Grafana support for Prometheus
Grafana supports querying Prometheus. The Grafana data source for Prometheus is included since Grafana 2.5.0 (2015-10-28).
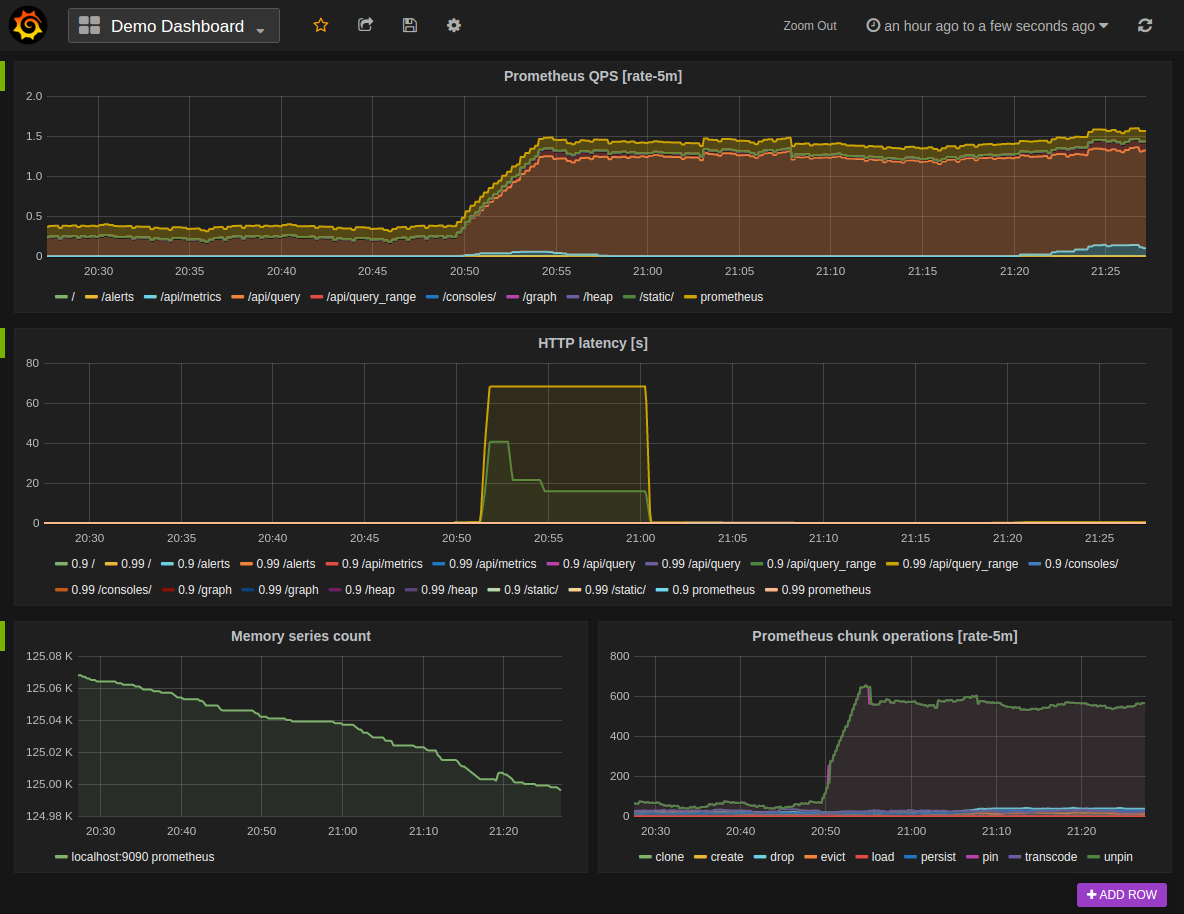
The following shows an example Grafana dashboard which queries Prometheus for data:
Installing
Using
By default, Grafana will be listening on http://localhost:3000. The default login is «admin» / «admin».
Creating a Prometheus data source
To create a Prometheus data source in Grafana:
- Click on the «cogwheel» in the sidebar to open the Configuration menu.
- Click on «Data Sources».
- Click on «Add data source».
- Select «Prometheus» as the type.
