Что означает поле length в программе wireshark
Wireshark Column Setup Deepdive
- Jasper
- 21/8/2018
- Wireshark
- 14 Comments
Every once in a while I check the blog statistics for the searches that have brought visitors here. Most of them are more or less concealed versions of “how can I grab the password of others/my ex partner/my children/friends”, which comes as no surprise. Today I saw one search expression that I used as inspiration for this post: “Good Wireshark columns to have”. So let’s talk about them.
First of all, what are those Wireshark “columns” the search mentions? Well, this is how Wireshark looks like “out of the box”. The columns are showing the values of the packet list, which you see in the top pane of the window:

Figure 1 – Wireshark Columns in the top pane
Let’s walk through the standard columns in Wireshark and explain what they are doing and why you might want to keep them:
The “No.” column shows a running number counting packets, from 1 up. You always should have this one:
- First of all it’s a good idea to be able to reference packets by their number if you’re discussing your findings
- It’s the only reliable way to sort all packets back to the order of how they were captured. If you think you can also achieve this by a relative or absolute time column as well, you’d be correct for most cases, but not all, e.g. when you have out-of-order arrivals on the capture cards. The reason why the correct order of packets is important is quite simple: the Wireshark TCP expert module processes packets in order of arrival, so if you can’t reconstruct the packet order you might get confused why it flags a packet as retransmission or out-of-order.
This is the column of the default set we need to look at in great detail. It looks simple at first: it displays the time since the beginning of the capture. Right? Well… sometimes (this is a question for a “it depends” answer), because there is a menu option in the “View” menu that allows you to configure what the column actually shows:
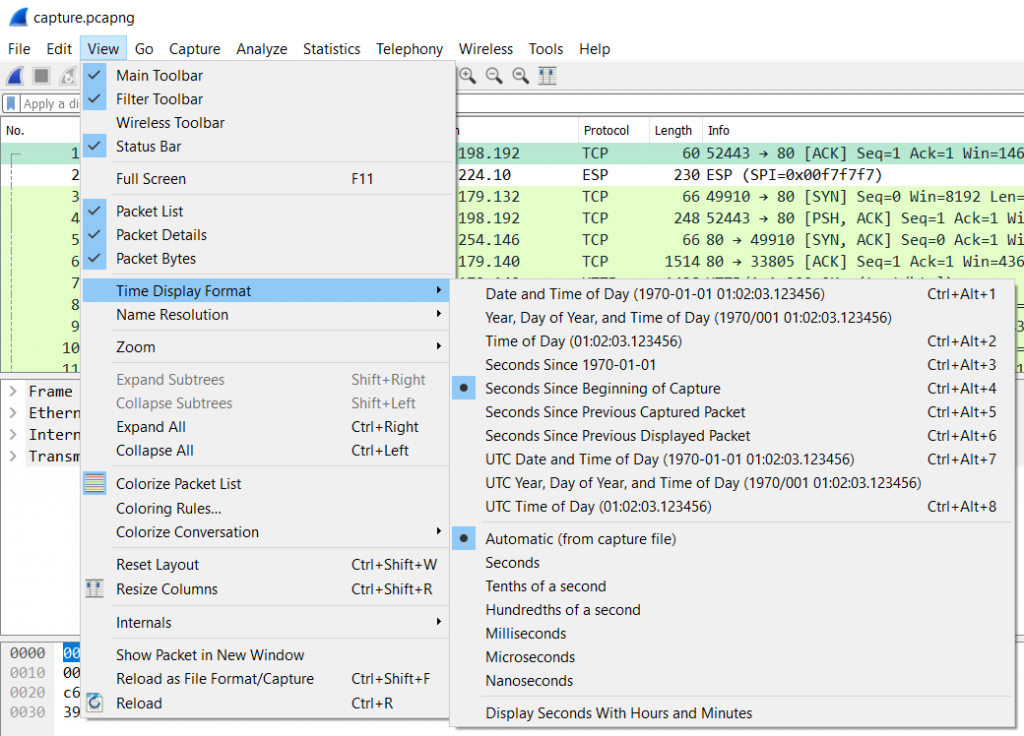
Figure 2 – Wireshark Time Display Format
As you can see, this column can display various time values for a packet. In general, there’s three formats that are mostly used:
- Seconds Since Beginning of Capture – you can think of this like a stop watch running during the capture and writing down the exact time for and when each packet is captured. This is also called “Relative Time” in many cases, because the values are relative to the point of origin, which is the beginning of the first packet by default. Oftentimes this format doesn’t seem too useful unless you want to know how much time passed from the start of the capture. But in combination with the option to set arbitrary starting points (called “Time Reference” points) this can be quite useful, e.g. when timing a TCP handshake to determine Initial Round Trip Time
- Seconds Since Previous Displayed Packet – this will tell you the time elapsed between the current packet and it’s predecessor. It’s also called “Delta Time Displayed”, because it doesn’t add up like the “Relative Time” does – it shows measurements between two packets, no more, no less.
Very important: there’s also a “Seconds Since Previous Captured Packet”, which seems to show the same values in most cases – until you apply a filter that hides the previous packet. In that situation the “captured” time value will stay the same, while the “displayed” time value will be adjusted to show the time from the new visible predecessor. I personally never use this one – I always use “Since Previous Displayed Packet”. - Date and Time of Day – this will show the absolute date and time of each packet, which is useful when you need to find packets based on a specific time something happened. The most important thing to know about this format is that the date and time may show unexpected values based on where the capture was taken and on which workstation you open the capture file.
Now let’s look at the precision settings in the same menu, which is set to “Automatic (from capture file)”. This part defines how granular the time values are displayed. Seconds are much to imprecise for most tasks, so you usually want Milliseconds and Microseconds, too. In general, the setting “Automatic (from capture file)” is fine, as it determines what precision the capture can provide and shows the time stamps with the same precision. This usually means that you won’t see Nanoseconds, because few capture devices can actually provide that kind of precision (in case you wonder: FPGA based capture cards and special devices like the ProfiShark TAP do).
Pro Tip: reading a time column in Wireshark takes some practice, but with a little training you can quickly tell Milli-, Micro- and Nanoseconds apart. If you see a time like 0.001166563 the only thing most people can specify right away are the seconds (because they are separated by a dot). Train your eye to split the part behind the dot into groups of three digits: 001 166 563 . The first group are Milliseconds, the second is Microseconds, and the last are Nanoseconds.
Source and Destination
This columns may look like a no-brainer, but there’s more than meets the eye here. In general, these two columns display source and destination addresses, and you’ll be used to seeing IP addresses displayed for each packet. But sometimes you’ll also see MAC addresses:

Figure 3 – Source and Destination column
The reason why there’s sometimes a MAC address and sometimes an IP address is simply that Wireshark displays the two highest layer address pairs it could find in each packet. So if there’s an IP layer, it will show IP addresses. For an ARP packet there are only MAC and no IP addresses, so that’s all we’ll see in those columns. That also means that when you have more than one IP layer you’ll only see the addresses present in the top IP layer, e.g. IPv6 for a tunneled conversation, and not the IPv4 addresses you might have expected to see:
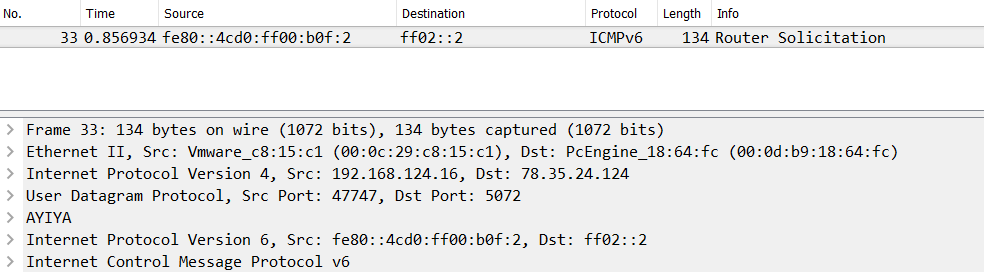
Figure 4 – Multiple IP layers in the decode
Pro Tip: you can use custom columns to show addresses other than those present in a higher layer. We’ll get to that later in this post in the Custom Column paragraph.
Protocol
The protocol column shows that top level protocol that Wireshark could determine. Sometimes it may be surprising that Wireshark will tell you something is “TCP” when you know that you’re looking at a HTTP session:

Figure 5 – Protocol Column showing TCP and HTTP
The reason why you see a lot of “TCP” values in the protocol column is that Wireshark can’t find HTTP content in all the ACK packets (they’re not carrying a TCP payload), so they’ll be marked as “TCP”, not “HTTP”. That also explains why filtering for “http” doesn’t display as many packets as filtering for “tcp.port==80”. Here’ a little homework for you: capture some HTTP traffic (hard to do these days, where everything turns HTTPS), and filter for “http” and then for “tcp.port==80”. Check the status bar for the number of currently displayed packets and compare ��
Length
The length column tells you the size of each packet. The only thing special here is that in almost all capture files you’re missing the Ethernet Frame Check Sequence (FCS, a CRC32 check sum). So if you see packet sizes of 60 bytes there were in fact 64 byte. Same for 1514 byte sized packets – there had been 1518 bytes on the wire. Some capture devices do capture the FCS, but that’s rare and easy to identify because you’ll see no packet less than 64 bytes.
The Info column contains details about the packet, once again depending on the highest layer that Wireshark was able to decode. It can be really helpful, or containing little value for you if it doesn’t show what you’re interested in. A very common question is “what can I do to change what the Info column shows”, and the answer is “very little”. You can force Wireshark to not decode the highest level protocol via the “Enabled Protocols” menu option in the “Analyze” menu, which is something I sometimes do if I only want to see TCP information, e.g. by disabling the “HTTP” protocol dissector for the same capture file previously shown in figure 5:

Figure 6 – Info column example not showing HTTP (HTTP protocol dissector disabled)
If you want Wireshark to display different things about the protocol it found at the top layer there’s just one way to go: grab your C compiler and the source code of Wireshark, and change the code. Or open a feature request, and maybe some nice developer will see that your request is useful and will implement it at some point in time. In can take a long time though.
Editing your column setup
There are couple of ways to edit you column setup. First of all, you can drag and drop the column headers left and right to rearrange them:
Figure 7 – Column Drag and Drop
You can also edit columns by right clicking on a column header and selecting “Edit Column” from the popup menu. The other way to do it is in the preferences dialog, which is also the place where you can add, remove, rearrange (via vertical drag and drop) and edit columns:
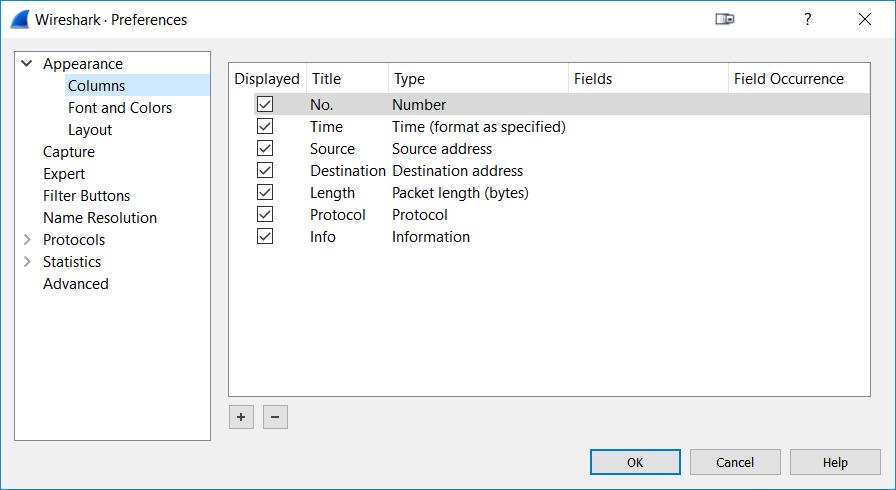
Figure 8 – Column settings in the preferences dialog
To add a column, simply click the “+” button at the bottom of the column list. Don’t wonder if there’s no additional settings are for the column like it used to in the 1.x versions of Wireshark – now you’ll simply get an additional row titled “New Column” which you can then modify to your liking. This is done by clicking on the title cell and type cell, sometimes repeatedly until it becomes editable. There is a number of predefined column types you can choose from, depending on what values you want to see in your packet list pane.
Pro Tip: If you can’t read the full name of the column type in the drop down box, resize the “Type” column itself:
Figure 9 – Adding a column and resizing the “Type” combo box
It’s a kind of Magic – Custom Columns
The selection of predefined columns is pretty good, but there’s often something you want to see in a column that doesn’t exist in the list of column types. For that, Wireshark offers “custom” columns.
The Basics
The idea behind custom columns is pretty simple: any value Wireshark can show in the packet decode pane can also be shown as a column. Let’s say I want to know which host name each HTTP request is sent to. There is no standard column for that, but I can get that value as long as I know the display filter syntax for it, which happens to be “http.host”:
Figure 10 – Adding a custom column for http.host
Sometimes Wireshark users are confused why a column doesn’t show values – keep in mind that when Wireshark doesn’t find the field of the column in a packet, it will not display anything. So in the case of the “http.host” column only HTTP packets with a host field will have a value present in the according column.
Also, there is an even faster way to add a custom column if you have a packet decode where you can find the value you want. In that case you can use the pop-up menu to quickly add a new column. The column will be placed to the right, which may cause it to be outside the current pane. In that case you need to rearrange the columns until you can see it, or resize Wireshark:
Figure 11 – Apply a field as column
If you want to you can even have a multi-purpose column that contains information from more than one field, e.g. if you want to show FQDNs from various name resolution protocols in a single column. A typical string to use for that custom column would be “http.host or tls.handshake.extensions_server_name or dns.resp.name”. Vladimir has a great post about this here. And while we’re at it there are also occurrences where you get more than one value in a column, which may be confusing, e.g. multiple TTLs. That can happen when a single packet contains multiple fields of the same type (the criteria is “matching the display filter”):
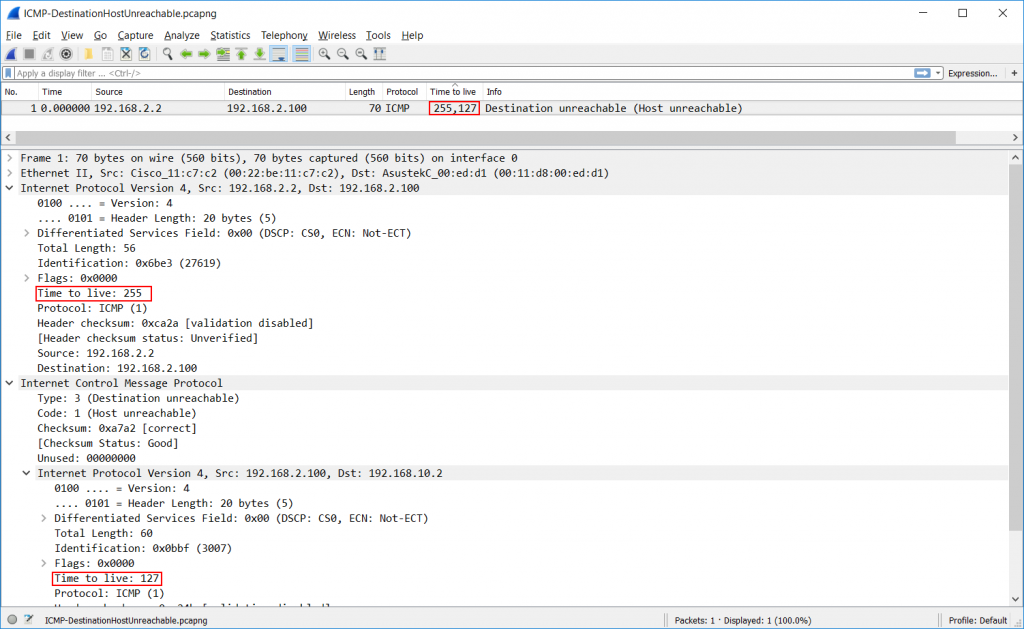
Figure 12 – Multiple comma separated values in a custom column
Pro Tip: use the “Resize packet list columns” button to help you resize columns and get to the new columns on the right, because it’ll also update the horizontal scrollbar (it’s the rightmost button on the toolbar).
Field Occurrence
When discussing the source and destination columns I mentioned that we can show more than one Source and Destination field if we need to. This can be done by using the “Field Occurrence” value of a custom column by specifying for each column which occurrence you want to display. Normally, the address columns show the values from the highest layer found in a packet. But with the occurrence index we can force Wireshark to show others as well. As an example I’ll configure two additional address columns to show the IPv4 carrier protocol for an IPv6 tunnel:
Figure 13 – adding columns with field occurrence
To be able to do that you need to add a custom column with the name of the desired protocol address field as value as you can’t use Field Occurrence on standard column definitions. The “Field Occurrence” field is used to set the index of the occurrence of the field in the packet decode, so “1” for the first, “2” for the second, and so on. Setting it to “0” shows all occurrences, separated by comma, which is the default. You can also use negative numbers for the index, making Wireshark count the occurrence from the last to the first, so “-1” would be the last, “-2” the second to last.
Pro Tip: If you try adding occurrence to standard column definitions they’ll turn into custom columns, and you need to fill in the filter value for the field if you want to use it that way.
Things outside the Box
There’s at least one other thing custom columns are very useful for: if you need to process data in a way that Wireshark can’t, e.g. creating a graph of IP TTL values. What you could do is use Excel or any other spreadsheet application for that kind of thing, but first you need to get the data out of Wireshark – and you can do that for any field values by using custom columns. Just add a custom column for the data you need, and then export your packet list to a comma separated value text file via the “File” -> “Export Packet Dissections” (a bit misleading, as you’re going to export the packet column data) -> “As CSV”.
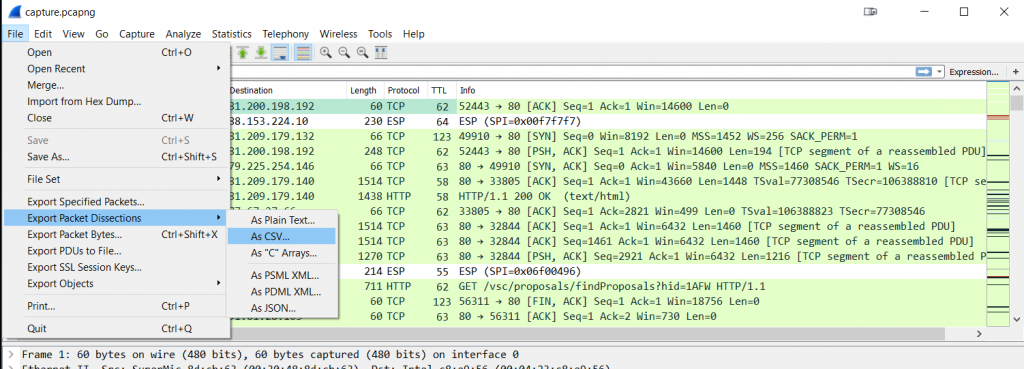
Figure 14 – Export column values as CSV
Just make sure that you uncheck the “Packet Details” checkbox, because otherwise you’ll have more than just the column values you want. After that, import the CSV file into your spreadsheet application and do whatever you want to do with the data. One of the coolest use cases for this was when years ago my team member Landi wanted to show that there was buffer bloat happening on a Cisco switch and he exported the bytes in flight to show that there was packet loss whenever the values went up past 100.000 bytes in flight – because that’s how big the buffer was, dropping packets when more bytes came in than it could hold. It was a perfect saw-tooth graph in Excel.
Removing columns
Removing columns is pretty easy: you either delete them in the preferences dialog, or via right click on the column header and selecting “Remove this Column” in the pop-up menu. One thing that may not be immediately obvious is that you can temporarily hide columns you don’t need, which is something I do a lot. Instead of creating multiple profiles I just add and hide columns, which is much faster (okay. I’m talking about a few mouse clicks here, but anything that slows me down is not going to happen :-)). For example, if I want to remove the TTL column for a while but may need it again later, I just uncheck it in the pop-up menu of the column header:
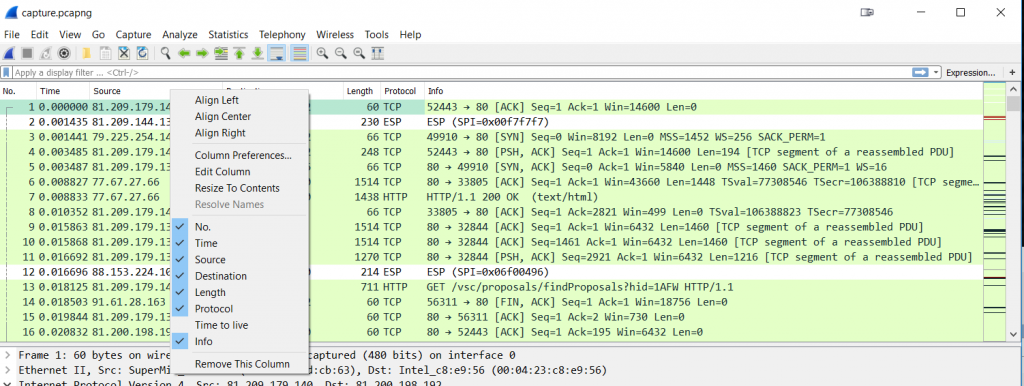
Figure 15 – Hiding a column
Final Words
When I setup my Wireshark configuration, I usually only add a few additional columns to the default setup:
- Delta Time Displayed, because I need to be able to see the time that passed between packets. In most cases that means something like “time between request from the client, and the response from the server”. Keep in mind that you need to isolate conversations via filter first. This column is absolutely critical to have if you do performance analysis or troubleshooting.
- Absolute Date and Time, because I often have to correlate packets with timestamps from other sources, e.g log files or notes taken during capture
- Cumulative Bytes, telling me how many bytes were transferred since the last time reference point
Other Wireshark gurus have a lot more columns than I do, mostly depending on what tasks they have to perform. If you do malware analysis like Brad Duncan from malware-traffic-analysis.net you probably need columns like http.host or URLs called, and remove No, length and protocol columns instead (for more on this check out his blog post that I only discovered an hour after publishing this article. duh!). For SMB analysis you’d go for columns telling you about SMB file access operations and error codes. Same for VoIP. TCP analysts often have columns telling them how long it took to ACK a packet, the next expected sequence number, or how many bytes in flight a TCP conversation has. My friend Hansang has a column set that boggles my mind when I see it, with about half a dozen of additional TCP values in custom columns. I prefer calculating them in my head and keeping them in mind, which may sound weird, but that’s how I work. I also have all my time columns on the right, because that’s what I’m used to (from my Network General Sniffer days).
And in the end, as Chris Greer put it in his great “TCP Fundamentals” presentation at Sharkfest 2018: you can’t just copy a profile (including the column settings) from somebody else, because everybody likes/needs a different set of columns for the tasks he wants to perform with Wireshark. But if you know what the columns are, you can build your own. And I hope this post helped a little with that. To get some more ideas, check out the Wireshark profiles repository. But don’t forget: you need to setup Wireshark your way, and your way only.
Как читать пакеты в Wireshark

Для многих ИТ-специалистов Wireshark – это инструмент для анализа сетевых пакетов. Программное обеспечение с открытым исходным кодом позволяет вам тщательно изучить собранные данные и определить корень проблемы с повышенной точностью. Кроме того, Wireshark работает в режиме реального времени и использует цветовое кодирование для отображения перехваченных пакетов, а также другие изящные механизмы.
В этом руководстве мы объясним, как захватывать, читать и фильтровать пакеты с помощью Wireshark. Ниже вы найдете пошаговые инструкции и описание основных функций сетевого анализа. Освоив эти основные шаги, вы сможете более эффективно проверять поток трафика в вашей сети и устранять проблемы.
Анализ пакетов
После захвата пакетов Wireshark упорядочивает их на панели подробного списка пакетов, которую невероятно легко читать. Если вы хотите получить доступ к информации об одном пакете, все, что вам нужно сделать, это найти его в списке и щелкнуть. Вы также можете расширить дерево, чтобы получить доступ к сведениям о каждом протоколе, содержащемся в пакете.
Для более полного обзора вы можете отобразить каждый захваченный пакет в отдельном окне. Вот как это сделать:
- выберите пакет из списка с помощью курсора, затем щелкните правой кнопкой мыши.

- Откройте “Просмотр” на панели инструментов выше.

- Выберите “Показать пакет в новом Окно” из раскрывающегося меню.

Примечание. Это намного проще. для сравнения захваченных пакетов, если вы открываете их в отдельных окнах.
Как уже упоминалось, Wireshark использует систему цветового кодирования для визуализации данных. Каждый пакет помечен своим цветом, который представляет разные типы трафика. Например, TCP-трафик обычно выделяется синим цветом, а черный используется для обозначения пакетов, содержащих ошибки.
Конечно, вам не нужно запоминать значение каждого цвета. Вместо этого вы можете проверить на месте:
- щелкните правой кнопкой мыши пакет, который хотите проверить.

- Выберите “Просмотр” на панели инструментов в верхней части экрана.

- Выберите &ldquo ;Правила раскраски” в раскрывающемся списке.

Вы увидите возможность настроить раскраску по своему вкусу. Однако, если вы хотите только временно изменить правила раскраски, выполните следующие действия:
- щелкните правой кнопкой мыши пакет в области списка пакетов.
- В списке параметров выберите “Раскрасить с помощью фильтра”

- Выберите цвет, которым вы хотите его пометить.

Число
Панель списка пакетов покажет вам точное количество захваченных битов данных. Поскольку пакеты организованы в несколько столбцов, их довольно легко интерпретировать. Категории по умолчанию:
- Нет. (Число): Как уже упоминалось, вы можете найти точное количество захваченных пакетов в этом столбце. Цифры останутся прежними даже после фильтрации данных.
- Время. Как вы уже догадались, здесь отображается временная метка пакета.
- Источник: показывает, откуда поступил пакет.
- Назначение: показывает место, где будет храниться пакет.
- Протокол: показывает имя протокола, обычно в виде аббревиатуры.
- Длина: показывает количество байтов, содержащихся в захваченном пакете.
- Информация : столбец включает любую дополнительную информацию о конкретном пакете.
Время
Поскольку Wireshark анализирует сетевой трафик, каждому захваченному пакету присваивается отметка времени. Затем метки времени включаются в панель списка пакетов и доступны для последующего просмотра.
Wireshark не создает метки времени самостоятельно. Вместо этого инструмент-анализатор получает их из библиотеки Npcap. Однако источником метки времени на самом деле является ядро. Вот почему точность метки времени может варьироваться от файла к файлу.
Вы можете выбрать формат, в котором временные метки будут отображаться в списке пакетов. Кроме того, вы можете установить предпочтительную точность или количество отображаемых десятичных разрядов. Помимо настройки точности по умолчанию, также есть:
- секунды
- десятые доли секунды
- Сотые доли секунды
- Миллисекунды
- Микросекунды
- Наносекунды
Источник
Как следует из названия, источником пакета является место происхождения. Если вы хотите получить исходный код репозитория Wireshark, вы можете загрузить его с помощью клиента Git. Однако этот метод требует наличия учетной записи GitLab. Можно обойтись и без него, но на всякий случай лучше зарегистрироваться.
Зарегистрировав аккаунт, выполните следующие действия:
- Убедитесь, что Git работает, с помощью этой команды: “$ git -–версия”

- Дважды проверьте, настроены ли ваш адрес электронной почты и имя пользователя.
- Затем создайте клон исходного кода Workshark. Используйте “$ git clone -o upstream [email protected]:wireshark/wireshark.git” URL-адрес SSH для создания копии.
- Если у вас нет учетной записи GitLab, попробуйте URL-адрес HTTPS: “$ git clone -o upstream https://gitlab.com/wireshark/wireshark.git.”

Все исходники впоследствии будут скопированы на ваше устройство. Имейте в виду, что клонирование может занять некоторое время, особенно если у вас медленное сетевое соединение.
Назначение
Если вы хотите узнать IP-адрес определенного адресата пакета, вы можете использовать фильтр отображения, чтобы найти его. Вот как это сделать:
- Введите “ip.addr == 8.8.8.8” в окно «Фильтр» Wireshark. Затем нажмите “Ввод”

- Панель списка пакетов будет перенастроена только для отображения адресата пакета. Найдите интересующий вас IP-адрес, прокрутив список.

- После того, как вы закончите, выберите “Очистить” с панели инструментов, чтобы перенастроить панель списка пакетов.
Протокол
Протокол — это руководство, определяющее передачу данных между различными устройствами, подключенными к одной и той же сети. Каждый пакет Wireshark содержит протокол, и вы можете вызвать его с помощью фильтра отображения. Вот как это сделать:
- В верхней части окна Wireshark нажмите “Фильтр” диалоговое окно.
- Введите имя протокола, который хотите проверить. Обычно заголовки протоколов пишутся строчными буквами.
- Нажмите “Ввод” или «Применить» чтобы включить фильтр отображения.
Длина
Длина пакета Wireshark определяется количеством байтов, захваченных в этой конкретной сети. фрагмент. Это число обычно соответствует количеству байтов необработанных данных, указанному в нижней части окна Wireshark.
Если вы хотите изучить распределение длин, откройте вкладку “Длины пакетов” окно. Вся информация разделена на следующие столбцы:
- Длина пакетов
- Количество
- Среднее
- Мин. значение/макс. значение
- Скорость
- Процент
- Скорость серийной съемки
- Начало серийной съемки
Информация
Если в конкретном захваченном пакете есть какие-либо аномалии или подобные элементы, Wireshark заметит это. Затем информация будет отображаться на панели списка пакетов для дальнейшего изучения. Таким образом, вы получите четкое представление о нетипичном поведении сети, что приведет к более быстрой реакции.
Дополнительные часто задаваемые вопросы
Как фильтровать данные пакета?
Фильтрация — это эффективная функция, позволяющая изучить особенности конкретной последовательности данных. Существует два типа фильтров Wireshark: захват и отображение. Фильтры захвата предназначены для ограничения захвата пакетов в соответствии с конкретными требованиями. Другими словами, вы можете просеивать различные типы трафика, применяя фильтр захвата. Как следует из названия, фильтры отображения позволяют оттачивать определенный элемент пакета, от длины пакета до протокола.
Применение фильтра — довольно простой процесс. Вы можете ввести название фильтра в диалоговом окне в верхней части окна Wireshark. Кроме того, программа обычно автоматически дополняет имя фильтра.
Кроме того, если вы хотите просмотреть стандартные фильтры Wireshark, сделайте следующее:
1. Откройте “Анализ” на панели инструментов в верхней части окна Wireshark.

2. В раскрывающемся списке выберите “Фильтр отображения”

3. Просмотрите список и выберите тот, который хотите применить.

Наконец, вот несколько распространенных фильтров Wireshark, которые могут пригодиться:
• Чтобы просмотреть только IP-адрес источника и получателя, используйте: “ip.src==IP-адрес и ip.dst==IP-адрес”
• Чтобы просмотреть только SMTP-трафик, введите: “tcp.port eq 25”
• Чтобы захватить весь трафик подсети, примените: “net 192.168.0.0/24”
• Чтобы захватить все, кроме трафика ARP и DNS, используйте: “port not 53 and not arp”
Как захватить данные пакета в Wireshark?
После того как вы загрузили Wireshark на свое устройство, вы можете начать отслеживать сетевое подключение . Чтобы захватить пакеты данных для всестороннего анализа, вам нужно сделать следующее:
1. Запустите Wireshark. Вы увидите список доступных сетей, поэтому выберите ту, которую хотите изучить. Вы также можете применить фильтр захвата, если хотите точно определить тип трафика.
2. Если вы хотите проверить несколько сетей, используйте сочетание клавиш “shift + щелчок левой кнопкой мыши” контроль.
3. Затем нажмите крайний левый значок плавника акулы на панели инструментов выше.
4. Вы также можете начать захват, нажав кнопку “Capture” вкладку и выбрав “Пуск” из выпадающего списка.
5. Другой способ сделать это — использовать “Control – E” нажатия клавиши.
По мере того, как программа захватывает данные, вы увидите их в панели списка пакетов в режиме реального времени.
Shark Byte
Несмотря на то, что Wireshark — это высокотехнологичный сетевой анализатор, его удивительно легко интерпретировать. Панель списка пакетов чрезвычайно обширна и хорошо организована. Вся информация разделена на семь различных цветов и помечена четкими цветовыми кодами.
Кроме того, программное обеспечение с открытым исходным кодом поставляется с множеством легко применимых фильтров, облегчающих мониторинг. Включив фильтр захвата, вы можете точно определить, какой трафик вы хотите анализировать Wireshark. И как только данные собраны, вы можете применить несколько фильтров отображения для определенных поисков. В целом, это очень эффективный механизм, который не так уж сложно освоить.
Используете ли вы Wireshark для анализа сети? Что вы думаете о функции фильтрации? Сообщите нам в комментариях ниже, есть ли полезная функция анализа пакетов, которую мы пропустили.
tcp.length and tcp.data wireshark filters
I was playing with Wireshark and noticed two filters: tcp.len and tcp.data . What is the difference between the two? As far as I know, the tcp.len (length) field tells how many bytes of data travel within a segment, correct?
thanks in advance 🙂
![]()
1 Answer 1
Simply put, tcp.len filters the length of TCP segment data in bytes, while tcp.data (or tcp.segment_data in newer versions of Wireshark) filters for the actual data (sequence of bytes) within the TCP segment data.
Example:
-
tcp.len == 1
- Filters for TCP segment data that contains the hexadecimal sequence of 49:27:6d:20:64:61:74:61
-
Filters for TCP segment data that is exactly 1 byte in length
-
The Overflow Blog
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.3.3.43278
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Фильтры захвата для сетевых анализаторов (tcpdump, Wireshark, Paketyzer)
Список основных примитивов, которые могут быть использованы для написания фильтров захвата, показан в таблице 2-1.
Таблица 2-1. Список основных примитивов, которые могут быть использованы для написания фильтров захвата.
| Примитив | Описание |
| dst host ip_address | Захватывать кадры, в которых в поле адреса получателя заголовка IPv4/IPv6 содержит заданный адрес узла |
| src host ip_address | Захватывать кадры, в которых в поле адреса отправителя заголовка IPv4/IPv6 содержит заданный адрес узла |
| host ip_address | Захватывать кадры, в которых в поле адреса отправителя или получателя заголовка IPv4/IPv6 содержит заданный адрес узла. Эквивалентен фильтру: ether proto ip and host ip_address |
| ether dst mac_address | Захватывать кадры, в которых в поле адреса получателя заголовка канального уровня содержит заданный MAC адрес узла |
| ether src mac_address | Захватывать кадры, в которых в поле адреса отправителя заголовка канального уровня содержит заданный MAC адрес узла |
| ether host mac_address | Захватывать кадры, в которых в поле адреса отправителя или получателя заголовка канального уровня содержит заданный MAC адрес узла |
| dst net network | Захватывать кадры, в которых в поле адреса получателя заголовка IPv4/IPv6 содержит заданный адрес, принадлежащий диапазону указанной классовой сети |
| src net network | Захватывать кадры, в которых в поле адреса отправителя заголовка IPv4/IPv6 содержит заданный адрес, принадлежащий диапазону указанной классовой сети |
| net network | Выбирает все пакеты IPv4/IPv6, содержащие адреса из указанной сети в поле отправителя или получателя |
| net network mask mask | Захватывать кадры, в которых в поле адреса отправителя или получателя заголовка IPv4/IPv6 содержит заданный адрес, принадлежащий диапазону указанной сети |
| net network/mask_length | Захватывать кадры, в которых в поле адреса отправителя или получателя заголовка IPv4/IPv6 содержит заданный адрес, принадлежащий диапазону указанной сети |
| dst port port | Захватывать кадры, в которых в поле порт получателя заголовка UDP или TCP содержит заданный номер порта |
| src port port | Захватывать кадры, в которых в поле порт отправителя заголовка UDP или TCP содержит заданный номер порта |
| port port | Захватывать кадры, в которых в поле порт отправителя заголовка UDP или TCP содержит заданный номер порта |
| less length | Захватывать кадры, размер которых не больше указанного значения |
| greater length | Захватывать кадры, размер которых не меньше указанного значения |
| ip proto protocol | Захватывать кадры, в которых в поле «Protocol» заголовка IPv4, содержится идентификатор указанного протокола. При этом можно указывать не только численные значения протоколов, но и их стандартные имена (icmp, igmp, igrp, pim, ah, esp, vrrp, udp, tcp и другие). Однако следует учитывать, что tcp, udp и icmp используются также в качестве ключевых слов, поэтому перед этими символьными идентификаторами следует помешать символ обратного слэша («\») |
| ip6 proto protocol | Захватывать кадры, в которых в поле «Protocol» заголовка IPv4, содержится идентификатор указанного протокола. При этом можно указывать не только численные значения протоколов, но и их стандартные имена (icmp6, igmp, igrp, pim, ah, esp, vrrp, udp, tcp и другие). Однако следует учитывать, что tcp, udp и icmp6 используются также в качестве ключевых слов, поэтому перед этими символьными идентификаторами следует помешать символ обратного слэша («\») |
| ether broadcast | Захватывать все широковещательные кадры Ethernet. Ключевое слово ether может быть опущено |
| ip broadcast | Захватывать кадры, содержащие широковещательные адреса в заголовке пакета IPv4. При этом для определения, является ли адрес широковещательным, используется маски подсети для интерфейса, который используется для захвата пакетов. Так же захватывает пакеты, отправленные на ограниченный широковещательный адрес |
| ether multicast | Захватывать все групповые кадры Ethernet. Ключевое слово ether может быть опущено |
| ip multicast | Захватывать кадры, содержащие групповые адреса в заголовке пакета IPv4 |
| ip6 multicast | Захватывать кадры, содержащие групповые адреса в заголовке пакета IPv6 |
| ether proto protocol_type | Захватывать кадры Ethernet с заданным типом протокола. Протокол может быть указан по номеру или имени (ip, ip6, arp, rarp, atalk, aarp, decnet, sca, lat, mopdl, moprc, iso, stp, ipx, netbeui) |
| ip, ip6, arp, rarp, atalk, aarp, decnet, iso, stp, ipx, netbeui, tcp, udp, icmp | Захватывать кадры передающие данные указанного протокола. Используются в качестве сокращения для: ether proto protocol |
| vlan [vlan_id] | Захватывать кадры соответствующе стандарту IEEE 802.1Q. Если при этом указан номер vlan_id, то захватываются только кадры принадлежащие указанному VLAN |
3. Расширенные примеры фильтров захвата
В котором в качестве expression могут быть константы, результаты арифметических (+, -, *, /) или двоичных побитовых операций (& — «И», | — «ИЛИ», << — сдвиг влево, >> — сдвиг вправо), оператор длинны offset, данные или поля заголовков кадра. В качестве операции могут быть применены символы «>» (больше), «<» (меньше), «>=» (больше равно), «<=» (меньше равно), «=» (равно), «!=» (не равно). Таким образом, можно выполнять проверку на совпадение или не совпадение определенных полей или байт кадра с необходимыми значениями, сравнивать разные поля заголовков между собой, а также выполнять над ними некоторые арифметические и логические операции и сравнивать результаты этих операций с определенными значениями.
Простейшим примером использования расширенного фильтра будет «5 = 3+1», где «5» и «3+1» — expression, а «=» — операция. В результате вычисления этой строки будет возвращено логическое значение, в данном случае false.
Для получения данных или заголовков кадра используется примитив proto[offset:size].
Могут быть ситуации, в которых необходимо анализировать только часть бит, определенного байта. Для решения этих задач используется битовая операция «И» (&). С ее помощью можно сохранить только определенные биты байта, а остальные обнулить.
Например, нам необходимо выделить только те кадры, которые передаются на канальном уровне широковещательными или групповыми кадрами. Мы знаем, что определить тип MAC адреса можно по его старшему байту:
| Тип адреса | Значение старшего байта в 16-й системе | Значение старшего байта в 2-й системе |
| Направленные\Unicast | 00 | 0000000 0 |
| Групповые\Multicast | 01 | 0000000 1 |
| Административно назначенные\Admin ID | 01 | 0000001 0 |
| Широковещательные\Broadcast | FF | 1111111 1 |
Исходя из этой информации, можно сделать вывод о том, то в широковещательных или групповых адресах младший бит старшего байта адреса равен единице, а в остальных – нулю. Если мы возьмем старший байта адреса, обнулим все его биты кроме самого младшего, и при этом значение байта станет равным единице, то этот адрес был или широковещательным, или групповым, если значение байта станет равным нулю, то этот адрес были или направленным, или административно заданным. В результате для выполнения данной проверки необходимо использоваться следующее выражение: ether[0]&1 = 1, где ether[0] – получает значение первого байта Ethernet заголовка, а &1 — битовая операция логическое «И», обнуляющая все биты этого байта, кроме младшего, «= 1» — проверка результата на совпадение с единицей.
Разберем еще один пример более подробно.
Нам нужно получить содержимое поля Type Of Service (ToS) заголовка IPv4. Для этого обратившись к RFC-791 мы увидим, что это поле является однобайтовым полем, и вторым байтом заголовка:
Каким бы ни было значение остальных бит, при накладывании этой маски в результат попадет только значение интересующего нас поля. Даже если мы установим все биты в единицу, это не повлияет на результат:
Таким образом, если интересующий нас бит равен единице, в результате наложения маски мы получим вес этого бита, если он равен нулю, то мы получим ноль.
Исходя из этого, для решения этой задачи нам необходимо применить следующий фильтр:
ip[1:1] & 2 = 2
Он будет брать значение второго байта, накладывать на него маску «вырезающую» значение определенного бита и сравнивать результат с весом этого бита.
Можно привести еще один пример на основании анализа поля Type Of Service заголовка IP: нам нужно увидеть все кадры, в которых в заголовке IPv4 в поле ToS значение битов Precedence (предпочтительность) не равна нулю. Для этого применим маску, в который единичками выделим те биты, которые отвечают за Precedence:
Результат не равен нулю, и это говорит о том, что поле Precedence так же не равно нулю.
Результат равен нулю, и это говорит о том, что поле Precedence так же равно нулю.
В результате, проверка на ненулевое значение поля ToS в заголовке IPv4 будет выглядеть следующим образом:
ip[1:1] & 224 != 0
или же тоже самое, но используя шестнадцатеричный вариант:
ip[1:1] & 0xe0 != 0
Рассмотрим пример с другим протоколом. Возьмем протокол TCP.
Например, нам нужно захватить все кадры, которые передают TCP сегменты с опциями. Для того что бы понять, что нужно искать и где обратимся к RFC-793.
Значение байта стала равно 120 – уменьшилось в два раза.
Как эту операцию мы можем использовать? Давайте вспомним, что поле IHL (Internet Header Length) заголовка IP указывает длину заголовка не в байтах, а в четырехбайтовых словах, и для того что бы проверить, содержит ли пакет опции мы применяли следующую операцию:
ip[0]&0xf = 5
То есть сравнивали не с реальным значением, а со значением, разделенным на четыре (20 байт это 5 четырехбайтовых слов). Если по каким-то причинам удобней работать с длиной заголовка в байтах (например, если это значение надо впоследствии вычесть из общей длины пакета), то его необходимо умножить на 4. Для того что бы умножить число на 4, его нужно дважды умножить на два, то есть провести операцию битового сдвига влево дважды, после чего сравнить с необходимой длинной IP заголовка в байтах:
ip[0]<<2 = 20