3. АРХИТЕКТУРА ПРОЦЕССОРОВ
леры. Это CISC (Complex Instruction Set Computers – компьютеры со сложной системой команд), RISC (Reduced Instruct Set Computers – компьютеры с сокращенной системой команд), Гарвардская, Принстонская.
Сложно сказать, какая из архитектур лучше – CISC или RISC, Гарвардская или Принстонская. Попытаемся объяснить различия между этими архитектурами и показать, какое отношение они имеют к микроконтроллерам.
3.1. CISC и RISC
В настоящее время существует множество RISC-процессоров, т. к. сложилось мнение, что RISC быстрее, чем CISC процессоры. Такое мнение не совсем верно. Имеется много процессоров, называемых RISC, но на самом деле относящихся к CISC. Более того, в некоторых приложениях CISC-процессоры выполняют программный код быстрее, чем это делают RISC-процессоры, или решают такие задачи, которые RISC-процессоры не могут выполнить.
Истинное различие между RISC и CISC в том, что CISC-процессоры выполняют большой набор команд с развитыми возможностями адресации (непосредственная, индексная и т. д.), давая разработчику возможность выбрать наиболее подходящую команду для выполнения необходимой операции, а в RISC-процессорах набор выполняемых команд сокращен до минимума. При этом разработчик должен комбинировать команды, чтобы реализовать более сложные операции.
Возможность равноправного использования всех регистров процессора называется «ортогональностью» или «симметричностью» процессора. Это обеспечивает дополнительную гибкость при выполнении некоторых операций. Рассмотрим, например, выполнение условных переходов в программе. В CISC-процессорах условный переход обычно реализуется в соответствии с определенным значением бита (флага) в регистре состояния. В RISC-процессорах условный переход может происходить при определенном значении бита, который находится в любом месте памяти. Это значительно упрощает операции с флагами и выполнение программ, использующих эти флаги.
Успех при использовании RISC-процессоров обеспечивается благодаря тому, что их более простые команды требуют для выполнения значительно меньшее число машинных циклов. Таким образом, достигается существенное повышение производительности, что позволяет RISC-процессорам эффективно решать чрезвычайно сложные задачи.
3.2. Гарвардская и Принстонская
Много лет назад правительство Соединенных Штатов дало задание Гарвардскому и Принстонскому университетам разработать архитектуру компьютера для военно-морской артиллерии. Принстонский университет разработал компьютер, ко-
торый имел общую память для хранения программ и данных. Такая архитектура компьютеров больше известна как архитектура фон Неймана по имени научного руководителя этой разработки. Структура компьютера с Принстонской архитектурой представлена на рис. 3.1.
Рис. 3.1. Структура компьютера с Принстонской архитектурой
В этой архитектуре блок интерфейса с памятью выполняет арбитраж запросов к памяти, обеспечивая выборку команд, чтение и запись данных, размещаемых в памяти или внутренних регистрах. Может показаться, что блок интерфейса является наиболее узким местом между процессором и памятью, т. к. одновременно с данными требуется выбирать из памяти очередную команду. Однако во многих процессорах с Принстонской архитектурой эта проблема решается путем выборки следующей команды во время выполнения предыдущей. Такая операция называется предварительной выборкой («предвыборка»), и она реализуется в большинстве процессоров с такой архитектурой.
Гарвардский университет представил разработку компьютера, в котором для хранения программ, данных и стека использовались отдельные банки памяти. Структура компьютера с Гарвардской архитектурой представлена на рис. 3.2.
Принстонская архитектура выиграла соревнование, т. к. она больше соответствовала уровню технологии того времени. Использование общей памяти оказалось более предпочтительным из-за ненадежности ламповой электроники (это было до широкого распространения транзисторов), при этом возникало меньше отказов.
Гарвардская архитектура почти не использовалась до конца 70-х годов, когда производители микроконтроллеров поняли, что эта архитектура дает преимущества устройствам, которые они разрабатывали.
Основным преимуществом архитектуры фон Неймана является то, что она упрощает устройство микропроцессора, т. к. реализует обращение только к одной общей памяти. Для микропроцессоров самым важным является то, что содержимое ОЗУ (RAM – Random Access Memory) может быть использовано как для хранения данных, так и для хранения программ. В некоторых приложениях программе необходимо иметь доступ к содержимому стека. Все это предоставляет большую гибкость для разработчика программного обеспечения.
Рис. 3.2. Структура компьютера с Гарвардской архитектурой
Гарвардская архитектура выполняет команды за меньшее количество тактов, чем архитектура фон Неймана. Это обусловлено тем, что в Гарвардской архитектуре больше возможностей для реализации параллельных операций. Выборка следующей команды может происходить одновременно с выполнением предыдущей команды, и нет необходимости останавливать процессор на время выборки команды.
Например, если процессору с Принстонской архитектурой необходимо считать байт и поместить его в аккумулятор, то он производит последовательность действий, показанную на рис. 3.3. В первом цикле из памяти выбирается команда; в следующем цикле данные, которые должны быть помещены в аккумулятор, считываются из памяти.
Рис. 3.3. Выполнение команды mov Асс, Reg в Принстонской архитектуре
В Гарвардской архитектуре, обеспечивающей более высокую степень параллелизма операций, выполнение текущей операции может совмещаться с выборкой следующей команды (рис. 3.4). Команда также выполняется за два цикла, но выборка очередной команды производится одновременно с выполнением предыдущей. Таким образом, команда выполняется всего за один цикл (во время чтения следующей команды).
Рис. 3.4. Выполнение команды mov Асс, Reg в Гарвардской архитектуре
Этот метод реализации операций («параллелизм») позволяет командам выполняться за одинаковое число тактов, что дает возможность более просто определить время выполнения циклов и критических участков программы. Это обстоятельство является особенно важным при выборе микроконтроллера для приложений, где требуется строгое обеспечение заданного времени выполнения. Например, микроконтроллер PIC фирмы Microchip выполняет любую команду, кроме тех, которые модифицируют содержимое программного счетчика, за четыре такта (один цикл). Это упрощает реализацию критических ко времени процедур по сравнению с микроконтроллером Intel 8051, где для выполнения команд может потребоваться от 16 до 64 тактов. Из-за этого часто не удается подсчитать точное время выполнения программы вручную и приходится применять симуляторы или аппаратные эмуляторы.