- Set the appropriate Prometheus server URL (for example, http://localhost:9090/ )
- Adjust other data source settings as desired (for example, choosing the right Access method).
- Click «Save & Test» to save the new data source.
The following shows an example data source configuration:

Creating a Prometheus graph
Follow the standard way of adding a new Grafana graph. Then:
- Click the graph title, then click «Edit».
- Under the «Metrics» tab, select your Prometheus data source (bottom right).
- Enter any Prometheus expression into the «Query» field, while using the «Metric» field to lookup metrics via autocompletion.
- To format the legend names of time series, use the «Legend format» input. For example, to show only the method and status labels of a returned query result, separated by a dash, you could use the legend format string <
> — < > . - Tune other graph settings until you have a working graph.
The following shows an example Prometheus graph configuration: 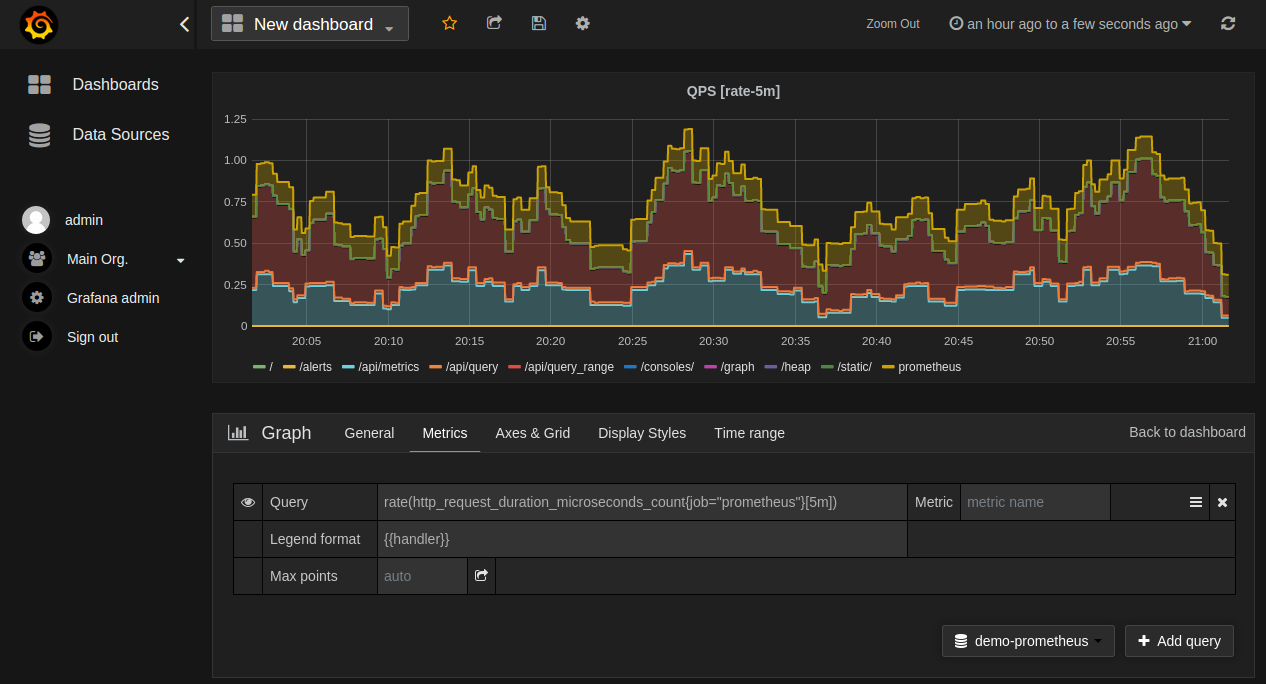
In Grafana 7.2 and later, the $__rate_interval variable is recommended for use in the rate and increase functions.
Importing pre-built dashboards from Grafana.com
Grafana.com maintains a collection of shared dashboards which can be downloaded and used with standalone instances of Grafana. Use the Grafana.com «Filter» option to browse dashboards for the «Prometheus» data source only.
You must currently manually edit the downloaded JSON files and correct the datasource: entries to reflect the Grafana data source name which you chose for your Prometheus server. Use the «Dashboards» → «Home» → «Import» option to import the edited dashboard file into your Grafana install.
Основы мониторинга (обзор Prometheus и Grafana)
Мониторинг сегодня – фактически обязательная «часть программы» для компании любых размеров. В данной статье мы попробуем разобраться в многообразии программного обеспечения для мониторинга и рассмотрим подробнее одно из популярных решений – систему на основе Prometheus и Grafana

История и определение
На заре появления компьютерных сетей в конце 1970х – начале 1980х гг. главной задачей мониторинга была проверка связности и доступности серверов. В 1981 году появился протокол ICMP, на основе которого в декабре 1983 года написана утилита ping, а позднее и traceroute, которые используются для диагностики сетевых неполадок и по сей день. Следующим этапом стало создание в 1988 году протокола SNMP, что привело к рождению MRTG – одной из первых программ для мониторинга и измерения нагрузки трафика на сетевые каналы. Параллельно с середины 1980х гг. стало активно разрабатываться программное обеспечение для мониторинга потребления ресурсов компьютерами, такое как top, vmstat, nmon, Task Manager и др. К середине 1990х годов в связи с ростом ИТ инфраструктуры многие компании стали испытывать потребность в комплексной и централизованной системе мониторинга, что послужило спусковым крючком для синхронного начала разработки нескольких прототипов. В 1999-2002 гг. на свет появились решения, предопределившие развитие отрасли на годы вперед и развивающиеся до сих пор – Cacti, Nagios и Zabbix.
Мониторинг в ИТ сегодня – это система, которая позволяет в режиме реального времени выявлять проблемы в ИТ инфраструктуре, а также оценивать тренды использования ресурсов. Как правило состоит из нескольких базовых компонентов – сбора сырых данных, обработки данных с целью их анализа, рассылки уведомлений и пользовательского интерфейса для просмотра графиков и отчетов. В настоящее время существует большое количество систем для мониторинга различных категорий – сети, серверной инфраструктуры, производительности приложений (APM), реального пользователя (RUM), безопасности и др. Таким образом, мониторить можно все – от сетевой доступности узлов в огромной корпорации до значений датчика температуры в спальне в «умном» доме.
Обзор систем мониторинга
Для цельности картины рассмотрим несколько примеров систем мониторинга:
PingInfoView, SolarWinds pingdom и др.
Ping – наиболее известный способ проверки доступности узлов в сети. Программы, умеющие с определенным интервалом пинговать набор сетевых узлов и отражающие в режиме реального времени графики доступности, по сути есть зародыш системы мониторинга. Выручат, если полноценной системы мониторинга еще нет
Zabbix
Поддерживает сбор данных из различных источников – как с помощью агентов (реализованы под большинство распространенных платформ), так и без них (agent-less) посредством SNMP и IPMI, ODBC, ICMP и TCP проверок, HTTP запросов и т.д., а также собственных скриптов. Имеются инструменты для преобразования и анализа данных, подсистема рассылки уведомлений и веб-интерфейс. Свободно распространяется по лицензии GNU GPL v2 (бесплатно)
PRTG
Поддерживает сбор данных без агентов посредством преднастроенных сенсоров SNMP, WMI, Database, ICMP и TCP проверок, HTTP запросов и т.д., а также собственных скриптов. Имеются инструменты для анализа данных, удобная подсистема рассылки уведомлений и веб-интерфейс. Является коммерческим продуктом, лицензируется по количеству сенсоров. PRTG Network Monitor с количеством сенсоров не более 100 доступен для использования бесплатно
Nagios Core / Nagios XI
