Что такое системная нагрузка?
В моем задании у нас есть репозиторий данных под управлением Ubuntu 12.04.03 CLI и поскольку я проверял их этим утром, когда я вошел в систему вместо того, чтобы дать мне нормальную информацию, это сказало, что информация не могла быть отображена, потому что системная нагрузка выше 2, и я задавался вопросом, что это означало? Я только что перезапустил его, потому что это был unresponive, это имеет некоторое отношение к процессу запуска и получения всего движение?
5 ответов
Работайте top или uptime команды:
средние числа загрузки указали , вот :
Рассматривают мои средние числа загрузки: 0.05, 0.16, 0.21
, Который означает, по последней минуте, в среднем, 0,05 процесса ожидали ресурсов.
Вы должны волноваться, что среднее число загрузки равняется 2? В целом, если среднее число загрузки больше, чем количество доступных центральных процессоров, то некоторый процесс должен был бездействовать вокруг ожидания слота ЦП.
, Если среднее число загрузки является меньше, чем вывод nproc , Вы не должны волноваться.
Системная нагрузка или среднее число системной нагрузки
Это — очередь выполнения т.е. очередь процессов, ожидающих ресурса (CPU, i/o и т.д.) для становления доступным.
Рассмотрите одножильное cpu как однополосный из трафика с мостом и процесса как автомобили.
Теперь в этой ситуации Системная нагрузка
- 0.0 — Если нет никакого трафика на дороге.
- 1.0 — Если трафик на дороге является точно способностью моста.
- Больше чем 1 — Если трафик на дороге выше, чем способность моста и автомобилей, должен ожидать для передачи канавки мост.
Это число не нормализовано согласно Вашему cpu . В Многопроцессорной системе загрузка 2 средних 100%-х использования мы используем двухъядерный процессор, загружаем 4 использования 100% средств, если мы используем четырехъядерный.
Можно получить использование системной нагрузки
- uptime
- cat /proc/loadavg
$uptime 22:49:47 11:47, 4 пользователя, загружают среднее число: 2.20, 1.03, 0.82
Здесь последние три числа, представляющие среднее число системной нагрузки для 1, 5 и 15 минут соответственно.
Пример выше указывает, что в среднем было 2,20 процесса, ожидающие, чтобы быть запланированными на очередь выполнения, измеряемую по последней минуте.
Системная нагрузка относится к количеству ядер процессора для exampleif, у Вас есть Квадратические Ядра процессора (4 Ядра) значение 1 средство, что системная нагрузка находится на 25%, и 4 средства 100%.
Если Вы введете во время работы терминала , то Вы будете видеть что-то как: среднее число загрузки и три столбца цифр, которые являются загрузками от один, пять и пятнадцать минут. Если у Вас есть двухъядерное использование 100% средств процессора 2, 1 средство 50% и т.д.
Системная нагрузка 2,0 не очень высока. В многоядерной системе Ваш ЦП может все еще даже быть частично неактивным.
среднее число загрузки А является мерой того, насколько перегруженный ядро процессора с точки зрения количества процессов, желающих использовать его сразу.
следующее принимают одноядерное (единственный поток) ЦП:
0.0
ЦП не делает ничего вообще. Если бы процесс должен был начать использовать ЦП затем, то это было бы единственное с помощью него.
1.0
ЦП при максимальном использовании, но существует нулевая конкуренция между процессами для использования ЦП. Таким образом, только единственный процесс работает так, он может требовать 100% процессорного времени для себя. С другой стороны, несколько процессов работают, но ни один не требует 100% ЦП, и их объединенное использование ЦП составляет в целом 100%. Они все все еще работают с такой скоростью, как они работали бы, даже если бы у них был ЦП полностью себе.
Больше, чем 1,0
ЦП при максимальном использовании, и существует несколько процессов, желающих использовать его одновременно, таким образом, они работают более медленно, чем они иначе смогли бы работать, если бы у них было эксклюзивное использование ЦП. Например, среднее число загрузки 3,0 указывает, что процессы выполняют на одной трети скорость, которую они хотят выполнить. Среднее число загрузки 50,0 указывает, что процессы выполняют в 1/50 скорость, которую они хотят выполнить, из-за всех других процессов выполнение. Таким образом, фигурирует выше, чем 1,0, указывают, что доступный ЦП делится между все более активными процессами.
Наличие нескольких ядро процессора не изменяет то, что числа имеют в виду только изменения, как они должны быть интерпретированы. Например, если у Вас есть 4 ядра процессора, затем загрузка 1,0 все еще эквивалентна одному процессу с помощью 100% ЦП на одном ядре, но существует три других ядра. Таким образом на 4 ядрах процессора, точка максимальной производительности 4.0, не 1.0 — и точка, в которой все работает в 1/3 эффективности, 12.0, не 3.0. Для добавления к сложности единственный процесс может иметь больше чем один поток каждое требование собственный ЦП. Таким образом, единственный процесс может использовать 100% всех 4 ядер, если это является многопоточным.
Записки IT специалиста
Linux — начинающим. Что такое Load Average и какую информацию он несет
- Автор: Уваров А.С.
- 29.06.2016

С необходимостью правильно оценить нагрузку на систему сталкивается каждый системный администратор. Если говорить о Linux-системах, то одним из основных терминов, с которым придется столкнуться начинающему администратору окажется Load Average (средняя загрузка). Однако, если говорить о русскоязычном сегменте сети интернет, описание данного параметра сводится к общим малозначащим фразам, в то время как за этими простыми цифрами кроется глубокий пласт информации о работе системы.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Если обратиться к популярным источникам (Википедия), то можно найти примерно следующее:
Средняя загрузка — среднее значение загрузки системы за некоторый период времени, как правило, отображается в виде трёх значений, которые представляют собой усредненные величины за последние 1, 5 и 15 минут, чем ниже, тем лучше. В UNIX это среднее значение вычислительной работы, которую выполняет система.
После прочтения данного абзаца никаких новых знаний, кроме того, что масло таки масляное (средняя загрузка — среднее значение загрузки) не возникает и понимания ситуации не прибавляется. Чем ниже, тем лучше, но насколько ниже и относительно чего.
Посмотреть текущую загрузку системы можно командной
Также ее значения выводят утилиты top и htop, а также множество других инструментов. В ответ мы получим что-то вроде:
Много это или мало? Хорошо или плохо? Давайте разбираться.
Чтобы понять, что такое загрузка системы следует обратиться к логике работы центрального процессора. Вне зависимости от того, мощный у вас процессор или слабый, многоядерный или нет, он выполняет некий программный код для некоторых процессов. Если процесс один, то вопросов нет, а вот когда их несколько? Надо как-то распределять ресурсы между ними и, желательно, равномерно, чтобы один процесс, «дорвавшись» до CPU, не оставил без вычислений другие.
Здесь можно провести аналогию, когда несколько игроков хотят поиграть на одной приставке. Что обычно делают в таких случаях? Договариваются о времени, скажем каждый играет по 15 минут, затем дает поиграть другому.
Процессор поступает аналогичным образом. Каждому нуждающемуся в вычислениях процессу выделяется некий промежуток времени, который зависит от типа процессора и системы, если говорить о современных процессорах Intel, то это значение обычно составляет 10 мс и называется тиком. Каждый тик процессорное время отдается какому-то одному процессу в порядке очереди, но если процесс имеет повышенный или пониженный приоритет, то он, соответственно получит большее или меньшее количество тиков.
Количество использованных тиков, в первом приближении, и представляет загрузку системы. В Linux для оценки загрузки используется интервал в 500 тиков (5 секунд), при этом учитываются как работающие процессы (использованные тики), так и ожидающие (которым не хватило тика, либо они не смогли его использовать, ожидая завершения иной операции).
Если мы используем все тики за указанный промежуток времени и у нас не будет ожидающих сводного тика процессов, то мы получим загрузку процессора на 100% или load average (LA) равное 1.
Давайте рассмотрим следующую схему:
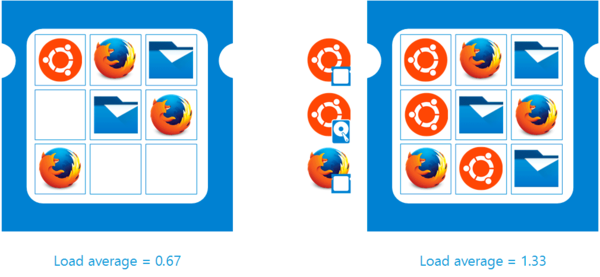
Для простоты мы будем использовать в расчетах более короткий интервал — 9 тиков. На схеме слева мы видим, что процессорные ресурсы сначала понадобились системе, затем браузеру и файловому менеджеру, потом активности в системе не было, затем еще один тик взял файловый менеджер и еще два браузер, последние два тика также не понадобились никому. Несложные расчеты показывают, что мы использовали 67% процессорного времени или load average системы составил 0,67.
Справа показана ситуация, когда каждый тик был занят своим процессом, но некоторые процессы так и не получили своего тика или не смогли получить, например, ждали окончания операции ввода-вывода. В таком случае загрузка процессора составит все те же 100%, но load average вырастет до 1,33, указывая на наличие очереди.
Чтобы лучше понять ситуацию давайте представим себе небольшой супермаркет, касса представляет собой аналог процессора, тик — среднее время обслуживания покупателя (скажем, 1 минута), а процессы — это покупатели. В разгар рабочего дня людей в магазине немного, и вы спокойно прошли на свободную кассу, рассчитались и пошли по своим делам. Это хорошо, но как оценить нагрузку на кассу? Для этого нужно взять некий промежуток времени, допустим 10 минут. Если за 10 минут в магазине кроме вас было еще три человека, то средняя загрузка составит 0,4.
А теперь зайдем в магазин вечером, все кассы заняты, и чтобы оплатить покупки придется ждать. Теперь если за 10 минут касса обслужила 10 человек и еще 10 стоят в очереди, то средняя загрузка будет равна 2, хотя касса загружена всего на 100%.
Вернемся к процессору и еще одному моменту, процессам, ожидающим окончания операций ввода-вывода (диск, сеть и т.п.). Во многих источниках указывается, что такие процессы искажают результат load average и мы можем получить высокие значения LA при отсутствии загрузки процессора. Да, это так. Посмотрим на еще одну схему ниже:
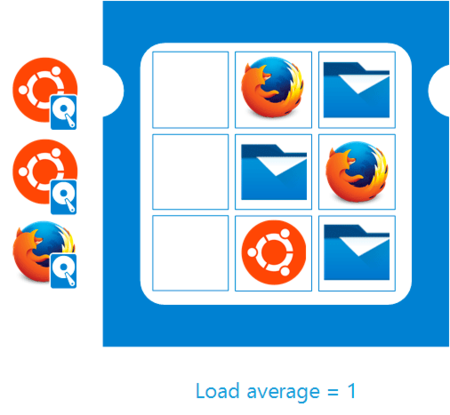
Как видим, из 9 тиков было использовано только 6, т.е. процессор загружен всего на 67%, но так как три процесса ждут данные от диска, то load average по-прежнему равен 1.
Если продолжать аналогию с супермаркетом, то похожая ситуация возникает, когда вы уже подошли к кассе и уже собрались выгружать продукты на ленту, но ваша супруга говорит вам, что она забыла купить хлеб, и вы тут стойте, а она сбегает. Собственно, все что вам остается до того, как она принесет хлеб, это стоять рядом с кассой и ждать, пропуская тех, кто находится в очереди позади вас.
Искажают ли такие процессы значение load average? На наш взгляд нет. Следует понимать, что средняя загрузка — это не показатель производительности процессора, не результат бенчмарка, не текущая нагрузка, а отношение числа процессов, которым требуются вычислительные ресурсы системы к имеющимся в наличии ресурсам.
Т.е. если у нас имеется 1 процессор и 500 тиков, но за это время процессорные ресурсы требуются тысяче процессов, то нагрузка у нас явно вдвое превышает имеющиеся ресурсы. И то, что часть процессов ждут жесткий диск и процессор работает вхолостую, не говорит о том, что система находится в простое, наоборот, она не может обработать нагрузку, правда по другой, не зависящей от процессора причине.
Пользователю ведь все равно по какой причине тормозит сайт или приложение, тем более что недостаток дисковых ресурсов обычно выражается подвисании приложения, в то время как при недостатке процессорных оно просто начинает тормозить.
Подведем промежуточный итог. Load average показывает отношение имеющихся запросов на вычислительные ресурсы к количеству этих самых ресурсов (тиков). Для одного процессора (одного процессорного ядра) использование всех имеющихся ресурсов обозначает load average = 1. Причем это будет справедливо и для Core i7 и для Pentium I, хотя производительность у этих двух процессоров разная.
Теперь перейдем к многопроцессорности и многоядерности. При появлении второго процессора или второго ядра у нас появляются дополнительные вычислительные ресурсы, т.е. же самые 500 тиков. Но за эти 500 тиков система уже может обработать уже 1000 запросов, что покажет нам load average = 2.
Значит ли это, что производительность выросла в два раза? Нет! Производительность зависит от того, сколько вычислений способен произвести процессор в течении одного тика. Понятно, что более мощный процессор выполнит за этот промежуток времени больше вычислений, но оба из них сделают одинаковое число тиков (для каждого процессорного ядра). В многопроцессорных (многоядерных) системах часть процессорного времени вместо вычислений занимают задачи межпроцессорного взаимодействия, переключения контекста и т.д. Поэтому появление второго ядра никогда не даст 100% прироста производительности, но всегда позволяет обработать вдвое большее количество запросов.
Это хорошо видно на примере технологии Hyper-threading, которая позволяет сделать из одного физического ядра процессора два виртуальных. Физическая производительность ядра процессора, т.е. количество производимых им вычислений в единицу времени не меняется, но появляется, хоть и виртуальное, но второе ядро, а это еще 500 тиков. Как показывают тесты, прирост производительности от Hyper-threading составляет 15-30%, что еще раз подтверждает старую поговорку, что лучше плохо ехать, чем хорошо стоять. Второе ядро, хоть и виртуальное, позволяет обрабатывать вычислительные запросы тех процессов, которые в одноядерном варианте стояли бы в очереди.
Непонимание этого момента приводит к тому, что load average ошибочно связывают не с доступностью и достаточностью вычислительных ресурсов, а с производительностью процессора, что приводит к неверным выводам.
Например, переводчик довольно неплохой статьи на Хабре делает ошибочный вывод в отношении Hyper-threading:
Хабраюзер esvaf в комментариях интересуется, как интерпретировать значения load average в случае использования процессора с технологией HyperThreading. Однозначного ответа на данный момент я не нашел. В данной статье утверждается, что процессор, который имеет два виртуальных ядра при одном физическом, будет на 10-30% более производительным, чем простой одноядерный. Если принимать такое допущение за истину, считаю, при интерпретации load average стоит брать в расчет только количество физических ядер.
А Википедия вообще написала полную ерунду (что для технических статей там совсем не редкость):
Средняя нагрузка — это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения). И если на компьютере есть несколько процессоров, то такой характеристике верить нельзя. Располагая двумя процессорами, можно (теоретически) одновременно выполнять в два раза большее число программ. Это означает, что средняя нагрузка 2.00 (на двухпроцессорном компьютере) будет эквивалентна средней нагрузке 1.00 (на однопроцессорном компьютере). На самом деле это не совсем так. Из-за дополнительной нагрузки, вызванной планированием и некоторыми другими факторами, двухпроцессорный компьютер не обеспечивает удвоения быстродействия по сравнению с однопроцессорным вариантом.
Убедиться, что это не так довольно легко. Если запустить бесконечный цикл командой
то мы обеспечим полную загрузку одного процессорного ядра и load average = 1 (в данный момент смотрим только на первые, минутные показания данного параметра).

Два процесса:
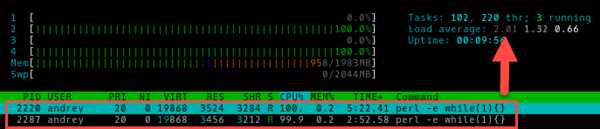
Четыре:
Мы не знаем, сколько именно операций в единицу времени выполняет наш процессор, но нам и не нужно знать это, гораздо важнее понимать, что на текущий момент все вычислительные ресурсы системы задействованы, но недостатка в них нет.
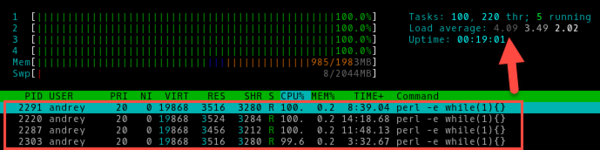
Запустим пятый процесс:
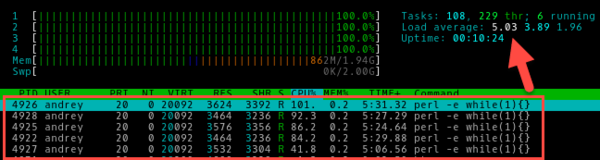
Что изменилось? Загрузка процессора осталась на уровне 100%, это и понятно, выше головы не прыгнешь, но load average вырос до 5, что означает нехватку вычислительных ресурсов примерно на 20%. Таким образом понимание сути значения средней загрузки позволяет администратору однозначно сделать выводы о текущей ситуации, чего не скажешь, глядя просто на индикатор загрузки CPU.
Теперь касательно HyperThreading, виртуализации и т.п. случаев, когда процессор, с которым работает система далеко не соответствует физическому процессору, искусственно создадим данную ситуацию. Для этого запустим на хосте параллельно с виртуальной машиной какой-нибудь ресурсоемкий процесс, например, кодирование видео. Виртуальная машина будет рассчитывать на 4 полных процессорных ядра, а по факту получит в лучшем случае половину их производительности. Проверим?
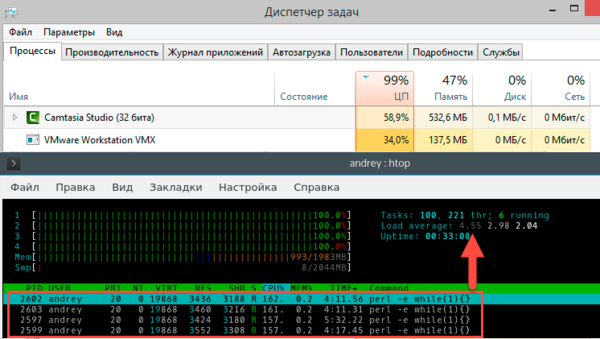
На что следует обратить внимание? В текущих условиях виртуальная машина получает примерно 30-40% загрузки физического процессора. Внутри виртуалки мы видим ожидаемые 100% загрузки процессора, однако если обратить внимание на колонку CPU%, то мы увидим там весьма интересные значения 157-162% загрузки процессора. Почему так происходит? Внутри виртуальной системы тиков CPU хватает всем, но реально гипервизор не выделяет виртуалке процессорного времени. Но это все лирика, что нам показывает load average? Налицо недостаток вычислительных ресурсов — 4,55. Соответствует это реальному положению дел? Да. Нужно ли вносить какие-то коррективы? На наш взгляд — нет.
Теперь уберем стороннюю нагрузку. Гипервизор тут же передаст максимум ресурсов виртуальной машине.
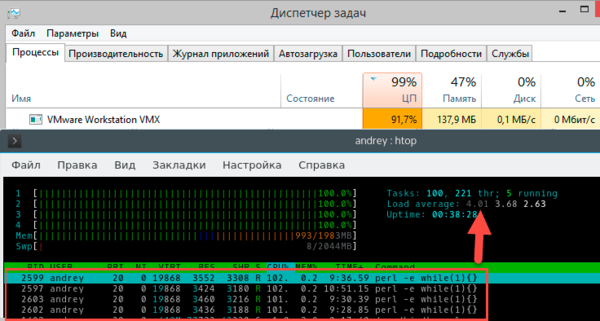
Как видим, вычислительных ресурсов снова стало достаточно и load average опустился до значения 4.
Какие выводы мы можем сделать из этого примера? Что значение load average корректно отражает загрузку системы даже в тех условиях, когда иные показатели не дают корректного представления о происходящих процессах. Так нагрузка на CPU в 157% явно противоречит здравому смыслу, а вот LA = 4,55 вполне реально отражает ситуацию. Поэтому никаких корректив на виртуальные ядра, виртуализацию и т.п. вносить не надо. Load average является относительной величиной и от реальной производительности CPU не зависит в тоже время показывая наличие или дефицит вычислительных ресурсов.
Теперь разберемся с самими цифрами. Мы получаем три значения load average для промежутков в 1, 5 и 15 минут. Как гласит та же Википедия — это средние значения за указанный промежуток времени, что снова неправильно. Для отображения load average используется экспоненциально взвешенная скользящая средняя, подобный тип кривых используется для для сглаживания краткосрочных колебаний и выделения основных тенденций или циклов.
Например, скользящие средние широко применяются в финансовом анализе, для выделения общих тенденций движения курсов валют и акций, позволяя отбросить так называемый «биржевой шум» и понять общие тренды рынка.
То, что подходит финансисту, наверняка подойдет и системному администратору. В чем основное преимущество скользящих средних? В том, что они позволяют выделить основные тенденции, отбросив кратковременные колебания. Это достоинство, а не недостаток, как пытается убедить нас Википедия:
Средняя нагрузка — это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения).
Именно усредненные по особому алгоритму значения позволяют нам окинуть ситуацию взглядом вширь и вглубь и разглядеть за деревьями лес. В этом отношении временные значения load average представляют собой не время, за которое посчитали среднее значение, а период времени относительно которого проводится усреднение.
Благодаря автору Хабра ZloyHobbit, который не поленился изучить исходный код Linux, можно точно смоделировать различные значения load average при заданной модели нагрузки. Мы смоделировали ситуацию, когда первые 30 минут единственное ядро CPU было нагружено на 100%, без ждущих в очереди процессов, в последующие полчаса нагрузка была полностью снята.
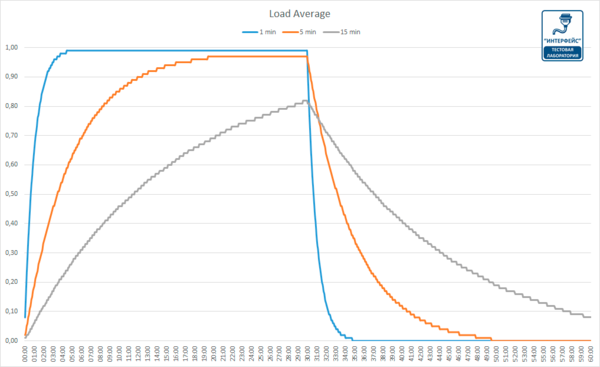
Как видим, разные периоды усреднения дают совершенно различные результаты, так LA 1 (1 min), начинает показывать реальные значения где-то через 4 минуты, LA 5 для отражения текущей нагрузки потребовалось уже 20 минут, а LA 15 за полчаса полной загрузки вышла только на 0,8.
О чем это говорит и как интерпретировать данные значения? Можно сказать, что LA 1 представляет собой недавнее прошлое (несколько минут назад), LA 5 прошлое (полчаса-час) и LA 15 отдаленное прошлое (несколько часов).
Теперь, располагая этим багажом знаний, мы можем правильно интерпретировать простые, на первый взгляд, три числа load average.
Для примера возьмем такое значение:
Это говорит о том, что имеет место достаточно кратковременный (около десятка минут) всплеск нагрузки, при этом вычислительных ресурсов пока достаточно.
Говорит о том, что не так давно система испытывала значительные нагрузки в течении довольно продолжительного времени (полчаса-час).
А вот такая картина:
Для четырехядерного процессора означает, что он работает на пределе своих возможностей в течении длительного времени (несколько часов).
Как видим, load average, несмотря всего на три цифры, способна представить системному администратору огромный пласт информации о фактической загрузке системы на протяжении последних нескольких часов.
Теперь самое время дать ответы на вопросы, поставленные нами в начале статьи: «Много это или мало? Хорошо или плохо? » Для одного ядра мы считаем приемлемыми следующие значения:
- LA 1 — может превышать 1.00, свидетельствуя о кратковременной пиковой нагрузке на систему.
- LA 5 — не должен превышать 1.00, в противном случае налицо явный недостаток вычислительных ресурсов.
- LA 15 — максимальное значение 0.7 — 0.8, но в любом случае не выше 1.0, в противном случае вы можете получить в три часа ночи звонок от руководства с вопросом: » А что это с нашим сервером. «
На многоядерной (многопроцессорной) системе значения load average следует откорректировать пропорционально числу ядер. Узнать их количество можно командой
Так, например, с учетом вышесказанного, для четырехядерной системы LA 15 не должен превышать 3.00, для двухядерной 1.5, а для одноядерной 0.75.
Теперь, понимая, что такое load average и каким образом формируются его значения вы всегда сможете быстро оценить производительность собственной системы и вовремя принять меры если в работе вашего сервера возникнут узкие места.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Дополнительные материалы:
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
Или подпишись на наш Телеграм-канал: ![]()
Мониторинг использования CPU на сервере Linux
Объем памяти, размер кеша, скорость чтения и записи на диск, скорость и доступность вычислительной мощности – это ключевые элементы, влияющие на производительность любой инфраструктуры.
Данное руководство ознакомит с базовыми понятиями мониторинга CPU. Вы узнаете, как использовать утилиты uptime и top, чтобы узнать о нагрузке и использовании ЦП.
Требования
- Сервер Linux.
- Утилиты uptime и top должны быть установлены по умолчанию. Если это не так, установите их вручную.
Основные понятия
Прежде чем приступить к работе с утилитами, нужно понять, как измеряется использование ЦП и к каким результатам нужно стремиться.
Загрузка и использование ЦП
Загрузка (CPU Load) и использование процессора (CPU Utilization) – два разных способа взглянуть на использование вычислительной мощности компьютера.
Чтобы оценить основное различие между ними, попробуйте представить, что процессоры – это кассиры в продуктовом магазине, а задачи – это клиенты, которых нужно обслужить. Загрузка процессора – это, по сути, одна очередь, в которой клиенты ждут, пока освободиться один из кассиров. Нагрузка – это в данном случае количество клиентов в очереди, включая тех, что уже на кассе. Чем длиннее очередь, тем дольше ждать.
Использование ЦП оценивает исключительно занятость кассиров и не знает, сколько клиентов в очереди.
Если говорить конкретнее, задачи создают очередь за ресурсами процессоров. Когда подходит очередь той или иной задачи, она должна получить определенное количество времени обработки. Если задача была выполнена, он снимается; в противном случае она возвращается в конец очереди. После этого обрабатывается следующая задача в очереди.
Загрузка ЦП – это длина очереди запланированных задач, включая те, что находятся в обработке. Задачи могут переключаться в пределах миллисекунд, поэтому один снапшот загрузки не так полезен, как среднее значение из нескольких снапшотов, взятых за определенный период времени. Потому загрузка ЦП часто представляется как среднее значение.
Загрузка процессора отображает спрос на процессорное время. Высокий спрос может привести к сбоям и ухудшению производительности.
Использование ЦП сообщает, насколько загружены процессоры, не беря во внимание количество ожидающих задач. Мониторинг использования ЦП может отображать тенденции во времени, выделять пики использования процессора и выявлять нежелательную активность на сервере.
Ненормированные и нормированные значения
В одной процессорной системе общая емкость всегда равна 1. В многопроцессорной системе данные могут отображаться двумя разными способами. Суммарная емкость всех процессоров рассчитывается как 100% независимо от количества процессоров, такое значение считается нормированным. Другой вариант предлагает считать каждый процессор как единицу, так что 2-процессорная система в полном объеме имеет емкость 200%, 4-процессорная система в полном объеме имеет мощность 400% и т. д.
Чтобы правильно интерпретировать загрузку или использование CPU, нужно знать количество процессоров на сервере.
Отображение информации о ЦП
Чтобы узнать количество процессоров, можно использовать команду nproc с опцией –all. Без этого флага команда отобразит количество обрабатывающих блоков, доступных для текущего процесса, что будет меньше общего количества процессоров.
В большинстве современных дистрибутивов Linux также можно использовать команду lscpu, которая отображает не только количество процессоров, но и архитектуру, имя модели, скорость и многое другое:
lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2650L v3 @ 1.80GHz
Stepping: 2
CPU MHz: 1797.917
BogoMIPS: 3595.83
Virtualization: VT-x
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 30720K
NUMA node0 CPU(s): 0,1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm vnmi ept fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat
Знание точного количества процессоров важно для интерпретации результатов тех или иных утилит.
Оптимальные значения загрузки и использования ЦП
Оптимальное значение использования ЦП зависит от того, какую работу должен выполнять сервер. Стабильно высокое использование процессора негативно влияет на отзывчивость системы. Часто приложениям и пакетным заданиям с интенсивными вычислениями необходим весь или почти весь объем ЦП. Однако, если система должна обслуживать веб-страницы или поддерживать интерактивные сеансы сервисов (например, SSH), тогда может понадобиться свободная вычислительная мощность.
Как и во многих других аспектах производительности, ключом к оптимизации ресурсов является изучение потребностей сервисов системы и мониторинг непредвиденных изменений.
Мониторинг ЦП
Существует множество инструментов для получения данных о состоянии ЦП системы. Мы рассмотрим две команды: uptime и top. Обе утилиты являются частью стандартной установки большинства популярных дистрибутивов Linux и обычно используются для исследования загрузки и использования ЦП.
Примечание: Следующие примеры выполнены на 2-ядерном сервере.
Утилита uptime
Команда uptime позволяет отследить загрузку процессора. Она может быть полезна, если система медленно реагирует на интерактивные запросы (вероятно, ей не хватает системных ресурсов).
Утилита uptime сообщает следующие данные:
- системное время в момент выполнения команды;
- как долго работает сервер;
- сколько подключений пользователей обслуживает машина;
- средняя загрузка процессора за последние одну, пять и пятнадцать минут.
uptime
14:08:15 up 22:54, 2 users, load average: 2.00, 1.37, 0.63
В этом примере команда была запущена в 14:08 на сервере, который работал почти 23 часа. При запуске uptime подключились два пользователя. Этот сервер имеет 2 процессора. За минуту до запуска команды средняя загрузка процессора была 2,00, что означает, что в течение этой минуты процессоры использовали в среднем две задачи, а ожидающих задач не было. Среднее значение загрузки з а5 минут указывает на то, что в течение некоторого интервала времени один из процессоров бездействовал около 60% времени. Среднее за 15 минут значение указывает на то, что было доступно больше времени обработки. Вместе эти три значения показывают увеличение загрузки за последние пятнадцать минут.
Утилита uptime сообщает полезные средние значения загрузки ЦП, но для того, чтобы получить более подробную информацию, нужно использовать top.
Утилита top
Как и uptime, утилита top доступна как в Linux, так и в Unix-системах, но помимо отображения средних значений нагрузки для заданных временных интервалов она предоставляет информацию о потреблении ЦП в реальном времени, а также другие полезные показатели производительности. Если uptime запускается и сразу завершает работу, top работает на переднем плане и регулярно обновляется.
Заглавный блок
Первые пять строк содержат сводную информацию о процессах на сервере:
top — 18:31:30 up 1 day, 3:17, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 114 total, 1 running, 113 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.7 us, 0.0 sy, 0.0 ni, 92.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.1 st
KiB Mem : 4046532 total, 3238884 free, 73020 used, 734628 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3694712 avail Mem
Первая строка почти идентична выводу утилиты uptime. Здесь показаны средние значения за одну, пять и пятнадцать минут. Эта строка отличается от вывода uptime только тем, что вначале указывается утилита top и время последнего обновления данных.
Вторая строка предоставляет краткий обзор состояния задач: общее количество процессов, количество запущенных, спящих, остановленных и зависших процессов.
Третья строка говорит об использовании ЦП. Эти цифры нормируются и отображаются в процентах (без символа %), так что все значения в этой строке должны составлять до 100% независимо от количества процессоров.
Четвертая и пятая строки сообщают об использовании памяти и swap соответственно.
После заглавного блока следует таблица с информацией о каждом отдельном процессе, которую мы вскоре рассмотрим.
В нижеприведенном заглавном блоке среднее значение загрузки за одну минуту превышает число процессоров на .77, что указывает на короткую очередь с небольшим временем ожидания. Общая емкость процессора используется на 100%, и есть много свободной памяти.
top — 14:36:05 up 23:22, 2 users, load average: 2.77, 2.27, 1.91
Tasks: 117 total, 3 running, 114 sleeping, 0 stopped, 0 zombie
%Cpu(s): 98.3 us, 0.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.2 si, 1.3 st
KiB Mem : 4046532 total, 3244112 free, 72372 used, 730048 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3695452 avail Mem
. . .
Давайте рассмотрим подробнее все компоненты строки CPU.
- us, user: время на un-niced процессы пользователя. Эта категория относится к пользовательским процессам, которые были запущены без явного приоритета планирования. Системы Linux используют команду nice для установки приоритета планирования процесса. «un-niced» означает, что приоритет по умолчанию не менялся с помощью nice. Значения user и nice учитывают все пользовательские процессы. Высокое использование ЦП в этой категории может указывать на неконтролируемый процесс. Вывод в таблице процессов может определить, действительно ли это так.
- sy, system: системные процессы. Большинство приложений имеют как пользовательские компоненты, так и компоненты ядра. Когда ядро Linux создает системные вызовы, проверяет привилегии или взаимодействует с устройствами от имени приложения, здесь отображается использование процессора. Когда процесс выполняется не ядром, он будет отображаться либо в показателе user, либо в nice, если его приоритет был задан с помощью nice.
- ni, nice: niced процессы пользователя. Как и user, это поле отображает задачи, не связанные с ядром. В отличие от user, приоритет планирования для этих задач был установлен с помощью nice. Уровень приоритета (niceness) процесса указан в четвертом столбце таблицы процессов в заголовке NI. Процессы со значением niceness от 1 до 20 имеют пониженный приоритет. Такие процессы, потребляющие много процессорного времени, обычно не создают проблем, потому что задачи с повышенным приоритетом получат вычислительную мощность своевременно. Однако, если задачи с повышенным приоритетом (между -1 и -20) занимают непропорциональное количество CPU, они могут легко повлиять на отзывчивость системы. Обратите внимание, что многие процессы с самым высоким приоритетом планирования (-19 или -20 в зависимости от системы) порождаются ядром для выполнения важных задач, которые влияют на стабильность системы. Если вы не уверены, что точно знаете все процессы, указанные в выводе, лучше исследуйте их, но не останавливайте.
- Id, idle: время, затраченное на обработчик простоя ядра. Этот показатель отображает процент времени, в течение которого ЦП был доступен и простаивал. Считается, что система разумно использует ЦП, если сумма user, nice и idle близка к 100%.
- wa, IO-wait: время ожидания завершения ввода-вывода. Показатель сообщает, когда процессор начал операцию чтения или записи и ожидает завершения операции ввода-вывода. Задачи чтения и записи для удаленных ресурсов (таких как NFS и LDAP) будут также учитываться. Как и в строке idle, прыжки здесь считаются нормой. Но если показатель сообщает о частых или продолжительных обработках, это может указывать на зависшую задачу или потенциальную проблему с жестким диском.
- hi: время на бслуживание аппаратных прерываний. Это время, затрачиваемое на физические прерывания, отправленные на процессор с периферийных устройств (дисков и аппаратных сетевых интерфейсов). Если значение аппаратного прерывания велико, одно из периферийных устройств может работать неправильно.
- si: время, затраченное на обслуживание программных прерываний. Программные прерывания отправляются процессами, а не физическими устройствами. В отличие от аппаратных прерываний, которые происходят на уровне ЦП, программные прерывания происходят на уровне ядра. Если этот показатель сообщает о высоком использовании вычислительной мощности, исследуйте процессы, которые используют CPU.
- st: время, которое использовал гипервизор. Значение steal сообщает, как долго виртуальный процессор ожидает ответа физического процессора, когда гипервизор обслуживает свои задачи или другой виртуальный процессор. По сути, объем использования ЦП в этом поле указывает, сколько мощности для обработки виртуальной машины готово к использованию, но недоступно приложению, поскольку оно используется физическим хостом или другой виртуальной машиной. Как правило, нормой значения steal считается до 10% в течение коротких периодов времени. Большее значение steal в течение более длительного периода времени указывает на то, что физический сервер имеет больший спрос на CPU, чем он может предоставить.
Таблица процессов
Все процессы, выполняемые на сервере, независимо от их состояния перечисляются под заглавным блоком вывода. Ниже приведены первые шесть строк таблицы процессов из предыдущего примера. По умолчанию таблица процессов сортируется по% CPU, поэтому в начале находятся процессы, которые потребляют больше CPU.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9966 8host 20 0 9528 96 0 R 99.7 0.0 0:40.53 stress
9967 8host 20 0 9528 96 0 R 99.3 0.0 0:40.38 stress
7 root 20 0 0 0 0 S 0.3 0.0 0:01.86 rcu_sched
1431 root 10 -10 7772 4556 2448 S 0.3 0.1 0:22.45 iscsid
9968 root 20 0 42556 3604 3012 R 0.3 0.1 0:00.08 top
9977 root 20 0 96080 6556 5668 S 0.3 0.2 0:00.01 sshd
.
Столбец %CPU представлен как процентное значение, но он не нормируется, поэтому в этой двухъядерной системе общее количество всех значений в таблице процессов должно составлять до 200%, если оба процессора полностью используются.
Примечание: Если вы предпочитаете работать с нормированными значениями, вы можете нажать SHIFT + I, и отображение переключится с режима Irix в режим Solaris. Этот режим выводит ту же информацию, которая усредняется по всему количеству процессоров, так что используемая сумма не будет превышать 100%. Перейдя к режиму Solaris, вы получите краткое сообщение о том, что режим Irix выключен.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10081 8host 20 0 9528 96 0 R 50.0 0.0 0:49.18 stress
10082 8host 20 0 9528 96 0 R 50.0 0.0 0:49.08 stress
1439 root 20 0 223832 27012 14048 S 0.2 0.7 0:11.07 snapd
1 root 20 0 39832 5868 4020 S 0.0 0.1 0:07.31 systemd
Заключение
Теперь вы умеете работать с утилитами uptime и top и интерпретировать их вывод.
CPU Load: когда начинать волноваться?
Данная заметка является переводом статьи из блога компании Scout. В статье дается простое и наглядное объяснение такого понятия, как load average . Статья ориентирована на начинающих Linux-администраторов, но, возможно, будет полезна и более опытным админам. Заинтересовавшимся добро пожаловать под кат.
Вероятно, Вы уже знакомы с понятием load average . Load average — это три числа, отображаемые при выполнении команд top и uptime . Выглядят они примерно так:
Большинство интуитивно понимают, что эти три числа обозначают средние значения загрузки процессора на прогрессивно увеличивающихся временных промежутках (одна, пять и пятнадцать минут) и чем меньше их значения — тем лучше. Большие числа свидетельствуют о слишком большой нагрузке на сервер. Но какие значения считать предельными? Какие значения являются «плохими», а какие — «хорошими»? Когда Вам следует просто волноваться о занчениях средней загрузки, а когда следует бросать другие дела и решать проблему так быстро, как это возможно?
Для начала, давайте разберемся, что же означает load average . Рассмотрим простейший случай: предположим, что у нас в наличии один сервер с одноядерным процессором.
Аналогия транспортного потока
- 0.00 означает, что на мосту нет ни одной машины. Фактически, значения от 0.00 до 1.00 означают отсутствие очереди. Подъезжающая машина может воспользоваться мостом без ожидания;
- 1.00 означает, что на мосту находится как раз столько автомобилей, сколько он может вместить. Все еще идет хорошо, но, в случае увеличения потока машин, возможны проблемы;
- Значения, превышающие 1.00 означают наличие очереди на въезде. Насколько большой? Например, значение 2.00 показывает, что в очереди стоит столько же автомобилей, сколько движется по мосту. 3.00 означает, что мост полностью занят и в очереди ожидает в два раза больше машин, чем он может вместить. И так далее.
Так Вы говорите, 1.00 — идеальное значание load average?
- Практическое правило «Требуется присмотр»: 0.70. Если среднее значение загрузки постоянно превышает 0.70, следует выяснить причину такого поведения системы во избежании проблем в будущем;
- Практическое правило «Почини это немедленно!»: 1.00. Если средняя загрузка системы превышает 1.00, необходимо срочно найти причину и устранить ее. В противном случае, Вы рискуете быть разбуженным посреди ночи и это точно не будет весело;
- Практическое правило «Щас же 3 ночи. ШОЗАНАХ. »: 5.00. Если среднее значение загрузки процессора превышает 5.00, у Вас серьезные проблемы. Сервер может подвисать или работать очень медленно. Скорее всего, это произойдет в худший из возможных моментов. Например, посреди ночи или когда Вы выступаете с докладом на конференции.
Что насчет многопроцессорных систем? Мой сервер показывает загрузку 3.00 и все ОК!
У Вас четырехпроцессорная система? Все в порядке, если load average равен 3.00.
В мультипроцессорных системах загрузка вычисляется относительно количества доступных процессорных ядер. 100% загрузка обозначается числом 1.00 для одноядерной машины, числом 2.00 для двуядерной, 4.00 для четырехъядерной и т.д.
Если вернуться к нашей аналогии с мостом, 1.00 означает «одну полностью загруженную полосу движения». Если на мосту всего одна полоса, 1.00 означает, что мост загружен на 100%, если же в наличии две полосы, он загружен всего на 50%.
То же самое с процессорами. 1.00 означает 100% загрузки одноядерного процессора. 2.00 — 100% загрузки двуядерного и т.д.
Многоядерность vs. многопроцессорность
- «Количество ядер = максимальная загрузка». На многоядерной системе, загрузка не должна превышать количества доступных ядер;
- «Ядра — они и в Африке ядра». То, как ядра распределены по процессорам — неважно. Два четырехъядерных = четыре двуядерных = восем одноядерных процессоров. Имеет значение лишь общее число ядер.
Сведем все вместе
Давайте посмотрим на средние значения загрузки с помощью команды uptime :
Здесь представлены показатели для системы с четырехъядерным процессором и мы видим, что имеется большой запас по нагрузке. Я даже не буду задумываться о ней, пока load average не превысит 3.70.
Какое среднее значение мне следует контролировать? Для одной, пяти или 15 минут?
Количество ядер важно для правильно понимания load average. Как мне его узнать?
Команда cat /proc/cpuinfo выводит информацию обо всех процессорах в вашей системе. Чтобы узнать количество ядер, «скормите» ее вывод утилите grep :
Примечания переводчика
Выше представлен перевод самой статьи. Также много интересной информации можно почерпнуть из комментариев к ней. Так, один из комментаторов говорит о том, что не для каждой системы важно иметь запас по производтельности и не допускать значения загрузки выше 0.70 — иногда нам нужно чтобы сервер работал «на всю катушку» и в таких случаях load average = 1.00 — то, что доктор прописал.
Хабраюзер dukelion добавил в комментариях ценное замечание, что в некоторых сценариях, для достижения максимального КПД «железа», стоит держать значение load average несколько выше 1.00 в ущерб эффективности работы каждого отдельного процесса.
Хабраюзер enemo в комментариях добавил замечание о том, что высокий показатель load average может быть вызван большим количеством процессов, выполняющих в данный момент операции чтения/записи. То есть, load average > 1.00 на одноядерной машине не всегда говорит о том, что в Вашей системе отсутствует запас по загрузке процессора. Требуется более внимательное изучение причин такого показателя. Кстати, это хорошая тема для нового поста на Хабре 🙂