Текущая длина очереди диска — как правильно оценить ?
Уже описывал свою конфигурацию: сервер Win2K8 подключен к СХД Xyratex c 12-мя дисками SATA через FC-адаптеры 4Gb\s. На данной полке создано два RAID-5 массива по 5 дисков в каждом, 2 — в глобальном спейре. Сервер (через ЛУН-маппинг) видит один из этих рейдов, на котором нарезаны LUNы для файлопомойки, итого в Windows видно 3 логических диска, физически расположенных на данной полке.
По рекомендации Microsoft параметр системного монитора «Текущая длина очереди диска» при нормальной производительности не должен превышать число шпинделей + 2, т.е. в моем случае этот парамет для логических дисков сервера на данной полке не должен превышеть: 5+2 = 7.
Когда начал мониторить — заметил, что примерно раз в 2-3 минуты, а то и чаще данный параметр подскакивает до 10, а то и выше, правда держится там не долго — меньше 1 секунды.
Правильно ли MS советует оценивать текущую длину очереди диска в случае вот таких LUNов на SAN ?
И в течении какого времени должно быть превышение данного параметра, чтобы это сигнализировало о том что дисковая система не справляется с нагрузкой ?
gs Сотрудник Тринити
Сообщения: 16650 Зарегистрирован: 23 авг 2002, 17:34 Откуда: Москва Контактная информация:
Мониторинг загрузки оборудования в Windows или почему тормозит 1С?
Раннее я уже писал о Системном мониторе и Сборщиках данных загруженности оборудования в операционных системах семейства Windows. В данной статье на примере работы программ системы «1С:Предприятие» версии 8 рассмотрим, где и какие счетчики необходимо включать в замер производительности, а также попробуем проанализировать полученную информацию и сделать соответствующие выводы (данная статья будет полезна не только в случае анализа работы системы «1С:Предприятие» на текущем оборудовании, но и в целом для мониторинга загруженности серверов под управлением Windows).
0. Оглавление
1. Где и зачем вести мониторинг?
Прежде чем приступать к настройке мониторинга загрузки оборудования системы, необходимо понять, является ли сервер, где планируется вести замер, виртуальным? В случае работы с виртуальными машинами замер следует вести как на самом виртуальном сервере так и на физической машине. Т. к. возможна ситуация, когда счетчики производительности на виртуальном сервере не будут фиксировать значительную нагрузку оборудования, когда как физический сервер может быть загружен «соседними» виртуальными машинами или собственными работающими службами. И наоборот, анализ только физического сервера не даст четкого понимания о загрузке виртуальной машины. Только сопоставив данные замера физического и виртуального серверов можно сделать правильные выводы о загруженности оборудования.
В случае анализа загруженности серверов, на которых работают компоненты системы «1С:Предприятие» прежде всего необходим мониторинг:
- Сервера баз данных
- Серверов, на которых запущен кластер серверов «1С:Предприятия»
- В редких случаях сервера терминалов, если такой имеет место быть
2. Основные счетчики производительности
Приведем примеры основных счетчиков производительности, разбив их по типу исследоваемого оборудования (для разных версий Windows названия счетчиков могут немного отличаться).
2.1 Процессоры
Для анализа загруженности процессоров системы, как правило, достаточно 2 счетчиков производительности:
| Счетчик (рус.) | Счетчик (англ.) |
|---|---|
| Описание | Критерий достаточной производительности |
| \Процессор(_Total)\% загруженности процессора | \Processor(_Total)\% Processor Time |
| % загруженности процессора — это доля времени, которую процессор тратит на обработку всех потоков команд, кроме простаивающего. Это значение равно разнице между 100 % и процентом времени, которое процессор затрачивает на выполнение простаивающего потока. Этот счетчик является основным показателем загруженности процессора. Он показывает среднее значение занятости процессора в течение интервала измерения. | Не более 70% в течение длительного времени |
| \Система\Длина очереди процессора | \System\Processor Queue Length |
| Длина очереди процессора — это текущая длина очереди процессора, измеряемая числом ожидающих потоков. Все процессоры используют одну общую очередь, в которой потоки ожидают получения циклов процессора. Этот счетчик не включает потоки, которые выполняются в настоящий момент. Этот счетчик отражает текущее значение, и не является средним значением по некоторому интервалу времени. | Не более 2 * количество ядер процессоров в течение длительного времени |
Для того, чтобы точно оценить, достаточно ли процессорных мощностей на сервере, может также понадобиться счетчик потоков.
