СУБД. Лекция 7
Репликация позволяет создать копию базы данных в географически удаленном пункте, например в другом центре обработки данных.
Балансировка нагрузки
С помощью репликации можно распределить запросы на чтение между несколькими серверами. В приложениях с интенсивным чтением эта тактика работает очень хорошо.
Реализовать несложное балансирование нагрузки можно, внеся совсем немного изменений в код.
Репликация
Резервное копирование
Репликация ― это ценное подспорье для резервного копирования. Однако подчиненный сервер все же не может использоваться в качестве резервной копии и не является заменой настоящему резервному копированию.
Аварийное переключение на резервный сервер (failover)
Репликация позволяет исправить ситуацию, при которой сервер является единственной точкой отказа приложения. Хорошая система аварийного переключения при отказе, имеющая в составе реплицированные подчиненные серверы, способна существенно сократить время простоя.
Репликация
Тестирование новых версий
Очень часто на подчиненный сервер устанавливают новую версию СУБД и перед тем как ставить ее на промышленные серверы, проверяют, что все запросы работают нормально.
Передача изменений в приложение
Все изменения данных могут передаваться для анализа в стороннее приложение непосредственно после фиксации в базе.
Варианты взаимодействия
Варианты реализации
Гарантии репликации
Физическая репликация
Общий принцип:
- Главный сервер записывает изменения данных в журнал транзакций;
- Подчиненный сервер копирует события журнала транзакций;
- Подчиненный сервер воспроизводит изменения из журнала транзакций.
Физическая репликация
Плюсы:
- Простота и надёжность;
- Подчиненный сервер в точности соответвует мастер-серверу;
- Практически отсутствуют накладные расходы.
Физическая репликация
Минусы:
- Если данные на мастере были испорченны из-за сбоев RAM, то на подчинённом сервере так же будут испорченные данные;
- На реплике не может быть локальных изменений схемы данных;
- Обновление индексов и VACUUM так же попадают в журнал транзакций, это порождает избыточное сетевое общение;
- Реплика может временно отставать, если на подчинённом сервере выполняется запрос на длительное чтение данных;
- На подчинённом сервере должна быть та же версия PostgreSQL, что и на мастере;
- Не возможна мастер-мастер репликация;
- VACUUM на мастере может удалить еще используемые данные на подчинённом.
Логическая репликация (Slony-I)
Slony использует триггеры PostgreSQL для привязки к событиям INSERT/DELETE/UPDATE и хранимые процедуры для выполнения действий.
Логическая репликация (Logical Decoding)
Общий принцип:
- Мастер сервер записывает изменения данных в журнал транзакций;
- На базе журнала транзакций мастер сервер восстанавливает информация об изменении записей;
- Данные об изменении записей передаются на подчиненный сервер.
Реализации:
- Postgres 10
- pglogical
- Postgres-BDR
Логическая репликация
Плюсы:
- Более компактный обмен данными;
- Если данные на мастере были испорченны из-за сбоев RAM, то репликация остановится;
- Репликация не может отставать из-за VACUUM;
- На мастере и подчинённом сервере могут быть разные версии PostgreSQL;
- На мастере и подчинённом сервере можно использовать разную схему данных;
- Потенциально возможна мастер-мастер репликация.
Логическая репликация
Минусы:
- Более высокая нагрузка на подчинённый сервер;
- Надо крайне аккуратно работать со схемой данных;
- Нет хорошего решения проблемы репликации DDL-запросов.
А как обстоят дела у соседей MySQL?
В MySQL используется только логическая репликация.
Архитектура MySQL
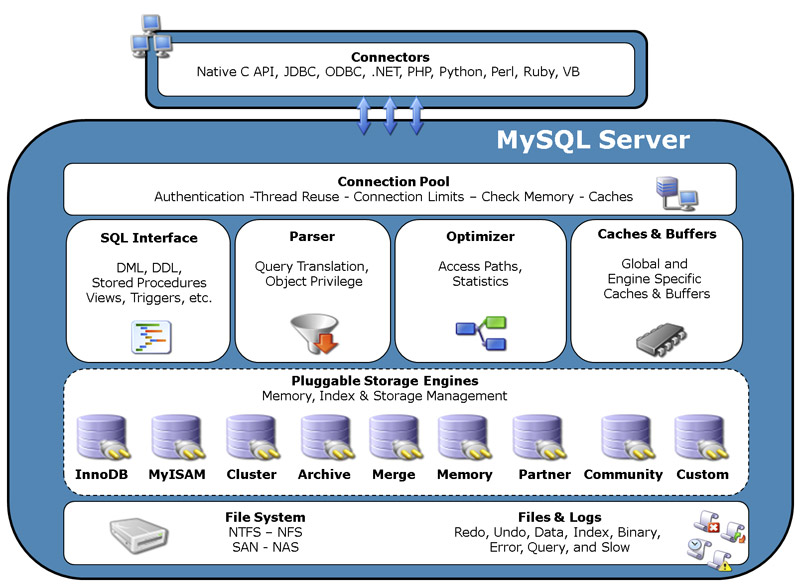
Архитектура MySQL
В MySQL различные хранилища объектов реализованы в виде подключаемых модулей.
Это порождает конфликт интересов:
- Подключаемые хранилищая требуют четкого и простого API для взаимодействия с ядром MySQL. Это требует, чтобы ядро знало о хранилище как можно меньше;
- Для эффективного выполнения запросов нужно знать о хранении данных как можно больше.
Данная особенность архитектуры MySQL проходит красной нитью через весь функционал.
Архитектура MySQL
В MySQL хранилище и лог транзакций существуют за пределами «движка» СУБД.
Как следствие, в MySQL вместо журнала транзакций для репликации используется отдельный журнал.
Репликация в MySQL
Режимы репликации:
Сохраняются непосредственно запросы, которые информаци об изменениях записей.
Сохраняется информаци об изменениях записей.
В случае DDL-выражений сохраняются сами запросы.
Промежуточный формат, который старается использовать statement, когда возможно, а когда нет — row.
Репликация в MySQL
- Репликация провоцирует больше записи на диск;
- Реплика воспроизводит транзакции по очереди;
- Двухфазная фиксации транзакции (между журналом транзакций и журналом репликации);
- Репликация хрупкая, так как некоторые запросы гарантировано ведут к порче данных.
Пример проблемного запроса:
Пару слов про кластеры
Кластер представляется как одна система (Single-System Image, SSI), то есть эквивалент операционной системы для кластера в целом.
В результате нет необходимости в модификации существующих приложений — все это осуществляется автоматически, прозрачно для приложений пообно SMP.
Узлы кластера используют единую файловую систему.
Операционная система берет на себя координацию работы с файловой системой и ряд сервисных функций.
Приложение должно явно поддерживать работу в кластере.
Функции кластера целиком реализуются внутри приложения.
Postgres-XL
Postgres-XL позволяет объединить несколько кластеров PostgreSQL таким образом, чтоб они работали как один инстанс БД.
Для клиента, который подключается в базе, нет никакой разницы, работает он с единственным инстансом PostgreSQL или с кластером Postgres-XL. Postgres-XL предлагает 2 режима распределения таблиц по кластеру: репликация и шардинг.
При репликации все узлы содержат одинаковую копию таблицы, а при шардинге данные равномерно распределяются среди членов кластера.
Pgpool II
Pgpool II позволяет балансировать нагрузку на чтение между частями кластера.
Для клиента, который подключается в базе, нет никакой разницы, работает он с единственным инстансом PostgreSQL или с кластером Pgpool II.
Есть поддержка Failover.
Полнотекстовый поиск
В чем проблема?
- Результат поиска нельзя оценивать бинарно: часть текстов больше, а часть меньше удовлетворяют поисковому запросу;
- Нужно учитывать словоформы: падежи, склонения, спряжения и т.п.;
- Документы могут быть не нескольких языках;
- Понотекстовый поиск должен работать быстро.
Предварительная обработка
Словоформы
Запрос: мыла раму
Текст: Мама мыла раму
Запрос: мыть раму
Текст: Мама мыла раму
Запрос: мягкая булка
Текст: Съешь ещё этих мягких французских булок и выпей чаю
Словоформы
Кровать
Глагол, несовершенный вид, переходный, тип спряжения по классификации А. Зализняка — 2b.
| Число | Лицо | Глагол |
|---|---|---|
| ед. | 1-е я (что делаю) | Крую |
| 2-е ты (что делаешь) | Круёшь | |
| 3-е он, она (что делает) | Круёт | |
| мн. | 1-е мы (что делаем) | Круём |
| 2-е вы (что делаете) | Круёте | |
| 3-е они (что делают) | Круют |
Проспрягал по образу «ковать»
Словари в PostgreSQL
Создавая словари, можно:
- определять стоп-слова, которые не будут индексироваться;
- сопоставлять синонимы с одним словом, используя Ispell;
- сопоставлять словосочетания с одним словом, используя тезаурус;
- сопоставлять различные склонения слова с канонической формой, используя словарь Ispell;
- сопоставлять различные склонения слова с канонической формой, используя стеммер Snowball.
Словари для Русского языка
В PostgreSQL по-умолчанию нет словарей для Русского языка, но можно воспользоваться словарями из пакета myspell-ru:
Репликация баз данных
Чаще всего репликацию связывают с базами данных и мы в основном будем говорить о базах данных на примере MS SQL Server. Причем не только с классическими базами, но и такими специализированными, как Active Directory. Но на этом мир не перевернулся, репликацию можно удачно использовать и для простых файлов, главное правильный подход.
Репликация в MS SQL Server строиться на трех понятиях – издатель, дистрибутор и подписчик. Чтобы понять, что это означает, достаточно обратиться к нашей реальной жизни, где издатель выдает какую-то информацию дистрибутору, а тот рассылает ее подписчикам. Точно также и в компьютерной жизни. Но обо всем по порядку.
Издатель — хранит источник базы данных, делая опубликованные данные из таблиц базы данных доступными для репликации, находит и отправляет изменения дистрибьютору.
Дистрибьютор – это сервер, который содержит распределенную базу данных и хранит метаданные, историю данных и транзакции. Роль дистрибьютора может быть разной и зависит от типа развернутой репликации.
Дистрибьютор и издатель могут быть на одном компьютере. Чаще всего нет смысла выделять для каждого отдельный сервер, но для большой базы данных, и наиболее активных сайтов, можно располагать дистрибьютора на собственном сервере для оптимизации производительности.
Подписчик – владеет копией данных, и получает изменения произведенные издателем. В зависимости от настроек репликации, подписчик может иметь права изменять данные и реплицировать их обратно издателю для репликации другим подписчикам. Это называется обновляющий подписчик.
Фильтруй базар
Возможно, для публикации вам нужен поднабор таблицы как отдельной статьи. Это называется фильтрацией данных. Фильтрация данных позволяет избавиться от конфликтов репликации, когда несколько сайтов имеют право обновлять данные. Ты можешь фильтровать таблицы вертикально, горизонтально или смешанно для создания отфильтрованной порции данных.
Вертикальный фильтр содержит поднабор колонок таблицы. Только реплицированные колонки отображаются подписчику. Для примера, можно использовать вертикальный фильтр для публикации всех колонок кроме «Заработная плата» в таблице «Работники».
Горизонтальный фильтр содержит поднабор строк таблицы. Подписчик получает только этот поднабор строк. Если ненужно реплицировать информацию о левых доходах, то ее можно отфильтровать запросом.
Возможно подписание на публикацию с помощью Push или Pop метода. Метод Push обычно используется в приложениях, которые должны отправлять изменения подписчику как можно быстрее после изменения. Этот метод более предпочтителен для публикаций требующих высокую защищенность и где высокая загрузка процессора у дистрибьютора не влияет на производительность.
Метод Pop более подходит в публикациях с меньшей защищенностью и может поддерживать большое количество подписчиков, например подписчики Internet.
Типы репликации
Существует три основных типа репликации: снимок, журнальный и смешение. Тип репликации назначается каждой публикации. Таким образом, возможно использование нескольких типов репликации в одной базе данных.
Репликация снимка распределяет данные напрямую как отображение на определенный момент, без мониторинга изменений. Это самый простой тип, при котором происходит банальное копирование снимка всех или отфильтрованных данных. Можете уронить свой взгляд на этот тип в следующих случаях:
- данные изменяются существенно, но редко;
- подписчику требуются данные только для чтения;
- возможна большая задержка, потому что данные обычно только периодически обновляются;
- подписчику требуется автономность.
При репликации транзакций от источника к приемнику поступают только изменения. Агент мониторит изменения в журнале транзакций на изменение реплицированных данных и переносит необходимые записи дистрибьютору. Агент дистрибьютора отправляет изменения подписчику. Прежде чем этот тип начнет работать, подписчику отправляется полный снимок реплицированных таблиц, а затем подписчик получает только изменения.
Репликация транзакций может использоваться там, где необходимо, чтобы подписчик получал изменения с минимальной задержкой.
Смешение — этот тип позволяет сайтам автономно изменять реплицированные данные. Позже, изменения с сайтов сливаются в одно целое. Этот тип не гарантирует целостности транзакций, но он гарантирует, что все сайты сливаются в один результирующий набор.
Репликация MS SQL Server
Очень удачно сделана возможность репликации в MS SQL Server. Настройка проста, как три копейки, потому что ее легко сделать с помощью двух мастеров, но есть подводные камни, о которых мастер не может рассказать, а мануалы просто умалчивают. Итак, давайте бегло пробежимся по процессу настройки репликации и сделаем упор на подводные булыжники, о которых все молчат как рыбы.
Для начала необходимо создать издателя и дистрибутора. Для этого на одном из серверов выбираем меню Tools | Replication | Create and Manage Publication. Я бы порекомендовал использовать для издателя машину помощнее. Первое, что у нас попросит мастер – выбрать базу данных. Выбираем, жмем Create Publication, и на следующем этапе сервер предложит создать дистрибутора. По умолчанию дистрибутором предлагается сделать ту же машину.
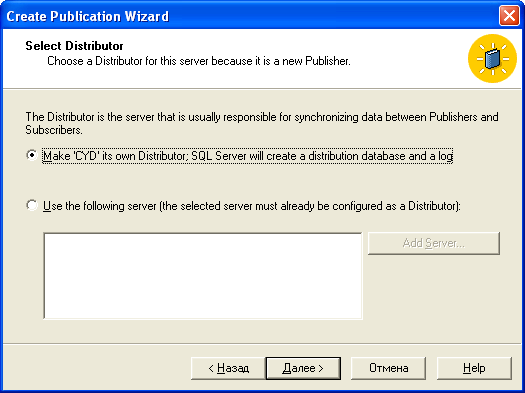
Мастер запрашивает создание дистрибутора репликации
Тут появляется первый подводный камень – если дистрибутор будет установлен на удаленно от издателя (на другой машине), то SQL Server Agent не может работать от имени системного аккаунта. Почему? Агент должен иметь возможность авторизоваться на машине дистрибутора и передать изменения, а для этого используется учетная запись, под которой работает агент. Под Local Account авторизоваться нигде не удастся, поэтому изменения никуда не пойдут.
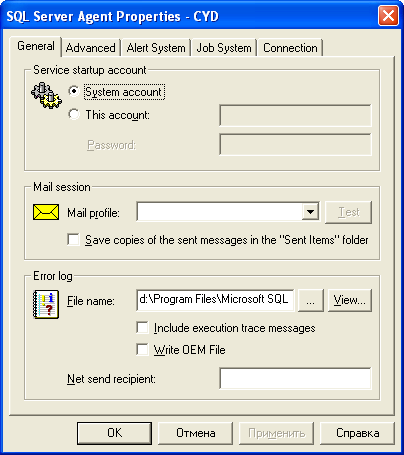
Настройка учетной записи MS SQL Server Agent
После этого вам предложат сконфигурировать самого агента вручную или автоматически. Если выбрать ручной режим, то количество шагов мастера резко возрастает, но они просты и с минимальными знаниями английского ты разберешься в них. Если выбрать автомат, то остается только указать мастеру требуемый тип репликации – снимок (Snapshot publication), транзакции (Transaction publication) или смешение (Merge publication) и указать необходимые таблицы. Да, в репликации участвует не вся база, а указанные таблицы. Системные таблицы реплицировать незачем.
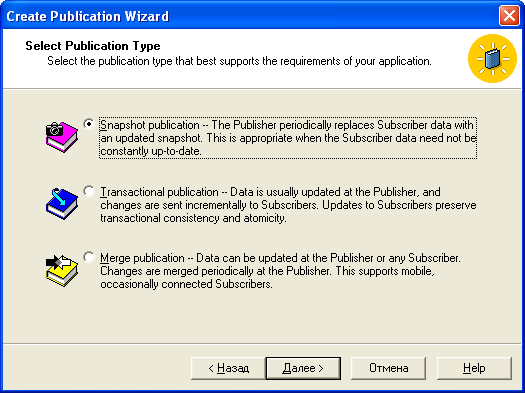
Выбор типа репликации
После создания издателя необходимо создать подписчика и настройку можно считать завершенной. Во время создания подписчика ты сможешь настроить план выполнения, указать дни, время или промежутки, через которые нужно выполнять репликацию.
Если ты настроил репликацию, и решил перенести базу данных на другой сервер, то можешь забыть про перенос через резервное копирование и восстановление. Дело в том, что в резервную копию не попадает информацию о репликации :(. Тут приходиться отключать базу Detach, копировать файлы на другой компьютер и подключать их заново Attach.
Золотой ключик
Следующая проблема, с которой ты можешь столкнуться – репликация ключевых полей. Если у тебя они имеют тип Guid, то никаких проблем тут не будет, но если Identity, то тебя ждут серьезные проблемы. Дело в том, что автоматически увеличиваемые поля не могут корректно реплицироваться с настройками по умолчанию, особенно при смешении, когда подписчик может изменять данные и должен уметь возвращать их издателю.
Допустим, что на двух компьютерах были созданы две разные записи с одинаковыми идентификаторами, что делать серверу? Какую из записей выбирать? По идее, в результирующую таблицу должно попасть обе записи, но изменять ID нельзя, особенно, если таблица связанная, а две записи с одинаковым ключом невозможны.
Проблема решается достаточно просто, нужно только выполнить следующие шаги:
- 1. Создаем копию базы данных издателя на компьютере подписчика.
- 2. Открываем окно редактирования таблицы или с помощью SQL запроса устанавливаем на издателе для ключа начальное значение 1, а для подписчика 1 000 000.
Все просто и красиво. Теперь, при добавлении записи на издателе новые записи будут нумероваться 1, 2, 3, 4. а на подписчике 1000001, 1000002, 1000003. Таким образом, записи пересекутся не скоро и конфликты могут никогда не появиться, особенно, если записи добавляются в таблицу не слишком интенсивно. Если же записи добавляются интенсивно, то откажись от автоувеличения и используй GUID поля в качестве ключа.
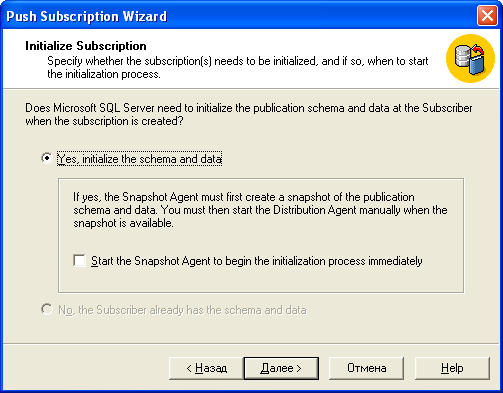
Запрос на копирование схемы
Но и это еще не все. При создании подписчика, тебе предложат перенести всю схему с издателя. Это удобно, если структура таблиц разная и их необходимо синхронизировать, но в нашем случае неприемлемо. Если ты поведешься на это предложение и ответишь Yes, то схема издателя будет скопирована подписчику и у обоих начальное значение ключа станет единицей, и все твои старания пойдут прахом, т.е. затрутся. Чтобы этого не произошло, жми No и наслаждайся, главное, чтобы на подписчике структура таблиц была такой же, как и у издателя.
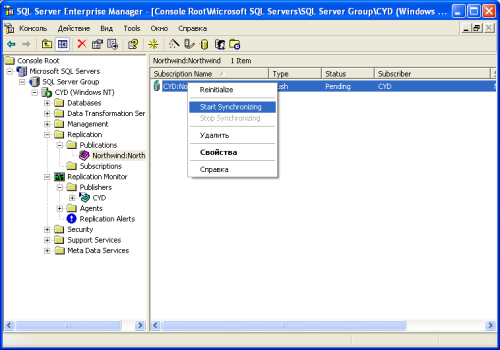
Ручной запуск репликации
Репликация Active Directory (AD)
Active Directory, которая активно используется серверами Windows – это тоже база данных. Она может быть распределенной, когда в работе участвуют несколько серверов, и при этом, пользователь должен иметь возможность войти на любой из них с одним и тем же паролем. Как это сделать? Зарегистрироваться на каждом сервере в отдельности? Глупо и бессмысленно. И тут на помощь приходит репликация. Достаточно зарегистрироваться на одном сервере и прописать необходимые права доступа и вся информация будет реплицирована куда надо.
Репликация в AD происходит автоматически и чаще всего не требует особого вмешательства, но требует хорошего понимания основной идеи. Если бы с Active Directory было бы все так просто, то я не рассматривал бы эту технологию отдельно. Для начала нужно понимать, что для аутентификации используется протокол Kerberos и ответственность за подлинность берет на себя контроллер домена. Когда ты заходишь на сервер, то имя и пароль направляются серверу, который проверяет эти данные и в случае удачи выдает белый билет. Нет, билет конечно не белый, но на его основе пользователь получает те или иные права. Если есть желание и нет знаний, то советую поближе познакомиться с Active Directory и Kerberos, а наша задача – репликация.
Если до Windows 2000 в сети мог быть только один контроллер домена, который хранил все самое важное и управлял репликацией (тогда не было и Kerberos), то в нынешних версиях может быть несколько контроллеров. При этом все они будут равноправными. Это усложняет задачу по управлению процессом репликацию и разрешению возможных конфликтов, но окна нашли простое решение. Контроллеры домена наблюдают друг за другом, определяя, какой из них в данный момент будет дистрибутором, т.е. одарит других изменениями.
Настраивать вручную соединения между контроллерами доменов в сети нет необходимости, хотя и есть такая возможность. Сервера сами через определенные промежутки времени отслеживают доступные контроллеры и хранят в памяти всю необходимую информацию.
По умолчанию, репликация происходит каждые пятнадцать минут. Через эти промежутки времени сервер направляет контроллерам домена сообщения о том, что есть изменения и конечно же становиться дистрибутором. Остальные участники репликации, получив подобное сообщение, подключаются к серверу и вытягивают данные. Сам дистрибутор без запроса свои изменения в сеть не выплюнет, чтобы злые хакеры не смогли перехватить подобный пакет. Просто нет смысла без надобности кидать в сеть такие важные данные, вдруг остальные контроллеры домена упали (пусть земля им будет пухом и прахом).
Конфликты в Active Directory
Благодаря тому, что репликация выполняется с задержкой, сервер реплицирует обновления пачками. Все изменения в Active Directory накапливаются и в определенный момент рассылаются всем контроллерам домена. Это хорошо, но за счет задержки возможны и проблемы. Допустим, что в определенный промежуток времени, одновременно произошло изменение на двух контроллерах домена. Чьи изменения будут реплицированы? Давай попробуем разобраться.
Все объекты Active Directory имеют версию, которая при создании получает значение единицы. После каждого редактирования объекта версия увеличивается, поэтому если приходит просьба реплицировать запись с меньшим номером версии, чем текущая, то такие изменения откатываются.
А что если серверу придет одновременно два предложения на репликацию от разных контроллеров, и при этом версии объектов будут одинаковыми, но сами объекты разными? Такое может случиться, когда один и тот же объект с идентичной версией изменяется на разных контроллерах. Оба контроллера увеличат версию, и она будет снова одинаковой. В этом случае побеждает тот сервер и соответствующее изменение, которое было сделано последним.
Самый крайний случай – когда версии одинаковы и даже время изменения идентично. Конечно, вероятность этого слишком мала, но она есть, поэтому разработчики Active Directory в данном случае предпочли выбирать то изменение, которое пришло с сервера с большим глобальным идентификатором GUID. Конечно, это глупый выбор и может оказаться далеко не точным, но он хоть как-то решает конфликт.
Каждый контроллер, получив изменения, пытается втулить их другим контроллерам вашей сети. Тут тоже есть проблема — представим, что у нас три контроллера домена. Редактируем объект на первом и он, конечно же, должен уведомить остальных об изменения. Они забрали эти изменения, но в этот момент второй контроллер пытается эти же изменения впихнуть нам обратно или на третий домен, который уже забрал изменения. Что делать в этом случае? Все очень просто – у нас же есть версия изменений и по ней можно узнать, нужно забирать запись, или она уже реплицирована.
Эта проблема частично решается и тем, что репликация может пройти не дальше трех контроллеров. Если сервер получил изменения третьим, то дальше он уже никому его передавать не будет. Передача репликации по цепочки происходит, только если контроллер получил новую версию объекта первым или вторым.
Репликация AD через 56к
Реплицировать данные каждые 15 минут удобно и приятно, но только если все контроллеры домена связаны между собой высокоскоростным соединением. А что если два контроллера находятся в другом районе или деревне, где они могут быть подключены к общей сети только по DialUp? В этом случае, трафик репликации может отнять слишком много ресурсов, и полосы пропускания не хватит на решение других задач.
Чтобы этого избежать, можно и даже нужно разделить эти сервера на сайты. Все контроллеры, подключенные по высокоскоростной связи поместить в один сайт, а два удаленных в другой сайт. Внутри сайтов репликация может происходить по правилам, установленным по умолчанию, а вот между сайтами, можно настроить обмен так, чтобы не перегрузить полосу и оставить ее для передачи более важных данных. Такое разделение ты без проблем можешь настроить с помощью оснастки AD Sites and Services.
В качестве возможных вариантов сохранения трафика, в technet от MS предлагаются варианты:
- репликации данных по ночам;
- репликации в обеденные перерывы;
- репликации с большими промежутками времени.
Мне импонируют первые два варианта, особенно, если сайты находятся в одной временной зоне. Но если один расположен в Москве, а другой на Чукотке, то ты не то, что в обеденный перерыв не сможешь попасть, когда в Москве день, в Петропавловске уже полночь.
Еще о репликации Active Directory (AD)
Если хочешь узнать больше о репликации в Acive Directory, и нет проблем с английским, то рекомендую скачать следующий документ: www.certmag.com/bookshelf/C0617953.pdf. Это 92 страницы полезного и халявного чтива. Если и этого мало, то бегом на technet от Microsoft. Там информация изложена не так удобно и последовательно, но очень много хороших рекомендаций.
По Active Directory и репликации в частности могу посоветовать сайт only4gurus.com и конкретно ссылочка — http://www.only4gurus.com/v3/sitemap_active_directory.shtml. По репликации здесь можно найти хорошие презентации, рисунки которой были взяты за основу к данной статье. Я лишь перевел эти рисунки на мой родной русский и немного подкорректировал, чтобы они были нагляднее.
Итого
Я надеюсь, что я смог тебя убедить, что репликация – это не просто синхронизация, а более продвинутый и интеллектуальный шаг вперед. При правильном подходе, этот шаг будет большим. Если ты хорошо разберешься с этой темой, то без проблем сможешь даже сделать ручную репликацию так, где ее нет изначально. Ведь не во всех базах данных реализована такая возможность.
За кадром данной статьи осталась очень интересная тема – репликация Exchange сервера. У нее очень много похожего на Active Directory и SQL Server, но есть и интересные нюансы.
Поделитесь с друзьями
Внимание. Если ты копируешь эту статью себе на сайт, то оставляй ссылку непосредственно на эту страницу. Спасибо за понимание
Репликация данных

Репликация — одна из техник масштабирования баз данных. Состоит эта техника в том, что данные с одного сервера базы данных постоянно копируются (реплицируются) на один или несколько других (называемые репликами). Для приложения появляется возможность использовать не один сервер для обработки всех запросов, а несколько. Таким образом появляется возможность распределить нагрузку с одного сервера на несколько.
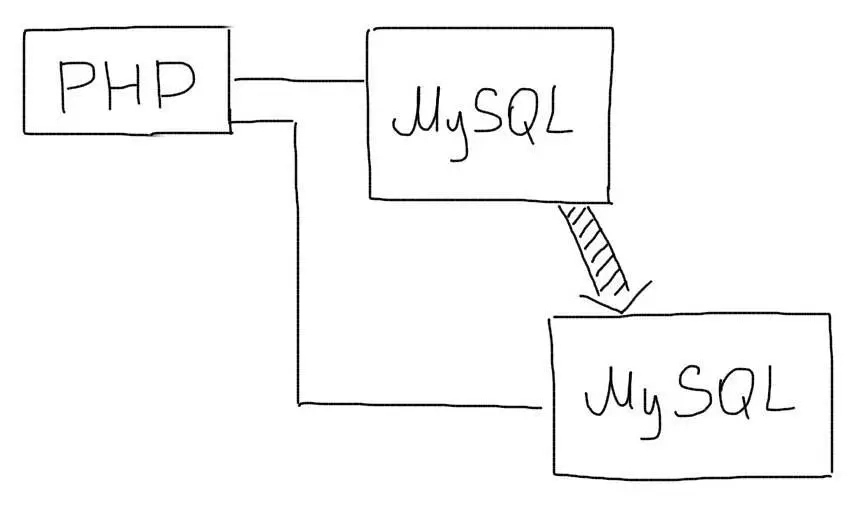
Существует два основных подхода при работе с репликацией данных:
- Репликация Master-Slave;
- Репликация Master-Master.
Master-Slave репликация
В этом подходе выделяется один основной сервер базы данных, который называется Мастером. На нем происходят все изменения в данных (любые запросы MySQL INSERT/UPDATE/DELETE). Слейв сервер постоянно копирует все изменения с Мастера. С приложения на Слейв сервер отправляются запросы чтения данных (запросы SELECT). Таким образом Мастер сервер отвечает за изменения данных, а Слейв за чтение.
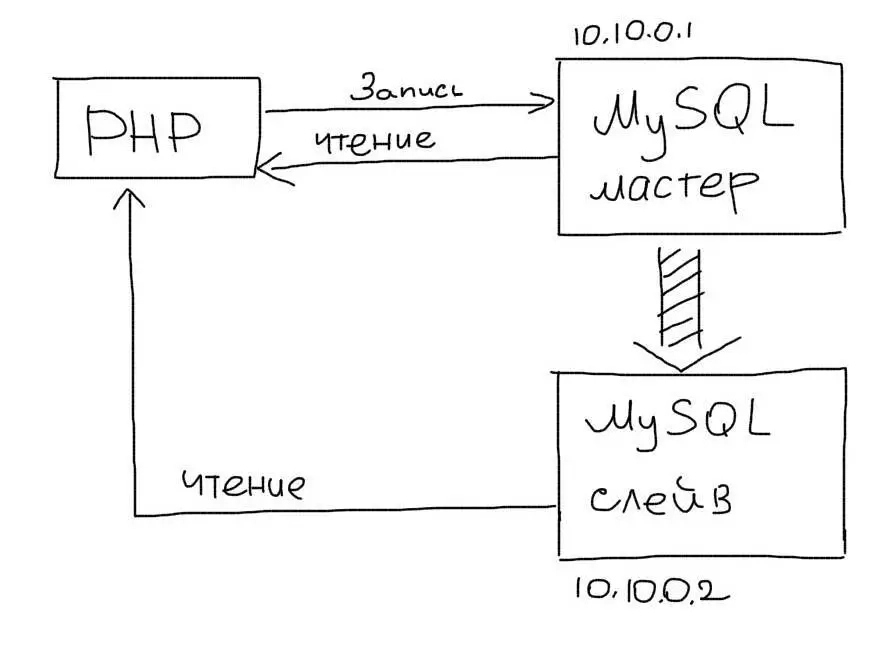
В приложении нужно использовать два соединения – одно для Мастера, второе — для Слейва:
Используем два соединения — для Мастера и Слейва — для записи и чтения соответственно
Несколько Слейвов
Преимущество этого типа репликации в том, что Вы можете использовать более одного Слейва. Обычно следует использовать не более 20 Слейв серверов при работе с одним Мастером.
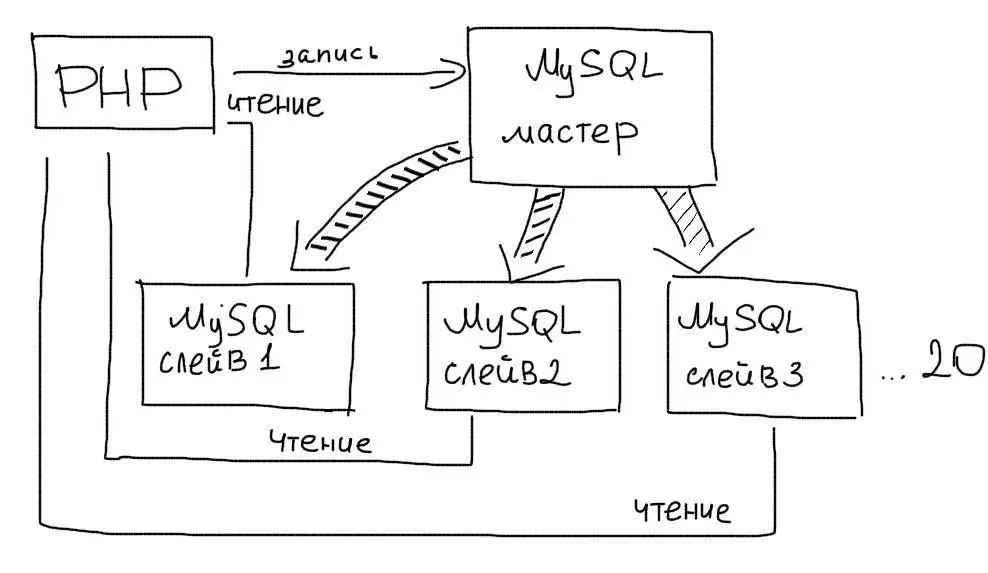
Тогда из приложения Вы выбираете случайным образом один из Слейвов для обработки запросов:
Асинхронность репликации означает, что данные на Слейве могут появится с небольшой задержкой. Поэтому, в последовательных операциях необходимо использовать чтение с Мастера, чтобы получить актуальные данные:
При обращении к изменяемым данным, необходимо использовать Мастер-соединение
Выход из строя
При выходе из строя Слейва, достаточно просто переключить все приложение на работу с Мастером. После этого восстановить репликацию на Слейве и снова его запустить.
Если выходит из строя Мастер, нужно переключить все операции (и чтения и записи) на Слейв. Таким образом он станет новым Мастером. После восстановления старого Мастера, настроить на нем реплику, и он станет новым Слейвом.
Резервирование
Намного чаще репликацию Master-Slave используют не для масштабирования, а для резервирования. В этом случае, Мастер сервер обрабатывает все запросы от приложения. Слейв сервер работает в пассивном режиме. Но в случае выхода из строя Мастера, все операции переключаются на Слейв.
Master-Master репликация
В этой схеме, любой из серверов может использоваться как для чтения так и для записи: 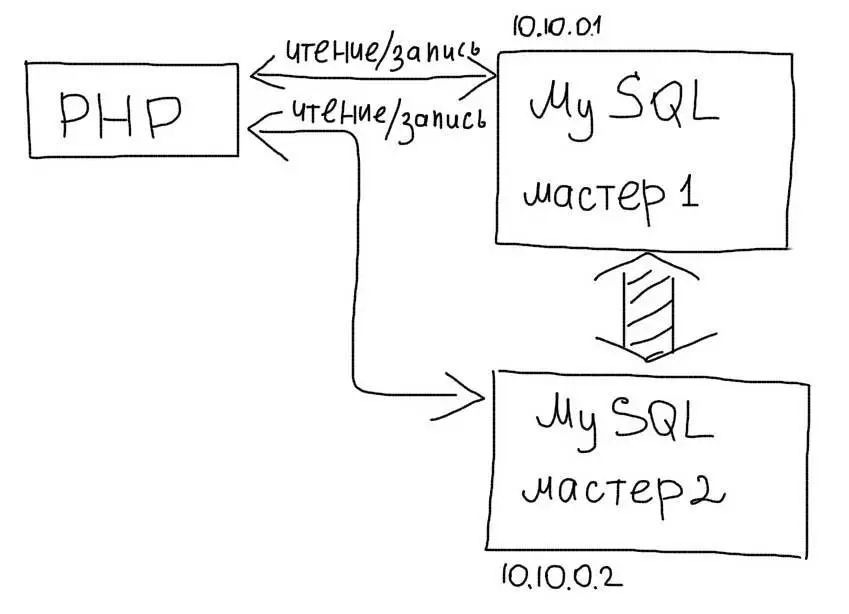
При использовании такого типа репликации достаточно выбирать случайное соединение из доступных Мастеров:
Выбор случайного Мастера для обработки соединений
Выход из строя
Вероятные поломки делают Master-Master репликацию непривлекательной. Выход из строя одного из серверов практически всегда приводит к потере каких-то данных. Последующее восстановление также сильно затрудняется необходимостью ручного анализа данных, которые успели либо не успели скопироваться.
Используйте Master-Master репликацию только в крайнем случае. Вместо нее лучше пользоваться техникой “ручной” репликации, описанной ниже.
Асинхронность репликации
В MySQL репликация работает в асинхронном режиме. Это значит, что приложение не знает, как быстро данные появятся на Слейве. 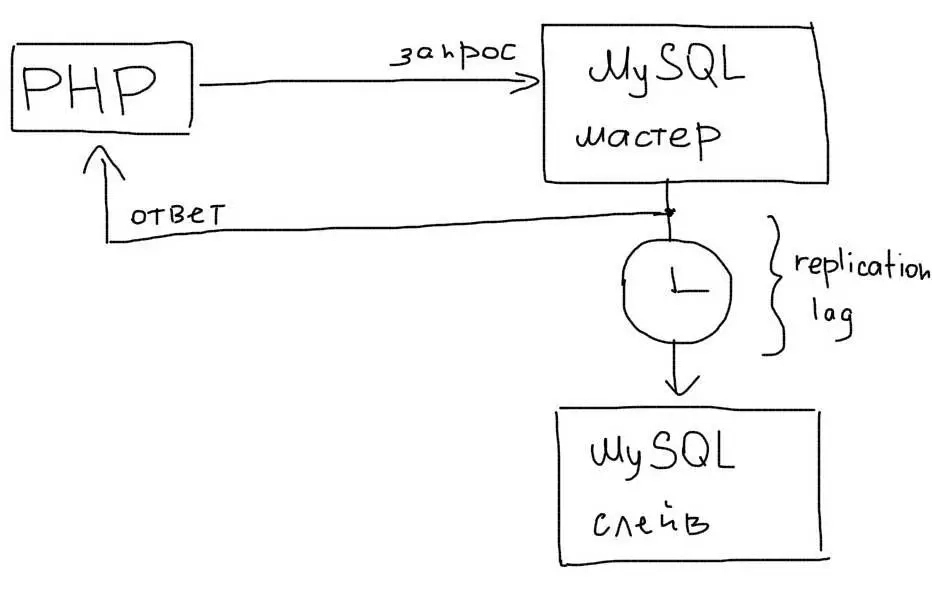
Задержка в репликации (replication lag) может быть как очень маленькой, так и очень большой. Обычно рост задержки говорит о том, что сервера не справляются с текущей нагрузкой и их необходимо масштабировать дальше, например техниками горизонтального и вертикального шардинга.
Синхронный режим
Синхронный режим репликации позволит гарантировать копирование данных на Слейв. 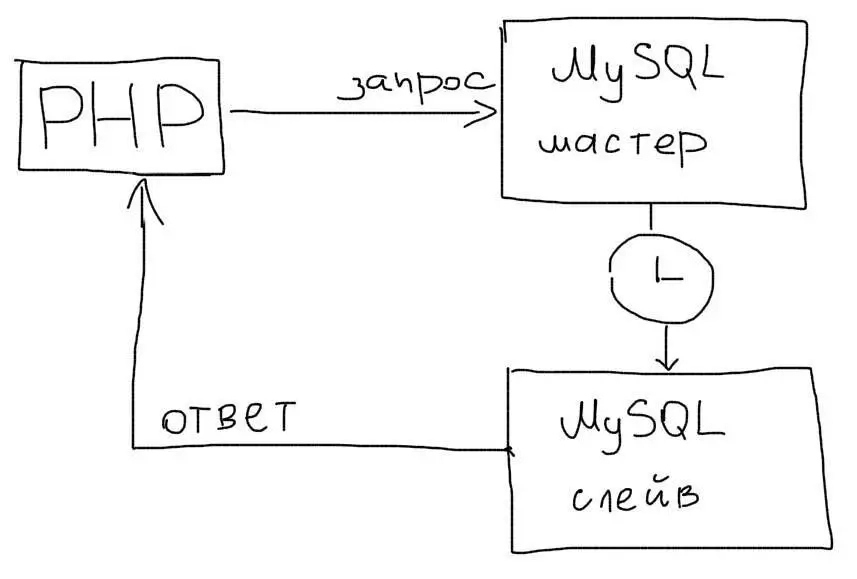
Это упростит работу в приложении, т.к. все операции чтения можно будет всегда отправлять на Слейв. Однако это может значительно уменьшить скорость работы MySQL. Синхронный режим не следует использовать в Web приложениях.
“Ручная” репликация
Следует помнить, что репликация — это не технология, а методика. Встроенные механизмы репликации могут принести ненужные усложнения либо не иметь какой-то нужной функции. Некоторые технологии вообще не имеют встроенной репликации.
В таких случаях, следует использовать самостоятельную реализацию репликации. В самом простом случае, приложение будет дублировать все запросы сразу на несколько серверов базы данных: 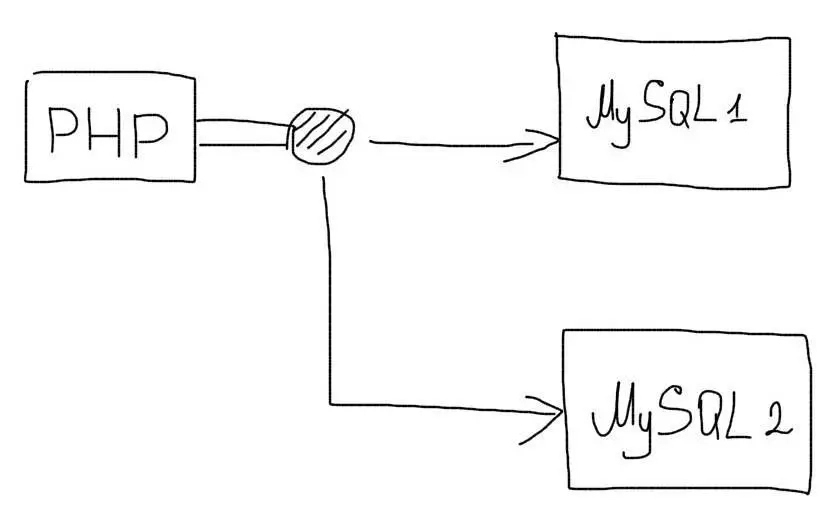
При записи данных, все запросы будут отправляться на несколько серверов. Зато операции чтения можно будет отправлять на любой сервер. Нагрузка при этом будет распределяться по всем доступным серверам:
Все операции изменения данных происходят на нескольких серверах, а чтения — на одном случайном
Это позволит использовать преимущества репликации даже если сама технология ее не поддерживает.
Выход из строя
При поломке одного из серверов в такой схеме необходимо сделать следующее:
- Исключить сервер из списка используемых.
- Настроить репликацию Master-Slave на новом сервере, используя один из рабочих серверов в качестве Мастера.
- Когда все данные репликации будут синхронизированы, включить сервер обратно в список используемых и остановить репликацию.
Самое важное
Репликация используется в большей мере для резервирования баз данных и в меньшей для масштабирования. Master-Slave репликация удобна для распределения запросов чтения по нескольким серверам. Подход ручной репликации позволит использовать преимущества репликации для технологий, которые ее не поддерживают. Зачастую репликация используется вместе с шардингом при решении вопросов масштабирования.
Этот текст был написан несколько лет назад. С тех пор упомянутые здесь инструменты и софт могли получить обновления. Пожалуйста, проверяйте их актуальность.
Путеводитель по репликации баз данных
Повторяться, но каждый раз по-новому – разве не это есть искусство?
Станислав Ежи Лец, из книги «Непричёсанные мысли»
Словарь определяет репликацию как процесс поддержания двух (или более) наборов данных в согласованном состоянии. Что такое «согласованное состояние наборов данных» – отдельный большой вопрос, поэтому переформулируем определение проще: процесс изменения одного набора данных, называемого репликой, в ответ на изменения другого набора данных, называемого основным. Совсем не обязательно наборы при этом будут одинаковыми.

Поддержка репликации баз данных – одна из важнейших задач администратора: почти у каждой сколько-нибудь важной базы данных есть реплика, а то и не одна.
Среди задач, решаемых репликацией, можно назвать как минимум
- поддержку резервной базы данных на случай потери основной;
- снижение нагрузки на базу за счёт переноса части запросов на реплики;
- перенос данных в архивные или аналитические системы.
- Блочная репликация на уровне системы хранения данных;
- Физическая репликация на уровне СУБД;
- Логическая репликация на уровне СУБД.
Блочная репликация
При блочной репликации каждая операция записи выполняется не только на основном диске, но и на резервном. Таким образом тому на одном массиве соответствует зеркальный том на другом массиве, с точностью до байта повторяющий основной том:
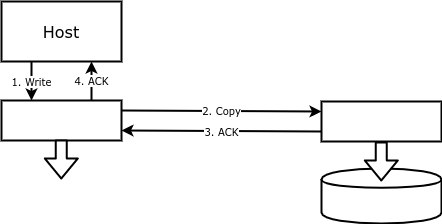
К достоинствам такой репликации можно отнести простоту настройки и надёжность. Записывать данные на удалённый диск может либо дисковый массив, либо нечто (устройство или программное обеспечение), стоящее между хостом и диском.
Дисковые массивы могут быть дополнены опциями, позволяющими включить репликацию. Название опции зависит от производителя массива:
| Производитель | Торговая марка |
|---|---|
| EMC | SRDF (Symmetrix Remote Data Facility) |
| IBM | Metro Mirror – синхронная репликация Global Mirror – асинхронная репликация |
| Hitachi | TrueCopy |
| Hewlett-Packard | Continuous Access |
| Huawei | HyperReplication |
Если дисковый массив не способен реплицировать данные, между хостом и массивом может быть установлен агент, осуществляющей запись на два массива сразу. Агент может быть как отдельным устройством (EMC VPLEX), так и программным компонентом (HPE PeerPersistence, Windows Server Storage Replica, DRBD). В отличие от дискового массива, который может работать только с таким же массивом или, как минимум, с массивом того же производителя, агент может работать с совершенно разными дисковыми устройствами.
Главное назначение блочной репликации – обеспечение отказоустойчивости. Если база данных потеряна, то можно перезапустить её с использованием зеркального тома.
Блочная репликация хороша своей универсальностью, но за универсальность приходится платить.
Во-первых, никакой сервер не может работать с зеркальным томом, поскольку его операционная система не может управлять записью на него; с точки зрения наблюдателя данные на зеркальном томе появляются сами собой. В случае аварии (отказ основного сервера или всего ЦОДа, где находится основной сервер) следует остановить репликацию, размонтировать основной том и смонтировать зеркальный том. Как только появится возможность, следует перезапустить репликацию в обратном направлении.
В случае использования агента все эти действия выполнит агент, что упрощает настройку, но не уменьшает время переключения.
Во-вторых, сама СУБД на резервном сервере может быть запущена только после монтирования диска. В некоторых операционных системах, например, в Solaris, память под кеш при выделении размечается, и время разметки пропорционально объёму выделяемой памяти, то есть старт экземпляра будет отнюдь не мгновенным. Плюс ко всему кеш после рестарта будет пуст.
В-третьих, после запуска на резервном сервере СУБД обнаружит, что данные на диске неконсистентны, и нужно потратить значительное время на восстановление с применением журналов повторного выполнения: сначала повторить те транзакции, результаты которых сохранились в журнале, но не успели сохраниться в файлы данных, а потом откатить транзакции, которые к моменту сбоя не успели завершиться.
Блочная репликация не может использоваться для распределения нагрузки, а для обновления хранилища данных используется похожая схема, когда зеркальный том находится в том же массиве, что и основной. У EMC и HP эта схема называется BCV, только EMC расшифровывает аббревиатуру как Business Continuance Volume, а HP – как Business Copy Volume. У IBM на этот случай нет специальной торговой марки, эта схема так и называется – «mirrored volume».

В массиве создаются два тома, и операции записи синхронно выполняются на обоих (A). В определённое время зеркало разрывается (B), то есть тома становятся независимыми. Зеркальный том монтируется к серверу, выделенному для обновления хранилища, и на этом сервере поднимается экземпляр базы данных. Экземпляр будет подниматься так же долго, как и при восстановлении с помощью блочной репликации, но это время может быть существенно уменьшено за счёт разрыва зеркала в период минимальной нагрузки. Дело в том, что разрыв зеркала по своим последствиям эквивалентен аварийному завершению СУБД, а время восстановление при аварийном завершении существенно зависит от количества активных транзакций в момент аварии. База данных, предназначенная для выгрузки, доступна как на чтение, так и на запись. Идентификаторы всех блоков, изменённых после разрыва зеркала как на основном, так и на зеркальном томе, сохраняются в специальной области Block Change Tracking – BCT.
После окончания выгрузки зеркальный том размонтируется (С), зеркало восстанавливается, и через некоторое время зеркальный том вновь догоняет основной и становится его копией.
Физическая репликация
Журналы (redo log или write-ahead log) содержат все изменения, которые вносятся в файлы базы данных. Идея физической репликации состоит в том, что изменения из журналов повторно выполняются в другой базе (реплике), и таким образом данные в реплике повторяют данные в основной базе байт-в-байт.
Возможность использовать журналы базы данных для обновления реплики появилась в релизе Oracle 7.3, который вышел в 1996 году, а уже в релизе Oracle 8i доставка журналов с основной базы в реплику была автоматизирована и получила название DataGuard. Технология оказалась настолько востребованной, что сегодня механизм физической репликации есть практически во всех современных СУБД.
| СУБД | Опция репликации |
|---|---|
| Oracle | Active DataGuard |
| IBM DB2 | HADR |
| Microsoft SQL Server | Log shipping/Always On |
| PostgreSQL | Log shipping/Streaming replication |
| MySQL | Alibaba physical InnoDB replication |
Опыт показывает, что если использовать сервер только для поддержания реплики в актуальном состоянии, то ему достаточно примерно 10% процессорной мощности сервера, на котором работает основная база.
Журналы СУБД не предназначены для использования вне этой платформы, их формат не документируется и может меняться без предупреждения. Отсюда совершенно естественное требование, что физическая репликация возможна только между экземплярами одной и той же версии одной той же СУБД. Отсюда же возможные ограничения на операционную систему и архитектуру процессора, которые тоже могут влиять на формат журнала.
Естественно, никаких ограничений на модели СХД физическая репликация не накладывает. Более того, файлы в базе-реплике могут располагаться совсем по-другому, чем на базе-источнике – надо лишь описать соответствие между томами, на которых лежат эти файлы.
Oracle DataGuard позволяет удалить часть файлов из базы-реплики – в этом случае изменения в журналах, относящиеся к этим файлам, будут проигнорированы.
Физическая репликация базы данных имеет множество преимуществ перед репликацией средствами СХД:
- объём передаваемых данных меньше за счёт того, что передаются только журналы, но не файлы с данными; эксперименты показывают уменьшение трафика в 5-7 раз;
- переключение на резервную базу происходит значительно быстрее: экземпляр-реплика уже поднят, поэтому при переключении ему нужно лишь откатить активные транзакции; более того, к моменту сбоя кеш реплики уже прогрет;
- на реплике можно выполнять запросы, сняв тем самым часть нагрузки с основной базы. В частности, реплику можно использовать для создания резервных копий.
Запись данных в реплику невозможна, поскольку изменения в неё приходят побайтно, и реплика не может обеспечить конкурентное исполнение своих запросов. Oracle Active DataGuard в последних релизах разрешает запись в реплику, но это не более чем «сахар»: на самом деле изменения выполняются на основной базе, а клиент ждёт, пока они докатятся до реплики.
В случае повреждения файла в основной базе можно просто скопировать соответствующий файл с реплики (прежде, чем делать такое со своей базой, внимательно изучите руководство администратора!). Файл на реплике может быть не идентичен файлу в основной базе: дело в том, что когда файл расширяется, новые блоки в целях ускорения ничем не заполняются, и их содержимое случайно. База может использовать не всё пространство блока (например, в блоке может оставаться свободное место), но содержимое использованного пространства совпадает с точностью до байта.
Физическая репликация может быть как синхронной, так и асинхронной. При асинхронной репликации всегда есть некий набор транзакций, которые завершены на основной базе, но ещё не дошли до резервной, и в случае перехода на резервную базу при сбое основной эти транзакции будут потеряны. При синхронной репликации завершение операции commit означает, что все журнальные записи, относящиеся к данной транзакции, переданы на реплику. Важно понимать, что получение репликой журнала не означает применения изменений к данным. При потере основной базы транзакции не будут потеряны, но если приложение пишет данные в основную базу и считывает их из реплики, то у него есть шанс получить старую версию этих данных.
В PostgreSQL есть возможность сконфигурировать репликацию так, чтобы commit завершался только после применения изменений к данным реплики (опция synchronous_commit = remote_apply ), а в Oracle можно сконфигурировать всю реплику или отдельные сессии, чтобы запросы выполнялись только если реплика не отстаёт от основной базы ( STANDBY_MAX_DATA_DELAY=0 ). Однако всё же лучше проектировать приложение так, чтобы запись в основную базу и чтение из реплик выполнялись в разных модулях.
При поиске ответа на вопрос, какой режим выбрать, синхронный или асинхронный, нам на помощь приходят маркетологи Oracle. DataGuard предусматривает три режима, каждый из которых максимизирует один из параметров – сохранность данных, производительность, доступность – за счёт остальных:
- Maximum performance: репликация всегда асинхронная;
- Maximum protection: репликация синхронная; если реплика не отвечает, commit на основной базе не завершается;
- Maximum availability: репликация синхронная; если реплика не отвечает, то репликация переключается в асинхронный режим и, как только связь восстанавливается, реплика догоняет основную базу и репликация снова становится синхронной.
Во-первых, в случае репликации средствами дискового массива трафик идёт не по сети передачи данных (LAN), а по сети хранения данных (Storage Area Network). Зачастую в инфраструктурах, построенных давно, SAN гораздо надёжнее и производительнее, чем сеть передачи данных.
Во-вторых, синхронная репликация средствами СУБД стала надёжной относительно недавно. В Oracle прорыв произошёл в релизе 11g, который вышел в 2007 году, а в других СУБД синхронная репликация появилась ещё позже. Конечно, 10 лет по меркам сферы информационных технологий – срок не такой уж маленький, но когда речь идёт о сохранности данных, некоторые администраторы до сих пор руководствуются принципом «как бы чего не вышло»…
Логическая репликация
Все изменения в базе данных происходят в результате вызовов её API – например, в результате выполнения SQL-запросов. Очень заманчивой кажется идея выполнять одну и ту же последовательность запросов на двух разных базах. Для репликации необходимо придерживаться двух правил:
- Нельзя начинать транзакцию, пока не завершены все транзакции, которые должны закончиться раньше. Так на рисунке ниже нельзя запускать транзакцию D, пока не завершены транзакции A и B.
- Нельзя завершать транзакцию, пока не начаты все транзакции, которые должны закончиться до завершения текущей транзакции. Так на рисунке ниже даже если транзакция B выполнилась мгновенно, завершить её можно только после того, как начнётся транзакция C.