Поддерживает сбор данных с помощью агентов (реализованы под большинство распространенных платформ) и без них посредством SNMP и WMI, а также расширений и собственных скриптов. Имеются инструменты для анализа данных, подсистема рассылки уведомлений и веб-интерфейс. Nagios Core свободно распространяется по лицензии GNU GPL v2 (бесплатно), Nagios XI является коммерческим продуктом. Подробнее о различиях между Nagios Core и Nagios XI можно почитать в статье Nagios Core vs. Nagios XI: 4 Key Differences
Icinga
Появилась как форк Nagios. Поддерживает сбор данных с помощью агентов, а также расширений и собственных скриптов. Имеются инструменты для анализа данных, подсистема рассылки уведомлений и веб-интерфейс. Свободно распространяется по лицензии GNU GPL v2 (бесплатно)
Prometheus
Ядро – БД временных рядов (Time series database, TSDB). Поддерживает сбор данных из различных источников посредством экспортеров и шлюза PushGateway. Имеются инструменты для анализа данных, подсистема уведомлений и простой веб-интерфейс. Для визуализации рекомендуется использовать Grafana. Свободно распространяется по лицензии Apache License 2.0 (бесплатно)
VictoriaMetrics
Ядро – БД временных рядов (TSDB). Поддерживает сбор данных из различных источников посредством экспортеров (совместимых с Prometheus), интеграции с внешними системами (например, Prometheus) и прямых запросов на вставку. Имеются инструменты для анализа данных, подсистема уведомлений и простой веб-интерфейс. Для визуализации рекомендуется использовать Grafana. Свободно распространяется по лицензии Apache License 2.0 (бесплатно)
Grafana
Не является системой мониторинга, однако не упомянуть ее в контексте статьи просто нельзя. Является прекрасной системой визуализации и анализа информации, которая позволяет «из коробки» работать с широким спектром источников данных (data source) – Elasticsearch, Loki, MS SQL, MySQL, PostgreSQL, Prometheus и др. При необходимости также интегрируется с Zabbix, PRTG и др. системами. Свободно распространяется по лицензии GNU AGPL v3 (бесплатно)
Работа с Prometheus и Grafana
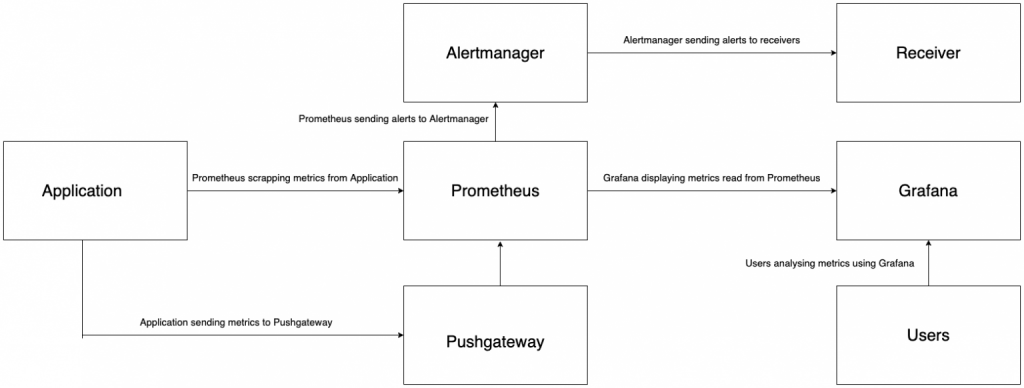
Рассмотрим подробнее схему взаимодействия компонентов системы мониторинга на основе Prometheus. Базовая конфигурация состоит из трех компонентов экосистемы:
Экспортеры (exporters)
Экспортер собирает данные и возвращает их в виде набора метрик. Экспортеры делятся на официальные (написанные командой Prometheus) и неофициальные (написанные разработчиками различного программного обеспечения для интеграции с Prometheus). При необходимости есть возможность писать свои экспортеры и расширять существующие дополнительными метриками
Prometheus
Получает метрики от экспортеров и сохраняет их в БД временных рядов. Поддерживает мощный язык запросов PromQL (Prometheus Query Language) для выборки и аггрегации метрик. Позволяет строить простые графики и формировать правила уведомлений (alerts) на основе выражений PromQL для отправки через Alertmanager
Alertmanager
Обрабатывает уведомления от Prometheus и рассылает их. С помощью механизма приемников (receivers) реализована интеграция с почтой (SMTP), Telegram, Slack и др. системами, а также отправка сообщений в собственный API посредством вебхуков (webhook)
Таким образом, базовая конфигурация позволяет собирать данные, писать сложные запросы и отправлять уведомления на их основе. Однако по-настоящему потенциал Prometheus раскрывается при добавлении двух дополнительных компонентов (или как минимум одного – Grafana):
VictoriaMetrics
Получает метрики из Prometheus посредством remote write. Поддерживает язык запросов MetricsQL, синтаксис которого совместим с PromQL. Предоставляет оптимизированное по потреблению ресурсов хранение данных и высокопроизводительное выполнение запросов. Идеально подходит для долговременного хранения большого количества метрик
Имеет ли смысл рассматривать VictoriaMetrics как полноценную замену Prometheus, а не его дополнение (параллельную инсталляцию)? Вероятнее всего да. Экспортеры совместимы (для сбора данных можно дополнительно использовать vmagent), а для формирования уведомлений есть vmalert
Grafana
Предоставляет средства визуализации и дополнительного анализа информации из Prometheus и VictoriaMetrics. Есть примеры дашбордов практически под любые задачи, которые при необходимости можно легко доработать. Создание собственных дашбордов также интуитивно (разумеется, за исключением некоторых тонкостей) – достаточно знать основы PromQL / MetricsQL
Де-факто использование Grafana вместе с Prometheus уже стало стандартом, в то время как добавление в конфигурацию VictoriaMetrics безусловно опционально и необходимо скорее для высоконагруженных систем.

Схема взаимодействия компонентов
Практика
Итак, система мониторинга на основе Prometheus – PAVG (Prometheus, Alertmanager, VictoriaMetrics, Grafana) – предоставляет широкий спектр возможностей. Рассмотрим ее практическое применение. Для упрощения предположим, что основные компоненты будут развернуты на одном сервере мониторинга с примением docker и systemd, а также вынесем требования безопасности за рамки данной статьи.
Все ниженаписанное является лишь иллюстрацией, которая призвана помочь ознакомиться с рассматриваемой системой
Развертывание экспортеров
Экспортеры могут быть развернуты на сервере мониторинга (например blackbox), на целевых серверах (kafka, mongodb, jmx и др.) или на всех серверах (node, cadvisor и др.). Как правило не требовательны к аппаратным ресурсам. В качестве примера возьмем три экспортера – node (сбор данных по ЦПУ, ОЗУ, дисковой подсистеме и сети), cadvisor (сбор информации о контейнерах) и blackbox (проверка точек входа TCP, HTTP/HTTPS и др.). Для развертывания необходимо:
How to setup Monitoring using Prometheus and Grafana
So you have finally written and deployed your first microservice? Or maybe you have decided to embark on the microservices adventure to future proof yourself? Either way, Congratulations.
It’s time to take the next step. Its time to set up monitoring!
Why setting up monitoring is important?
Monitoring is super important. It is that part of your system that lets you know what’s going on in your app.
And it isn’t just a dashboard with fancy charts.
Monitoring is the systematic process of aggregating actionable metrics and logs.
The keyword here is actionable.
You are collecting all these metrics and logs to take decisions based on it.
For example, you would want to collect the health of your VMs & microservices to ensure you have enough healthy capacity to service user requests. You’d also like to trigger emails & notifications in case failures go below a certain threshold.
This is what monitoring helps you achieve. This is why you need to set up monitoring.
As its clearly evident, your monitoring stack is a source from which several processes can be automated. So its really important to make sure your monitoring stack is reliable and that it can scale with your application.
Prometheus has become the go-to monitoring stack in recent times.
It’s novel pull-based architecture, along with in-built support for alerting, makes it an ideal choice for a wide variety of workloads.
In this article, we’ll use Prometheus to setup up monitoring. For visualisations, we’ll use Grafana.
This guide is available in video format as well. Feel free to refer to it.
I’ve set up a GitHub repository for you guys as well. Use it to reproduce everything we’ll be doing today.
What is Prometheus and Grafana?
Prometheus is a metrics aggregator.
Instead of your services pushing metrics to it, like in the case of a database, Prometheus pulls metrics from your services.
It expects services to make an endpoint exposing all the metrics in a particular format. All we need to do now is tell Prometheus the address of such services, and it will begin scraping them periodically.
Prometheus then stores these metrics for a configured duration and makes them available for querying. It pretty much acts like a time-series database in that regard.
Along with that, Prometheus has got first-class support for alerting using AlertManager. With AlertManager, you can send notifications via Slack, email, PagerDuty and tons of other mediums when certain triggers go off.
All of this makes it super easy to set up monitoring using Prometheus.
While Prometheus and AlertManager provided a well-rounded monitoring solution, we need dashboards to visualise what’s going on within our cluster. That’s where Grafana comes in.
Grafana is a fantastic tool that can create outstanding visualisation.
Grafana itself can’t store data. But you can hook it up to various sources to pull metrics from including Prometheus.
So the way it works is, we use an aggregator like Prometheus to scrap all the metrics. Then we link Grafana to it to visualise the data in the form of dashboards.
What we’ll be monitoring?
Microservices
We’ll be monitoring two microservices today.
The first microservices is written by a math genius to perform insane calculations. By insane calculations, I mean adding two numbers.
It’s a simple HTTP endpoint expecting two numbers in the request and responds back with the addition of those two numbers.
The second one is a polite greeter service that takes a name as a URL parameter and responds with a greeting.
Here’s what the endpoints look like:
And here’s the link to the code:
-
: Written in Node.js : Written in Golang
Both these services will be running inside Docker. Neither one of them have any code related to monitoring whatsoever. In fact, they don’t even know that they are being monitored.
Wait that doesn’t sound right.
Metrics
We will be monitoring a couple of metrics. This is what the final dashboard will look like.
First is the CPU & memory utilisation of our services. Since all our services will be running in Docker, we’ll use cAdvisor to collect these metrics.
cAdvisor is a really neat tool. It collects container metrics directly from the host and makes it available for Prometheus to scrape. You don’t really need to configure anything for it to work.
We’ll also be collecting HTTP metrics. These are also called l7 metrics.
What we are interested in is the requests coming in per second grouped by response status code. Using this metric alone, we can infer the error rates and total throughput of each service.
Now we could modify our services to collect these metrics and make them available for Prometheus to scrape. But that sounds like a lot of work. Instead, we will use a reverse proxy like HAProxy in front of our services which can collect metrics on our behalf.
The reverse proxy plays two roles, it exposes our apps to the outside world, and it collects metrics while it’s at it.
Unfortunately, HAProxy doesn’t export metrics in a Prometheus compatible format. Luckily the community has built an exporter which can do this for us.
We have a small problem with this setup.
HAproxy won’t capture metrics for direct service to service communication since that will bypass it altogether.
We can solve this loophole entirely by using something we call a service mesh. You can read more about it in this article.
Our Final Monitoring Setup
Our final monitoring setup using Prometheus and Grafana will look something like this:
Deploying our Monitoring Stack
Finally, it’s time to get our hands dirty.
To get our services up, we’ll write a docker-compose file. Docker-compose is an awesome way to describe all the containers we need in a single YAML file. Again, all the resources can be found in this GitHub repo.
I have also gone ahead to make custom config files for Prometheus and HAProxy.
For Prometheus, we are setting up scrapping jobs for cAdvisor and HAProxy exporter. All we need to do is to give Prometheus the host and port of the targets. If not provided explicitly, Prometheus fires HTTP requests on the /metrics endpoint to retreive metrics.
For HAProxy, we configure one backend for each service. We will be splitting traffic between the two microservices based on the incoming request's url. We'll forward the request to the greeter service if the url begins with /greeting . Otherwise, we forward the request to the math service.
Bringing our services online
Now that we have described all our services in a single docker-compose file, we can copy all of this on our VM, ssh into it and then run docker-compose -p monitoring up -d .
Docker will get everything up and running.
These are the ports all the exposed services will be listening on. Make sure these ports are accessible.
- Prometheus: 9090
- Grafana: 3000
- HAProxy: 11000
We can check if Prometheus was configured correctly by visiting http://YOUR_IP:9090/targets . Both the targets (cAdvisor and HAProxy exported) should be healthy.
We can check if our proxy is configured properly by opening the following urls:
- Math Service: http://YOUR_IP:11000/add/1/2
- Greeter Service: http://YOUR_IP:11000/greeting/YourTechBud
Setting up our Monitoring Dashboard
Then the last step remaining would be to configure Grafana.