| Счетчик (рус.) | Счетчик (англ.) |
|---|---|
| Описание | Критерий достаточной производительности |
| \Система\Потоки | \System\Threads |
| Счетчик потоков — это количество потоков в компьютере в момент сбора информации. Данный показатель представляет собой конкретное текущее значение, и не является средним значением по некоторому интервалу времени. Поток — это базовый занятости процессора в течение интервала измерения. | — |
2.2 Оперативная память
Для анализа достаточности / нехватки оперативной памяти на рабочем сервере, как правило, применяют 2 следующих счетчика:
| Счетчик (рус.) | Счетчик (англ.) |
|---|---|
| Описание | Критерий достаточной производительности |
| \Память\Доступно МБ | \Memory\Avalible Mbytes |
| Доступно МБ — это объем физической памяти в мегабайтах, немедленно доступной для выделения процессу или для использования системой. Эта величина равна сумме памяти, выделенной для кэша, свободной памяти и обнуленных страниц памяти. | — |
| \Память\Обмен страниц/с | \Memory\Pages/sec |
| Обмен страниц/сек — это число страниц, прочитанных с диска или записанных на диск. Эта величина является суммой величин Ввод страниц/сек и Вывод страниц/сек, и включает страничный обмен (подкачку) системной кэш-памяти для доступа к файлам данных для приложений. Кроме того, сюда включается страничный обмен (подкачка) для не кэшированных файлов, непосредственно отображаемых в память. | Не более 20 |
2.3 Жесткие диски
| Счетчик (рус.) | Счетчик (англ.) |
|---|---|
| Описание | Критерий достаточной производительности |
| \Физический диск()\Средняя длина очереди диска | \Physical Disk()\Avg. Disk Queue Length |
| Средняя длина очереди диска — это среднее общее количество запросов на чтение и на запись, которые были поставлены в очередь для соответствующего диска в течение интервала измерения. | Не более 2 * количество дисков, работающих параллельно |
| \Физический диск()\Среднее время записи на диск (с) | \PhysicalDisk()\Avg. Disk Sec/Write |
| Среднее время записи на диск — это время в секундах, затрачиваемое в среднем на одну операцию записи данных на диск. | — |
| \Физический диск()\Среднее время чтения с диска (с) | \PhysicalDisk()\Avg. Disk Sec/Read |
| Среднее время чтения с диска — это время в секундах, затрачиваемое в среднем на одну операцию чтения данных с диска. | — |
2.4 Сетевые интерфейсы
Для каждого из используемых сетевых адаптеров на сервере можно скорость передачи данных через сеть с помощью следующего счетчика:
| Счетчик (рус.) | Счетчик (англ.) |
|---|---|
| Описание | Критерий достаточной производительности |
| \Сетевой адапетер\Всего байт/с | \Network Interface\Bytes Total/sec |
| Всего байт/с — это скорость, с которой происходит получение или посылка байт через сетевые адаптеры, включая символы обрамления (framing characters). Данный счетчик является суммой счетчиков Сетевой интерфейс\Получено байт/с и Сетевой интерфейс\Отправлено байт/с. | Не более 65% от пропускной способности сетевого адаптера |
Смотрите также:
При попытке установить типовую конфигурацию системы «1С:Предприятие» 7.7 в 64-разрядных операционных системах вместо необходимых каталогов с информационными базами увидим ошибку: «Версия этого файла несовместима с используемой версией Windows. С помощью сведений о…
Установка платформы 1С:Предприятие 7.7 на 64-х битную операционную систему сопряжена с некоторыми трудностями. Дело в том, что установить 1С через обычный установщик не получится, даже если запускать программу в режиме…
По умолчанию поиск в Windows (в данном примере в Windows 7) ищет файлы по имени. Содержимое учитывает только в проиндексированных расположениях. Чтобы поиск искал по содержимому всех документов, нужно изменить…
Счетчики производительности для дисковой подсистемы
Дисковая подсистема довольно часто становится узким местом в работе приложений, поэтому очень важно уметь диагностировать проблемы с дисками. Одним из основных инструментов для наблюдения за производительностью дисковой подсистемы являются счетчики производительности, о которых и пойдет сегодня речь.
Для наблюдения за дисками можно выбрать два типа объектов:
• Physical Disk — в качестве объекта мониторинга выступает то, что система определяет как физическое устройство. Это может быть как отдельный жесткий диск, так и несколько дисков, объединенных в RAID-массив. Если физический диск разбит на логические разделы (тома), то счетчики выдают суммарное значение для всех томов, находящихся на диске.
• Logical Disk — здесь в качестве объекта мониторинга выступает логический раздел. Perfmon идентифицирует тома по букве диска или точке монтирования (если том примонтирован как папка). Если физический диск разбит на несколько томов, то счетчики будут выдавать значения для каждого выбранного тома отдельно. Возможна и обратная ситуация, когда при использовании динамических дисков том может быть растянут на несколько физических устройств, тогда счетчики покажут значения сразу для всех физических дисков, входящих в состав логического.
Набор счетчиков для физического и логического диска практически идентичен, за небольшим исключением, о котором чуть позже.
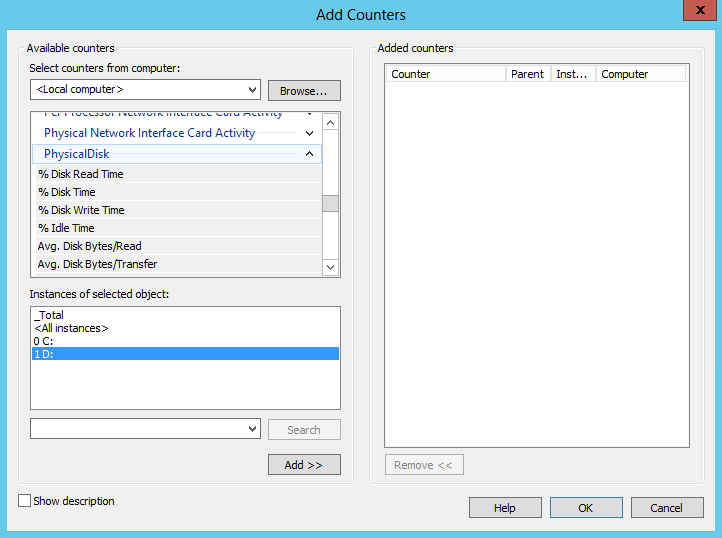
Приступим к описанию счетчиков.
%Disk Time
Показывает процент общей загруженности диска. Представляет из себя сумму значений счетчиков %Disk Read Time (процент загруженности диска операциями чтения) и %Disk Write Time (процент загруженности диска операциями записи). Теоретически его значения должны быть в диапазоне от 0 до 100%, однако это верно только для одиночного диска. При использовании RAID-массивов часто можно увидеть значения этого счетчика больше 100%.
%Idle Time
Показывает время простоя диска, т.е. время, в течении которого диск оставался в состоянии покоя, не обрабатывая запросы чтения\записи. В отличии от %Disk Time лежит строго в диапазоне от 100% (полный покой) до 0 (полная загрузка).
Disk Transfers/sec
Основной показатель интенсивности запросов к диску. Показывает общее количество операций ввода\вывода, обработанных (завершенных) диском в течении 1 секунды (Input/Output Operations Per Second, IOPS). Этот счетчик позволяет примерно оценить, насколько нагрузка на диски близка к предельной. Для дисков, работающих в нормальном режиме, можно ориентироваться на следующие значения: 80-160 IOPS для одиночного жесткого диска SATA или SAS, 1800-5000 IOPS для одиночного SSD диска. Для уточнения можно воспользоваться счетчиками Disk Reads/sec (количество обработанных за секунду запросов на чтение) и Disk Writes/sec (количество обработанных за секунду запросов на запись).
Avg. Disk sec/Transfer
Среднее время в секундах, требуемое для выполнения диском одной операции чтения или записи. Складывается из значений Avg. Disk sec/Read (время на выполнение операции чтения) и Avg. Disk sec/Write (время на выполнение операции записи). Для высоконагруженых систем, таких как сервера БД, значение Avg. Disk sec/Transfer не должно превышать 0,1, для рядовых серверов допустимо значение 0,25.
Эти счетчики стоит отметить особо, так как они позволяют точно определить, сколько времени дисковая подсистема потратила на обслуживание операций ввода\вывода, независимо от используемых аппаратных средств.
Avg. Disk Queue Length
Cредняя длина очереди запросов к диску. Отображает количество запросов к диску, ожидающих обработки в течении определенного интервала времени. Нормальным считается очередь не больше 2 для одиночного диска. Если в очереди больше двух запросов, то возможно диск перегружен и не успевает обрабатывать поступающие запросы. Уточнить, с какими именно операциями не справляется диск, можно с помощью счетчиков Avg. Disk Read Queue Length (очередь запросов на чтение) и Avg. Disk Wright Queue Length (очередь запросов на запись).
Значение Avg. Disk Queue Length не измеряется, а рассчитывается по закону Литтла из математической теории очередей. Согласно этому закону, количество запросов, ожидающих обработки, в среднем равняется частоте поступления запросов, умноженной на время обработки запроса. Т.е. в нашем случае Avg. Disk Queue Length = (Disk Transfers/sec) * (Avg. Disk sec/Transfer).
Avg. Disk Queue Length приводится как один из основных счетчиков для определения загруженности дисковой подсистемы, однако для его адекватной оценки необходимо точно представлять физическую структуру системы хранения. К примеру, для одиночного жесткого диска критическим считается значение больше 2, а если диск располагается на RAID-массиве из 4-х дисков, то волноваться стоит при значении больше 4*2=8.
Current Disk Queue Length
Текущая длина очереди запросов к диску. Показывает количество запросов, ожидающих обработки в данный конкретный момент. По сути это мгновенное значение (срез) текущей очереди запросов.
Disk Bytes/sec
Средняя скорость обмена данными с диском, или скорость чтения\записи. Показывает общее количество байт, отправленных на диск (запись) и с диска (чтение) в течении одной секунды, тем самым позволяя оценить пропускную способность дисковой системы. Складывается из значений Disk Read Bytes/sec (скорость чтения) и Disk Write Bytes/sec (скорость записи). Предельные значения сильно зависят от типа диска: к примеру для одиночного жесткого диска максимальная скорость чтения\записи лежит в пределах 160-250Mb/s, для одиночного SSD — около 550-600Mb/s.
Avg. Disk Bytes/Transfer
Среднее количество байт, передаваемое при выполнении одной операции чтения\записи. Чем больше размер передаваемых блоков, тем меньше нагрузка на диск. При нормальной работе этот параметр должен быть больше 20Kb, значения меньше говорят о большом количестве мелких запросов, т.е. о неэффективном использовании дисковой системы. Более точную информацию можно получить из значений счетчиков Avg. Disk Bytes/Read (количество байт, передаваемое при выполнении одной операции чтения) и Avg. Disk Bytes/Write (количество байт, передаваемое при выполнении одной операции записи).
Split IO/Sec
Частота разделения операций ввода\вывода на несколько операций. Значение, отличное от нуля показывает, что запрашиваются слишком большие блоки данных, которые не могут быть переданы за одну операцию. Это может быть следствием сильной фрагментации диска.
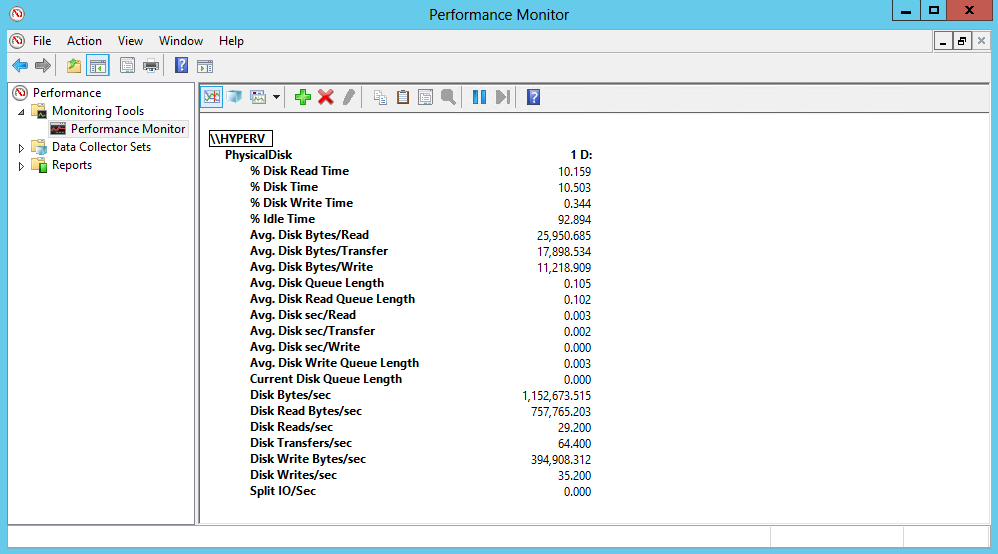
И только для объектов Logical Disk есть еще два счетчика, позволяющие определить наличие свободного места на диске.
%Free Space
Объем свободного дискового пространства на выбранном логическом диске, в процентах.
Free Megabytes
Объем свободного пространства на логическом диске, в мегабайтах.
Заключение
Для того, чтобы адекватно оценить полученные данные, необходимо точно представлять физическую структуру системы хранения. В первую очередь важен тип используемых дисков (HDD, SSD), интерфейс (SATA, SAS, FC, PCIe), скорость вращения HDD (7200, 10k, 15k). При использовании RAID-массивов нужно знать тип массива (0, 1, 5, 10 и т.д.) и количество дисков в массиве.
И еще, при оценке производительности дисковой подсистемы обязательно надо учитывать тип нагрузки, создаваемой приложениями. В идеале есть два типа дисковых нагрузок:
1. Большое количество случайных операций чтения\записи, данные обрабатываются небольшими блоками. Этот тип нагрузки характерен для серверов баз данных. При таком типе нагрузки наиболее важным параметром является количество IOPS-ов. Основные счетчики — Disk Transfers/sec, Avg. Disk sec/Transfer и конечно Avg. Disk Queue Length.
2. Последовательное чтение\запись больших блоков данных. Такая нагрузка характерна, к примеру, для серверов потокового видео. В этом случае наиболее важна пропускная способность дисковой системы, которую показывает Disk Bytes/sec.
Мониторинг и оптимизация дисковой подсистемы сервера
Вычислительная мощность центральных процессоров далеко не всегда является определяющим параметром производительности серверов в массовых приложениях. Опытные пользователи платформы 1С:Предприятие знают это как никто другой.
Говоря об 1С как «пожирателе ресурсов», надо понимать, что половину предприятий страны эта система делопроизводства устраивает и у них нет достаточных оснований для перехода на другую. Можно сколько угодно пенять на издержки архитектуры приложения и качество программного кода, но . «жизнь такова, какова она есть, и больше никакова». Но даже если свобода действий сводится к оптимизации одного только серверного оборудования, ею нужно пользоваться. Вдумчивому администратору мониторинг подсистем собственного сервера под реальной нагрузкой дает много больше информации, чем ковровые бомбардировки всех продавцов вместе взятых.
Вклад в производительность сервера его основных подсистем: центральных процессоров , оперативной памяти, дискового и сетевого ввода/вывода зависит от приложений и типов данных, с которыми они работают. По многообразию решаемых задач нет равных дисковой подсистеме, которая отвечает за сохранность и доступность данных, производительность дисковых операций, восстановление информации после отказа накопителей. При такой «многовекторности» исключено появление единого стандарта или законодателя мод, подобного Intel на рынке процессоров. Тем не менее, существующая мешанина подходов/интерфейсов/типов накопителей/политик — не повод для крайностей: перебора всех возможных комбинаций или, наоборот, бездумной веры в бренд. Существует стандартный инструментарий оценки вычислительной нагрузки. Тому, кто не ленится приложить усилия к замерам параметров и анализу результатов, наградой будет точное соответствие проектируемого сервера задачам, а значит — существенная экономия как стартовых, так и операционных затрат. Попробуем разложить характеристики нагрузки по полочкам. Сделаем это на примере базовой ОС Microsoft Windows Server 2008 R2 и ее встроенного инструмента Windows Performance Monitor (Системный монитор Windows), параметр за параметром. Типичный вид результатов мониторинга приведен на Рис 1.

Включение датчиков — физический диск
1. % Free Space — процент свободного пространства на логическом диске. Если свободно менее 15% емкости диска, он считается перегруженным, а его дальнейший анализ некорректным — на него будет влиять фрагментированность данных. Рекомендуемый объем свободного места на серверном диске — не менее 20%.
2. Avg. Disk sec/Transfer — среднее время обращения к диску. Параметр показывает усредненное время в секундах, требуемое для одной операции обмена данными с диском. Для слабо нагруженных систем (например, файловых хранилищ) его значение не должно превышать 0,25 секунды. Для высоконагруженных серверов (SQL, Exchange, VDI) — 0,1 секунды. Большие значения параметра говорят о перегрузке дисковой подсистемы. Для понимания, какие именно операции, чтения или записи, и в какой пропорции съедают время, считывают показатели Avg. Disk sec/Read (среднее время чтения с диска в секундах) и Avg. Disk sec/Write (среднее время обращения к диску на запись). К примеру, интегральный показатель Avg. Disk sec/Transfer в RAID5 при существенном преобладании операций чтения может быть в пределах нормы, но при этом операции записи проходить чрезвычайно медленно. Особенно важен параметр Avg. Disk sec/Write для массивов на дисках SSD, массивах с SSD-кешированием, любых массивах RAID 5 и RAID 6.
Радикально снижает значение Avg. Disk sec/ Read переход с HDD на SSD, с размещением на твердотельных накопителях «горячих» (наиболее востребованных) данных, особенно если их объем невелик. Приложениям с преимущественно линейным чтением данных большого объема (к примеру, видеопотоков) традиционно помогает увеличение количества дисков HDD в массиве. При большом показателе Avg. Disk sec/Write в первую очередь нужно обратить внимание на уровень RAID—массива, его «штраф на запись». Дело в том, что для записи избыточной информации в массиве необходимо вместо одной операции записи выполнить две и более. Штраф на запись для одиночного диска и RAID 0 равен «1» (на запись данных тратится одно обращение RAID-контроллера к дискам). Для RAID 1 и RAID 10 — штраф на запись равен «2» (для записи одного блока данных контроллер делает два обращения на запись к дискам — что, в свою очередь, приводит к общему снижению производительности дисковой подсистемы RAID 1 и RAID 10 в IOPS на запись в два раза относительно производительности этих же дисков в IOPS в RAID 0). Штраф на запись для RAID 5 равен «4», а для RAID 6 — «6». Если собран массив RAID 5 или RAID 6 и его среднее время отклика высоко — надо либо переходить к менее ресурсоемкому на запись RAID 10, либо увеличивать количество физических дисков в RAID-массиве.

PerfMon за работой
SSD — хороший инструмент и для снижения задержек записи, особенно в приложениях класса SQL Server или Exchange Server. Самый революционный эффект дают SSD, устанавливаемые напрямую в слот PCI Express — как Fusion’s ioDrive (SLC и MLС), LSI WarpDrive (SLC и MLC) или Intel 910 (MLC), хоть и в разной степени, с разбросом цен от $2K до $15K. Более привычно подключение автономных накопителей SSD к высокопроизводительному RAID-контроллеру. Для массива из одних только SSD можно рекомендовать контроллеры LSI MegaRAID SAS 926x/928x со включенной опцией FastPath или 7-й серию Adaptec. Самым «бархатным» вариантом считается SSD-кеширование (LSI CacheCade 2.0, Adaptec MaxCache 3.0) — когда SSD включаются в массивы HDD в качестве кеша второго уровня RAID-контроллеров. Обсуждая SSD под корпоративные приложения, мы говорим о накопителях как минимум уровня Seagate Pulsar.2 (MLC) или Intel 710 (MLC) . Ожидать высокой производительности в серверных задачах и под существенной нагрузкой десктопных дисков класса Intel 520 не приходится (хоть они и бьют HDD SAS 15K rpm по паспортной производительности).
3. Интегральный показатель Avg. Disk Queue Length (средняя длина очереди диска), и его составляющие: Avg. Disk Read Queue Length (средняя длина очереди к диску на чтение) и Avg. Disk Write Queue Length (средняя длина очереди к диску на запись). Данный показатель указывает, сколько операций ввода/вывода в среднем ожидают, когда жесткий диск станет доступным. Он не измеряется, а вычисляется по закону Литтла из теории очередей как (Disk Transfers/sec) *(Disk sec/Transfer) или N = A * Sr, где N — число ожидающих запросов в системе, A — скорость поступления запросов, Sr — время отклика. Для нормально работающей дисковой подсистемы этот показатель не должен превышать больше чем на 1 количество дисков в RAID-группе. В приложениях класса SQL Server, Exchange Server его среднее значение лучше удерживать на уровне менее 0.2. Его уменьшению способствует SSD-кеширование, перенос «горячих» данных на SSD, на худой конец — традиционное увеличение количества дисков в RAID-группе. Среднюю длину очереди к диску на чтение снижает переход на SSD, а среднюю длину очереди на запись — отказ от вариантов RAID с большим штрафом на запись RAID 5 и RAID 6 — в пользу RAID 10.
4. Current Disk Queue Length (текущая длина очереди диска) показывает число не выполненных и ожидающих обработки запросов, адресованных выбранному диску. Это текущее значение, моментальный показатель, а не среднее значение за интервал времени. Время задержки пропорционально длине очереди. В установившемся режиме количество ожидающих запросов не должно превышать количество физических дисков в массиве более чем в 1,5-2 раза. При этом массив из нескольких дисков может одновременно выбирать из очереди по одному запросу на каждый диск. Текущую очередь укорачивают теми же методами, что и среднюю, с одной оговоркой: кратковременные пики нагрузки хорошо гасятся скоростными RAID-контроллерами с большим объемом кеш-памяти. При длительных пиках стоит применить SSD-кеширование, перевести «горячие» данные на SSD или в гибридный том SSD/HDD, увеличить число дисков в RAID-группе.

Avg. Disk sec/Read + Avg. Disk sec/Write
5. % Disk Time (% активности диска), % Disk Read Time (% активности диска при чтении), % Disk Write Time (% активность диска при записи) — процент времени, затраченного дисковым устройством на обработку запросов (всего, по чтению и по записи). Показания этого счетчика в массиве охватывают больше чем один физический диск, и могут превышать 100%. Тем не менее, желательно, чтобы общая загрузка не превышала 80 — 90% (особенно важно для массивов из SSD). Этот счетчик не всегда показателен, его надо анализировать вместе с % Idle Time (процент времени бездействия).
Править эти показатели можно по-разному. Например, разместить данные на различных массивах в зависимости от типа нагрузки: таблицы SQL на одной RAID-группе дисков, а лог-файлы SQL — на другой. Помогает установка RAID-контроллера с большим объемом кеша (или SSD-кешем) и включенным кешированием записи — отложенная запись в пакетном режиме снижает зависимость от латентности дисков. Хорошо работает традиционный способ увеличения количества дисков в массиве, замена дисков на более быстрые HDD или SSD.
6. % Idle Time (% времени бездействия) — доля интервала между измерениями, в течение которого физический диск бездействовал. Фактически, зеркальный параметр для % Disk Time и применим исключительно к физическим дискам. Желательно, чтобы в сервере параметр был не менее 15-20% для HDD и не менее 20-25% для SSD. Инструменты его улучшения — точно такие же, как для предыдущего параметра: RAID-контроллер с большим кешем и/или SSD-кеширование, больше дисков в RAID-группе, переход на более быстрые диски HDD и SSD.

Avg. Disk Queue Length — пример нагруженного сервера
7. Disk Transfers/sec (обращений к диску/сек) — количество отдельных дисковых запросов ввода-вывода, завершённых в течение одной секунды. Показывает реальные потребности приложений по случайному чтению и записи к дисковой подсистеме. Для дисков, работающих в нормальном режиме, нагрузка не должна превышать их физические пределы, с учетом количества дисков в массиве и его уровня RAID. Так, для RAID 10 (штраф на запись «2») штатные значения такие:
до 80 IOPS на каждый SATA или NL SAS диск;
до 160 IOPS на каждый SAS диск;
до 1800 IOPS на каждый бытовой SSD
до 5000 IOPS на каждый серверный SSD.
Как и любой показатель, суммирующий несколько отдельных счетчиков — не очень информативен, позволяет лишь оценить «обстановку в целом». Надо анализировать более содержательные Disk Reads/sec (обращений чтения с диска/сек) и Disk Writes/sec (обращений записи на диск/сек).
Disk Reads/sec — количество обращений чтения в секунду, то есть частота выполнения операций чтения с диска. Важнейший параметр для приложений класса SQL Server, Exchange Server, определяющий реальную производительность дисковой подсистемы. В нормальном устоявшемся режиме интенсивность обращений не должна превышать физические возможности дисков — их индивидуальным пределам, умноженным на количество дисков в массиве. Для RAID 10 это:
100-120 IOPS на каждый SATA или NL SAS диск;
200-240 IOPS на каждый SAS 15000 rpm диск;
30 000-40 000 IOPS на каждый диск SSD класса интеловских серий 320 или 710;
до 90 000 IOPS для Intel SSD 910-й серии 400GB .
В режиме чтения для различных типов RAID могут учитываться не все диски. В том же RAID-6 в массиве из шести дисков скорость чтения равна скорости чтения с четырех дисков (с оставшихся двух считываются контрольные суммы).
Disk Writes/sec — количество обращений записи в секунду, то есть частота выполнения операций записи на диск. Чрезвычайно важный параметр для приложений класса SQL Server , чуть менее важный для Exchange Server. При работе в нормальном режиме интенсивность обращений не должна превышать физические пределы дисков, умноженные на их количество в массиве и с учетом штрафа на запись для выбранного типа RAID. Для RAID 10 (штраф на запись «2»):
40-50 IOPS на каждый SATA или NL SAS диск;
80-100 IOPS на каждый SAS диск;
150-300 IOPS на бытовой SSD;
1100-2400 IOPS на серверный SSD;
до 38 000 IOPS для Intel SSD 910-й серии 400GB.
Анализировать корректно Disk Reads/sec и Disk Writes/sec можно только с учетом текущей длины очереди Current Disk Queue Length и средней длины очередей чтения/записи Avg. Disk Read Queue Length и Avg. Disk Write Queue Length. Если Current Disk Queue Length или Avg. Disk Read Queue Length и Avg. Disk Write Queue Length существенно выходят за штатные пределы — скорее всего, реальная потребность в IOPS дисковой подсистемы будет в разы, а то и на порядок выше, чем фиксируют Disk Reads/sec и Disk Writes/sec. К примеру, если Current Disk Queue Length для массива RAID 10 из 4 дисков в какие-то интервалы времени достигает показателей 12-16, с пиками до 100 — то реальный спрос на операции ввода/вывода в эти моменты у приложений почти наверняка превышает возможности дисковой подсистемы в 2-3 раза. Если устоявшееся значение Current Disk Queue Length составляет 30-40, с пиками до 140-180 — значит реальный спрос на IOPS у приложений превосходит физические возможности дисковой подсистемы в 4-8 раз.
Влияние средней длины очередей чтения и записи на показатели Disk Reads/sec и Disk Writes/sec более сложно, и сильно зависит от характера приложений. К примеру, для того же RAID 10 из 4 дисков в режиме файл-сервера под нагрузкой вполне допустимы значения 2-4. Для базы данных приложения «1С:Предприятие 8.2» под MS SQL Server 2008R2 превышение значения 0.2 — уже повод задуматься, тогда как приближение к 0.8-1 — четкий сигнал к модернизации дисковой подсистемы.
Способы повышения производительности дисковой подсистемы в IOPS традиционны — увеличение количества дисков в RAID группе, применение технологий SSD-кеширования на чтение и запись, применение гибридных RAID и массивов из одних только SSD, переход к SSD-устройствам с интерфейсом PCI Express. Сгладить большие и непродолжительные пики Current Disk Queue Length поможет объемный кеш RAID-контроллера, но при длительных высоких нагрузках он будет малоэффективен.

Current Disk Queue Length — длительные периоды пиков говорят о перегрузке по IOPS
8. Disk Bytes/sec — скорость обмена с диском в байт/сек, пропускная способность дисковой системы при выполнении операций чтения и записи. Этот параметр важен для задач потокового чтения/записи и редко бывает критичным для баз данных. Как и предыдущий параметр, привязан к физическим возможностям дисков. Приведенные ниже цифры — ориентировочные, реальные показатели очень сильно зависят от параметров конкретного диска, а для HDD снижаются почти в 2 раза при переходе с внешних на внутренние дорожки. Для интерфейсов SATA 2 и SAS 1.0 значения ограничены пропускной способностью интерфейса (300 MB/s) и составляют на больших блоках и последовательных операциях от 250 до 140 MB/s на каждый SATA, NL SAS, SAS, и порядка 300 MB/s на каждый SSD диск. Для интерфейсов SATA 3, SAS 2.0 на больших блоках и последовательных операциях — от 250 до 140 MB/s на каждый SATA, NL SAS, SAS , и до 550-600 MB/s на каждый SSD диск на последовательных операциях. SSD с интерфейсом PCI Express класса Intel SSD 910-й серии выдают до 1000 MB/s на чтение и до 750 MB/s на запись.
Disk Read Bytes/sec — скорость чтения с диска в байт/сек. Для корректного расчета предела возможностей дисков в различных вариантах RAID необходимо учитывать те из них, которые выдают информацию (для RAID 6 из 6 дисков — учитываем 4 диска, для RAID 10 из 6 дисков — учитываем 6 дисков).
Disk Write Bytes/sec — скорость записи на диск в байт/сек. Необходимо учитывать те диски, которые одновременно сохраняют различные данные (для RAID 6 из 6 дисков — учитываем 4 диска, для RAID 10 из 6 дисков — учитываем 3 диска). Наиболее эффективный способ повышения производительности дисковой подсистемы по скорости обмена — увеличение количества дисков в RAID-группе.

Недостаточная производительность в IOPS по параметрам Disk Reads/sec и Disk Writes/sec приводит к длительным перегурзкам и снижению общей производительности, что видно по Avg. Disk Queue Length
9. Avg. Disk Bytes/Transfer — среднее количество байт данных, переданных при выполнении операций чтения или записи. Показывает средний объём операций ввода — вывода. Чем больше объем одного «пакета» — тем меньше нагрузка на дисковую подсистему. При нормальной работе этот параметр должен быть больше 20 Кбайт, значения меньше 20 Кбайт сигнализируют о неэффективности использования дисков приложением. Avg. Disk Bytes/Read — среднее количество байт данных, полученных с диска при выполнении операций чтения. Avg. Disk Bytes/Write — среднее количество байт данных, переданных на диск при выполнении операций записи.
Безусловно, основным путем улучшения данного параметра является оптимизация приложения. Для приложений класса SQL Server будет эффективным выделение большего пространства в оперативной памяти (RAM) под программный кеш. Помогает применение RAID-контроллера с включенным кешированием на запись и переход к использованию SSD во всех возможных вариантах — как более уместного накопителя для работы с короткими запросами случайного доступа.
10. Split IO/sec — частота расщепления операций ввода-вывода диска на несколько операций. Крайне редко используемый в реальной жизни параметр. Может сигнализировать, что приложением запрашиваются слишком большие блоки данных, которые не могут быть переданы за одну операцию. Для нагруженных дисков HDD с малыми показателями — % Free Space и % Idle Time может говорить о высоким уровне фрагментации диска.
Все перечисленные выше параметры, их рабочие диапазоны, возможные причины выхода за их пределы и рекомендации по их возврату в штатные рамки сведены в одну таблицу. Хотя универсальных советов по интерпретации реальных замеров быть не может, один общий вывод все-таки есть: «информирован — значит вооружен».
Счётчик (counter )
Толкование
Нормальный диапазон
Причины выхода за него
Рецепты
Avg . Disk sec / Transfer
Среднее время обращения к диску (сек)
Avg . Disk sec / Read
Среднее время чтения с диска (сек)
Avg . Disk sec / Write
Среднее время обращения к диску на запись (сек)
Physical Disk / Logical Disk
Среднее время в секундах, требуемое для одной операции обмена данными с диском.
Среднее время в секундах, требуемое для чтения данных с диска.
Среднее время в секундах, требуемое для записи данных на диск.
< 0.25 секунды для файловых серверов
< 0.10 секунды для SQL Server , Exchange Server , VM / VDI .
Большое значение говорит о перегрузке дисковой подсистемы. Возможно, контроллер повторяет попытки обращения к неисправному диску.
Увеличить количество дисков в массиве.
Заменить на боле е быстрые HDD или SSD .
Применить технологии кеширования.
Заменить диск.
Current Disk Queue Length
Текущая длина очереди диска
Physical Disk / Logical Disk
Число невыполненных и ожидающих обработки запросов, адресованных выбранному диску. Текущее значение, моментальный показатель, не является средним значением по интервалу времени.
В установившемся режиме количество ожидающих запросов не должно превышать количество физических дисков в массиве более чем в 1.5-2 раза.
Допустимы моментальные пики.
При перегрузках дисковой подсистемы значение счетчика будет постоянно большим.
Увеличить количество дисков в массиве.
Заменить на боле е быстрые HDD или SSD .
Перенести часть данных на другие диски.
% Disk Time
% активности диска
% Disk Read Time
% активности диска при чтении
% Disk Write Time
% активности диска при записи
Physical Disk / Logical Disk
Процент времени, затраченного дисковым устройством на обработку запросов.
Процент времени на обработку запросов чтения.
Процент времени на обработку запросов записи.
Данные счетчика в массиве охватывают больше чем один физический диск, и могут превышать 100%.
Необходимо анализировать вместе с параметром % Idle Time.
до 80 — 90%
Постоянные высокие нагрузки.
Разместить данные на различных массивах по типу нагрузки (например, таблицы БД и лог-файлы).
Увеличить количество дисков в массиве.
Заменить на боле е быстрые HDD или SSD .
% Idle Time
% времени бездействия
Physical Disk
Время бездействия диска между измерениями.
Анализировать совместно с параметром % Disk Time
Не менее 20%
Постоянные высокие нагрузки.
Разместить данные на различных массивах по типу нагрузки (например, таблицы БД и лог-файлы).
Увеличить количество дисков в массиве.
Заменить на боле е быстрые HDD или SSD .
Avg . Disk Queue Length
Средняя длина очереди диска
Avg . Disk Read Queue Length
Средняя длина очереди к диску на чтение
Avg . Disk Write Queue Length
Средняя длина очереди к диску на запись
Physical Disk / Logical Disk
Среднее количество незавершенных операций ввода/вывода в очереди к диску.
Среднее количество запросов чтения в очереди к диску.
Среднее количество запросов на запись в очереди к диску.
Это производное значение, а не прямое измерение, равно ( Disk Transfers / sec ) *( Disk sec / Transfer )
Рекомендуемое для многопоточных ресурсоёмких ( SQL Server , Exchange Server , VM / VDI , 1С) не более 0,2.
Допустимое = количество дисков в массиве + 1.
Большое значение говорит о перегрузке дисковой подсистемы.
Увеличить количество дисков в массиве.
Заменить на боле е быстрые HDD или SSD .
Disk Transfers / sec
Обращений к диску/сек
Disk Reads / sec
Обращений чтения с диска/сек
Disk Writes / sec
Обращений записи на диск/сек
Physical Disk / Logical Disk
Количество отдельных дисковых запросов ввода-вывода, завершённых в течение одной секунды.
Частота выполнения операций чтения с диска.
Частота выполнения операций записи на диск.
Равняются произведению показателей одного диска на их количество. Для различных типов RAID на чтение могут учитываться не все диски.
Для записи полученная сумма делится на штраф на запись: 1 (RAID 0), 2 (RAID 1, 10), 4 (RAID5), 6 (RAID 6).
Disk Transfers / sec
для RAID 10 (штраф на запись 2):
— до 80 IOPS на каждый SATA или NL SAS диск;
— до 160 IOPS на каждый SAS диск;
— до 1800 IOPS на каждый десктопный SSD
— до 5000 IOPS на каждый серверный SSD .
Disk Reads / sec для RAID 10:
— 100 IOPS на каждый SATA или NL SAS диск;
220 IOPS на каждый SAS диск;
— до 30 000 IOPS на SSD ;
— Intel SSD 910 series 400 GB – 90 000 IOPS .
Disk Writes / sec для RAID 10 (штраф на запись 2):
— 40 IOPS на каждый SATA или NL SAS диск;
80 IOPS на каждый SAS диск;
— до 150-300 IOPS на десктопный SSD ;
— до 1100 — 2400 IOPS на серверный SSD ;
— Intel SSD 910 series 400 GB – 38 000 IOPS .
Постоянные высокие нагрузки случайного чтения и/или случайной записи.
Увеличить количество дисков в массиве.
Заменить на боле е быстрые HDD или SSD .
Перейти на массив из SSD .
Применить технологии кеширования на SSD .
Перейти на PCIe SSD .
Disk Bytes / sec
Скорость обмена с диском (байт/сек)
Disk Read Bytes / sec
Скорость чтения с диска (байт/сек)
Disk Write Bytes/sec
Скорость записи на диск (байт/сек)
Physical Disk / Logical Disk
Пропускная способность дисковой системы (скорость обмена данными с диском) при выполнении операций чтения и записи.
Скорость передачи данных с диска при выполнении операций чтения.
Скорость передачи данных на диск при выполнении операций записи.
Сильно зависит от спецификаций на конкретный диск.
SATA 2, SAS 1.0:
— до 300 MB / s на каждый SATA , NL , SAS , SAS , SSD диск на последовательных операциях.
SATA 3, SAS 2.0:
— до 600 MB / s на каждый SATA , NL , SAS , SAS , SSD диск на последовательных операциях.
PCIe SSD : Intel SSD 910 series 400 GB
— до 1000 MB / s на чтение,
— до 750 MB / s на запись.
Постоянные высокие нагрузки линейного чтения и/или линейной записи.
Увеличить количество дисков в массиве.
Avg . Disk Bytes / Transfer
Средний размер одного обмена с диском (байт)
Avg . Disk Bytes / Read
Средний размер одного чтения с диска (байт)
Avg . Disk Bytes / Write
Средний размер одной записи на диск (байт)
Physical Disk / Logical Disk
Среднее количество байт данных, переданных при выполнении операций чтения или записи.
Среднее количество байт данных, полученных с диска при выполнении операций чтения.
Среднее количество байт данных, переданных на диск при выполнении операций записи.
>20 Кбайт
Значение меньше 20 Кбайт будут в случае, если приложение использует диск неэффективно.
Большое количество слишком мелких запросов.
Оптимизировать приложения.
Выделить большой объем в оперативной памяти под кеш приложения.
Использовать режим отложенной записи RAID -контроллера.
Перейти на SSD .
% Free Space
% свободного места
Logical Disk
Доля свободного места на логическом диске, по отношению к его общему объему.
15%
Постепенное исчерпание свободного пространства.
Заменить диск на более емкий.
Добавить диски в RAID -массив.
Free Megabytes
Свободно мегабайт
Logical Disk
Объем незанятого пространства на логическом диске в мегабайтах.
Split IO/sec
Расщепления ввода/вывода/сек
Physical Disk / Logical Disk
Частота, с которой операции ввода-вывода диска расщепляются на несколько операций ввода-вывода.
Запрашиваются слишком большие блоки данных, которые не могут быть переданы за одну операцию.