What is tcp three way handshake ? What is SYN , ACK packets ?
We know that TCP is one of the implementation example of transport layer protocol according to the OSI model. The protocol is connection oriented, means before sending any data to the remote peer, tcp client setup a virtual connection over packet based underlying IP network. Three way handshake is the protocol procedure to achieve connection setup. Here we will cover the tcp connection setup procedure in detail. First question comes in mind, who is responsible for starting TCP connection? The protocol layer itself ,on startup or some other external entity instruct the layer for connection? The answer is TCP user is responsible to start a TCP three way handshake. For example HTTP (web browser uses HTTP) , is one of the user of TCP. When HTTP user need to send a web request to the remote server. Before sending any user data, HTTP request TCP to make a connection with the remote server. Once TCP layer receives connection request it starts tcp 3 way handshake. Like any other protocol, the three way handshake procedure requires to exchange packets or messages between client and server. Following are the used in connection setup.
Following is message flow for three way handshake.
User of HTTP issues a connect request to the TCP layer. TCP layer works as tcp Client and sends the tcp syn with a initial sequence number. Sequence number is to maintain the sequencing of messages. Upon SYN received Sever sends the a new syn and ack of received syn to the client, then client sends the ACK to the server for syn received from server. This completes the connection setup. Following mentions each message in detail for three way handshake.
TCP SYN packet:
This is the first packet from client to the server. TCP message set SYN flag to 1 in message , so make the tcp message as SYN packet. It have the initial sequence number of the client along with other few more parameters.
TCP SYN ACK packet:
After receiving SYN packet, server sends the syn ack packet to the client. Not to mention that this is a single tcp packet with syn and ack bit set to 1. The syn sequence number is the initial sequence number of server accepting the connection. The ack part have client sequence number plus one. This way server tell that it is ready to accept the packet with next sequence number from the client.
TCP ACK packet:
Final packet for connection setup is tcp ack. Client sends tcp ack packet upon receiving tcp syn ack from server. The packet includes sequence number from server plus one.
TCP user indication after three way handshake :
In start we have mentioned that , it is the user who initiates connection request. But how the user get, that connection is done ? And user can use the connection to send data to remote server? User gets an indication about the connection setup result from the TCP layer. If handshake is successful, then gets the connection identifier. Else and error. Connection identifier works as handler for sending/receiving data to/from server. We will show in another post about the exact implementation of TCP client/server , then you can get more clear picture of connection handler.
Внутренние механизмы ТСР, влияющие на скорость загрузки: часть 1
Ускорение каких-либо процессов невозможно без детального представления их внутреннего устройства. Ускорение интернета невозможно без понимания (и соответствующей настройки) основополагающих протоколов — IP и TCP. Давайте разбираться с особенностями протоколов, влияющих на скорость интернета.
IP (Internet Protocol) обеспечивает маршрутизацию между хостами и адресацию. TCP (Transmission Control Protocol) обеспечивает абстракцию, в которой сеть надежно работает по ненадежному по своей сути каналу.
Протоколы TCP/IP были предложены Винтом Серфом и Бобом Каном в статье «Протокол связи для сети на основе пакетов», опубликованной в 1974 году. Исходное предложение, зарегистрированное как RFC 675, было несколько раз отредактировано и в 1981 году 4-я версия спецификации TCP/IP была опубликована как два разных RFC:
- RFC 791 – Internet Protocol
- RFC 793 – Transmission Control Protocol
TCP обеспечивает нужную абстракцию сетевых соединений, чтобы приложениям не пришлось решать различные связанные с этим задачи, такие как: повторная передача потерянных данных, доставка данных в определенном порядке, целостность данных и тому подобное. Когда вы работаете с потоком TCP, вы знаете, что отправленные байты будут идентичны полученным, и что они придут в одинаковом порядке. Можно сказать, что TCP больше «заточен» на корректность доставки данных, а не на скорость. Этот факт создает ряд проблем, когда дело доходит до оптимизации производительности сайтов.
Стандарт НТТР не требует использования именно TCP как транспортного протокола. Если мы захотим, мы можем передавать НТТР через датаграммный сокет (UDP – User Datagram Protocol) или через любой другой. Но на практике весь НТТР трафик передается через TCP, благодаря удобству последнего.
Поэтому необходимо понимать некоторые внутренние механизмы TCP, чтобы оптимизировать сайты. Скорее всего, вы не будете работать с сокетами TCP напрямую в своем приложении, но некоторые ваши решения в части проектирования приложения будут диктовать производительность TCP, через который будет работать ваше приложение.
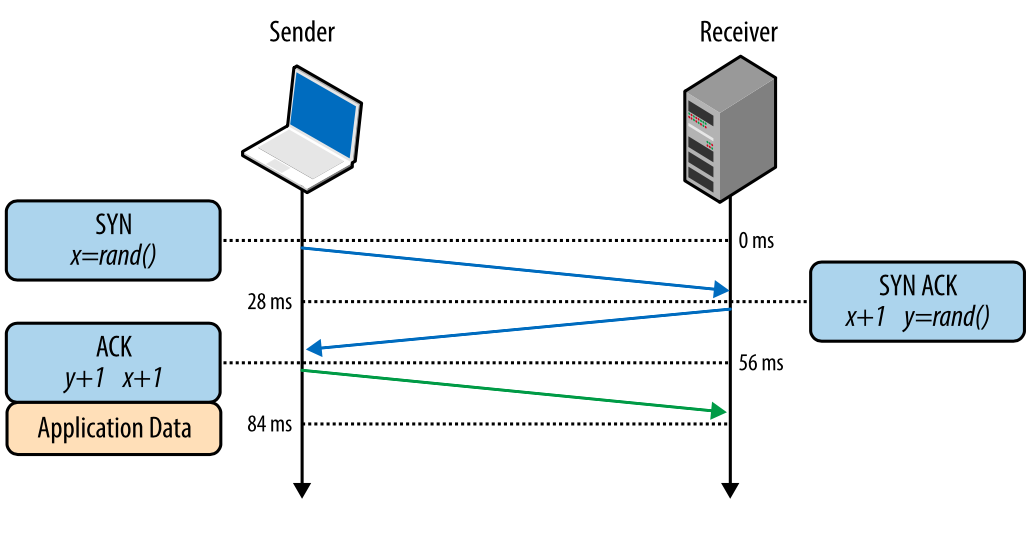
Тройное рукопожатие
Все TCP-соединения начинаются с тройного рукопожатия (рис. 1). До того как клиент и сервер могут обменяться любыми данными приложения, они должны «договориться» о начальном числе последовательности пакетов, а также о ряде других переменных, связанных с этим соединением. Числа последовательностей выбираются случайно на обоих сторонах ради безопасности.
Клиент выбирает случайное число Х и отправляет SYN-пакет, который может также содержать дополнительные флаги TCP и значения опций.
SYN ACK
Сервер выбирает свое собственное случайное число Y, прибавляет 1 к значению Х, добавляет свои флаги и опции и отправляет ответ.
Клиент прибавляет 1 к значениям Х и Y и завершает хэндшейк, отправляя АСК-пакет.
Рис. 1. Тройное рукопожатие.
После того как хэндшейк совершен, может быть начат обмен данными. Клиент может отправить пакет данных сразу после АСК-пакета, сервер должен дождаться АСК-пакета, чтобы начать отправлять данные. Этот процесс происходит при каждом TCP-соединении и представляет серьезную сложность плане производительности сайтов. Ведь каждое новое соединение означает некоторую сетевую задержку.
Например, если клиент в Нью-Йорке, сервер – в Лондоне, и мы создаем новое TCP-соединение, это займет 56 миллисекунд. 28 миллисекунд, чтобы пакет прошел в одном направлении и столько же, чтобы вернуться в Нью-Йорк. Ширина канала не играет здесь никакой роли. Создание TCP-соединений оказывается «дорогим удовольствием», поэтому повторное использование соединений является важной возможностью оптимизации любых приложений, работающих по TCP.
TCP Fast Open (TFO)
Загрузка страницы может означать скачивание сотен ее составляющих с разных хостов. Это может потребовать создания браузером десятков новых TCP-соединений, каждое из которых будет давать задержку из-за хэндшейка. Стоит ли говорить, что это может ухудшить скорость загрузки такой страницы, особенно для мобильных пользователей.
TCP Fast Open (TFO) – это механизм, который позволяет снизить задержку за счет того, что позволяет отправку данных внутри SYN-пакета. Однако и у него есть свои ограничения: в частности, на максимальный размер данных внутри SYN-пакета. Кроме того, только некоторые типы HTTP-запросов могут использовать TFO, и это работает только для повторных соединений, поскольку использует cookie-файл.
Использование TFO требует явной поддержки этого механизма на клиенте, сервере и в приложении. Это работает на сервере с ядром Linux версии 3.7 и выше и с совместимым клиентом (Linux, iOS9 и выше, OSX 10.11 и выше), а также потребуется включить соответствующие флаги сокетов внутри приложения.
Специалисты компании Google определили, что TFO может снизить сетевую задержку при HTTP-запросах на 15%, ускорить загрузку страниц на 10% в среднем и в отдельных случаях – до 40%.
Контроль за перегрузкой
В начале 1984 года Джон Нейгл описал состояние сети, названное им как «коллапс перегрузки», которое может сформироваться в любой сети, где ширина каналов между узлами неодинакова.
Когда круговая задержка (время прохождения пакетов «туда-обратно») превосходит максимальный интервал повторной передачи, хосты начинают отправлять копии одних и тех же датаграмм в сеть. Это приведет к тому, что буферы будут забиты и пакеты будут теряться. В итоге хосты будут слать пакеты по нескольку раз, и спустя несколько попыток пакеты будут достигать цели. Это называется «коллапсом перегрузки».
Нейгл показал, что коллапс перегрузки не представлял в то время проблемы для ARPANETN, поскольку у узлов была одинаковая ширина каналов, а у бэкбона (высокоскоростной магистрали) была избыточная пропускная способность. Однако это уже давно не так в современном интернете. Еще в 1986 году, когда число узлов в сети превысило 5000, произошла серия коллапсов перегрузки. В некоторых случаях это привело к тому, что скорость работы сети падала в 1000 раз, что означало фактическую неработоспособность.
Чтобы справиться с этой проблемой, в TCP были применены несколько механизмов: контроль потока, контроль перегрузки, предотвращение перегрузки. Они определяли скорость, с которой данные могут передаваться в обоих направлениях.
Контроль потока
Контроль потока предотвращает отправку слишком большого количества данных получателю, которые он не сможет обработать. Чтобы этого не происходило, каждая сторона TCP-соединения сообщает размер доступного места в буфере для поступающих данных. Этот параметр — «окно приема» (receive window – rwnd).
Когда устанавливается соединение, обе стороны задают свои значения rwn на основании своих системных значений по умолчанию. Открытие типичной страницы в интернете будет означать отправку большого количества данных от сервера клиенту, таким образом, окно приема клиента будет главным ограничителем. Однако, если клиент отправляет много данных на сервер, например, загружая туда видео, тогда ограничивающим фактором будет окно приема сервера.
Если по каким-то причинам одна сторона не может справиться с поступающим потоком данных, она должна сообщить уменьшенное значение своего окна приема. Если окно приема достигает значения 0, это служит сигналом отправителю, что не нужно более отправлять данные, пока буфер получателя не будет очищен на уровне приложения. Эта последовательность повторяется постоянно в каждом TCP-соединении: каждый АСК-пакет несет в себе свежее значение rwnd для обеих сторон, позволяя им динамически корректировать скорость потока данных в соответствии с возможностями получателя и отправителя.
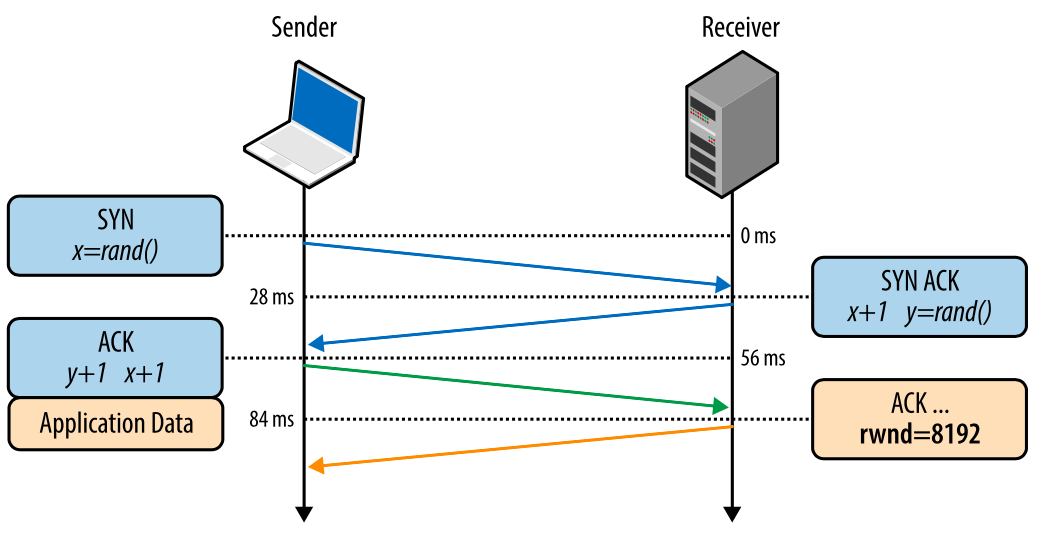
Рис. 2. Передача значения окна приема.
Масштабирование окна (RFC 1323)
Исходная спецификация TCP ограничивала 16-ю битами размер передаваемого значения окна приема. Это серьезно ограничило его сверху, поскольку окно приема не могло быть более 2^16 или 65 535 байт. Оказалось, что это зачастую недостаточно для оптимальной производительности, особенно в сетях с большим «произведением ширины канала на задержку» (BDP – bandwidth-delay product).
Чтобы справиться с этой проблемой в RFC 1323 была введена опция масштабирования TCP-окна, которая позволяла увеличить размер окна приема с 65 535 байт до 1 гигабайта. Параметр масштабирования окна передается при тройном рукопожатии и представляет количество бит для сдвига влево 16-битного размера окна приема в следующих АСК-пакетах.
Сегодня масштабирование окна приема включено по умолчанию на всех основных платформах. Однако промежуточные узлы, роутеры и сетевые экраны могут переписать или даже удалить этот параметр. Если ваше соединение не может полностью использовать весь канал, нужно начать с проверки значений окон приема. На платформе Linux опцию масштабирования окна можно проверить и установить так:
В следующей части мы разберемся, что такое TCP Slow Start, как оптимизировать скорость передачи данных и увеличить начальное окно, а также соберем все рекомендации по оптимизации TCP/IP стека воедино.
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Транспортные протоколы TCP и UDP
Оглавление: Компьютерные сети
6. Канальный уровень передачи данных
7. Маршрутизация данных
8. Служебный протокол ICMP
10. Настройка сетевых подключений в командной строке Linux
11. Определение проблем работы сети
12. Туннелизация
Сходства и различия TCP и UDP
В первой части «Как работают компьютерные сети» мы узнали, что для передачи информации используются транспортные протоколы TCP и UDP. В физическом смысле эти протоколы представляют собой сетевые пакеты. Каждый сетевой пакет передаёт небольшой фрагмент информации, поэтому данные разбиваются на много пакетов.
Каждый сетевой пакет обоих протоколов TCP и UDP состоит из двух частей:
- заголовок
- непосредственно данные
В заголовке содержится «служебная информация» (можно сказать, что это метаданные) — порты пункта назначения и исходного узла, номер пакета в потоке, тип пакета и так далее.
Различие между протоколами TCP и UDP в том, что протокол TCP имеет механизм контроля полноты переданных данных — если какой-либо пакет был потерян или повреждён, то предусмотрен механизм для проверки этого факта и повторной отправки пакета. В протоколе UDP такого механизма нет — то есть если потерян пакет протокола UDP, то узел, который его отправил, никогда об этом не узнает, а принимающая сторона никогда не узнает, что ей был отправлен потерянный пакет UDP.
Может возникнуть вопрос, зачем вообще нужен такой ненадёжный протокол UDP, если есть надёжный протокол TCP? Платой за надёжность протокола TCP является то, что в бухгалтерии называется «накладные расходы» (overheads) — суть в том, что для обеспечения механизма контроля доставки пакетов в протоколе TCP отправляется много данных, которые не содержат полезной информации, а служат только для установки и контроля соединения. К примеру, чтобы отправить хотя бы одни пакет с полезными данными в TCP нужно завершить трёхступенчатое рукопожатие, которое заключается в отправке 1 особого пакета от источника к пункту назначения, получения 1 пакета о возможности установить соединения и отправки ещё 1 специального пакета от источника с подтверждением, что всё готово к отправке — за это время с помощью протокола UDP можно было бы отправить уже несколько пакетов с полезными данными.
По этой причине, оба протокола TCP и UDP являются «хорошими» — важно правильно их использовать. Например, при потоковом вещании видео неважно, какой пакет был потерян секунду или две назад. Но при открытии веб-страницы, когда из-за неполных данных могут возникнуть проблемы с обработкой запроса от HTTP протокола, напротив, нужно следить за доставкой и целостностью каждого пакета с данными.
Детальное понимание TCP и UDP имеет значение при:
- анализе сетевого трафика
- настройке сетевого файервола iptables
- понимания и защиты от DoS атак некоторого вида.
К примеру, понимая механизм TCP подключения, можно настроить файлервол (iptables) так, что будут запрещены все новые подключения с сохранением существующих, либо запретить любые входящие подключения с полным разрешением исходящих, понимать и предотвращать ряд DoS атак, понимать SYN и другие виды сканирований — почему они возможны и каков их механизм и т.д..
Протокол TCP
Transmission Control Protocol (TCP, протокол управления передачей) — один из основных протоколов передачи данных интернета, предназначен для управления передачей данных.
Из-за перегрузки сети, балансировки нагрузки трафика или непредсказуемого поведения сети, IP-пакеты могут быть потеряны, дублированы или доставлены не в неправильном порядке. TCP обнаруживает эти проблемы, запрашивает повторную передачу потерянных данных, переупорядочивает неупорядоченные данные и даже помогает минимизировать перегрузку сети, чтобы уменьшить возникновение других проблем. Если данные все ещё остаются недоставленными, источник уведомляется об этом сбое. После того, как получатель TCP собрал последовательность первоначально переданных октетов, он передаёт их принимающему приложению. Таким образом, TCP абстрагирует связь приложения от базовых сетевых деталей.
TCP широко используется во многих интернет-приложениях, включая World Wide Web (WWW), электронную почту, протокол передачи файлов, Secure Shell, одноранговый обмен файлами и потоковое мультимедиа.
Протокол TCP оптимизирован для точной доставки, а не для своевременной доставки, и может вызывать относительно длительные задержки (порядка секунд) при ожидании сообщений, вышедших из строя или повторных передач потерянных сообщений. Поэтому он не особенно подходит для приложений реального времени, таких как передача голоса по IP.
Итак, механизм TCP предоставляет поток данных с предварительной установкой соединения, осуществляет повторный запрос данных в случае потери данных и устраняет дублирование при получении двух копий одного пакета, гарантируя тем самым, в отличие от UDP, целостность передаваемых данных и уведомление отправителя о результатах передачи.
Алгоритм работы TCP следующий:
- Устанавливается трёхэтапное рукопожатие между двумя узлами. На этом этапе узлы согласуют два числа — начальные номера первого пакета для каждого из узлов.
- При отправке пакетов узлы последовательно номеруют их, то есть каждому сетевому пакету присвоен один из последовательных номеров.
- В дополнении к номеру, для каждого пакета рассчитывается контрольная сумма. Получив пакет, вновь рассчитывается контрольная сумма для полученных данных — если она не совпадает, значит пакет был повреждён при передаче.
- Итак, поскольку все пакеты имеют последовательные номера, то становится видно если какие-то из них отсутствуют. В этом случае отправляется запрос на повторную отправку пакета.
- Если для какого-то пакета не совпала контрольная сумма, то отправляется запрос на повторную отправку пакета.
В общем, используя два простых механизма — контрольную сумму и последовательную нумерацию каждого пакета — удаётся достичь надёжности передачи данных и возможности организовать их в правильную последовательность независимо от того, в каком порядке они доставлены.
Всё это возможно с помощью заголовков TCP пакета.
Что такое 1 соединение TCP
Прежде чем изучить структуру заголовка TCP пакета, разберёмся, что такое 1 TCP соединение — это поможет яснее понимать, что именно мы анализируем в Wireshark и сколько TCP соединений нам нужно искать. К примеру, сколько TCP соединений задействуется при открытии 1 страницы веб-сайта? Типичный веб-сайт состоит из 1 страницы HTML кода, нескольких страниц каскадных таблиц стилей CSS и JavaScript файлов, а также пары десятков файлов изображений. Так вот, для получения каждого из этих файлов создаётся новое TCP соединеие. Для каждого из этих соединений выполняется трёхэтапное рукопожатие — это к вопросу о том, какие издержки, «накладные расходы» несёт в себе TCP.
То есть при открытии страницы веб-сайта браузер делает первое TCP подключение и получает исходный код веб страницы. В данном коде браузер находит ссылки на файлы стилей, скриптов, картинок — для каждого из этого файлов запускается новое TCP соединение.
Поэтому при анализе трафика в Wireshark при открытии даже одной веб страницы вы увидите множество начатых и завершённых TCP соединений.
Заголовок TCP
- Порт источника — биты 0-15. Это порт источника пакета. Исходный порт изначально был связан напрямую с процессом в отправляющей системе. Сегодня мы используем хеш между IP-адресами и портами назначения и порта источника для достижения этой уникальности, которую мы можем привязать к одному приложению или программе.
- Порт назначения — биты 16-31. Это порт назначения пакета TCP. Как и в случае с портом-источником, он изначально был напрямую связан с процессом в принимающей системе. Сегодня вместо этого используется хеш, который позволяет нам иметь больше открытых соединений одновременно. Когда пакет получен, порты назначения и исходные порты возвращаются в ответе обратно к первоначально отправляющему хосту, так что порт назначения теперь является портом источника, а порт источника является портом назначения.
Порт источника и порт назначения не обязаны быть одинаковыми: к примеру, если делается запрос к 80-му порту сервера, то этот запрос может прийти, например, с порта 34054.
Номера портов на сервере могут использоваться как стандартные, так и произвольные.
- Порядковый номер (Sequence number) — биты 32-63. Поле порядкового номера используется для установки номера в каждом TCP-пакете, чтобы можно было правильно упорядочить поток TCP (например, пакеты приводятся к правильному порядку). Затем в поле ACK возвращается порядковый номер, чтобы подтвердить, что пакет был принят правильно.
Указывает на количество переданных байт, и каждый переданный байт полезных данных (payload) увеличивает это значение на 1.
Если установлен флаг SYN (идёт установление сессии), то поле содержит изначальный порядковый номер — ISN (Initial Sequence Number). В целях безопасности это значение генерируется случайным образом и может быть равно от 0 до 2 32 -1 (4294967295). Первый байт полезных данных в устанавливающейся сессии будет иметь номер ISN+1.
В противном случае, если SYN не установлен, первый байт данных, передаваемый в данном пакете, имеет этот порядковый номер.
- Номер подтверждения (Acknowledgment Number (ACK SN)) — биты 64-95. Это поле используется, когда мы подтверждаем определённый пакет, полученный хостом. Например, мы получаем пакет с одним установленным порядковым номером, и если с пакетом все в порядке, мы отвечаем пакетом ACK с номером подтверждения, равным оригинальному порядковому номеру.
Если установлен флаг ACK, то это поле содержит порядковый номер октета, который отправитель данного сегмента желает получить. Это означает, что все предыдущие октеты (с номерами от ISN+1 до ACK-1 включительно) были успешно получены.
Каждая сторона подсчитывает свой Sequence number для переданных данных и отдельно Acknowledgement number для полученных данных. Соответственно Sequence number каждой из сторон соответствует Acknowledgement number другой стороны.
- Длина заголовка (смещение данных) — биты 96-99. В этом поле указывается длина заголовка TCP пакета и где начинаются фактические данные (полезная нагрузка). Поле имеет размер в 4 бита и указывает заголовок TCP в 32-битных словах. Заголовок должен всегда заканчиваться чётной 32-битной границей, даже с различными установленными опциями (опции могут отсутствовать вовсе, либо их количество может различаться). Это возможно благодаря полю Padding в самом конце заголовка TCP.
Минимальный размер заголовка составляет 5 слов, а максимальный — 15 слов, что даёт минимальный размер 20 байтов и максимум 60 байтов, что позволяет использовать до 40 байтов опций в заголовке. Это поле получило такое имя (смещение данных) из-за того, что оно также показывает расположение фактических данных от начала сегмента TCP.
Итак, длина заголовка определяет смещение полезных данных относительно начала сегмента. Например, Data offset равное 1111 говорит о том, что заголовок занимает пятнадцать 32-битных слова (15 строк*32 бита в каждой строке/8 бит = 60 байт).
- Зарезервировано — биты 100-102. Эти биты зарезервированы для будущего использования.
- Флаги (управляющие биты)
- NS — бит 103. ECN-nonce — concealment protection
- CWR (Congestion Window Reduced) — бит 104. Поле «Окно перегрузки уменьшено» — флаг установлен отправителем, чтобы указать, что получен пакет с установленным флагом ECE
- ECE — бит 105. ECE (ECN-Echo) — Поле «Эхо ECN» — указывает, что данный узел способен на ECN (явное уведомление перегрузки) и для указания отправителю о перегрузках в сети (RFC 3168)
- URG — бит 106. Поле «Указатель важности» задействовано. Если установлено значение 0, не используется Urgent Pointer, если установлено значение 1, то используется Urgent Pointer.
- ACK — бит 107. Этот бит устанавливается для пакета, чтобы указать, что это ответ на другой полученный нами пакет, содержащий данные. Пакет подтверждения всегда отправляется, чтобы указать, что мы фактически получили пакет, и что он не содержит ошибок. Если этот бит установлен, исходный отправитель данных проверит номер подтверждения, чтобы увидеть, какой пакет фактически подтверждён, а затем выгрузит его из буферов.
- PSH — бит 108. Флаг PUSH используется для указания протоколу TCP на любых промежуточных хостах отправлять данные фактическому пользователю, включая реализацию TCP на принимающем хосте. Это протолкнёт все данные, независимо от того, где и сколько из окна TCP было уже передано.
- RST — бит 109. Флаг RESET установлен, чтобы сообщить другому концу разорвать TCP-соединение. Это делается в нескольких различных сценариях, основными причинами которых является то, что соединение по какой-то причине разорвалось, если соединение не существует или если пакет каким-то образом неправильный.
- SYN — бит 110. SYN (или синхронизация номеров последовательности) используется во время первоначального установления соединения. Он устанавливается в двух экземплярах соединения: начальный пакет, который открывает соединение, и ответный пакет SYN/ACK. Он никогда не должен использоваться за пределами этих случаев.
- FIN — бит 111. Бит FIN указывает, что у хоста, который отправил бит FIN, больше нет данных для отправки. Когда другой конец увидит бит FIN, он ответит FIN/ACK. Как только это будет сделано, хост, который первоначально отправил бит FIN, больше не сможет отправлять какие-либо данные. Однако другой конец может продолжать отправлять данные до тех пор, пока они не будет завершаться, и затем отправит пакет FIN обратно и дождётся окончательного FIN/ACK, после чего соединение отправляется в состояние CLOSED.
- Размер окна (Window Size) — биты 112-127. Window Size определяет количество байт данных (payload), после передачи которых отправитель ожидает подтверждения от получателя, что данные получены. Иначе говоря, получатель пакета располагает для приёма данных буфером длиной "размер окна" байт.
По умолчанию размер окна измеряется в байтах, поэтому ограничен 2 16 (65535) байтами. Однако благодаря TCP опции Window scale option этот размер может быть увеличен до 1 Гбайта. Чтобы задействовать эту опцию, обе стороны должны согласовать это в своих SYN сегментах.
- Контрольная сумма — биты 128-143. Поле контрольной суммы — это 16-битное дополнение к сумме всех 16-битных слов заголовка (включая псевдозаголовок) и данных. Если сегмент, по которому вычисляется контрольная сумма, имеет длину не кратную 16-битам, то длина сегмента увеличивается до кратной 16-ти, за счёт дополнения к нему справа нулевых битов заполнения. Биты заполнения (0) не передаются в сообщении и служат только для расчёта контрольной суммы. При расчёте контрольной суммы значение самого поля контрольной суммы принимается равным 0.
- Указатель важности (Urgent pointer) — биты 144-159. 16-битовое значение положительного смещения от порядкового номера в данном сегменте. Это поле указывает порядковый номер октета, которым заканчиваются важные (urgent) данные. Поле принимается во внимание только для пакетов с установленным флагом URG. Используется для внеполосных данных.
- Опции — биты 160-**. Могут применяться в некоторых случаях для расширения протокола. Иногда используются для тестирования. На данный момент в опции практически всегда включают 2 байта NOP (в данном случае 0x01) и 10 байт, задающих timestamps. Вычислить длину поля опции можно через значение поля смещения.
Поле Options является полем переменной длины и содержит необязательные заголовки, которые мы можем захотеть использовать. По сути, это поле всегда содержит 3 подполя. В начальном поле указывается длина поля «Параметры», во втором поле указывается, какие параметры используются, а затем у нас есть фактические параметры. Полный список всех опций TCP можно найти в опциях TCP.
- Заполнение (Padding) — биты**. Поле Заполнение дополняет заголовок TCP, пока весь заголовок не закончится на 32-разрядной границе. Это гарантирует, что часть данных пакета начинается с 32-разрядной границы, и данные в пакете не теряются. Заполнение всегда состоит только из нулей.
Сессия TCP
Рукопожатие TCP (установление подключения TCP)
Для установления соединения TCP использует трёхэтапное рукопожатие.
Подключение можно выполнить только если вторая сторона прослушивает порт, к которому будет выполняться подключение: к примеру, веб-сервер прослушивает порты 80 и 443. То есть это не охватывается рукопожатием, но прежде чем клиент попытается соединиться с сервером, сервер должен сначала подключиться к порту и начать прослушивать его, чтобы открыть его для соединений: это называется пассивным открытием. Как только пассивное открытие установлено, клиент может инициировать активное открытие. Для установления соединения происходит трёхэтапное (или трёхступенчатое) рукопожатие:
Первый этап, отправка пакета с включённым флагом SYN: активное открытие выполняется клиентом, отправляющим SYN на сервер. Клиент устанавливает порядковый номер сегмента на случайное значение A.
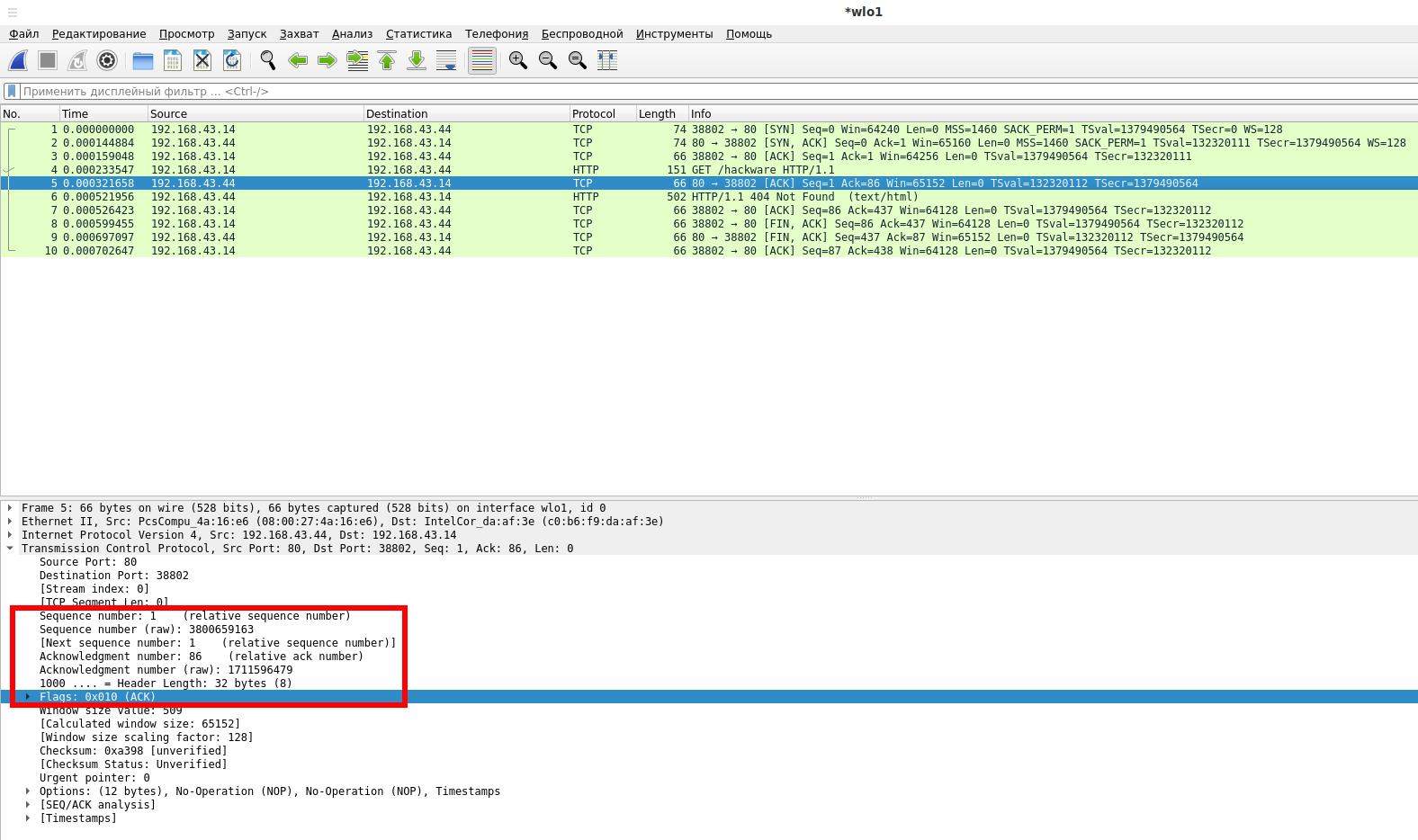
Обратите внимание, что по умолчанию Wireshark показывает относительное значение порядкового номера (Sequence number), чуть ниже вы также можете видеть реальное значение (показано как raw).
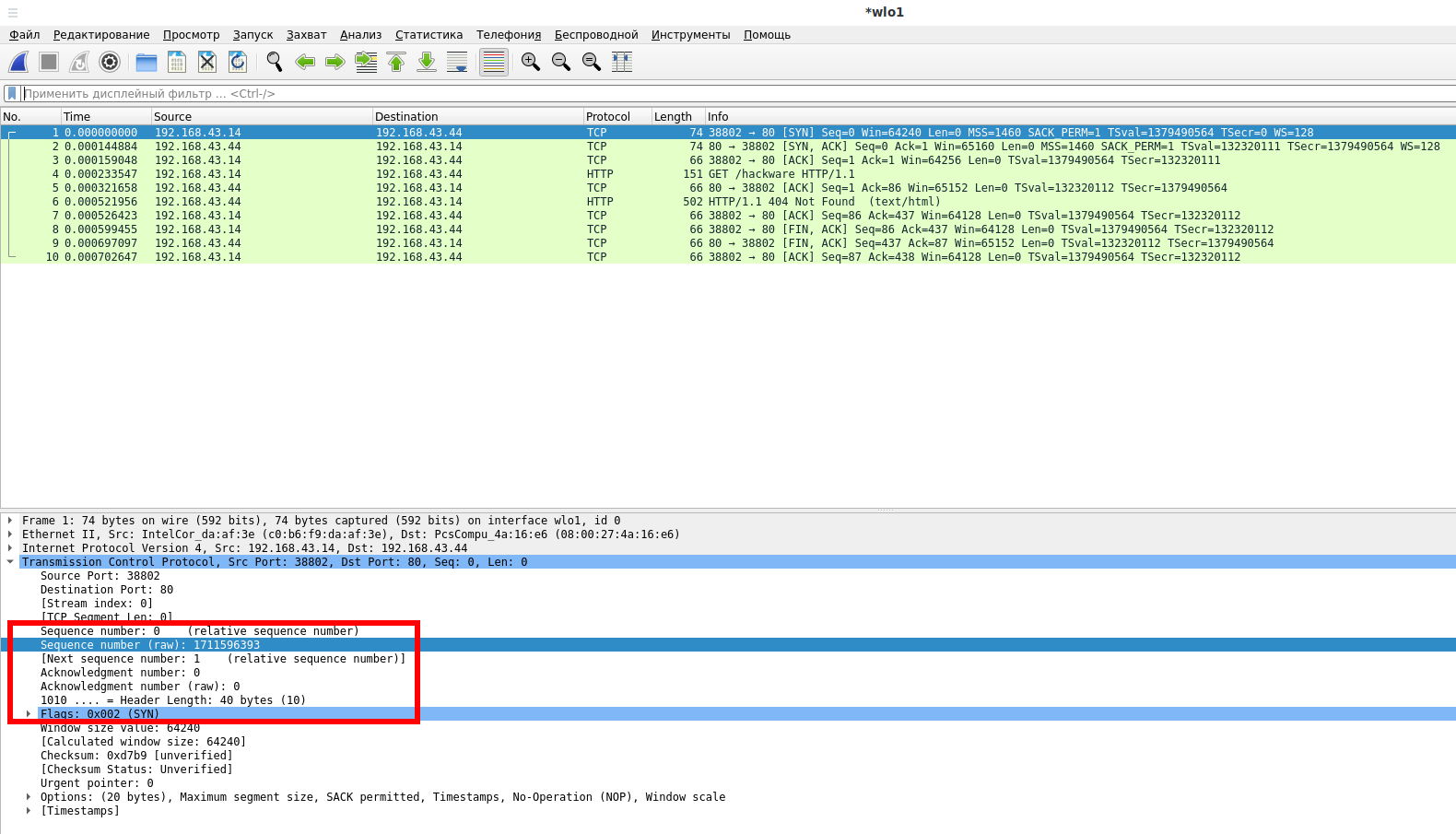
Второй этап, отправка пакета с включённым флагом SYN-ACK: В ответ сервер отвечает SYN-ACK. Номер подтверждения установлен на единицу больше принятого Порядкового номера (Sequence number), то есть A+1. Поскольку сервер также будет отправлять данные, то для себя он тоже выбирает Порядковый номер (Sequence number) первого пакета с данными, который будет другим случайным числом B.

Третий этап, отправка пакета с включённым флагом ACK: наконец, клиент отправляет ACK обратно на сервер. Порядковый номер устанавливается равным полученному значению подтверждения, то есть A+1, а номер подтверждения устанавливается на единицу больше, чем принятый порядковый номер, то есть B+1.

На этом этапе и клиент, и сервер получили подтверждение соединения. Шаги 1, 2 устанавливают параметр соединения (порядковый номер) для одного направления, и оно подтверждается. Шаги 2, 3 устанавливают параметр соединения (порядковый номер) для другого направления, и он подтверждается. Таким образом устанавливается полнодуплексная (двухсторонняя) связь.
Передача данных в TCP
PSH-ACK: Клиент отправляет запрос к серверу по HTTP протоколу, поскольку данные поместились в один сетевой пакет TCP, то он имеет флаг PSH, чтобы сервер не ждал продолжение получения данных, а отправил их веб-серверу для выполнения.
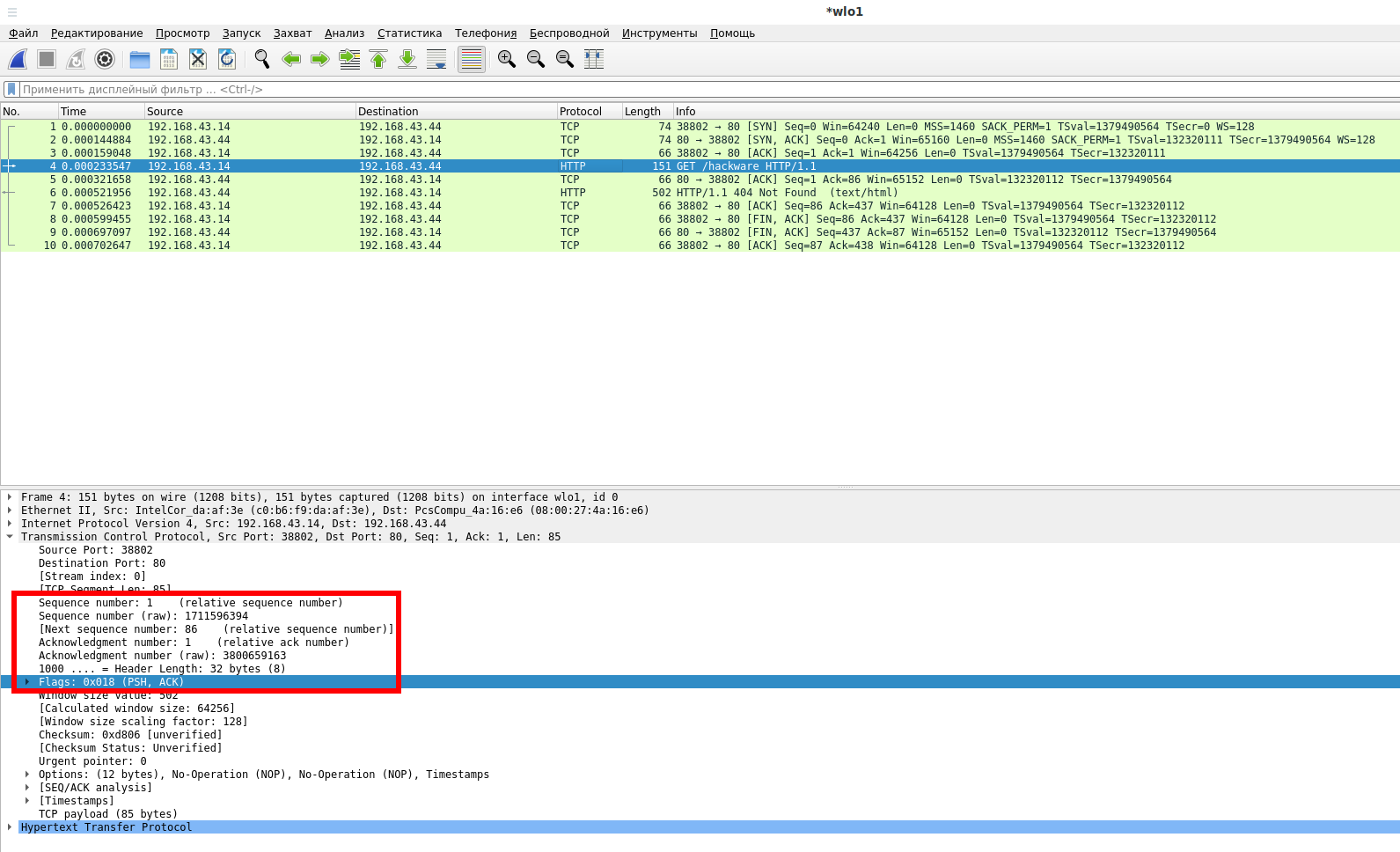
ACK: В ответ на принятую информацию сервер отправляет пакет ACK с номером успешно полученных данных.
PSH-ACK: Сервер обработал запрос и отправляет данные — веб страницу
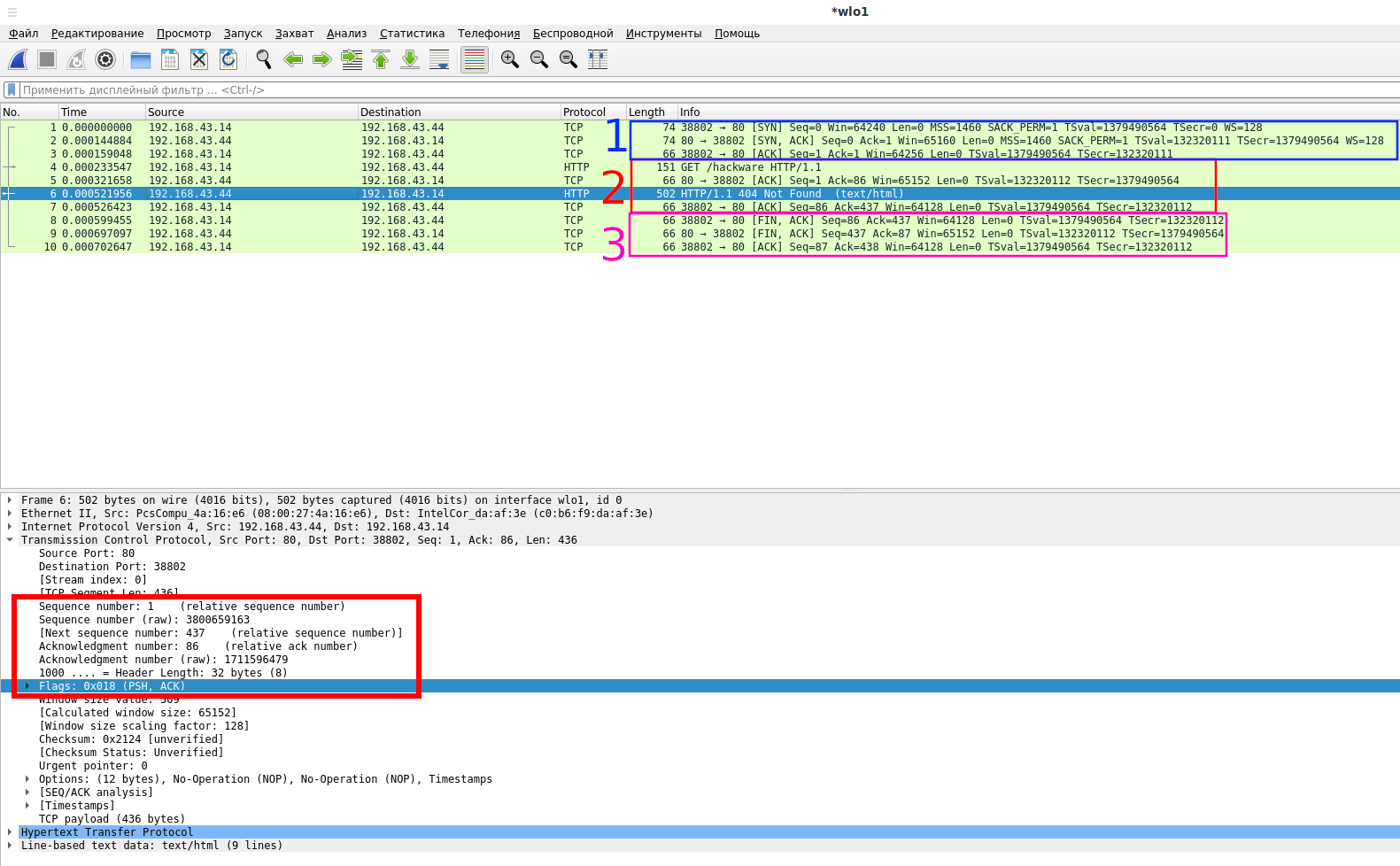
ACK: клиент подтверждает, что данные получены
На последнем скриншоте:
1 — установка соединения
2 — передача данных
3 — завершение соединения
Завершение соединения
Фаза завершения соединения использует четырёхэтапное рукопожатие, причём каждая сторона соединения завершается независимо. Когда конечная точка хочет остановить свою половину соединения, она передаёт пакет FIN, который другой конец подтверждает пакетом с флагом ACK. Поэтому для типичного разрыва требуется пара сегментов FIN и ACK от каждой конечной точки TCP. После того, как сторона, отправившая первый FIN, ответила с последним ACK, она ожидает тайм-аута, прежде чем окончательно закрывает соединение, в течение которого локальный порт недоступен для новых соединений; это предотвращает путаницу из-за задержанных пакетов, доставляемых во время последующих соединений.
Соединение может быть «полуоткрытым», и в этом случае одна сторона завершила свою часть, а другая — нет. Завершившая сторона больше не может отправлять какие-либо данные в соединение, но другая сторона может. Завершающая сторона должна продолжить чтение данных, пока другая сторона также не завершит свою работу.
Также возможно разорвать соединение трёхэтапным рукопожатием, когда хост A отправляет FIN, а хост B отвечает FIN&ACK (просто объединяет 2 шага в один), а хост A отвечает ACK.
Некоторые операционные системы, такие как Linux и H-UX, реализуют полудуплексную последовательность закрытия в стеке TCP. Если хост активно закрывает соединение, но при этом остаются непрочитанными входящие данные, хост отправляет сигнал RST (потеря всех полученных данных) вместо FIN. Это гарантирует приложению TCP, что удалённый процесс прочитал все переданные данные, ожидая сигнала FIN, прежде чем он активно закроет соединение. Удалённый процесс не может различить сигнал RST для прерывания соединения и потери данных. Оба вызывают удалённый стек, чтобы потерять все полученные данные.
Как можно увидеть на скриншоте, завершение TCP соединения также происходит как (Linux с последним ядром):
Клиент: FIN-ACK
Сервер: FIN-ACK
Клиент: ACK
Состояния клиента и сервера
| Состояния сеанса TCP | |
|---|---|
| CLOSED | Начальное состояние узла. Фактически фиктивное |
| LISTEN | Сервер ожидает запросов установления соединения от клиента |
| SYN-SENT | Клиент отправил запрос серверу на установление соединения и ожидает ответа |
| SYN-RECEIVED | Сервер получил запрос на соединение, отправил ответный запрос и ожидает подтверждения |
| ESTABLISHED | Соединение установлено, идёт передача данных |
| FIN-WAIT-1 | Одна из сторон (назовём её узел-1) завершает соединение, отправив сегмент с флагом FIN |
| CLOSE-WAIT | Другая сторона (узел-2) переходит в это состояние, отправив, в свою очередь сегмент ACK и продолжает одностороннюю передачу |
| FIN-WAIT-2 | Узел-1 получает ACK, продолжает чтение и ждёт получения сегмента с флагом FIN |
| LAST-ACK | Узел-2 заканчивает передачу и отправляет сегмент с флагом FIN |
| TIME-WAIT | Узел-1 получил сегмент с флагом FIN, отправил сегмент с флагом ACK и ждёт 2*MSL секунд, перед окончательным закрытием соединения |
| CLOSING | Обе стороны инициировали закрытие соединения одновременно: после отправки сегмента с флагом FIN узел-1 также получает сегмент FIN, отправляет ACK и находится в ожидании сегмента ACK (подтверждения на свой запрос о разъединении) |
Описание данных состояний позволяет лучше понимать информацию, которую показывают программы о состоянии сети, такие как netstat и ss (смотрите также «Как проверить открытые порты на своём компьютере. Что означают 0.0.0.0, :*, [::], 127.0.0.1. Как понять вывод NETSTAT»).
Фильтры Wireshark для TCP
Чтобы увидеть только трафик TCP:
Показать трафик, источником или портом назначения которого является определённый порт, например 8080:
Показать трафик, источником которого является порт 80:
Показать трафик, который отправляется службе, прослушивающей порт 80:
Показать TCP пакеты с включённым флагом SYN:
Показать TCP пакеты с включённым флагом SYN и отключённым флагом ACK:
Аналогично и для других флагов:
- SYN
- ACK
- RST
- FIN
- CWR
- ECE
- URG
- PSH
- NS
Также можно использовать синтаксис вида tcp.flags == 0x0XX, например:
- FIN это tcp.flags == 0x001
- SYN это tcp.flags == 0x002
- RST это tcp.flags == 0x004
- ACK это tcp.flags == 0x010
- Установленные одновременно ACK и FIN это tcp.flags == 0x011
- Установленные одновременно ACK и SYN это tcp.flags == 0x012
- Установленные одновременно ACK и RST это tcp.flags == 0x014
Длина заголовка (смещение данных):
Пакеты с установленными зарезервированными битами:
Вычесленный размер окна:
Фактор масштабирования размера окна:
tcp.window_size_value — это необработанное значение размера окна, считываемое непосредственно из заголовка TCP, тогда как tcp.window_size — это вычисленный размер окна, который основан на том, применимо ли масштабирование окна или нет. Если масштабирование окна не используется или коэффициент масштабирования равен 1 или неизвестно, применимо ли масштабирование окна или нет, потому что трёхэтапное рукопожатие TCP не было захвачено, тогда эти два значения будут одинаковыми. С помощью tcp.window_size_scalefactor вы можете определить, какое из этих условий применимо — если его значение равно -1, то оно неизвестно, если его значение равно -2, тогда масштабирование окна не используется, а все остальные значения представляют фактический размер фактора масштабирования окна.
Чтобы показать пакеты, содержащие какую либо строку, например, строку hackware:
Следовать потоку TCP с номером X:
Фильтровать по номеру потока:
Показать повторные отправки пакетов. Помогает прослеживать замедление производительности приложений и потери пакетов:
Этот фильтр выведен проблемные пакеты (потерянные сегменты, повторную отправку и другие. Этот фильтр проходят пакеты TCP Keep-Alive, но они не являются показателем проблем.
Фильтры для оценки качества сетевого подключения.
Следующие характеристики относятся к TCP фреймам. Причём они не основываются на заголовках фрейма — рассматриваемые характеристики (пропуск данных, дубли) присвоены программой Wireshark исходя из анализа.
Фильтр выводит информацию о фреймах с флагом ACK, которые являются дублями. Большое количество таких фреймов может говорить о проблемах связи:
Фильтр показа фреймов для которых не захвачен предыдущий сегмент:
Это нормально в начале захвата данных — поскольку информация перехватывается не с самого начала сессии.
Для показа фреймов, которые являются ретрансмиссией (отправляются повторно):
Вывод фреймов, которые получены не в правильном порядке:
Виды сканирований Nmap
Мы рассмотрели механизм рукопожатия TCP, напомним его структуру:
- Клиент: SYN
- Сервер: SYN-ACK
- Клиент: ACK
Знаменитый сканер портов Nmap по умолчанию выполняет сканирования с использованием полуотрытых соединений, или его ещё называют SYN сканированием. На самом деле, это не что иное, как отправленный пакет с включённым флагом SYN — то есть Nmap инициирует рукопожатие TCP. Если в ответ приходит пакет с флагами SYN-ACK (то есть удалённый хост отправляет свою часть рукопожатия), то это означает, что порт открыт. Если удалённый хост отвечает пакетом с флагом RST-ACK, то это означает, что порт закрыт.
Такой метод, с одной стороны, является универсальным — любой открытый порт обязательно должен ответить пакетом с флагами SYN-ACK, поскольку это стандарт транспортного протокола TCP. Но при этом Nmap не завершает рукопожатие, то есть не создаётся полноценное соединение и приложение, которое прослушивает просканированный порт, никогда не узнает об этом неудачном TCP рукопожатии, и этот факт не отобразиться в журналах этого приложения.
Пример сканирования портов:
На следующем скриншоте мы можем видеть отправленные и полученные пакеты:
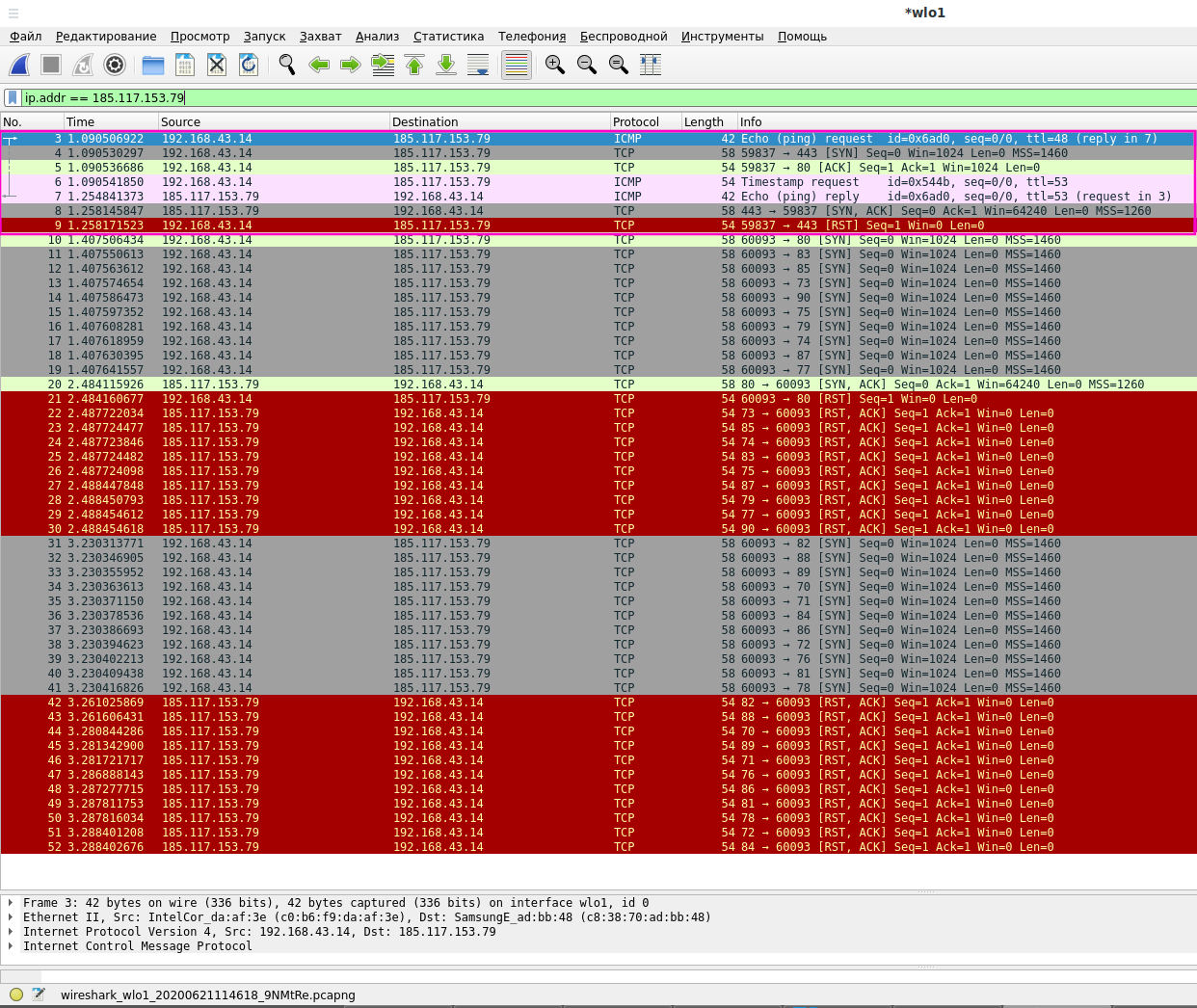
Первая группа пакетов (выделена прямоугольником) — пинг хоста, чтобы определить, доступен ли он. Также на этапе доступности хоста делается запрос к портам 80 и 443 (хотя порт 443 не указан для сканирования), видимо, также для подтверждения того, что хост онлайн.
Если от порта получен пакет SYN-ACK (сервер готов к установке соединения), то Nmap отвечает пакетом с флагом RST для обрыва начатого рукопожатия.
Вторая группа — они отмечены серым и зелёным — это непосредственно сканирование портов — это пакеты с флагом SYN. Серым отмечены те, которые прислали ответ RST-ACK (порт закрыт), а зелёным т е, которые прислали ответ SYN-ACK (порт открыт).
Пакеты RST-ACK, а также пакеты RST (от Nmap) помечены красным.
Как можно увидеть, техника очень простая и использует самые базовые возможности трансопртного протокола TCP.
Кроме этого метода, Nmap поддерживает ещё несколько типов сканирования:
Если вы хотите узнать об этих опциях и типах сканирвоания подробнее, то рекомендуется изучить их на справочной странице Nmap: https://kali.tools/?p=1317
Теперь, когда понятна суть сканирований портов, можно предложить меры по защите сервера от сканирований. Если ваш сервер предназначен принимать входящие соединения (например, это веб сервер с SSH), то на 100% защититься от сканирований портов нельзя, поскольку для полуоткрытых соединений используются «легальные» TCP пакеты с флагом SYN, которые являются первой частью рукопожатий. Тем не менее в iptables или fail2ban можно настроить примерно такое правило: «если от одного удалённого хоста поступило более 10 SYN пакетов за указанный промежуток времени, то отклонять его последующие попытки подключения». Это затруднит или даже сделает невозможным массовое сканирование портов на вашем сервере.
Если у вас настроен контроль доступа по IP, то можно запретить SYN пакеты от любого хоста, кроме разрешённых IP, — в этом случае посторонние не только не смогут подключаться, но и не смогут узнать, что порт на самом деле открыт.
Примеры iptables
[БУДЕТ ДОБАВЛЕНО ПОЗЖЕ]
Протокол UDP
Если вы смогли разобраться с TCP и его заголовками, то с UDP вам будет совсем просто.
Протокол пользовательских дейтаграмм (UDP) — это очень простой протокол. Он был разработан для обеспечения очень простой передачи данных без какого-либо обнаружения ошибок. Это так называемый stateless (то есть «без состояния») протокол, это отличает его от протокола TCP, в котором есть понятие соединения (stateful), включающее в себя создания подключения (трёхэтапное рукопожатие) и в котором передача данных выполняется только в рамках данного подключения. Соответственно, для протокола UDP не предусмотрены различные состояния клиента и сервера.
Однако он очень хорошо подходит для приложений типа запрос/ответ, таких как, например, DNS и т. д., поскольку мы знаем, что если мы не получим ответ от DNS-сервера, запрос где-то был потерян. Иногда также стоить использовать протокол UDP вместо TCP, например, когда мы хотим только обнаружение ошибок/потерь, но не заботимся о последовательности пакетов. Это устраняет некоторые издержки, связанные с протоколом TCP.
Природа UDP как протокола без сохранения состояния также полезна для серверов, отвечающих на небольшие запросы от огромного числа клиентов, например DNS и потоковые мультимедийные приложения вроде IPTV, Voice over IP, протоколы туннелирования IP и многие онлайн-игры.
Что такое 1 соединение UDP
Для UDP пакетов понятие «соединение» неправильное, поскольку отправляется один пакет без установки соединения. Если требуется передать поток данных, то отправляется множество UDP пакетов, которые хотя и могут иметь одну общую задачу, с точки зрения транспортного протокола каждый из них является независимым.
В ответ также может прийти один или несколько пакетов UDP. Они приходят на тот же порт, с которого был отправлен исходный UDP пакет — это позволяет определить, что данная датаграмма является ответной на отправленную ранее.
Тем не менее при открытом UDP порте состояние сервера становится LISTEN (сервер ожидает запросов установления соединения от клиента). Также UDP соединение может иметь статус UCONN или ESTAB.
Как можно увидеть, UDP пакет отправлен с порта 42044:
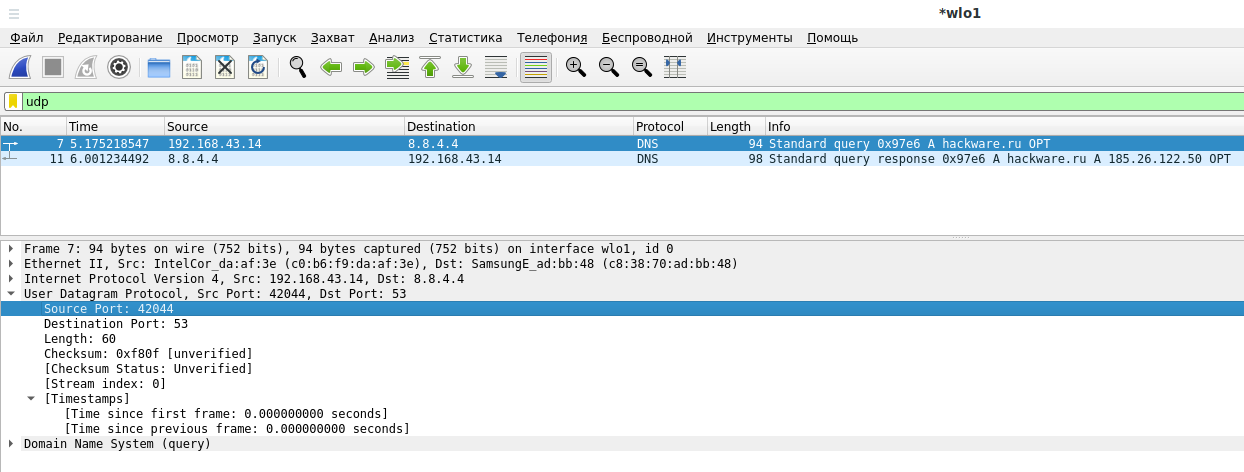
Ответный UDP пакет также пришёл на порт 42044:
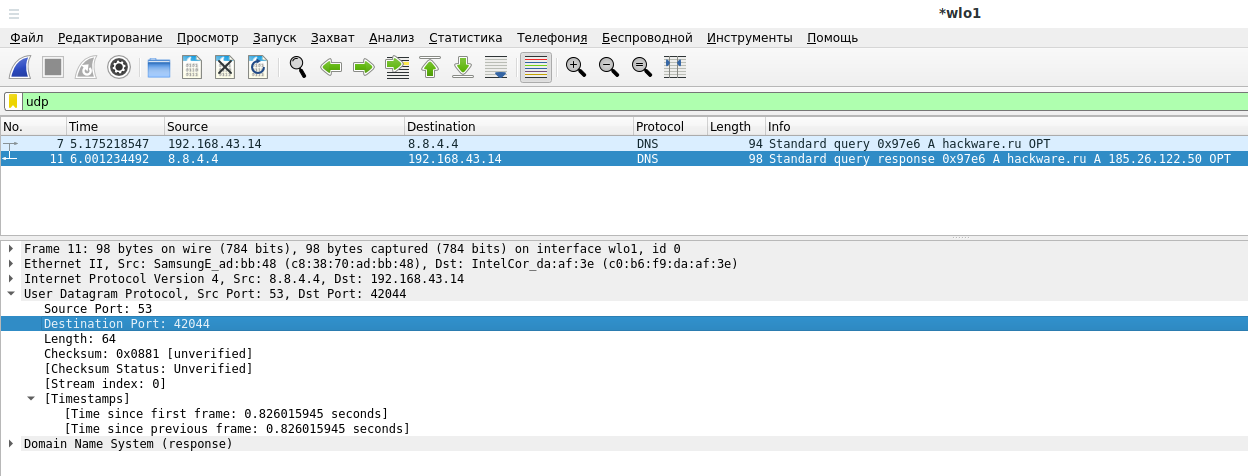
Если сравнить с TCP, то минимальное количество пакетов для отправки запроса и получения информации — 10, а для UDP минимальное количество пакетов для отправки запроса и получения информации — 2.
Заголовок UDP
Можно сказать, что заголовок UDP представляет собой очень упрощённый заголовок TCP. Он содержит порты назначения, порты источника, длину заголовка и контрольную сумму, как показано на рисунке ниже.
- Исходный порт — биты 0-15. Это порт источника пакета, описывающий, куда должен быть отправлен ответный пакет. Он может фактически быть установлено на ноль, если значение порта не применимо. Например, иногда нам не требуется ответный пакет, то тогда пакет может быть установлен на нулевой порт источника. В большинстве реализаций он установлен на некоторый номер порта.
- Порт назначения — биты 16-31. Порт назначения пакета. Это требуется для всех пакетов, в отличие от порта источника пакета.
Как и с протоколом TCP — для сервера обычно используется один из стандартных портов (например, порт 53 для DNS серверов), а порт источника выбирается произвольно для каждого соединения, обычно это номера портов с большим номером (десятки тысяч).
- Длина — биты 32-47. Поле длины указывает длину всего пакета в октетах, включая заголовок и части данных. Самый короткий возможный пакет может быть длиной 8 октетов.
Поле, задающее длину всей датаграммы (заголовка и данных) в байтах. Минимальная длина равна длине заголовка — 8 байт. Теоретически, максимальный размер поля — 65535 байт для UDP-датаграммы (8 байт на заголовок и 65527 на данные). Фактический предел для длины данных при использовании IPv4 — 65507 (помимо 8 байт на UDP-заголовок требуется ещё 20 на IP-заголовок).
- Контрольная сумма — биты 48-63. Контрольная сумма — это та же контрольная сумма, что и в заголовке TCP, за исключением того, что она содержит другой набор данных. Другими словами, это дополнение к сумме дополнительных частей заголовка IP, всего заголовка UDP, данных UDP и дополнения нулями в конце, когда это необходимо.
Поле контрольной суммы используется для проверки заголовка и данных на ошибки. Если сумма не сгенерирована передатчиком, то поле заполняется нулями. Поле не является обязательным для IPv4.
Фильтры Wireshark для UDP
Чтобы увидеть только трафик UDP:
Для UDP не используются флаги. Для этого протокола можно только указать порт.
Показать трафик, источником которого является порт 53:
Показать трафик, который отправляется службе, прослушивающей порт 53:
UDP пакет, в котором встречается определённая строка, например, строка hackware:
Порт назначения ИЛИ исходный порт:
Время между пакетами (для выявления проблем сети):
Номер потока (запрос-ответ):
Сравнение UDP и TCP
TCP — ориентированный на соединение протокол, что означает необходимость «рукопожатия» для установки соединения между двумя хостами. Как только соединение установлено, пользователи могут отправлять данные в обоих направлениях.
- Надёжность — TCP управляет подтверждением, повторной передачей и тайм-аутом сообщений. Производятся многочисленные попытки доставить сообщение. Если оно потеряется на пути, сервер вновь запросит потерянную часть. В TCP нет ни пропавших данных, ни (в случае многочисленных тайм-аутов) разорванных соединений.
- Упорядоченность — если два сообщения последовательно отправлены, первое сообщение достигнет приложения-получателя первым. Если участки данных прибывают в неверном порядке, TCP отправляет неупорядоченные данные в буфер до тех пор, пока все данные не могут быть упорядочены и переданы приложению.
- Тяжеловесность — TCP необходимо три пакета для установки сокет-соединения перед тем, как отправить данные. TCP следит за надёжностью и перегрузками.
- Потоковость — данные читаются как поток байтов, не передается никаких особых обозначений для границ сообщения или сегментов.
UDP — более простой, основанный на сообщениях протокол без установления соединения. Протоколы такого типа не устанавливают выделенного соединения между двумя хостами. Связь достигается путём передачи информации в одном направлении от источника к получателю без проверки готовности или состояния получателя. В приложениях для голосовой связи через интернет-протокол (Voice over IP, TCP/IP) UDP имеет преимущество над TCP, в котором любое «рукопожатие» помешало бы хорошей голосовой связи. В VoIP считается, что конечные пользователи в реальном времени предоставят любое необходимое подтверждение о получении сообщения.