Во-первых, не все API детерминированы. Например, если в SQL-запросе встречается функция now() или sysdate(), возвращающая текущее время, то на разных серверах она вернёт разный результат – из-за того, что запросы выполняются не одновременно. Кроме того, к различиям могут привести разные состояния триггеров и хранимых функций, разные национальные настройки, влияющие на порядок сортировки, и многое другое.
Во-вторых, репликацию, основанную на параллельном исполнении команд, невозможно корректно приостановить и перезапустить.
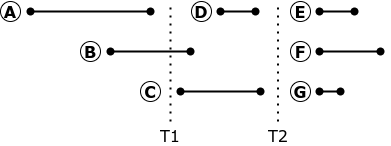
Если репликация остановлена в момент T1 транзакция B должна быть прервана и откачена. При перезапуске репликации исполнение транзакции B может привести реплику к состоянию, отличному от состояния базы-источника: на источнике транзакция B началась до того, как закончилась транзакция A, а значит, она не видела изменений, сделанных транзакцией A.
Репликация запросов может быть остановлена и перезапущена только в момент T2, когда в базе нет ни одной активной транзакции. Разумеется, на сколько-нибудь нагруженной промышленной базе таких моментов не бывает.
Обычно для логической репликации используют детерминированные запросы. Детерминированность запроса обеспечивается двумя свойствами:
- запрос обновляет (или вставляет, или удаляет) единственную запись, идентифицируя её по первичному (или уникальному) ключу;
- все параметры запроса явно заданы в самом запросе.
Предположим, что у нас есть таблица сотрудников со следующими данными:
| ID | Name | Dept | Salary |
|---|---|---|---|
| 3817 | Иванов Иван Иванович | 36 | 1800 |
| 2274 | Петров Пётр Петрович | 36 | 1600 |
| 4415 | Кузнецов Семён Андреевич | 41 | 2100 |
Над этой таблицей была выполнена следующая операция:
Для того, чтобы корректно реплицировать данные, в реплике будут выполнены такие запросы:
Запросы приводят к тому же результату, что и на исходной базе, но при этом не эквивалентны выполненным запросам.
База-реплика открыта и доступна не только на чтение, но и на запись. Это позволяет использовать реплику для выполнения части запросов, в том числе для построения отчётов, требующих создания дополнительных таблиц или индексов.
Важно понимать, что логическая реплика будет эквивалентна исходной базе только в том случае, если в неё не вносится никаких дополнительных изменений. Например, если в примере выше в реплике добавить в 36 отдел Сидорова, то он повышения не получит, а если Иванова перевести из 36 отдела, то он получит повышение, несмотря ни на что.
Логическая репликация предоставляет ряд возможностей, отсутствующих в других видах репликации:
- настройка набора реплицируемых данных на уровне таблиц (при физической репликации – на уровне файлов и табличных пространств, при блочной репликации – на уровне томов);
- построение сложных топологий репликации – например, консолидация нескольких баз в одной или двунаправленная репликация;
- уменьшение объёма передаваемых данных;
- репликация между разными версиями СУБД или даже между СУБД разных производителей;
- обработка данных при репликации, в том числе изменение структуры, обогащение, сохранение истории.
- все реплицируемые данные обязаны иметь первичные ключи;
- логическая репликация поддерживает не все типы данных – например, возможны проблемы с BLOB’ами.
- логическая репликация на практике не бывает полностью синхронной: время от получения изменений до их применения слишком велико, чтобы основная база могла ждать;
- логическая репликация создаёт большую нагрузку на реплику;
- при переключении приложение должно иметь возможность убедиться, что все изменения с основной базы, применены на реплике – СУБД зачастую сама не может этого определить, так как для неё режимы реплики и основной базы эквивалентны.
Есть несколько способов реализации логической репликации, и каждый из этих способов реализует одну часть возможностей и не реализует другую:
- репликация триггерами;
- использование журналов СУБД;
- использование программного обеспечения класса CDC (change data capture);
- прикладная репликация.
Репликация триггерами
Триггер – хранимая процедура, которая исполняется автоматически при каком-либо действии по модификации данных. Триггеру, который вызывается при изменении каждой записи, доступны ключ этой записи, а также старые и новые значения полей. При необходимости триггер может сохранять новые значения строк в специальную таблицу, откуда специальный процесс на стороне реплики будет их вычитывать. Объём кода в триггерах велик, поэтому существуют специальное программное обеспечение, генерирующее такие триггеры, например, «Репликация слиянием» (merge replication) – компонент Microsoft SQL Server или Slony-I – отдельный продукт для репликации PostgreSQL.
Сильные стороны репликации триггерами:
- независимость от версий основной базы и реплики;
- широкие возможности преобразования данных.
- нагрузка на основную базу;
- большая задержка при репликации.
Использование журналов СУБД
Сами СУБД также могут предоставлять возможности логической репликации. Источником данных, как и для физической репликации, являются журналы. К информации о побайтовом изменении добавляется также информация об изменённых полях (supplemental logging в Oracle, wal_level = logical в PostgreSQL), а также значение уникального ключа, даже если он не меняется. В результате объём журналов БД увеличивается – по разным оценкам от 10 до 15%.
Возможности репликации зависят от реализации в конкретной СУБД – если в Oracle можно построить logical standby, то в PostgreSQL или Microsoft SQL Server встроенными средствами платформы можно развернуть сложную систему взаимных подписок и публикаций. Кроме того, СУБД предоставляет встроенные средства мониторинга и управления репликацией.
К недостаткам данного подхода можно отнести увеличение объёма журналов и возможное увеличение трафика между узлами.
Использование CDC
Существует целый класс программного обеспечения, предназначенного для организации логической репликации. Это ПО называется CDC, change data capture. Вот список наиболее известных платформ этого класса:
- Oracle GoldenGate (компания GoldenGate приобретена в 2009 году);
- IBM InfoSphere Data Replication (ранее – InfoSphere CDC; ещё ранее – DataMirror Transformation Server, компания DataMirror приобретена в 2007 году);
- VisionSolutions DoubleTake/MIMIX (ранее – Vision Replicate1);
- Qlik Data Integration Platform (ранее – Attunity);
- Informatica PowerExchange CDC;
- Debezium;
- StreamSets Data Collector.
- возможность репликации между разными СУБД, в том числе загрузка данных в отчётные системы;
- широчайшие возможности обработки и преобразования данных;
- минимальный трафик между узлами – платформа отсекает ненужные данные и может сжимать трафик;
- встроенные возможности мониторинга состояния репликации.
- увеличение объёма журналов, как при логической репликации средствами СУБД;
- новое ПО – сложное в настройке и/или с дорогими лицензиями.
Прикладная репликация
Наконец, ещё один способ репликации – формирование векторов изменений непосредственно на стороне клиента. Клиент должен формировать детерминированные запросы, затрагивающие единственную запись. Добиться этого можно, используя специальную библиотеку работы с базой данных, например, Borland Database Engine (BDE) или Hibernate ORM.
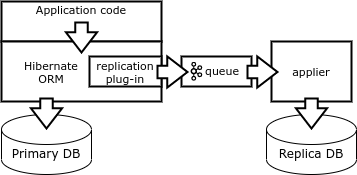
Когда приложение завершает транзакцию, подключаемый модуль Hibernate ORM записывает вектор изменений в очередь и выполняет транзакцию в базе данных. Специальный процесс-репликатор вычитывает векторы из очереди и выполняет транзакции в базе-реплике.
Этот механизм хорош для обновления отчётных систем. Может он использоваться и для обеспечения отказоустойчивости, но в этом случае в приложении должен быть реализован контроль состояния репликации.
Традиционно – сильные и слабые стороны данного подхода:
- возможность репликации между разными СУБД, в том числе загрузка данных в отчётные системы;
- возможность обработки и преобразования данных, мониторинга состояния и т. д.;
- минимальный трафик между узлами – платформа отсекает ненужные данные и может сжимать трафик;
- полная независимость от базы данных – как от формата, так и от внутренних механизмов.
- ограничения на архитектуру приложения;
- огромный объём собственного кода, обеспечивающего репликацию.
Так что же лучше?
Однозначного ответа на этот вопрос, как и на многие другие, не существует. Но надеюсь, что таблица ниже поможет сделать правильный выбор для каждой конкретной задачи: