разработчикам и DBA приходится решать для улучшения производительности базы данных это удаление лишних индексов, которые не используются при выборках, а только занимают место в базе и замедляют изменение данных. В таких случаях очень полезной может оказаться замечательная статья Грега Робиду «How to get index usage information in SQL Server».
Следующий запрос, взятый из этой статьи позволяет получить статистику всех операций, произведенных над индексом с момента старта SQL сервера:
Однако часто самого факта, что индекс используется может оказаться недостаточно и хотелось бы знать, какие именно запросы этот индекс используют. Когда мы имеем дело с одним запросом, то легко увидеть, какие индексы он использует, проанализировав план его выполнения. Будем использовать тот же подход и в случае множества запросов. Вначале получим статистику о выполненных запросах из кэша планов сервера:
Возвращаемые столбцы:
query_hash – хэш SQL-предложения (часть пакета)
query_plan_hash – хэш плана всего запроса
text – текст всего пакета или процедуры
query_plan – план запроса в виде xml (можно посмотреть его в SQL Server Management Studio, если сохранить его этот xml с расширением .sqlplan)
creation_time – когда план был скомпилирован
last_execution_time – когда запрос был выполнен по этому плану в последний раз
execution_count – сколько раз запрос был выполнен по этому плану
Затем из xml-плана каждого запроса с помощью методов типа данных xml получим информацию о том, какие индексы были задействованы и какие операции над ними выполнялись. Это достаточно несложно сделать, т.к xml плана запроса подчиняется схеме:
http://schemas.microsoft.com/sqlserver/2004/07/showplan
Например, для запроса (база данных master):
На моем SQL Server 2008 генерируется такой план:
На входе – xml с namespace-ом и сам namespace. На выходе – xml без namespace-а. Функция не отличается изяществом и просто удаляет первое вхождение строки @namespaceString .
Теперь функция, возвращающая табличное представление информации об индексах: