ReadMe.conf
Роутинг и policy-routing в Linux при помощи iproute2
Речь в статье пойдет о роутинге сетевых пакетов в Linux. А конкретно – о типе роутинга под названием policy-routing (роутинг на основании политик). Этот тип роутинга позволяет маршрутизировать пакеты на основании ряда достаточно гибких правил, в отличие от классического механизма маршрутизации destination-routing (роутинг на основании адреса назначения). Policy-routing применяется в случае наличия нескольких сетевых интерфейсов и необходимости отправлять определенные пакеты на определенный интерфейс, причем пакеты определяются не по адресу назначения или не только по адресу назначения. Например, policy-routing может использоваться для: балансировки трафика между несколькими внешними каналами (аплинками), обеспечения доступа к серверу в случае нескольких аплинков, при необходимости отправлять пакеты с разных внутренних адресов через разные внешние интерфейсы, даже для отправки пакетов на разные TCP-порты через разные интерфейсы и т.д.
Для управления сетевыми интерфейсами, маршрутизацией и шейпированием в Linux служит пакет утилит iproute2.
Этот набор утилит лишь задает настройки, реально вся работа выполняется ядром Linux. Для поддержки ядром policy-routing оно должно быть собрано с включенными опциями IP: advanced router (CONFIG_IP_ADVANCED_ROUTER) и IP: policy routing (CONFIG_IP_MULTIPLE_TABLES), находящимися в разделе Networking support -> Networking options -> TCP/IP networking.
ip route
Для настройки роутинга служит команда ip route. Выполненная без параметров, она покажет список текущих правил маршрутизации (не все правила, об этом чуть позже):
Так будет выглядеть роутинг при использовании на интерфейсе eth0 IP-адреса 192.168.12.101 с маской подсети 255.255.255.0 и шлюзом по умолчанию 192.168.12.1.
Мы видим, что трафик на подсеть 192.168.12.0/24 уходит через интерфейс eth0. proto kernel означает, что роутинг был задан ядром автоматически при задании IP интерфейса. scope link означает, что эта запись является действительной только для этого интерфейса (eth0). src 192.168.12.101 задает IP-адрес отправителя для пакетов, попадающих под это правило роутинга.
Трафик на любые другие хосты, не попадающие в подсеть 192.168.12.0/24 будет уходить на шлюз 192.168.12.1 через интерфейс eth0 ( default via 192.168.12.1 dev eth0 ). Кстати, при отправке пакетов на шлюз, IP-адрес назначения не изменяется, просто в Ethernet-фрейме в качестве MAC-адреса получателя будет указан MAC-адрес шлюза (часто даже специалисты со стажем путаются в этом моменте). Шлюз в свою очередь меняет IP-адрес отправителя, если используется NAT, либо просто отправляет пакет дальше. В данном случае используются приватный адрес (192.168.12.101), так что шлюз скорее всего делает NAT.
А теперь залезем в роутинг поглубже. На самом деле, таблиц маршрутизации несколько, а также можно создавать свои таблицы маршрутизации. Изначально предопределены таблицы local, main и default. В таблицу local ядро заносит записи для локальных IP адресов (чтобы трафик на эти IP-адреса оставался локальным и не пытался уходить во внешнюю сеть), а также для бродкастов. Таблица main является основной и именно она используется, если в команде не указано какую таблицу использовать (т.е. выше мы видели именно таблицу main). Таблица default изначально пуста. Давайте бегло взглянем на содержимое таблицы local:
broadcast и local определяют типы записей (выше мы рассматривали тип default ). Тип broadcast означает, что пакеты соответствующие этой записи будут отправлены как broadcast-пакеты, в соответствии с настройками интерфейса. local – пакеты будут отправлены локально. scope host указывает, что эта запись действительная только для этого хоста.
Для просмотра содержимого конкретной таблицы используется команда ip route show table TABLE_NAME . Для просмотра содержимого всех таблиц в качестве TABLE_NAME следует указывать all , unspec или 0 . Все таблицы на самом деле имеют цифровые идентификаторы, их символьные имена задаются в файле /etc/iproute2/rt_tables и используются лишь для удобства.
ip rule
Как же ядро выбирает, в какую таблицу отправлять пакеты? Все логично – для этого есть правила. В нашем случае:
Число в начале строки – идентификатор правила, from all – условие, означает пакеты с любых адресов, lookup указывает в какую таблицу направлять пакет. Если пакет подпадает под несколько правил, то он проходит их все по порядку возрастания идентификатора. Конечно, если пакет подпадет под какую-либо запись маршрутизации, то последующие записи маршрутизации и последующие правила он уже проходить не будет.
- from – мы уже рассматривали выше, это проверка отправителя пакета.
- to – получатель пакета.
- iif – имя интерфейса, на который пришел пакет.
- oif – имя интерфейса, с которого уходит пакет. Это условие действует только для пакетов, исходящих из локальных сокетов, привязанных к конкретному интерфейсу.
- tos – значение поля TOS IP-пакета.
- fwmark – проверка значения FWMARK пакета. Это условие дает потрясающую гибкость правил. При помощи правил iptables можно отфильтровать пакеты по огромному количеству признаков и установить определенные значения FWMARK. А затем эти значения учитывать при роутинге.
Условия можно комбинировать, например from 192.168.1.0/24 to 10.0.0.0/8 , а также можно использовать префикc not , который указывает, что пакет не должен соответствовать условию, чтобы подпадать под это правило.
Итак, мы разобрались что такое таблицы маршрутизации и правила маршрутизации. А создание собственных таблиц и правил маршрутизации это и есть policy-routing, он же PBR (policy based routing). Кстати SBR (source based routing) или source-routing в Linux является частным случаем policy-routing, это использование условия from в правиле маршрутизации.
Простой пример
Теперь рассмотрим простой пример. У нас есть некий шлюз, на него приходят пакеты с IP 192.168.1.20. Пакеты с этого IP нужно отправлять на шлюз 10.1.0.1. Чтобы это реализовать делаем следующее:
Создаем таблицу с единственным правилом:
Создаем правило, отправляющее нужные пакеты в нужную таблицу:
Как видите, все просто.
Доступность сервера через несколько аплинков
Теперь более реалистичный пример. Имеется два аплинка до двух провайдеров, необходимо обеспечить доступность сервера с обоих каналов:

В качестве маршрута по умолчанию используется один из провайдеров, не важно какой. При этом веб-сервер будет доступен только через сеть этого провайдера. Запросы через сеть другого провайдера приходить будут, но ответные пакеты будут уходить на шлюз по умолчанию и ничего из этого не выйдет.
Решается это весьма просто:
Думаю теперь уже объяснять смысл этих строк не надо. Аналогичным образом можно сделать доступность сервера по более чем двум аплинкам.
Балансировка трафика между аплинками
Делается одной элегантной командой:
Эта запись заменит существующий default-роутинг в таблице main. При этом маршрут будет выбираться в зависимости от веса шлюза ( weight ). Например, при указании весов 7 и 3, через первый шлюз будет уходить 70% соединений, а через второй – 30%. Есть один момент, который при этом надо учитывать: ядро кэширует маршруты, и маршрут для какого-либо хоста через определенный шлюз будет висеть в таблице еще некоторое время после последнего обращения к этой записи. А маршрут до часто используемых хостов может не успевать сбрасываться и будет все время обновляться в кэше, оставаясь на одном и том же шлюзе. Если это проблема, то можно иногда очищать кэш вручную командой ip route flush cache .
Использование маркировки пакетов при помощи iptables
Допустим нам нужно, чтобы пакеты на 80 порт уходили только через 11.22.33.1. Для этого делаем следующее:
Первой командой маркируем все пакеты, идущие на 80 порт. Второй командой создаем таблицу маршрутизации. Третьей командой заворачиваем все пакеты с указанной маркировкой в нужную таблицу.
Опять же все просто. Рассмотрим также использование модуля iptables CONNMARK. Он позволяет отслеживать и маркировать все пакеты, относящиеся к определенному соединению. Например, можно маркировать пакеты по определенному признаку еще в цепочке INPUT, а затем автоматически маркировать пакеты, относящиеся к этим соединениям и в цепочке OUTPUT. Используется он так:
Пакеты, приходящие с eth0 маркируются 2, а с eth1 – 4 (строки 1 и 2). Правило на третьей строке проверяет принадлежность пакета к тому или иному соединению и восстанавливает маркировки (которые были заданы для входящих) для исходящих пакетов.
Надеюсь изложенный материал поможет вам оценить всю гибкость роутинга в Linux. Спасибо за внимание 🙂
What does "proto kernel" means in Unix Routing Table?
I’ve been searching this in linux-ip.net and the whole internet but does appears nothing. What does the «proto kernel» part means in a Routing Table?
Just an example:
![]()
1 Answer 1
excerpt from man ip(8) :
-
The Overflow Blog
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.3.3.43278
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Принцип работы Routing Policy DataBase
 Доброго времени, уважаемые читатели и гости моего блога. Сегодня хочу углубить наши и ваши знания в понимании статической маршрутизации в Linux. Упор в статье будет сделан на работу с iproute и на маршрутизации на основе политик (Policy Routing). Для понимания того, о чем пойдет речь необходимо в обязательном порядке прочитать статьи «Основные понятия сетей», «Настройка сети в Linux» и «Настройка сети в Linux с помощью iproute».
Доброго времени, уважаемые читатели и гости моего блога. Сегодня хочу углубить наши и ваши знания в понимании статической маршрутизации в Linux. Упор в статье будет сделан на работу с iproute и на маршрутизации на основе политик (Policy Routing). Для понимания того, о чем пойдет речь необходимо в обязательном порядке прочитать статьи «Основные понятия сетей», «Настройка сети в Linux» и «Настройка сети в Linux с помощью iproute».
Пару вступительных слов о маршрутизации
Итак, из основных понятий сетей мы знаем, если сетевой пакет предназначен для локальной сети, к которой подключен интерфейс, то он направляется прямо в сеть. Маршрут для такого пакета создается автоматически при поднятии настроенного интерфейса. Если пакет предназначен не локальной сети, то ядро просматривает таблицу маршрутизации на наличие маршрута для данного пакета и отправляет по маршруту, в котором адрес назначения пакета соответствует заданному в маршруте параметру — на адрес шлюза, который указан в поле gateway в маршруте. При этом, может существовать несколько маршрутов для данного пакета. В таком случае выбирается тот маршрут, в котором в заданной подсети меньше всего компьютеров. Если для текущего пакета маршрут не обнаружен, то он направляется на маршрут «по-умолчанию». Это классическая маршрутизация протокола IPv4, основанная на поиске маршрута по адресу назначения в заголовках IP.
Маршруты в Linux могут появляться различными способами. Во-первых, как я уже говорил, при поднятии сетевого интерфейса появляется соответствующий маршрут в локальную сеть, куда смотрит интерфейс. Во-вторых, маршруты могут добавляться в ручную. Это называется статическая маршрутизация. В-третьих, маршруты могут формироваться динамически, базируясь на информации о топологии и состоянии сети, получаемой с помощью протокола динамической маршрутизации. Это называется динамической маршрутизацией. Динамической маршрутизацией в Linux заведует демон gated или routed, возможно еще какой-то о котором я не знаю
Классическую маршрутизацию на основе адреса назначения применяют в небольших сетях. Данную маршрутизацию можно сравнить с походом из дома, например, в торговый центр. При этом, дорога к торговому центру может быть разделена перекрестком и на перекрестке вы выбираете пойти вам на право или налево, основываясь лишь на том, по какой из дорог вы попадете к ТЦ.
Маршрутизация на основе политик (Policy Routing)
Продолжая нашу аналогию, представим что вы уперлись в пересечение шести дорог. Усложняя задачу, представьте, что одна из дорог — асфальтированная, и предназначена для легковых автомобилей, вторая — гравийная и предназначена для движения тракторов, третья — . В данном случае, необходимо принять решение не только на том, КУДА необходимо попасть, но и на том за рулем какого транспортного средства вы находитесь, где вам будет комфортней ехать и многих других параметрах. Аналогично, основной принцип работы механизма маршрутизации на основе политик базируется на основе анализа любых полей IP-пакета, таких как адрес отправителя, IP протокол, порты транспортного протокола, или даже содержимого, а не только на основании адреса получателя.
Основу маршрутизации на основе политик составляют 4 понятия. Это традиционные понятия address (адрес) , routes (маршрут), Routing table (таблица маршрутизации), а так же новое в Policy Routing (и являющееся его основой) — rules (правила). Давайте разберем каждый из них.
Адрес (Address) определяет место назначения пакета и источник. Маршрут (routes) задает путь пакета, данное понятие не сильно отличается от традиционной маршрутизации. Соответственно, при задании маршрута так же, как и в традиционном способе (с помощью команды route ) можно указать шлюз и несколько опций для маршрута, задаваемого для хоста или подсети. Среди опций можно выделить такие как: метрика (metric), размер-TCP-окна (window) и др. В Policy Routing помимо стандартных параметров добавления маршрута появились так же опции, позволяющие указать исходящий адрес источника пакета, интерфейс или тип ICMP ответа. Таблица маршрутизации (Routing table) состоит из последовательного набора маршрутов. Правила (rule) можно рассматривать, как своеобразный фильтр, который отбирает пакеты, удовлетворяющие определенным требованиям и подходящие — направляет по заданному маршруту.
Routing Policy DataBase (RPDB)
Механизм маршрутизации на основе политик впервые был реализован в ядре версии 2.1. Он так же называется «база данных политик маршрутизации» (он же Routing Policy DataBase (RPDB)). RPDB — это связанный набор маршрутов, таблиц маршрутизации и правил. Механизм маршрутизации и ip адресации в ядре Linux 2.1 был переписан чуть более чем полностью, в результате чего появилась возможность поддерживать до 255 таблиц маршрутизации и 2^32 правил маршрутизации. Это позволяет создать более чем 4 миллиарда правил, данная цифра перекрывает все пространство адресов IPv4. Другими словами, Вы можете определить правило управления каждым отдельным адресом, доступным во всем адресном пространстве IPv4.
Давайте рассмотрим некоторый пример, который далее позволит нам более детально разобраться в Routing Policy. В классическом примере на хосте Linux имеется единственная таблица маршрутизации, в которой согласно правил и места назначения пакета ищется маршрут (адрес шлюза и/или физической интерфейс). Давайте предположим, что у нас есть 3 маршрута к некоторой сети назначения, путь через которые (маршруты) проходит по каналам разного качества, соответственно разная скорость. Предположим, в локальной сети есть некоторая группа компьютеров, которой нужна гарантированная скорость, а другой группе высокая скорость не нужна. Если у нас будет единственная таблица маршрутизации, то мы сможем указать лишь единственный маршрут к сети назначения, через единственны шлюз. Данный функционал реализуем в Policy Routing — маршрутизации на основе адреса отправителя пакета. Это наиболее распространенный и часто применяемый метод маршрутизации. При этом, в правилах отбираются пакеты на основании принадлежности хоста-отправителя заданной в правиле подсети.
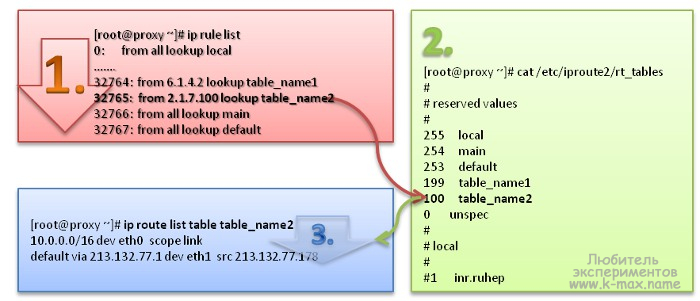
Давайте рассмотрим работу Routing Policy в схеме и разберем порядок работы:
1. Правила (rules)
Как видно, при маршрутизации первый элемент, через который проходит пакет — это набор правил. Каждое правило состоит из критерия отбора пакетов — своеобразный «фильтр» (например, from 2.1.7.100 — отбирает все пакеты с адресом отправителя 2.1.7.100) и действия над «подходящим» пакетом (например, lookup table_name2 — направляет пакет в таблицу маршрутизации с именем table_name2. Дословно: просмотреть table_name2).
При этом, каждый фильтр/критерий может состоять из указания исходного адреса, адреса получателя, входящего интерфейса, TOS и fwmark (поле TOS задает тип сервиса, что это и с чем его едят я ответить не готов, но могу направить в RFC 1349, fwmark — это метки, которые можно задать силами iptables/netfilter).
Действие, применяемое к пакету может возвращать неудачный результат, когда маршрут в заданной таблице не найден, в таком случае пакет переходит к следующему правилу. При создании правила маршрутизации можно задать определенное действие над пакетом (не только направить в заданную таблицу). Действия подразделяются на следующие типы:
- unicast (lookup) — просмотр указанной таблицы маршрутизации, если при создании правила не указан тип, то используется данный тип.
- nat — правило преобразовывает адрес отправителя, без запоминания состояния соединения! (обычно используется совместно с соответствующей записью, маршрутизирующей данный пакет)
- unreachable — выбросить пакет и вернуть сообщение ICMP о недоступности сети
- prohibit — выбросить пакет и вернуть сообщение ICMP о запрещении доступа
- blackhole — молча выбросить пакет (дословно — черная дыра)
Каждое правило имеет свой приоритет от 0 до 32767, в соответствии с которым ядро просматривает данные правила. При старте системы по умолчанию создаются следующие правила:
Правило с приоритетом 0 (ноль) действует для всех пакетов (from all) и направляет в таблицу маршрутизации local. Таблица local — специальная таблица маршрутизации, содержащая высокоприоритетные маршруты управления для локальных и широковещательных адресов. Правило 0 (ноль) является особенным, оно не может быть удалено или переопределено.
Правило с приоритетом 32766 действует так же для всех пакетов (from all) и направляет в таблицу main. Таблица main — основная таблица маршрутизации, содержащая все маршруты не имеющие политик (то есть работающие по классическому принципу — месту назначения пакета) . Это правило может быть удалено или переопределено в других (вышестоящих) правилах.
Правило с приоритетом 32767 действует так же для всех пакетов (from all) и направляет в таблицу default. Таблица default — по-умолчанию пуста и зарезервирована для использования. Может применяться для назначения маршрутов по умолчанию для пакетов, не направленных куда-либо в предыдущих правилах. Правило может быть удалено.
При добавлении правила в ручную, без указания приоритета (параметр priority), новые правила будут получать номер с 32765 до 1.
Очень важно понимать разницу между правилом и таблицей маршрутизации. Правило маршрутизации указывает на таблицу. Несколько правил могут отправлять пакет к одной таблице маршрутизации. При этом, некоторые таблицы маршрутизации могут быть БЕЗ правила, указывающего на них (читай — могут не использоваться).
Управление правилами осуществляется с помощью команды ip с ключом rule. Вот некоторые примеры:
2. Таблицы маршрутизации
Итак, следующим шагом на пути пакета по сетевой подсистеме ядра будет таблица маршрутизации, в которую пакет будет направлен соответствующим правилом. Ядро использует несколько таблиц маршрутизации с номерами от 1 до 255. Сопоставление номеров таблиц к их именам задается в файле /etc/iproute2/rt_tables. Фактически, задавать имена таблиц их номерным идентификаторам нет необходимости (в правилах можно просто использовать номера таблиц). По умолчанию при создании маршрута в Linux, если не задано имя таблицы, то используется таблица с ID 254 (main). Кроме таблицы main в ядре зарезервированы следующие имена:
Про main я уже сказал, но в ядре существует так же не менее важная таблица local с ID 255, которая состоит из маршрутов для локальных и широковещательных адресов. Ядро поддерживает эту таблицу автоматически, и администраторы никогда не должны изменять ее содержимое и нет необходимости даже в нее заглядывать при нормальном функционировании. Назначение таблицы default я описывал выше при описании правил. Таблица unspec — это «псевдо-таблица», которая содержит в себе правила ВСЕХ таблиц маршрутизации системы. Именно по этому у нее номер ноль, который не входит в диапазон с 1 по 255. Все таблицы маршрутизации ядра никак между собой не связаны , таким образом, у Вас может быть несколько идентичных маршрутов в различных таблицах, которые не будут конфликтовать. Нумерация таблиц большого значения не имеет. То есть все таблицы по сути имеют одинаковый вес и приоритет их определяется только заданными правилами.
Просмотреть содержимое таблицы можно командой ip (на примере таблицы main):
3. Маршруты/правила
Попадая в какую-либо таблицу маршрутизации, пакет «просматривает» последовательно каждое правило. На данном шаге, дальнейшее направление пакета никак не отличается от «классического» определения маршрута по адресу назначения. Если в текущей таблице маршрут для пакета не обнаружен, то он (пакет) возвращается в базу данных маршрутизации на основе политик к следующему правилу. Стоит обязательно отметить, что существуют разные типы маршрутов (которые очень похожи с типами правил, но правила стоят несколько «выше» маршрутов):
- unicast — обычный маршрут, определяет исходящий интерфейс и адрес следующего хопа для подсети/хоста назначения.
- unreachable — пакет выбрасывается и посылается ICMP сообщение «host unreachable».
- blackhole — пакет просто выбрасывается без возвращения какого-либо сообщения.
- prohibit (дословно — запрещен) — пакет выбрасывается и посылается ICMP сообщение «administratively prohibited».
- local — место назначения данного маршрута — локальный хост. В этом маршруте пакеты перемещаются локально.
- broadcast — пакет пересылается в виде широковещательного сообщения
- throw — специальный управляющий маршрут, используется совместно с правилами маршрутизации; Если пакет будет соответствовать данному маршруту, то поиск в этой таблице завершается, эмитируя что для данного пакета маршрут не найден и возвращается в RPDB для обработки в следующем правиле.
- nat — адреса сети назначения преобразуются в соответствии с параметром via; маршрутизатор также обслуживает ARP запросы для этой сети; не предназначен для сжатия адресного пространства или разделения нагрузки; в частности, не хранит таблицу соединений и не заглядывает внутрь пакета; можно использовать при перенумерации сети; для обратного преобразования необходимо задать дополнительное правило маршрутизации «ip rule add from реальный-адрес nat виртуальный-адрес».
- anycast — локальные адреса, которые нельзя использовать в качестве адресов источника. (непонятный мне тип маршрута)
- multicast — Специальный тип, используемый для многоадресной маршрутизации. Он не присутствует в статичных таблицах маршрутизации.
Управление правилами в таблице маршрутизации осуществляется с помощью команды ip с ключом route.
Выбор IP-адреса для исходящих соединений
Выбор локального адреса для исходящих соединений в большинстве случаев системой осуществляется автоматически, исходя из имеющихся IP-адресов интерфейсов и таблиц маршрутизации. Во многих случаях сетевые сервисы (веб-сервер, почтовый сервер и др.) позволяют указывать исходный адрес с помощью конфигурационных файлов. Давайте рассмотрим пример. Пусть система имеет два интерфейса eth0(192.168.1.1/24) и eth1(192.168.56.102/24):
Маршрут по умолчанию у данной системы — 192.168.56.1:
При такой конфигурации для исходящих соединений будет использоваться интерфейс eth1 и IP-адрес 192.168.56.102 (кроме соединений с узлами сети 192.168.1.0/24 — eth0 и IP-адрес 192.168.1.1). Ниже показан дамп сетевого пакета, отправленного командой ping -c 1 192.168.3.4:
Однако, если добавить альтернативный маршрут для сети 192.168.3.0/24 через некоторый шлюз 192.168.1.254:
то, для пакетов, предназначенных узлу 192.168.3.4, будет использоваться интерфейс eth0 и исходящий адрес 192.168.1.1 (показан дамп сетевого пакета):
Синтаксис команды ip route позволяет повлиять на выбор локального IP-адреса при соединении с удаленными системами. Для этого служит параметр src с указанием предпочитаемого IP-адреса (должен быть установлен на сетевом интерфейсе компьютера) для отправки пакетов на направление, определяемое в команде префиксом маршрутизации. Так, для указанной ниже конфигурации будет использоваться исходящий адрес 192.168.56.102 (кроме взаимодействия с узлами сети 192.168.1.0/24):
Для того, чтобы использовать исходный адрес 192.168.1.10 для соединения с узлами сети 192.168.3.0/24 следует использовать команду:
Таблица маршрутизации при этом будет иметь вид:
Добавление альтернативного маршрута для «избранных» хостов
Рассмотрим классический пример, когда в локальной сети необходимо направить избранные хосты по альтернативному маршруту. Предположим, что в локальной сети 10.0.0.0/24 имеется некоторый шлюз с двумя интерфейсами, имеющими IP-адреса 10.0.0.1/24 — смотрит в локальную сеть, 12.13.14.15/24 — смотрит в глобальную сеть. Маршрут по умолчанию проходит через IP 12.13.14.1. При этом необходимо, чтобы хост 10.0.0.100 был направлен по маршруту 12.13.14.100. Для решения этой задачи, необходимо:
Добавить описание дополнительной таблицы маршрутизации в файл /etc/iproute2/rt_tables (это действие необязательно, можно использовать просто номер таблицы)
Добавить правило, которое будет направлять пакеты с адресом отправителя 10.0.0.100 в описанную на прошлом шаге таблицу маршрутизации
Добавить новый маршрут по умолчанию, отправляющий пакеты на хост 12.13.14.100 в новую таблицу маршрутизации
Давайте рассмотрим путь пакета, согласно наших правил. Хост 10.0.0.100 отправляет пакет некоторому узлу 7.8.9.10, соответственно, в заголовках пакета источник — 10.0.0.100, назначение — 7.8.9.10. На хосте 10.0.0.100 шлюз по умолчанию — 10.0.0.1, согласно данного правила пакет попадает на шлюз 10.0.0.1. Ядро, получив пакет последовательно с нулевого правила просматривает соответствие пакета заданным в правилах фильтрам/критериям. Пакет подходит под действие правила 0 (0: from all lookup local) и направляется в таблицу маршрутизации local. Но т.к. пакет не принадлежит локальной системе и он не широковещательный, то маршрут в данной таблице не найден и пакет возвращается в RPDB для просмотра следующего правила. Следующее правило на пути пакета — 32765: from 10.0.0.100 lookup newtable. Пакет под критерии данного правила подходит, поэтому направляется в таблицу newtable (id 100). Согласно данной таблицы все пакеты направляются на единственный маршрут по умолчанию — 12.13.14.100. Пакет уходит согласно этого правила на указанный хост. Следующие правила не обрабатываются. Обращаю внимание, что в данном разборе я не учитывал прохождение пакета через таблицы netfilter.
Краткие итоги
В статье я рассмотрел работу механизма Routing Policy DataBase (RPDB) — маршрутизации на основе политик. Я долго вникал в работу этого механизма и постарался изложить свое понимание всего происходящего в ядре. Доходчивой документации на русском языке по данному вопросу в сети я не нашел. Даже всеми хваленый LARTC не дает прозрачного понимания RPDB. Надеюсь, что мои мысли помогут вам понять основные принципы. Подводя итог всему вышесказанному можно свести основной смысл к тому, что пакет в порядке приоритета правил (от 0 до 32767) сверяется с каждым правилом и в случае, если подходит под заданные условия, над пакетом совершается какое-либо действие (обычно отправляется в указанную таблицу). Если пакет в заданной таблице находит свой маршрут, то он отправляется по заданному маршруту. Если не находит — возвращается к списку правил для обработки в следующем правиле. Управление всем этим делом осуществляется командой ip с различными параметрами. В дальнейших статьях я постараюсь рассмотреть более интересные примеры реализации маршрутизации на основе политик. Кроме того, я бы обязательно посоветовал вам почитать приведенные ниже ссылки для более глубокого ознакомления.
Как использовать команду ip в Linux
Вы можете настроить IP-адреса, сетевые интерфейсы и правила маршрутизации на лету с помощью команды Linux ip. Мы покажем вам, как вы можете использовать эту современную замену классическому (и теперь устаревшему) ifconfig.
Как работает команда ip
С помощью команды ip вы можете настроить способ, которым компьютер Linux обрабатывает IP-адреса, контроллеры сетевых интерфейсов (NIC) и правила маршрутизации. В дополнении к этому, изменения вступают в силу немедленно — вам не нужно перезагружаться. Команда ip может сделать намного больше, чем это, но в этой статье мы сосредоточимся на наиболее распространённых случаях использования.
Команда ip имеет много подкоманд, каждая из которых работает с типом объекта, таким как IP-адреса, маршруты и т.д. В свою очередь, имеется много вариантов для каждого из этих объектов. Именно это богатство функциональности даёт команде ip гранулярность, необходимую для выполнения сложных задач.
Объекты, с которыми работает команда ip
Общий синтаксис команды ip следующий:
ОБЪЕКТАМИ в команде ip являются:
- address: управление адресом (IP или IPv6 протокола) на устройстве
- addrlabel: конфигурация меток для выбора адреса протокола
- l2tp: туннель ethernet через IP (L2TPv3)
- link: настройка сетевых устройств
- maddress: управление многоадресными адресами
- monitor: мониторит состояние, следит за сообщениями netlink
- mroute: запись кэша многоадресной маршрутизации
- mrule: правило в базе данных политики многоадресной маршрутизации
- neighbour: управлять записями кэша ARP или NDISC.
- netns: управление сетевым пространством имён
- ntable: управлять работой кэша neighbor
- route: записи в таблице маршрутизации
- rule: управление базой данных политики маршрутизации
- tcp_metrics/tcpmetrics: управление метриками TCP
- token: управлять идентификаторами интерфейса токена
- tunnel: настройка туннелей через IP
- tuntap: управление устройствами TUN/TAP
- xfrm: управление политиками IPSec
Мы рассмотрим следующие объекты:
- address (адрес): IP-адреса и диапазоны.
- link: сетевые интерфейсы, такие как проводные соединения и адаптеры Wi-Fi.
- route (маршрут): правила, управляющие маршрутизацией трафика, отправляемого на адреса через интерфейсы (link).
- monitor: (мониторинг): наблюдение за происходящим с сетевыми интерфейсами
Использование ip с адресами
Очевидно, что сначала вы должны знать настройки, с которыми вы имеете дело. Чтобы узнать, какие IP-адреса у вашего компьютера, используйте команду ip с объектом address. Действием по умолчанию является show, которое перечислит IP-адреса. Вы также можете опустить show и сокращать написание address до «addr» или даже до «a».
Все следующие команды эквивалентны:

Мы видим два IP-адреса, а также много другой информации. IP-адреса связаны с контроллерами сетевого интерфейса (NIC). Команда ip пытается быть полезной и предоставляет много информации об интерфейсе.
Первый IP-адрес — это (внутренний) петлевой адрес, используемый для связи внутри компьютера. Второй фактический (внешний) IP-адрес, который компьютер имеет в локальной сети (LAN).
Кроме петлевого интерфейса lo, также имеются следующие:
- enp3s0 — физический интерфейс проводного сетевого подключения. В некоторых дистрибутивах Linux по умолчанию называется eth0.
- wlo1 — физический интерфейс беспроводного сетевого подключения. В некоторых дистрибутивах Linux по умолчанию называется wlan0.
- vboxnet0 — виртуальный интерфейс, созданный программой VirtualBox для организации локальной сети между виртуальными машинами (смотрите Виртуальные машины в одной сети, изолированные от других сетей).
- tun0 — программный интерфейс для создания туннеля между двумя компьютерами. В данном случае этот интерфейс создан программой OpenVPN.
Давайте разберём всю информацию, которую мы получили по первому интерфейсу:
- lo: Имя сетевого интерфейса в виде строки.
- <LOOPBACK,UP,LOWER_UP>: это петлевой интерфейс. Здесь указано UP, что означает, что он работает. Физический сетевой уровень (первый уровень) также работает, об этом говорит LOWER_UP.
- mtu 65536: максимальная единица передачи. Это размер наибольшего фрагмента данных, который может передавать этот интерфейс.
- qdisc noqueue: qdisc — это механизм организации очередей. Планирует передачу пакетов. Существуют различные методы очередей, называемые дисциплинами. Дисциплина noqueue означает «отправляй мгновенно, не ставь в очередь». Это стандартная дисциплина qdisc для виртуальных устройств, например адресов LOOPBACK.
- state UNKNOWN: могут быть такие состояния как DOWN (сетевой интерфейс не работает), UNKNOWN (сетевой интерфейс работает, но ничего не подключено) или UP (сеть работает и соединение установлено).
- group default: интерфейсы могут быть сгруппированы логически. По умолчанию они помещаются в группу под названием «default».
- qlen 1000: максимальная длина очереди передачи.
- link/loopback: адрес управления доступом к среде (MAC) интерфейса.
- inet 127.0.0.1/8: IP-адрес версии 4. Часть адреса после косой черты (/) представляет собой нотацию бесклассовой междоменной маршрутизации (CIDR), представляющую маску подсети. Она указывает, сколько ведущих непрерывных битов имеют значение единица в маске подсети. Значение восемь означает восемь битов. Восемь битов, равных единице, представляют 255 в двоичном виде, поэтому маска подсети равна 255.0.0.0. Более подробно об IP адресе и подсетях смотрите в статье «IP адрес».
- scope host: область IP-адреса. Этот IP-адрес действителен только внутри компьютера («хост»).
- lo: интерфейс, с которым связан этот IP-адрес.
- valid_lft: допустимое время жизни. Для IP-адреса версии 4 IP, назначенного протоколом динамической конфигурации хоста (DHCP), это период времени, в течение которого IP-адрес считается действительным и может создавать и принимать запросы на подключение.
- preferred_lft: предпочтительное время жизни. Для IP-адреса версии 4, выделенного протоколом DHCP, это количество времени, в течение которого IP-адрес может использоваться без ограничений. Оно никогда не должно быть больше значения valid_lft.
- inet6: IP-адрес версии 6, оvalid_lft и preferred_lft.
Физические интерфейсы, как мы покажем ниже, более интересны. Рассмотрим два физических интерфейса: один из них не задействован (провод не подключён), а второй используется (беспроводной Wi-Fi адаптер).
Неиспользуемый сетевой интерфейс:
- enp3s0: имя сетевого интерфейса в виде строки. «en» обозначает Ethernet, «p3» — номер шины карты Ethernet, а «s0» — номер слота.
- <NO-CARRIER,BROADCAST,MULTICAST,UP>: NO-CARRIER означает, что сетевой разъем не обнаруживает сигнал на линии. Обычно это происходит потому, что сетевой кабель отключён или повреждён. В редких случаях это также может быть аппаратный сбой или ошибка драйвера. В моём случае просто не подключён сетевой кабель UP означает, что устройство работает. BROADCAST — устройство может отправлять трафик всем хостам по link. MULTICAST — устройство может выполнять и принимать многоадресные пакеты.
- mtu 1500: максимальная единица передачи, поддерживаемая этим интерфейсом.
- qdisc fq_codel: FQ_Codel (управляемая задержка честной очереди) — это дисциплина очередей, которая объединяет честную очередь со схемой CoDel AQM. FQ_Codel использует стохастическую модель для классификации входящих пакетов в разные потоки и используется для обеспечения справедливой доли пропускной способности для всех потоков, использующих очередь. Каждый такой поток управляется дисциплиной очередей CoDel. Переупорядочение внутри потока исключается, поскольку Codel внутренне использует очередь FIFO.
- state DOWN: интерфейс не работает и не подключён.
- group default: этот интерфейс входит в интерфейсную группу «default».
- qlen 1000: максимальная длина очереди передачи.
- link/ether 4c:ed:fb:da:53:3c brd ff:ff:ff:ff:ff:ff: MAC-адрес интерфейса.
Используемый сетевой интерфейс:
- wlo1: имя сетевого интерфейса в виде строки.
- <BROADCAST,MULTICAST,UP,LOWER_UPP>: этот интерфейс поддерживает широкополосную и многоадресную рассылку, и интерфейс в состоянии UP (работает). Физический (аппаратный) уровень сети (уровень один) также в состоянии UP.
- mtu 1500: максимальная единица передачи, поддерживаемая этим интерфейсом.
- qdisc noqueue: Дисциплина noqueue означает «отправляй мгновенно, не ставь в очередь».
- state UP: интерфейс работает и подключён.
- group default: этот интерфейс входит в интерфейсную группу «default».
- qlen 1000: максимальная длина очереди передачи.
- link/ether: MAC-адрес интерфейса.
- inet 192.168.0.89/24: IP-адрес версии 4. «/24» говорит нам, что в маске подсети установлено 24 смежных старших бита, равных единице. Это три группы по восемь битов. Восьмибитовое двоичное число равно 255; следовательно, маска подсети 255.255.255.0.
- brd 192.168.0.255: широковещательный адрес для этой подсети.
- scope global: IP-адрес действителен везде в этой сети.
- dynamic: IP-адрес теряется при отключении интерфейса.
- noprefixroute: не создавать маршрут в таблице маршрутов при добавлении этого IP-адреса. Кто-то должен добавить маршрут вручную, если он хочет использовать его с этим IP-адресом. Аналогично, если этот IP-адрес удалён, не искать маршрут для удаления.
- wlo1: интерфейс, с которым связан этот IP-адрес.
- valid_lft: допустимое время жизни. Время, когда IP-адрес будет считаться действительным; 77599 секунд — это 21 час 33 минуты.
- preferred_lft: предпочтительное время жизни. Это время, которое IP-адрес будет работать без каких-либо ограничений.
- inet6: IP-адрес версии 6, scope link, valid_lft и preferred_lft.
Отображать только адреса IPv4 или IPv6
Если вы хотите ограничить вывод IP-адресами версии 4, вы можете использовать опцию -4 следующим образом:
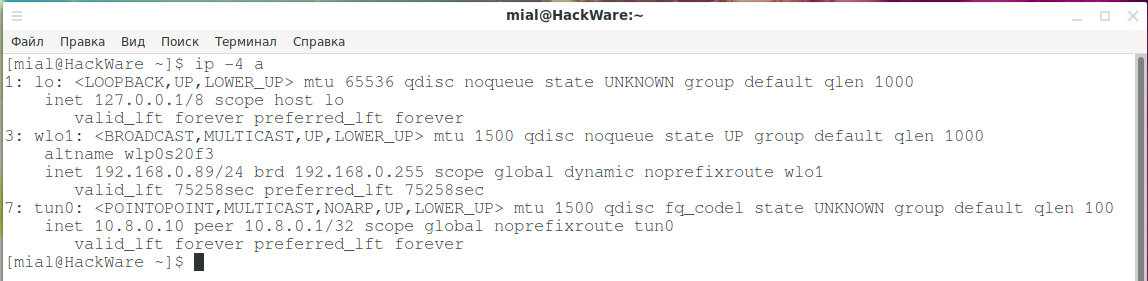
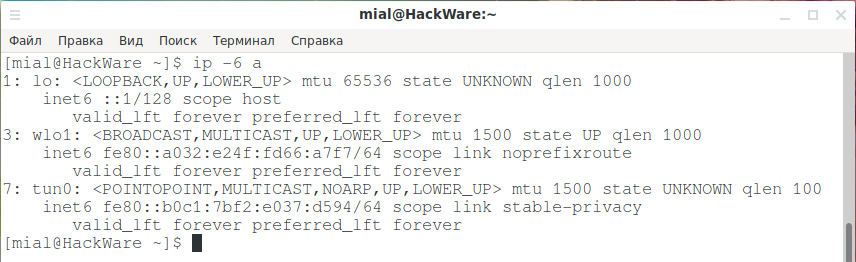
Если вы хотите ограничить вывод IP-адресами версии 6, вы можете использовать опцию -6 следующим образом:
Отображение информации для одного интерфейса
Если вы хотите просмотреть информацию об IP-адресе для одного интерфейса, вы можете использовать параметры show и dev и название интерфейса, как показано ниже:
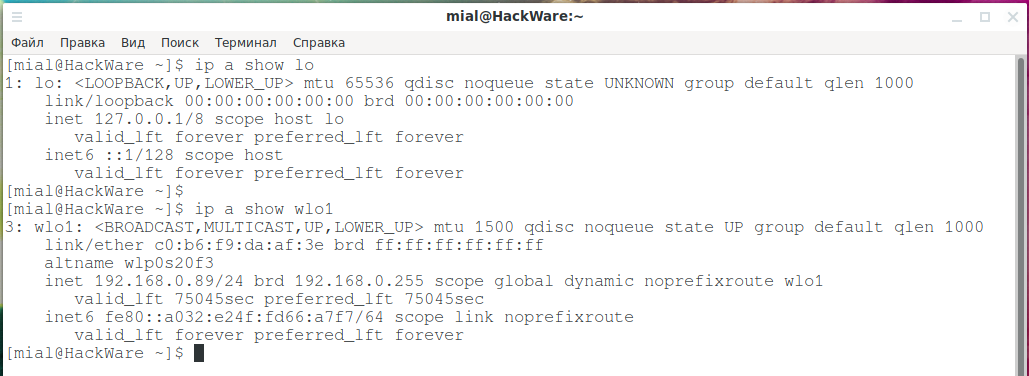
Можно пропустить строку dev:

Вы также можете использовать флаг -4 или -6 для дальнейшего уточнения вывода, чтобы видеть только то, что вас интересует.
Если вы хотите увидеть информацию IP версии 4, связанную с адресами в интерфейсе wlo1, введите следующую команду:
Как добавить IP адреса
Вы можете использовать опции add и dev для добавления IP-адреса в интерфейс. Вам просто нужно указать команде ip, какой IP-адрес и к какому интерфейсу добавить.
Мы собираемся добавить IP-адрес 192.168.0.33 в интерфейс wlo1. Мы также должны предоставить нотацию CIDR для маски подсети. Мы вводим следующее:
Мы вводим следующее, чтобы ещё раз взглянуть на IP-адреса IP версии 4 на этом интерфейсе:

Новый IP-адрес присутствует в этом сетевом интерфейсе. Мы переходим на другой компьютер и используем следующую команду, чтобы проверить, можем ли мы пропинговать новый IP-адрес:

IP-адрес отвечает и отправляет подтверждения пингам. Наш новый IP-адрес запущен и работает после одной простой команды ip.
Удаление IP-адреса
Для удаления IP-адреса команда почти такая же, как и для добавления, за исключением того, что вы заменяете add на del, как показано ниже:
Если мы введём следующее для проверки, мы увидим, что новый IP-адрес был удалён:
Как просмотреть статистику использования трафика сетевыми интерфейсами
Чтобы увидеть статистику полученных и отправленных данных каждым интерфейсом, используйте опцию -s:
Причём опцию -s можно использовать 2 и более раз, если вы хотите более подробную информацию:
Если вы хотите, чтобы данные выводились в удобном для восприятия виде, то укажите опцию -h:
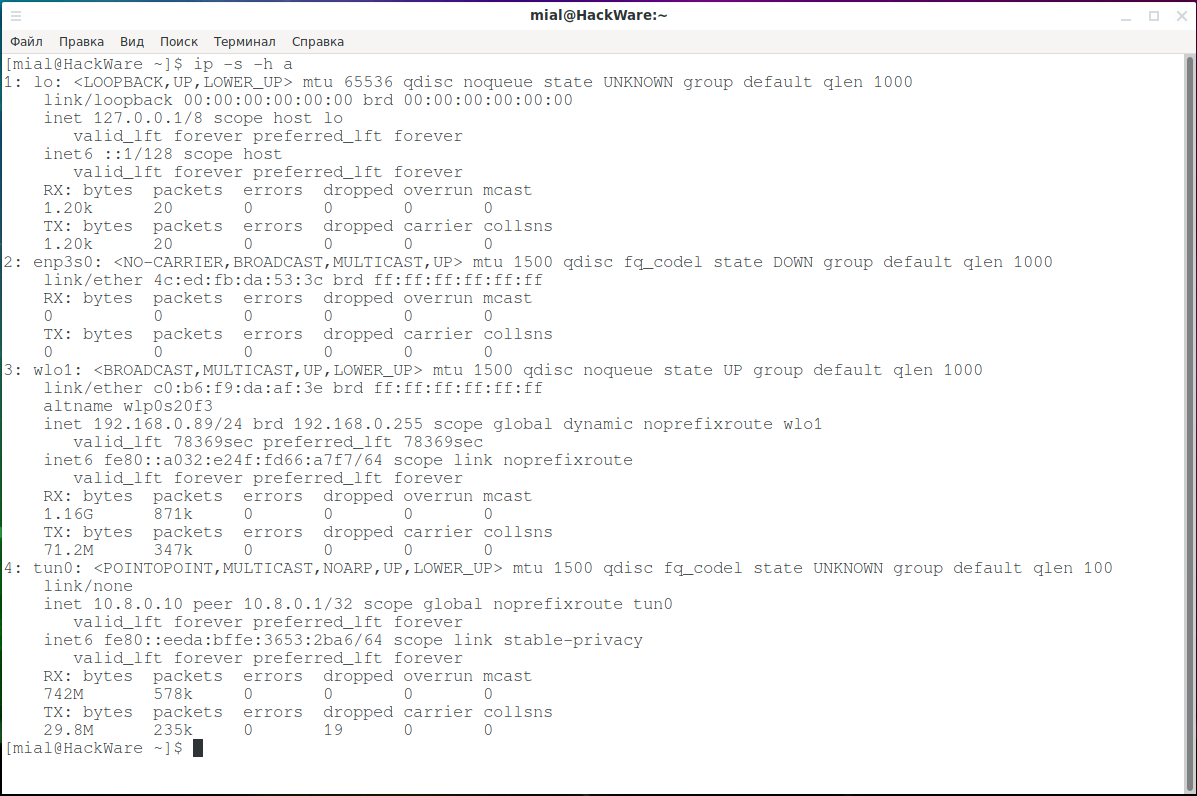
Смотрите также очень интересный пример использования команды ip «Просмотр статистики трафика в реальном времени».
Использование ip для управления сетевыми интерфейсами
Объект link используется для проверки и работы с сетевыми интерфейсами. То есть работа осуществляется не на уровне логического IP адреса, а на уровне сетевой карты как аппаратного оборудования. На уровне IP протокола мы выполняем различные операции с IP адресом, а на аппаратном уровне мы включаем и отключаем сетевые интерфейсы, меняем MAC адрес, добавляем и удаляем аппаратные сетевые интерфейсы и делаем другую настройку сетевых интерфейсов. Смотрите также «Как поменять MAC-адрес в Linux, как включить и отключить автоматическую смену (спуфинг) MAC в Linux».
Введите следующую команду, чтобы увидеть интерфейсы, установленные на вашем компьютере:

Чтобы увидеть информацию только по одному определённому сетевому интерфейсу, просто добавьте его имя в команду, как показано ниже:
Включение и отключение link (сетевых устройств)
Вы можете использовать опцию set с опцией up или down для включения или остановки сетевого интерфейса. Вы также должны использовать sudo как показано ниже:
Мы вводим следующее, чтобы снова взглянуть на сетевой интерфейс:
Состояние сетевого интерфейса DOWN. Мы можем использовать опцию up для перезапуска сетевого интерфейса, как показано ниже:
Мы вводим следующее, чтобы выполнить ещё одну быструю проверку состояния сетевого интерфейса:

Сетевой интерфейс был перезапущен, и состояние отображается как UP.
Использование ip с маршрутами
С помощью объекта route вы можете проверять маршруты и управлять ими. Правила маршрутизации определяют, на какой сетевой интерфейс отправляется сетевой трафик в зависимости от целевого IP-адреса. Смотрите также
- Практика настройки сетевых маршрутов: выбор подключения, используемое для Интернета; одновременное использование нескольких подключений для разных целей
- Как в Windows выбрать подключение, используемое для Интернета
Если сетевой пакет предназначен устройству, которое непосредственно подключено к отправителю, то путь пакета очевиден — этот пакет отправляется напрямую получателю. Но во всех других случаях необходимо принять решение, через какой сетевой интерфейс нужно отправить трафик. Самый частый пример, с которым многие из нас сталкиваются каждый день, это роутер: если он получил сетевой пакет, предназначенный для локального IP адреса, то он отправляет его через LAN интерфейс, если же пакет предназначен для Глобальной сети (или просто IP не входит в домашнюю локальную сеть), то такой пакет отправляется через WAN интерфейс. Эти правила и являются правилами маршрутизации. Всего различают две группы правил:
- правила для определённых IP и диапазонов сетей
- правила для всего остального трафика, который не упомянут в предыдущих правилах — все такие сетевые пакеты отправляются по маршруту по умолчанию
Чтобы просмотреть маршруты, установленные на вашем компьютере, введите следующую команду:
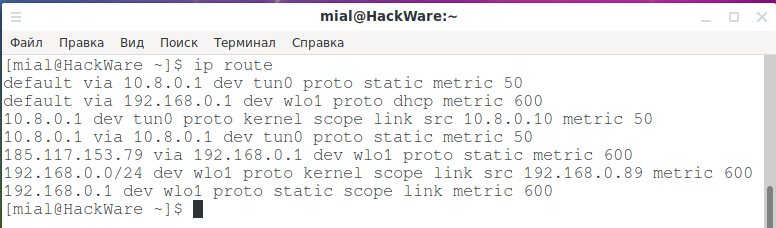
На скриншоте отражены правила маршрутизации для одного сетевого соединения, работающего через OpenVPN.
Начнём с разбора строки:
Давайте посмотрим на информацию, которую мы получили:
- default: правило по умолчанию. Этот маршрут используется, если ни одно из других правил не соответствует отправляемому. Маршрутов по умолчанию может быть несколько (на скриншоте выше их два), но у них должно быть разное значение метрики, для установки приоритета, то есть какой из них должен использоваться в первую очередь.
- via 192.168.0.1: маршрутизирует пакеты через устройство на 192.168.0.1. Это IP-адрес маршрутизатора по умолчанию в этой сети.
- dev wlo1: использовать этот сетевой интерфейс для отправки пакетов на маршрутизатор.
- proto dhcp: идентификатор протокола маршрутизации. DHCP означает, что маршруты будут определены динамически.
- metric 600: указание предпочтения маршрута по сравнению с другими. Маршруты с более низкими показателями предпочтительнее, чем с более высокими показателями. Вы можете использовать это, чтобы выбрать для отправки данных интерфейс проводной сети, а не Wi-Fi (или наоборот), либо чтобы выбрать предпочитаемое беспроводное соединение, если у вас больше одной Wi-Fi карты.
- 192.168.0.0/24: диапазон IP-адресов, которым управляет это правило маршрутизации. Если компьютер обменивается данными в этом диапазоне IP-адресов, это правило запускает и контролирует маршрутизацию пакетов.
- dev wlo1: интерфейс, через который этот маршрут будет отправлять пакеты.
- proto kernel: маршрут, созданный ядром во время автоматической настройки
- scope link: область действия является ссылкой, что означает, что область действия ограничена непосредственной сетью, к которой подключён этот компьютер.
- src 192.168.0.89: IP-адрес, с которого отправляются пакеты, отправленные этим маршрутом.
- metric 600: метрика, определяющая (низкий) приоритет этого маршрута.
Как показать информацию только об одном маршруте
Если вы хотите сосредоточиться на деталях определённого маршрута, вы можете добавить в команду опцию list и диапазон IP-адресов маршрута следующим образом:
Добавление маршрута
Ранее мы получили следующий список маршрутов:
- wlo1 — физический беспроводной интерфейс
- tun0 — интерфейс созданный программно, для организации тоннеля OpenVPN
- 185.117.153.79 — адрес OpenVPN сервера, как можно увидеть, для него создано специальное правило, перенаправляющее трафик на этот IP адрес напрямую через физическое устройство wlo1, а не через tun0 (иначе не было бы подключения к серверу OpenVPN и ничего бы не работало)
- 192.168.0.0/24 — это локальная сеть
- 10.8.0.10 — это IP адрес интерфейса tun0, то есть IP в виртуальной частной сети OpenVPN, а 10.8.0.1 это IP адрес другой точки туннеля, по сути сервера OpenVPN в виртуальной частной сети (его внешний IP 185.117.153.79)
Предположим, я хочу подключаться к определённому IP или диапазонам IP адресов напрямую. Я хочу подключаться к 157.245.118.66 минуя OpenVPN, тогда мне достаточно установить явный маршрут для данного IP:
- 157.245.118.66 — IP, для которого создаётся маршрут
- 192.168.0.1 — IP адрес, куда должен отправиться пакет для этого маршрута
- wlo1 — физический интерфейс, который подключён к устройству, имеющему IP адрес 192.168.0.1
Добавление маршрута (присвоение новому интерфейсу IP и настройка маршрутизации)
Предположим, что мы только что добавили новую сетевую карту на этот компьютер. Мы набираем следующее и видим, что он отображается как enp0s8:
Мы добавим новый маршрут к компьютеру, чтобы использовать этот новый интерфейс. Сначала мы вводим следующее, чтобы связать IP-адрес с интерфейсом:
Маршрут по умолчанию с использованием существующего IP-адреса добавляется в новый интерфейс. Мы используем опцию delete и указываем его свойства, как показано ниже, чтобы удалить маршрут по умолчанию:
Теперь мы будем использовать опцию add, чтобы добавить наш новый маршрут. Новый интерфейс будет обрабатывать сетевой трафик в диапазоне IP-адресов 192.168.121.0/24. Мы дадим ему метрику 100; потому что это будет единственный маршрут, обрабатывающий этот трафик, метрика в значительной степени академическая.
Мы вводим следующее:
Теперь мы набираем следующее, чтобы увидеть, что мы получили в конечном счёте:
Наш новый маршрут уже на месте. Однако у нас все ещё есть маршрут 192.168.4.0/24, который указывает на интерфейс enp0s8 — мы набираем следующее, чтобы удалить его:
Теперь у нас должен быть новый маршрут, который направляет весь трафик, предназначенный для диапазона IP 192.168.121.0/24, через интерфейс enp0s8. Это также должен быть единственный маршрут, который использует наш новый интерфейс.
Мы вводим следующее для подтверждения:
Показ и настройка маршрутов для IPv6
Вы можете использовать параметры -4 и -6 для просмотра только маршрутов IPv4 или IPv6. По умолчанию отображаются только маршруты IPv4. Для просмотра маршрутов IPv6 используйте:
Для управления маршрутов IPv6 используйте показанные выше команды с опцией -6.
Все изменения являются временными
Самое замечательное в этих командах — они не постоянны. Если вы хотите очистить их, просто перезагрузите систему. Это означает, что вы можете экспериментировать с ними, пока они не будут работать так, как вы хотите. И это очень хорошо, если вы наделаете ужасный беспорядок в вашей системе — простая перезагрузка восстановит порядок и вернёт всё как было.
С другой стороны, если вы хотите, чтобы изменения были постоянными, вам нужно выполнить дополнительные действия. Что именно нужно сделать зависит от семейства дистрибутива, а также от того, используете ли вы графическое окружение рабочего стола. В безголовых серверах необходимо выполнить настройку конфигурационных файлов, в системах с графическим интерфейсом часть настройки может выполняться автоматически программами вроде NetworkManager, либо также может быть выполнена с помощью конфигурационных файлов.
Таким образом, вы можете протестировать команды перед тем, как сделать что-либо постоянным.
Мониторинг событий сетевых интерфейсов
Всё, что происходит с сетевыми интерфейсами в режиме реального времени можно наблюдать с помощью команды:
Эта команда покажет удаление и добавление маршрутов, изменение IP адресов, включение и отключение сетевых устройств и другие события.
Чтобы мониторить события, связанные с IPv6:
Управление таблицами соседей (ARP и NDP)
Эта команда поддерживает варианты написания как американского (ip neighbour), так и британского (ip neighbour) правописания.
Для просмотра таблиц соседей:
Все команды «show» поддерживают параметры -4 и -6 для просмотра только соседей IPv4 (ARP) или IPv6 (NDP). По умолчанию отображаются все соседи.