Как мне узнать кодировку имени файла? [закрыт]
Хотите улучшить этот вопрос? Переформулируйте вопрос так, чтобы он был сосредоточен только на одной проблеме.
Закрыт 4 года назад .
Как мне узнать кодировку имени файла? Подскажите программы под Windows и Linux. Также временами надо делать групповое переименование кодировки в именах и внутренностях файлов. Тоже нужна надёжная программа под Windows и Linux.
Про Linux не скажу, а для Windows с кодировкой все просто: все имена файловых объектов в NTFS хранятся в UTF-16.
Если же вам надо определять к какому национальному алфавиту принадлежит конкретное имя, то это надо анализировать коды символов (например, символы кириллицы имеют коды UTF-16 вида 04xx ). Смысла в этом не очень много, потому что в имени могут смешиваться символы любых алфавитов. Готовую программу для такого анализа найти будет сложно. А если писать самому, то тут в помощь только непосредственно материалы Unicode Consortium, в частности библиотека ICU.
![]()
Дизайн сайта / логотип © 2023 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2023.3.3.43278
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Автоопределение кодировки текста

Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandia\cpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется, получилось забавно.
| # | Кодировка | html/charset | saintfish/chardet | softlandia/cpd | enca |
|---|---|---|---|---|---|
| 1 | CP1251 | windows-1252 | CP1251 | CP1251 | CP1251 |
| 2 | CP866 | windows-1252 | windows-1252 | CP866 | CP866 |
| 3 | KOI8-R | windows-1252 | KOI8-R | KOI8-R | KOI8-R |
| 4 | ISO-8859-5 | windows-1252 | ISO-8859-5 | ISO-8859-5 | ISO-8859-5 |
| 5 | UTF-8 with BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 6 | UTF-8 without BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 7 | UTF-16LE with BOM | utf-16le | utf-16le | utf-16le | ISO-10646-UCS-2 |
| 8 | UTF-16LE without BOM | windows-1252 | ISO-8859-1 | utf-16le | unknown |
| 9 | UTF-16BE with BOM | utf-16le | utf-16be | utf-16be | ISO-10646-UCS-2 |
| 10 | UTF-16BE without BOM | windows-1252 | ISO-8859-1 | utf-16be | ISO-10646-UCS-2 |
| 11 | UTF-32LE with BOM | utf-16le | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 12 | UTF-32LE without BOM | windows-1252 | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 13 | UTF-32BE with BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 14 | UTF-32BE without BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 15 | KOI8-R (UPPER) | windows-1252 | KOI8-R | KOI8-R | CP1251 |
| 16 | CP1251 (UPPER) | windows-1252 | CP1251 | CP1251 | KOI8-R |
| 17 | CP866 & CP1251 | windows-1252 | CP1251 | CP1251 | unknown |
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
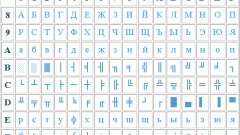
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
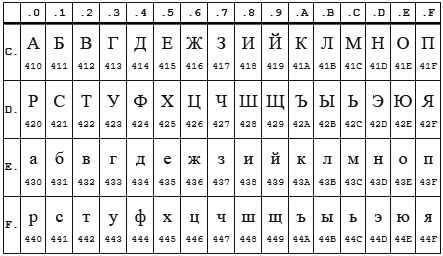
Таблица KOI8-r

В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед

Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Особенности, с которыми я столкнулся
Чуть коснусь прелестей и проблем, связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Излишне переживая и пытаясь дуть на воду, прослышав от других о страшных ожогах от молока, переборщил с проверкой входного параметра типа io.Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
Но как оказалось в моём случае достаточно проверить на nil. Теперь всё стало проще
вызов bufio.NewReader( r ).Peek(ReadBufSize) спокойно проходит следующий тест:
В этом случае Peek() возвращает ошибку.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно, очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные, имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно даёт результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение, когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Спасибо falconandy за конструктивные и полезные советы
Благодаря ему
- перевёл тесты на testify и они действительно стали более читабельны
- исправил в тестах пути к файлам данных для совместимости с Linux
- прошёлся линтером — таки он нашёл одну реальную ошибку (проклятущий copy/past)
Продолжаю добавлять тесты, выявился случай не определения UTF16. Обновил. Теперь UTF16 и LE и BE определяются даже в случае отсутствия русских букв
Как узнать кодировку файла windows

- Кодировка текста ASCII
- Как перевести абракадабру
- Как определить кодировку текста
- Как узнать кодировку текста
- Как узнать кодировку файла
- Как определить кодировку

- Как проверить кодировку

- Как раскодировать файлы

- Как подобрать кодировку

- Как узнать кодировку

- Контрольный список полноты кода ML

- Как расшифровать txt

- Как расшифровать файл
- Как расшифровать строку

- Как можно раскодировать

- Как расшифровать расширение файла
- Как определить символ

- Как дешифровать файлы

- Как интерпретировать данные, выводимые командой htop
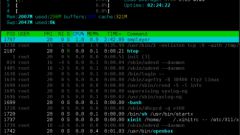
- Как восстановить кодировку

- Как узнать кодировку сайта

- Как сменить кодировку
- Как узнать код символа

- Как указать кодировку

- Как раскодировать закодированные данные

- Как определить открыт файл или нет

- Как открыть org файл

- Почему вместо букв показываются иероглифы


Способ 2: Online Decoder
- Воспользуйтесь ссылкой выше или самостоятельно откройте главную страницу сайта Online Decoder, где сразу же активируйте поле для ввода и вставьте туда целевой текст.
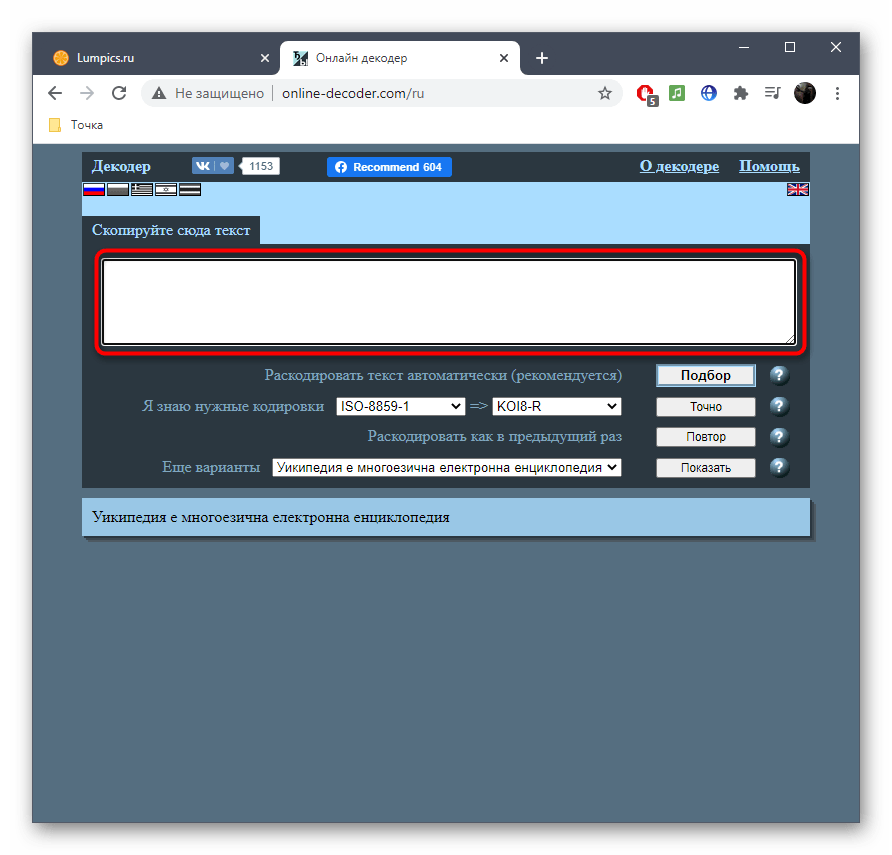
- Напротив пункта «Раскодировать текст автоматически (рекомендуется)» нажмите по кнопке «Подбор» для запуска процесса распознавания.
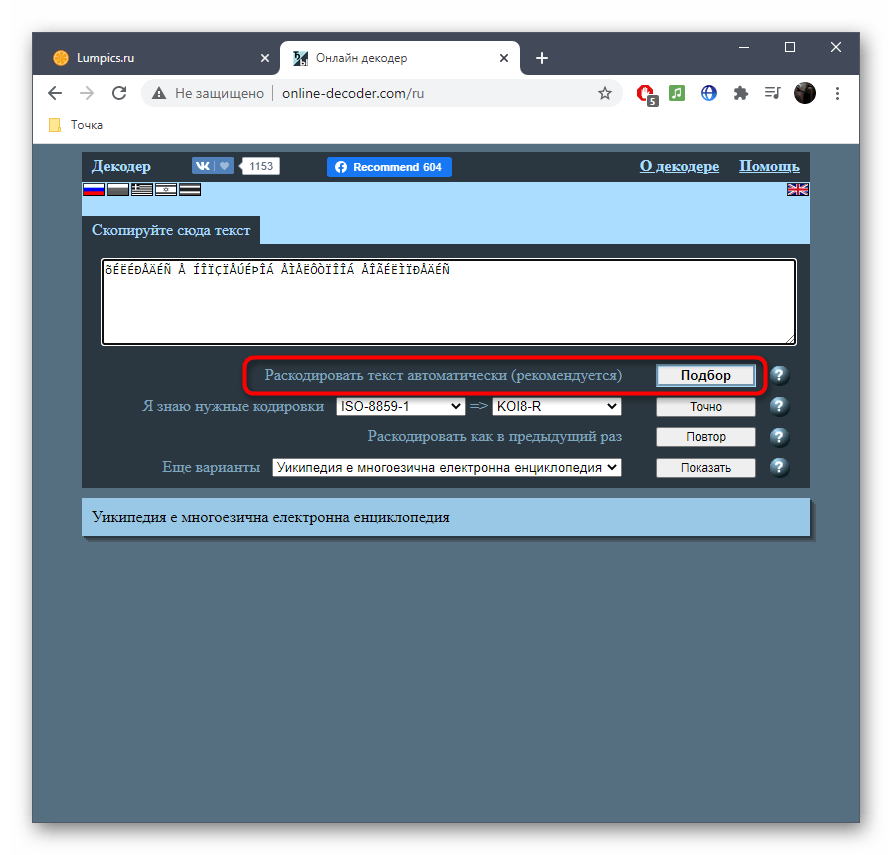
- Та кодировка, в которую выполнен перевод, отображается второй.
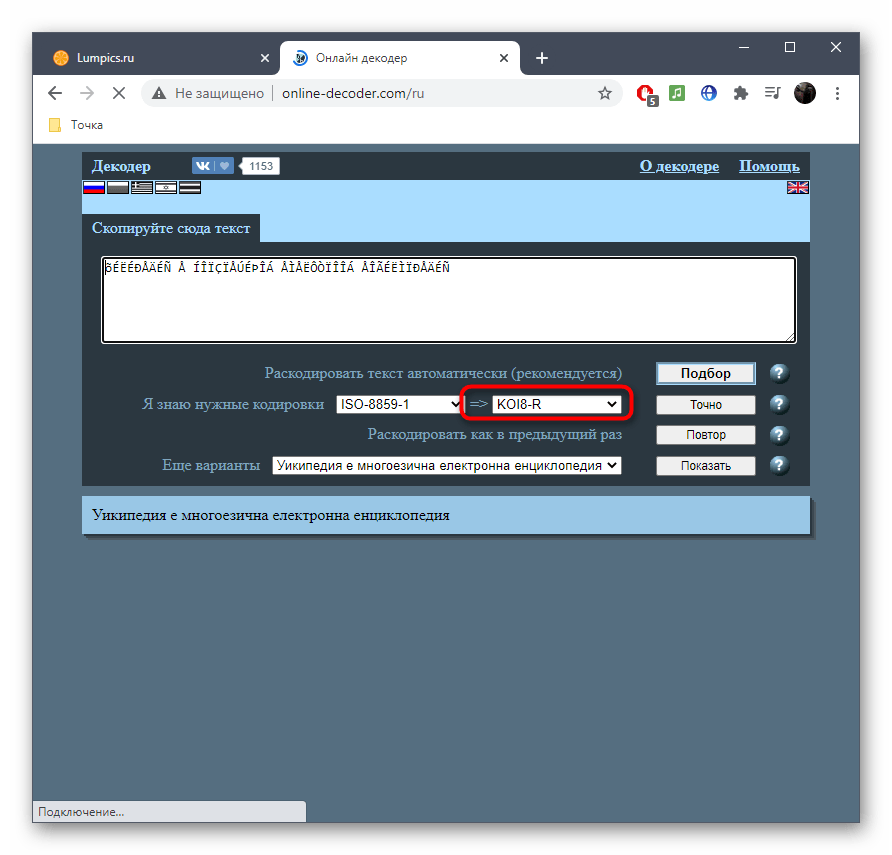
- Исходная находится прямо после надписи «Я знаю нужные кодировки». Ее и надо узнать, если речь идет об определении стилистики символов.


Способ 3: FoxTools
- Активируйте поле для ввода и вставьте туда скопированную ранее надпись.

- Снизу поля «Исходная кодировка» вы найдете кнопку «Определить», по которой и следует нажать для запуска процесса распознавания.
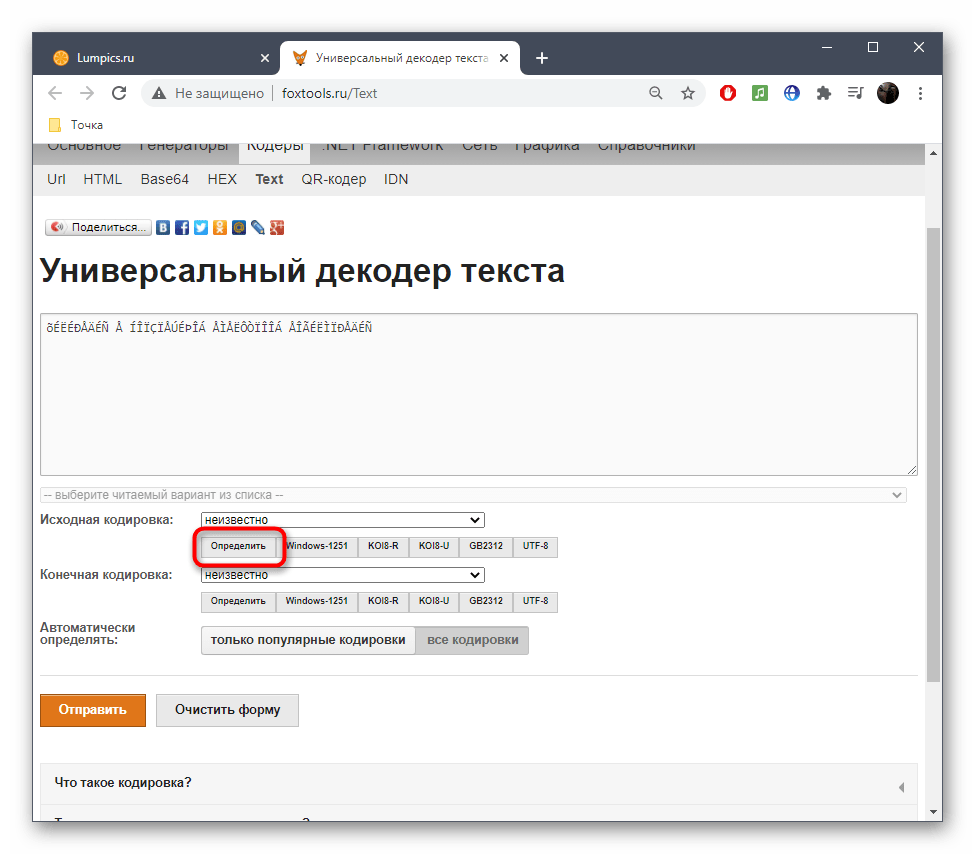
- Если параллельно осуществляется перевод в читаемый вид, выберите его из выпадающего меню сверху.

- Нажмите «Отправить», чтобы получить результат со всей необходимой информацией.
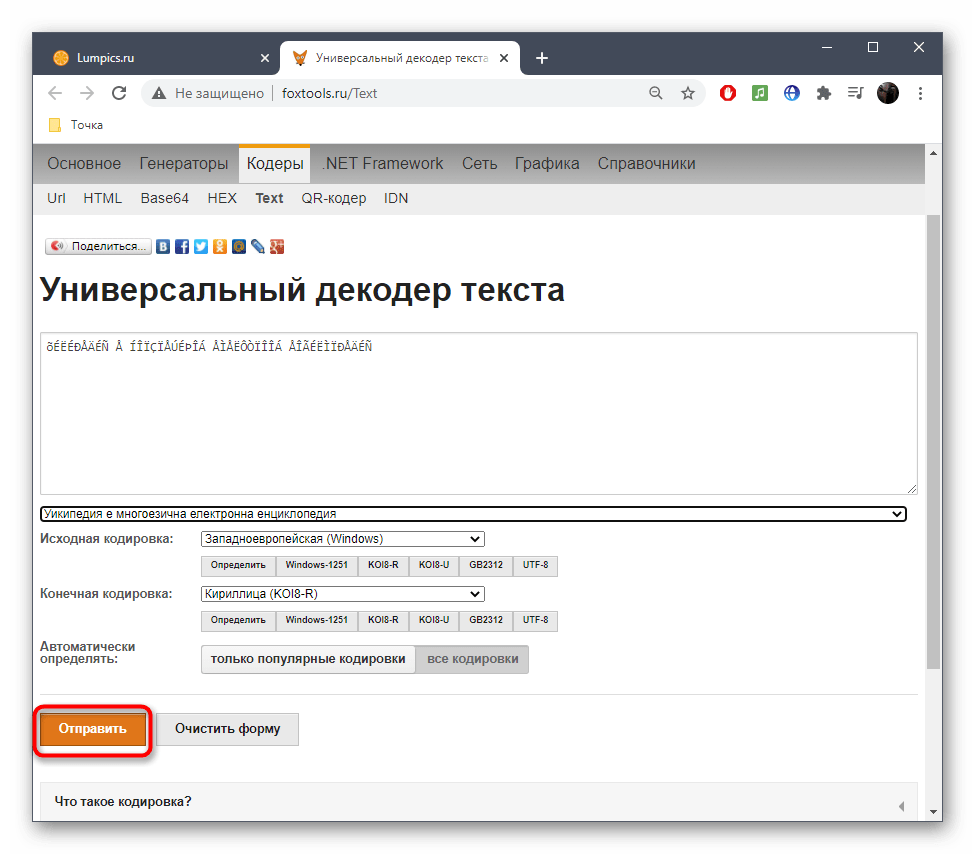
- Ознакомьтесь с параметром возле пункта «Исходная кодировка» для определения символьного набора. Если он отображен не в кодовом названии, найдите перевод через Википедию для общего понимания.

- Иногда FoxTools не распознает редко используемые кодировки, поэтому потребуется переключиться в режим «Все кодировки» и повторить процедуру подбора.

 Мы рады, что смогли помочь Вам в решении проблемы.
Мы рады, что смогли помочь Вам в решении проблемы.
Определение кодировки онлайн
Основное предназначение онлайн-сервиса 2cyr заключается в декодировании определенного отрывка текста, однако это не помешает использовать встроенные в него инструменты для определения кодировки, для чего потребуется только скопировать небольшую надпись.
- В самом декодере вставьте скопированный текст в соответствующую форму, используя контекстное меню или горячую клавишу Ctrl + V.
- Убедитесь в том, что текст был успешно добавлен, а затем в поле «Выберите кодировку» установите значение «Автоматически (рекомендуется)». Подтвердите распознавание, нажав по кнопке «ОК», которая расположена справа.

Ничего не помешает сохранить или запомнить этот онлайн-сервис и обращаться к нему в те моменты, когда требуется перевести кодировку или снова определить ее. Если же этот вариант не подходит, переходите к рассмотрению следующих сайтов.
Способ 2: Online Decoder
Онлайн-сервис под названием Online Decoder тоже умеет определять кодировку текста в автоматическом режиме, а также переводить ее в читаемый вид или любые другие кодировки, если это требуется. Подбор символов на этом сайте осуществляется буквально в несколько кликов.
- Воспользуйтесь ссылкой выше или самостоятельно откройте главную страницу сайта Online Decoder, где сразу же активируйте поле для ввода и вставьте туда целевой текст.
- Напротив пункта «Раскодировать текст автоматически (рекомендуется)» нажмите по кнопке «Подбор» для запуска процесса распознавания.
- Та кодировка, в которую выполнен перевод, отображается второй.
- Исходная находится прямо после надписи «Я знаю нужные кодировки». Ее и надо узнать, если речь идет об определении стилистики символов.
Способ 3: FoxTools
FoxTools — еще один онлайн-сервис, основное предназначение которого заключается в декодировании текста, однако его функциональность можно использовать и для определения необходимого символьного набора, что происходит так:
- Активируйте поле для ввода и вставьте туда скопированную ранее надпись.
- Снизу поля «Исходная кодировка» вы найдете кнопку «Определить», по которой и следует нажать для запуска процесса распознавания.
- Если параллельно осуществляется перевод в читаемый вид, выберите его из выпадающего меню сверху.
- Нажмите «Отправить», чтобы получить результат со всей необходимой информацией.
- Ознакомьтесь с параметром возле пункта «Исходная кодировка» для определения символьного набора. Если он отображен не в кодовом названии, найдите перевод через Википедию для общего понимания.
- Иногда FoxTools не распознает редко используемые кодировки, поэтому потребуется переключиться в режим «Все кодировки» и повторить процедуру подбора.