Visit http://YOUR_IP:3000 to open up Grafana. The default username and password will be admin .
Add Prometheus as a data source
All our monitoring metrics are being scrapped and stored in Prometheus. Hence, the first step is to add Prometheus as a datastore.
To do that, Hit Add a datasource > Select Prometheus from the dropdown > Enter http://prometheus:9090 as the Prometheus url > Hit Save & Test .
That’s all we need to do to link Grafana with Prometheus.
Create our dashboard.
Creating a dashboard from scratch can take time. You can import the dashboard I’ve already made to speed things up.
After hitting the Import Dashboard button in the Manage Dashboards section, simply copy and paste the JSON in the text area and select Prometheus as the data source.
Feel free to refer to this 10 minute video if you get lost.
Wrapping Up
You’ve just setup monitoring using Prometheus and Grafana.
You can edit a chart to see what I’ve done. You’ll see that all it takes to populate a chart is a Prometheus query.
Here’s one query as an example: sum(container_memory_usage_bytes \"monitoring_svc.*\"> / 1024 / 1024) by (name) . This query calculates the total memory being consumed by our two microservices. I agree that the Prometheus queries can be a bit overwhelming. But that doesn’t really matter. You can simply import this dashboard and expect it to just work. Use it as a boilerplate. Mess around with it. Enjoy! Did this article help you? How do you make sure your apps are cloud-native? Share your experiences below. In this article, we are going to learn about a popular monitoring solution for cloud and containers, Prometheus Grafana stack! Prometheus is an open source application which can scrap the real-time metrics to monitor events and also do real-time alerting. Grafana is an analytical and visualization tool which is helpful to create interactive charts & graphs from the data and alerts scraped from the monitoring tools. Table of Contents Monitoring stacks are responsible for analyzing each aspect of how one’s machine has been performing at a given time – whether it’s the percentage of resources being used by processes specifically or if a specific process is crashing & restarting frequently (which may indicate an error or bug), and even stats like who or what process started or shut down over a period of time – they’re constantly watching over the systems to make sure everything is running smoothly and efficiently. Apart from this, there’s yet another reason why monitoring solutions are a necessity nowadays. As the tools and methods get improved, code gets created, tested, and shipped faster, with increased speed comes increased chances of making mistakes! It’s smart not to leave the software to chance! You can always trust your software code… but why take the risk? A monitoring solution helps in just that – by keeping an eye out for potential issues where they usually occur. The most widely used monitoring solution for cloud and containers is – Prometheus-Grafana stack. It’s actually comprised of four components:- Prometheus scrapes metrics from a variety of application endpoints and stores them in its internal database. Grafana then reads these metrics from Prometheus and displays visualizations and dashboards based on these metrics on its UI. Prometheus alerts can also be configured to send notifications to external systems, such that when an event occurs, Prometheus sends the alert data to the Alertmanager which in turn dynamically routes the alerts to different receivers such as email, Slack, or PagerDuty. Some applications do not tell you their metrics via dedicated endpoints and instead rely on an additional component called “exporter” to get their job done. An exporter reads internal data of a particular process and then exposes them through the given endpoint. They are used widely by many popular databases such as Postgres, Redis, etc. For metrics that don’t work with the push model of Prometheus up, a push gateway is utilized. In this article, we are going to see the important features & installation procedures for these components. Though t hese components can be installed on any operating system, here – we are going to install them on Ubuntu 20 which is one of the best linux os for programming . In this article, we are going to lay out the use case of each component and the steps on how to set up a complete monitoring solution. We’re using Ubuntu 20 here as an operating system; however, one can also use them in other operating systems as well. Let’s start with a quick guide ! It works by pulling/scrapping real-time metrics from applications at regular intervals of time by sending HTTP requests on metrics endpoints of applications. After the data is collected, it stores them in an internal time-series database. There are two reasons – Let’s go over the step-by-step procedure. 1. Add prometheus user: 2. Download and install the Prometheus binary: 3. Copy files from prometheus setup: 4. Adding content to prometheus’s configuration file: 5. Give user ‘prometheus’ the permission to the file used to run prometheus server. 6. Add the prometheus startup in the service script. A service unit describes a service or application on the machine will be managed. It includes instructions for starting or stopping the service and many other things. 7. Run the following to add the above service unit and start prometheus. The installation is complete. Prometheus occupies port 9090 by default. Grafana is an open-source tool for displaying visualizations and metrics for analysis that support many 3rd party data sources such as Elasticsearch, Influxdb, Graphite, Prometheus, AWS Cloud Watch, and many others. Grafana can be thought of as the frontend of the monitoring solution i.e. it reads metrics data from Prometheus and displays the metrics in an organized fashion to the user via visualization and graphs. Let’s go over the step-by-step procedure. 1. Add grafana’s required user: 2. Download & install Grafana binary: 3. Run the following to add the above service unit and start grafana. The installation is complete. Grafana occupies port 3000 by default. In a monitoring solution, the most crucial task is of alerting. Metrics collected are analyzed by Prometheus, If it finds something out of order such as memory utilization too high or too many process restarts then it triggers an alert so that a human intervenes. This alerting mechanism is handled by the Alertmanager i.e. Prometheus sends alerts to the Alertmanager, which then sends out a notification requesting human intervention. It takes care of deduplicating, grouping, and routing the alerts to the correct receiver endpoints such as email, PagerDuty, or Slack. It also takes care of silencing and inhibition of alerts. In this way, it helps keep the monitoring solution efficient and reliable. Let’s go over the step-by-step procedure. 1. Add an alertmanager user: 2. Download and install the Prometheus binary: 3. Create folders for use by alertmanager 3. Copy files for alertmanager setup: 4. Assign ownership of files to alertmanager user 5. Create a service file 6. Run the following to add the above service unit and start alertmanager. The installation is complete. Alertmanager occupies port 9093 by default. The Pushgateway is an intermediary component that allows the pushing of metrics from endpoints that cannot be scrapped. In cases where applications die before they even have the chance to let Prometheus find them. For example, if you are using Kubernetes service discovery, and your pods do not live enough to be picked up by Prometheus. Then the typical pull model of Prometheus does not fit anymore because Prometheus cannot find or scrape all of the targets You can send metrics data to the Pushgateway from your script’s output that might have been cut off early, after which the metrics will be eventually ingested by Prometheus. Let’s go over the step-by-step procedure. 1. Add a pushgateway user 2. Download and install the Prometheus binary: 3. Copy files for pushgateway setup: 4. Assign ownership of files to pushgateway user: 5. Create a service file 6. Run the following to add the above service unit and start pushgateway. The installation is complete. Pushgateway occupies port 9091 by default. For accessing the UI of each component, the port must be reachable from outside the server. The way to do differs in each cloud provider. For e.g. In AWS, we need to add an entry for the corresponding ports in the security group and make it accessible from anywhere. Until now, we have understood the function and use case of each component in the monitoring solution, as well as went through the importance of the whole monitoring solution in general. We encourage you to explore more about the components we have described in this tutorial so that you can do some hands-on exercises as well. Why not try connecting Grafana with Prometheus and set up alerts from Alertmanager to Prometheus? Or even attempt something such as setting up alert receivers in AlertManager? These monitoring tools for cloud and containers are so priceless that they’re like the Swiss army knife of every team! These tools will never go out of application stacks! They’re essential to almost every team, so make sure you know how to use them properly.What is Prometheus Grafana Stack ?
What is a monitoring stack ?
Why do we need a monitoring solution for Cloud & Containers?
Common problems that monitoring solutions can detect –
Prometheus Grafana stack
How does Prometheus work with Grafana?
End-to-end Flow
Prometheus – How does it work?
What makes it the de facto monitoring tool?
How to install Prometheus?
Grafana – A short tutorial
What is Grafana?
How does it work?
How to install Grafana?
Alertmanager
How does alerting work?
What is the role of an Alertmanager?
How does Alertmanager help?
How do we install Alertmanager?
Push gateway
When are they required?
What does it do?
How do we install Pushgateway?
Accessing the UI of these components
Final words