Следует отметить, что такие общие способы сравнения производительности не следует использовать для всех процессоров и микроконтроллеров, в которых реализуются эти две архитектуры. Сравнение лучше проводить применительно к конкретному приложению. Различные архитектуры и устройства имеют свои специфические особенности, которые позволяют наилучшим образом реализовать те или иные приложения. В некоторых случаях конкретное приложение может быть выполнено только с использованием определенной архитектуры и специфических особенностей микроконтроллера.
На первый взгляд Гарвардская архитектура – это единственно правильный выбор. Но Гарвардская архитектура является недостаточно гибкой для некоторых программных процедур, которые требуются для реализации ряда приложений.
Как разрабатываются и создаются процессоры? Часть 1: Фундаментальные основы архитектуры процессоров
Существует общественное мнение, что процессор — мозг компьютера. Но как работает этот самый мозг, состоящий из миллиардов транзисторов? В этой небольшой серии статей (всего из четырех частей)портал Techspotрешил тщательно разобраться в том, что же заставляет работать ваше «железо».
В статьях будут затронуты такие темы, как принцип работы компьютерной архитектуры, дизайн микросхем процессоров, сверхбольшая масштабная интеграция (VLSI), создание чипов и грядущие тренды. Если вам всегда было интересно, как работают процессоры, то присаживайтесь прямо сейчас и наслаждайтесь чтением, потому что именно с этого и начнется данная статья.
Для началанужно понять, из чего состоит процессор, и как блоки соединяются в функциональное целое. Также будет затронута тема ядер процессоров, иерархии памяти, прогнозирования ветвлений и многого другого. Для начала, стоит дать базовое определение тому, что именно делает процессор. Если говорить простым языком, то процессор проводит операции над введенными командами, следуя конкретным инструкциям. Такой операцией может быть считывание значений из памяти, сложение этих значений, а затем сохранение их в другом отделе памяти. Или что-то более сложное — например, деление двух чисел, если результат предыдущего вычисления оказался выше нуля.
Любая программа, будь то операционная система или видеоигра, представляет собой набор инструкций, которые необходимо выполнить. Эти действия загружаются из памяти и запускаются по очереди, вплоть до окончания программы. Многие разработчики пишут программы на сложных языках программирования, например, C++ или Python, но стоит отметить, что процессор их попросту не понимает. Все, что он может — обработать нули и единицы, поэтому необходимо представить код в подобном формате.
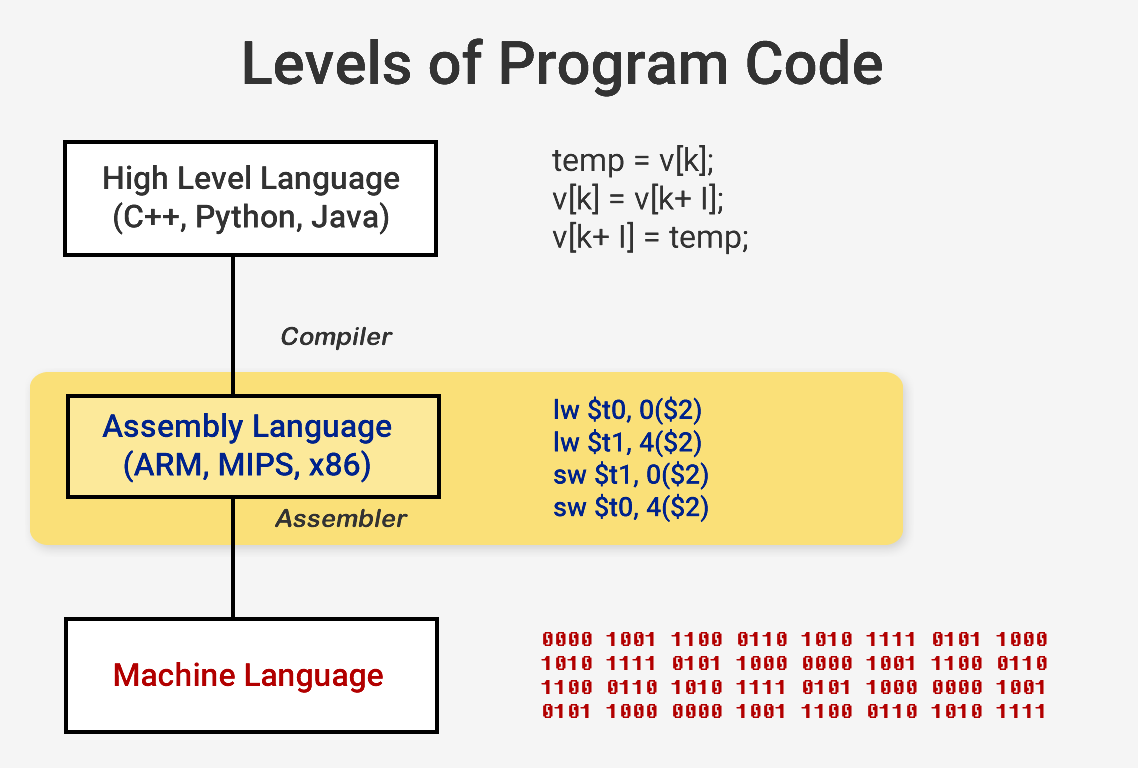
Программы представляют собой набор низкоуровневых инструкций. Их называют языком ассемблера (assembly language), и они являются одной из частей архитектуры набора команд (ISA). Процессоры запрограммированы на распознавание и выполнение этих инструкций. Самыми распространенными архитектурами набора команд являются x86, MIPS, ARM, RISC-V и PowerPC. Каждая из них отличается друг от друга написанием кода, по аналогии с языками программирования.
Эти архитектуры можно разбить на две категории: архитектуры с фиксированной длиной и переменной длиной. RISC-V является архитектурой с фиксированной длиной, и это означает, что по количеству битов можно понять можно определить тип инструкции. Ее полная противоположность — это x86: архитектура с переменной длиной, в которой каждая инструкция может быть закодирована совершенно по-разному и с разным количеством битов в каждой части. Именно поэтому декодер инструкций на процессорах с архитектурой x86 является самой сложной деталью всего устройства.
Инструкции с фиксированной длиной декодируются легче и быстрее, но у таких архитектур существует лимит поддерживаемых инструкций. Так, самые распространенные процессоры на RISC-V с открытым доступом поддерживают около 100 инструкций, а x86 является закрытой архитектурой, поэтому никто не знает точного количества поддерживаемых инструкций. Многие считают, что это число достигает нескольких тысяч, но это лишь догадки. Тем не менее, несмотря на такую разницу, процессоры на обеих архитектурах выполняют одни и те же функции.
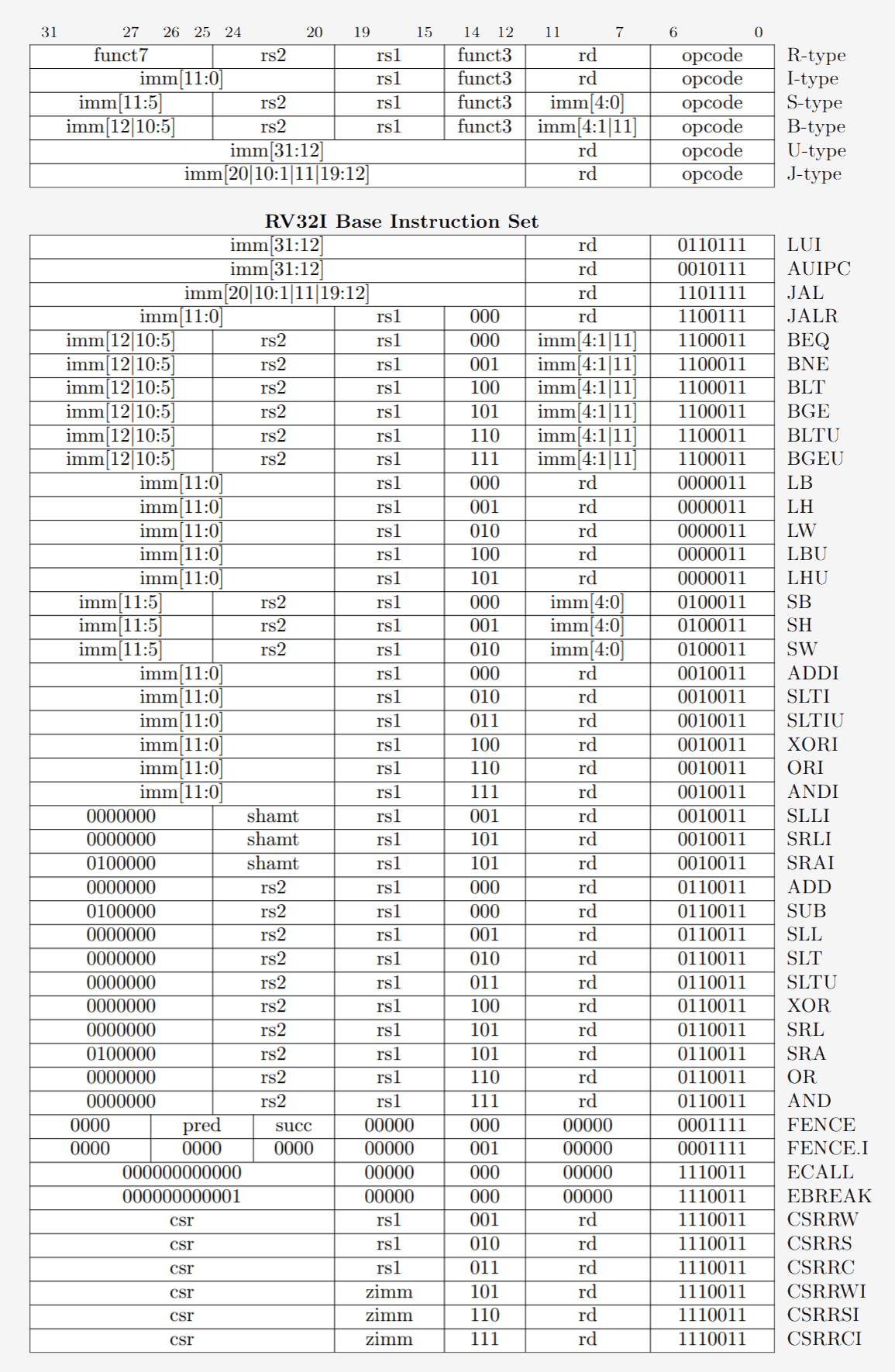
Примеры инструкций архитектуры RISC-V. Инструкция opcode справа занимает 7 бит, что, в свою очередь, определяет ее тип. Каждая инструкция состоит из битов, которые отвечают за то, какие регистры и функции будут выполняться. Так инструкции ассемблера превращаются в бинарный код, который процессор способен считывать.
Итак, теперь можно включать компьютер и запускать программы. Стоит отметить, что выполнение инструкции состоит из нескольких базовых шагов.
Первым таким шагом является перенос инструкции из памяти в сам процессор. На второй стадии инструкция декодируется, чтобы процессор смог понять, что это за инструкция. Типов инструкций много — от арифметических действий до инструкций памяти. После того, как процессор определил тип инструкции, он достает необходимые операнды из памяти или внутренних регистров. Объясняется это просто — вы не можете сложить числа A и B, если не знаете их значений. Стоит также упомянуть, что, так как многие современные процессоры 64-битные, то размер значения данных тоже будет составлять 64 бита.
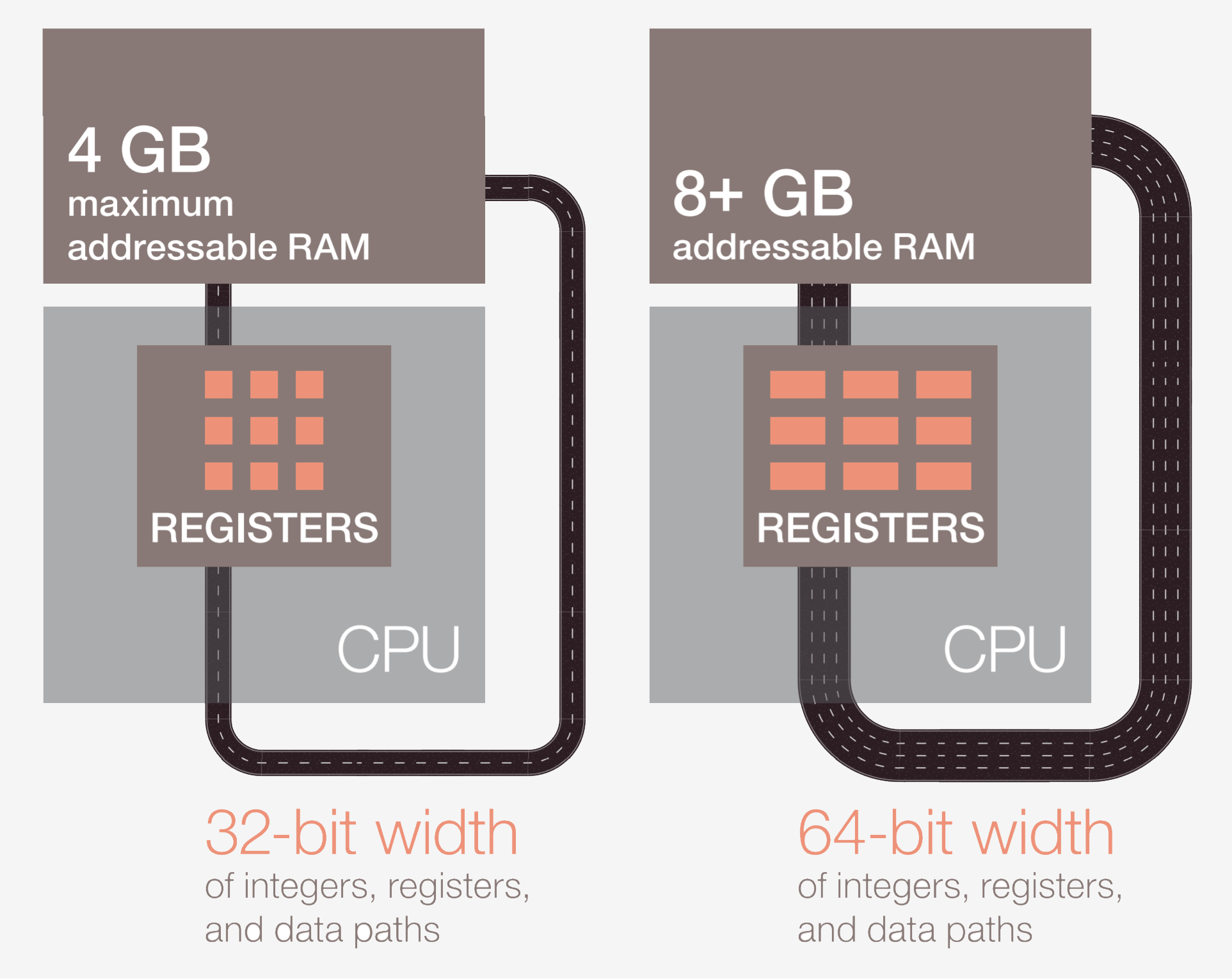
64 бита — это пропускная способность регистра процессора; пути данных и/или адреса памяти. Чем больше бит, тем больше информации компьютер может обрабатывать за раз. Проще говоря, 64-битный процессор может обрабатывать в два раза больше информации, чем 32-битный.
После того, как процессор получил необходимые операнды, начинается выполнение инструкции и операций над введенными данными. Это может быть добавление чисел, проведение логических манипуляций или даже отсутствие действий, когда значение просто отправляется дальше. После подсчета результатапроцессор может снова обратиться к памяти, чтобы сохранить полученное значение там или же просто отложить полученное значение в одном из внутренних регистров. Только после того, как результат сохранен, процессор обновит состояние различных элементов и перейдет к выполнению следующей инструкции.
Следует отметить, что вся вышеперечисленная цепочка действий значительно упрощена, поскольку в реальных ситуациях большинство современных процессоров разделяют все эти действия на 20+ более мелких циклов, чтобы повысить эффективность. В профессиональной среде подобное называется пайплайном — чем-то вроде трубопровода, который постепенно заполняется жидкостью, но как только заполнится полностью, внутри создается постоянный поток.
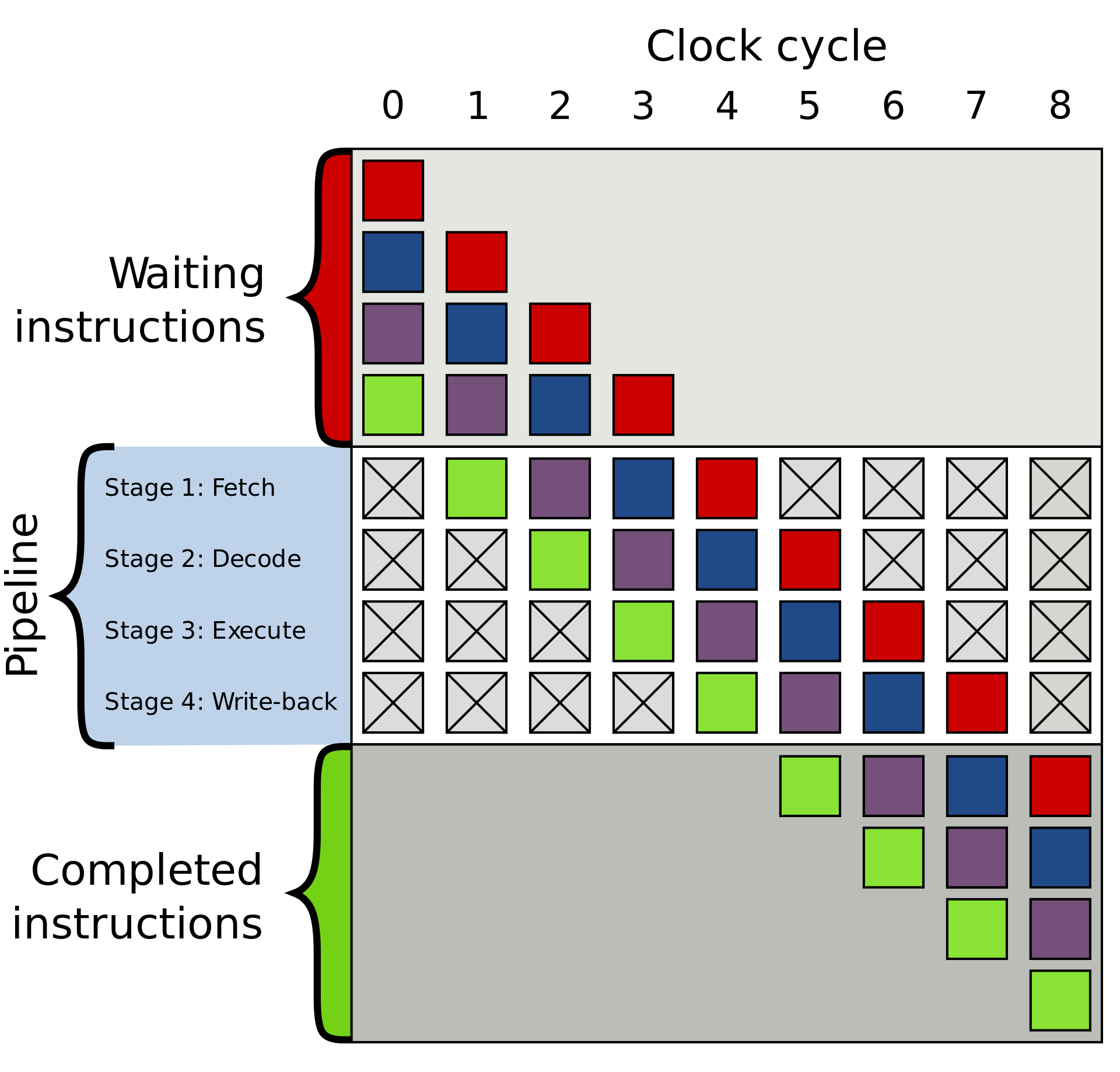
Пример четырехступенчатого пайплайна. Цветные квадраты представляют собой независимые друг от друга инструкции.
Прохождение циклов — тщательно отлаженный процесс, но не все инструкции заканчиваются одновременно. Сложение, например, выполняется невероятно быстро, а вот делению или загрузке из памяти может потребоваться на выполнение несколько сотен циклов. Современные процессорывместо того, чтобы простаивать в ожидании завершения одной медленной инструкции, могут выполнять инструкции вне очереди. Процессор сам способен определить, какую инструкцию лучше выполнить в данный момент, а какие — после нее. Если выполняемая инструкция еще не готова, то система может забежать немного вперед, чтобы посмотреть, готово ли что-то другое.
Современные процессоры, кроме внеочередного выполнения инструкций, обладают также суперскалярной архитектурой. Это означает, что процессор может выполнять сразу несколько инструкций на каждом из этапов пайплайна. Для того, чтобы это было возможно, процессору необходимо иметь несколько копий каждого этапа пайплайна. Таким образом, если процессор видит две доступные для исполнения инструкции, между которыми нет никакой зависимости друг от друга, то он сможет одновременно выполнить обе. Такая технология называется одновременной многопотоковостью (SMT), более известной как гиперпотоковость (Hyper-Threading). Процессоры Intel и AMD поддерживают двухстороннюю одновременную многопотоковость, в то время как IBM разработала чипы, поддерживающие уже восьмистороннюю многопотоковость.

Для того, чтобы в точности прорабатывать подобную схему, процессорупомимо ядра для работы необходимы и другие элементы. В каждом процессоре расположены сотни модулей, причем каждый предназначен для специфической задачи, но в этой статье будут затронуты лишь самые важные. Основные два — это кэш и блок предсказания ветвлений.
Неопытных пользователей кэш может сбить с толку, ведь его главная задача — хранить данные, прямо как оперативная память или любой другой накопитель. Главное отличие кэша заключается в его огромной скорости и низкой задержке при работе с данными. Несмотря на то, что оперативная память обладает высокой скоростью работы с данными, она все еще в разы медленней кэша и слишком медленная для работы процессора. Если говоритьо более точных цифрах, то кэш быстрее оперативной памяти в 100 раз и в 1000 раз быстрее любого SSD. Без кэша процессоры работали бы в разы медленней.
Почти в каждом процессоре есть три уровня кэша — это называется иерархией памяти. Кэш 1 уровня (L1) самый быстрый и самый маленький, 3 уровня (L3), наоборот, крупнейший и медленный, а кэш 2 уровня (L2) — «золотая середина» между ними. Выше кэша в иерархии памяти стоят маленькие регистры, в которых сохраняется одиночное значение данных во время работы процессора. Эти регистры по скорости даже опережают кэш. Регистры используются, когда компилятор переводит высокоуровневые программы в язык ассемблера.
Когда процессор запрашивает данные из памяти, то он сначала проверяет, находятся ли эти данные в кэше первого уровня. Если они там есть, то процессор получает доступ к ним всего за пару циклов. Однако, если данных нет в кэше первого уровня, то процессор поищет их в кэше второго, а затем третьего уровня. С каждым уровнем будет снижаться скорость и увеличиваться задержка. Наконец, если в кэше данных не было, процессор начнет искать их уже в основной памяти (RAM).
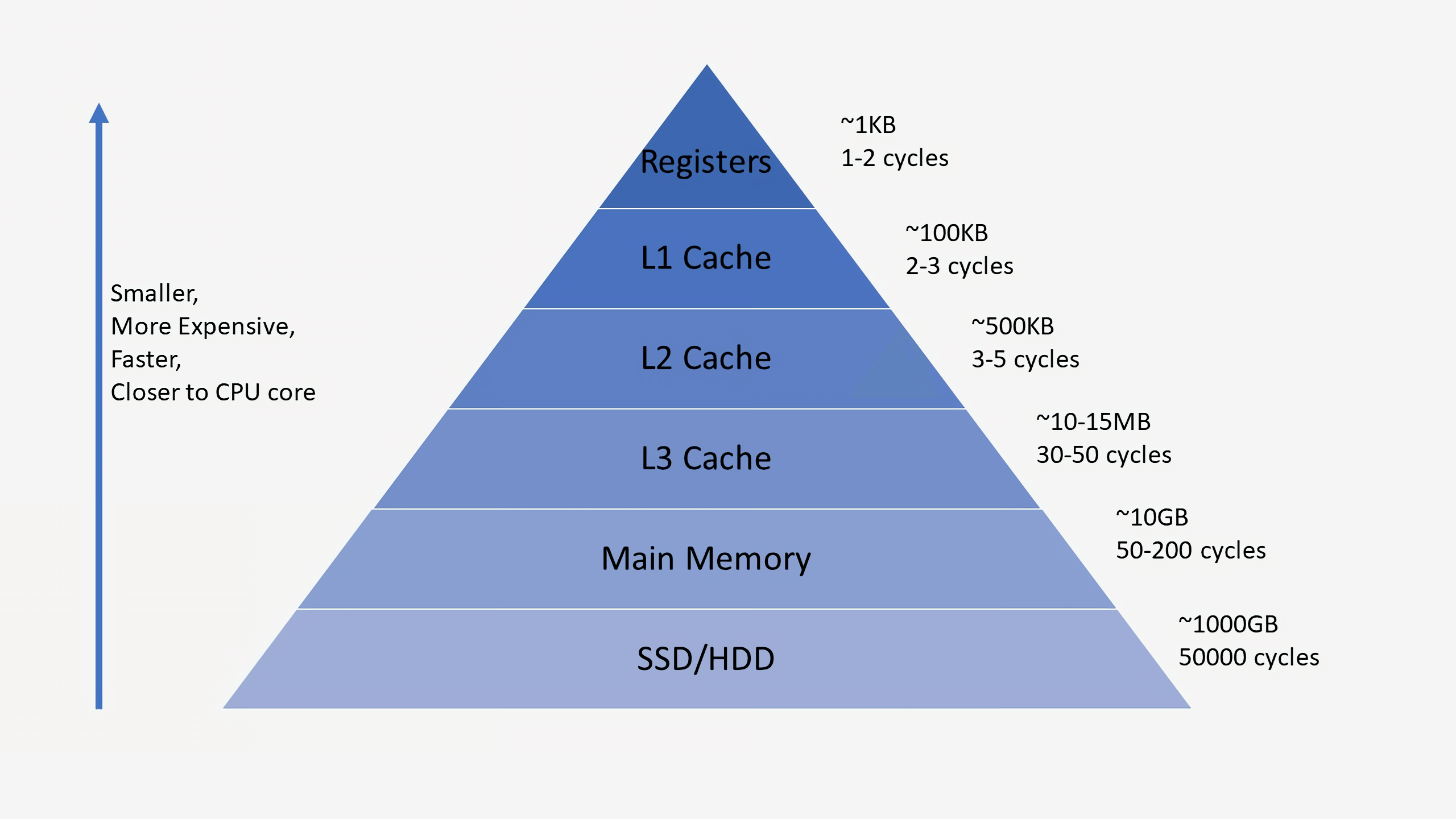
В большинстве процессоров каждое ядро оснащено двумя кэшами первого уровня: один предназначен для данных, а другой — для инструкций. Кэш первого уровнязачастуюоколо 100 КБ в размере, хотя это число может отличаться в зависимости от процессора. Обычно на каждое ядро приходится по кэшу второго уровня, хотя в некоторых архитектурах процессоров может кэш может быть разделен между двумя ядрами. Размер этого кэша составляет уже несколько сотен килобайт. Самым большим (несколько десятков мегабайт) является кэш 3 уровня, который делится сразу между всеми ядрами процессора.
Во время обработки кода процессороминструкции и значения данных в большинстве случаев направляются в кэш. Так значительно увеличивается скорость выполнения задачи, поскольку процессору не нужно обращаться к главной памяти. Более подробно работа систем памяти будет рассмотрена во второй и третьей части этой серии статей.
Вторым важнейшим элементом процессора является блок предсказания ветвлений. Разветвленные инструкции являются чем-то вроде команды “если”, только в контексте процессора. Одна часть инструкций будет выполняться, если условие верно, а другая — если условие ложно. Пример: необходимо сравнить два числа, иесли числа равны, то выполнить одну функцию, а если нет — то другую. Ветвления довольно распространены изачастуюсоставляют около 20% всех инструкций программы.
На бумаге разветвленные инструкции звучат довольно просто, но для процессоров их выполнение может быть довольно проблематичным. Поскольку процессор может выполнять 10-20 инструкций одновременно, ему важно понимать, какие именно нужно обработать. Процессору может понадобиться 5 циклов, чтобы определить, является ли инструкция разветвленной, а затем до 10 циклов для того, чтобы определить верна она или нет. В это же время, процессор может начать выполнять десятки дополнительных инструкций, даже не зная правильно ли их выполнение.
Для решения этой проблемы все современные высокопроизводительные процессоры используют технологию спекулятивного выполнения. Благодаря этой технологии, процессор запоминает выполняемые разветвленные инструкции и автоматически угадывает, произойдет ли ветвление или нет. Если системе удалось угадать, то процессор будет заранее выполнять другие инструкции, что увеличивает производительность. Если же не удалось, то процессор остановит выполнение всех неподходящих инструкций и начнет выполнять задачи с правильной точки.
Блоки предсказания ветвлений — это нечто вроде ранней формы машинного обучения, поскольку блок будет постепенно заучивать принцип работы разветвленных инструкций. Благодаря тому, что блоки развивались и улучшались десятилетиями, точность прогнозов в современных процессорах превышает 90%.
Несмотря на то, что эти предсказания могут увеличить производительность процессора, они также образуют дыры в безопасности. Так, недавняя уязвимость Spectre позволяла злоумышленникам получить доступ к процессору именно через блок предсказания ветвлений. Из-за этого производители процессоров вынуждены были переписать алгоритмы работы, тем самым слегка снизив производительность.
В последние несколько десятилетий процессоры развились до невероятных высот. Благодаря умелому использованию многих элементов процессоров, производителям удалось поднять производительность на новый уровень. Увы, но эти самые производители держат все принципы работы своих технологий в строжайшем секрете, поэтому трудно понять, как работают мельчайшие детали. К счастью, большинство фундаментальных основ работы процессоров остаются неизменными, стандартизированным и общеизвестными. Если Intel вдруг внезапно решит каким-то волшебным образом увеличить скорость работы кэша, либо AMD добавит более продвинутый блок предсказания ветвлений, знайте — обе компании стараются добиться одной и той же цели.
На этом заканчивается небольшая экскурсия в мир основ работы процессоров. В следующей статье речь пойдет о том, как создаются различные компоненты процессора, о логических вентилях, частоте, энергопотреблении, печатных схемах и многом другом.
Виды популярных архитектур процессоров
Прежде чем рассмотреть основные виды архитектур процессоров, необходимо понять, что это такое. Под архитектурой процессора обычно понимают две совершенно разные сущности.
С программной точки зрения архитектура процессора — это совместимость с определённым набором команд (Intel x86), их структуры (система адресации, набор регистров) и способа исполнения (счётчик команд).
Говоря простым языком, это способность программы, собранной для архитектуры x86, работать практически на любой x86-совместимой системе. При этом такая программа не будет работать, например, на ARM системе.
С аппаратной точки зрения архитектура процессора — это некий набор свойств и качеств, присущий целому семейству процессоров (Skylake – процессоры Intel Core 5 и 6 поколений).
Если тема кажется сложной, можно начать со статьи о том, чем CPU отличается от GPU.
Виды архитектур
В этой статье мы рассмотрим самые распространенные и актуальные архитектуры с программной точки зрения, кроме узкоспециализированных (графических, математических, тензорных).
CISC (англ. Complex Instruction Set Computer — «компьютер с полным набором команд») — тип процессорной архитектуры, в первую очередь, с нефиксированной длиной команд, а также с кодированием арифметических действий в одной команде и небольшим числом регистров, многие из которых выполняют строго определенную функцию.
Самый яркий пример CISC архитектуры — это x86 (он же IA-32) и x86_64 (он же AMD64).
В CISC процессорах одна команда может быть заменена ей аналогичной, либо группой команд, выполняющих ту же функцию. Отсюда вытекают плюсы и минусы архитектуры: высокая производительность благодаря тому, что несколько команд могут быть заменены одной аналогичной, но большая цена по сравнению с RISC процессорами из-за более сложной архитектуры, в которой многие команды сложнее раскодировать.
RISC (англ. Reduced Instruction Set Computer — «компьютер с сокращённым набором команд») — архитектура процессора, в котором быстродействие увеличивается за счёт упрощения инструкций: их декодирование становится более простым, а время выполнения — меньшим. Первые RISC-процессоры не имели даже инструкций умножения и деления и не поддерживали работу с числами с плавающей запятой.
По сравнению с CISC эта архитектура имеет константную длину команды, а также меньшее количество схожих инструкций, позволяя уменьшить итоговую цену процессора и энергопотребление, что критично для мобильного сегмента. У RISC также большее количество регистров.
Примеры RISC-архитектур: PowerPC, серия архитектур ARM (ARM7, ARM9, ARM11, Cortex).
В общем случае RISC быстрее CISC. Даже если системе RISC приходится выполнять 4 или 5 команд вместо одной, которую выполняет CISC, RISC все равно выигрывает в скорости, так как RISC-команды выполняются в 10 раз быстрее.
Отсюда возникает закономерный вопрос: почему многие всё ещё используют CISC, когда есть RISC? Всё дело в совместимости. x86_64 всё ещё лидер в desktop-сегменте только по историческим причинам. Так как старые программы работают только на x86, то и новые desktop-системы должны быть x86(_64), чтобы все старые программы и игры могли работать на новой машине.
Для Open Source это по большей части не является проблемой, так как пользователь может найти в интернете версию программы под другую архитектуру. Сделать же версию проприетарной программы под другую архитектуру может только владелец исходного кода программы.
MISC (англ. Minimal Instruction Set Computer — «компьютер с минимальным набором команд»).
Ещё более простая архитектура, используемая в первую очередь для ещё большего уменьшения итоговой цены и энергопотребления процессора. Используется в IoT-сегменте и недорогих компьютерах, например, роутерах.
Для увеличения производительности во всех вышеперечисленных архитектурах может использоваться “спекулятивное исполнение команд”. Это выполнение команды до того, как станет известно, понадобится эта команда или нет.
VLIW (англ. Very Long Instruction Word — «очень длинная машинная команда») — архитектура процессоров с несколькими вычислительными устройствами. Характеризуется тем, что одна инструкция процессора содержит несколько операций, которые должны выполняться параллельно.
По сути является архитектурой CISC со своим аналогом спекулятивного исполнения команд, только сама спекуляция выполняется во время компиляции, а не во время работы программы, из-за чего уязвимости Meltdown и Spectre невозможны для этих процессоров. Компиляторы для процессоров этой архитектуры сильно привязаны к конкретным процессорам. Например, в следующем поколении максимальная длина «очень длинной команды» может из условных 256 бит стать 512 бит, и тут приходится выбирать между увеличением производительности путём компиляции под новый процессор и обратной совместимостью со старым процессором. Опять же, Open Sourсe позволяет простой перекомпиляцией получить программу под конкретный процессор.
Примеры архитектуры: Intel Itanium, Эльбрус-3.
Виртуальные архитектуры
Но раз нельзя запустить программу одной архитектуры на другой, то откуда берутся магические JAR-файлы, которые можно запустить на любой машине? Это пример виртуальной JVM-архитектуры, которая, по сути, эмулируется на целевой реальной машине. Поэтому достаточно JVM-машины для целевой архитектуры для запуска на ней любой Java-программы. Другим примером виртуальной архитектуры является .NET CIL.
Из минусов виртуальных архитектур можно выделить меньшую производительность по сравнению с реальными архитектурами. Этот минус нивелируется с помощью JIT- и AOT-компиляции. Однако большим плюсом будет кроссплатформенность.
Дальнейшим развитием этих архитектур стали гибридные архитектуры. Например современные x86_64 процессоры хотя и CISC-совместимы, но являются процессорами с RISC-ядром. В таких гибридных CISC-процессорах CISC-инструкции преобразовываются в набор внутренних RISC-команд. Какое дальнейшее развитие получат архитектуры процессора, покажет только время.
Собственная платформа. Часть 0.1 Теория. Немного о процессорах
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Немного про архитектуру процессора
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились «Группы» архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Адресация памяти
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Особенности процессоров
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
Техники применяемые в GPU
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Прочее
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Прерывания
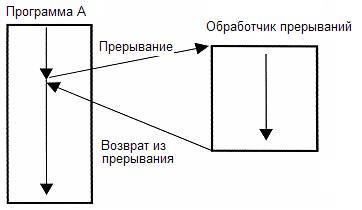
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Контроллеры доступа в память и прочие методы сдерживания программ
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже 🙂
MPU и MMU
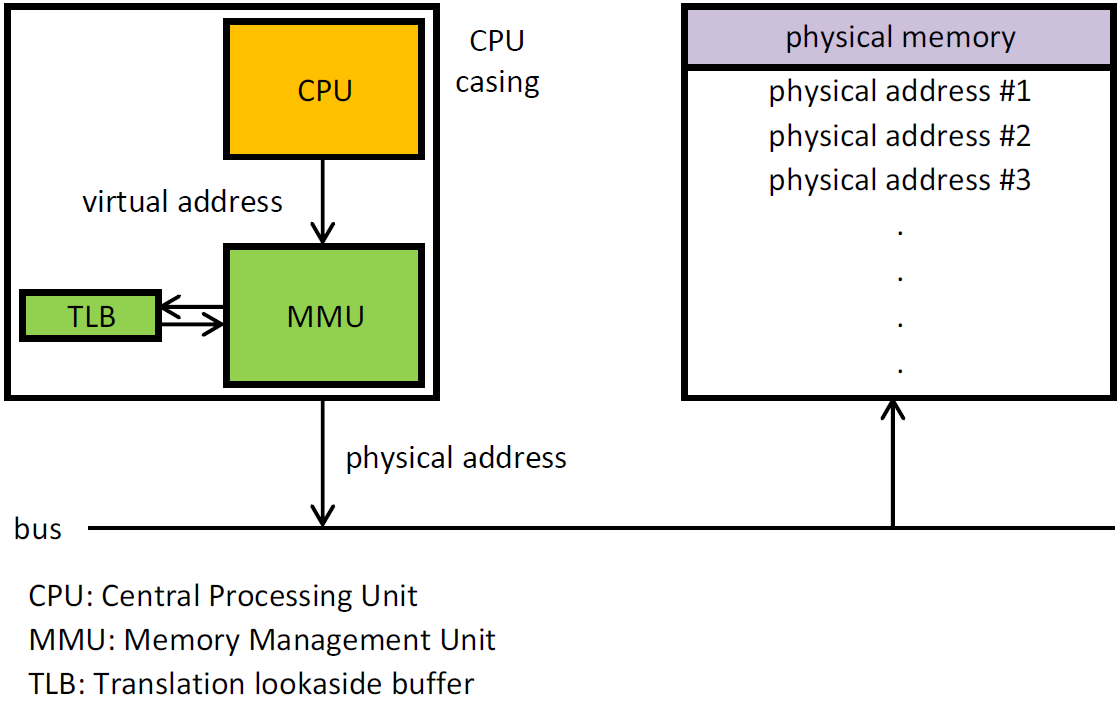
MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет «передвинуть» память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Reposition for Optimization
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.
Status register

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
mov vs $0 reg
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Rd, Rs vs Rd, rs, rt
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).
Endianness

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.
Битность процессора
Итак, что такое битность процессора? Многие считают, что это битность шины данных, но это не так. Почему? В ранние переоды микроконтроллеров и микропроцессоров шина могла быть, например, 4-х битной, но передавала пакетами по 8 бит. Для программы казалось, что это 8-и битный режим, но это была иллюзия, как и сейчас. Например, в ARM SoC-ах часто применяют 128-и битную шину данных или инструкций.
Сопроцессоры
Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомарность операций
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
Shadow Registers
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.
Stack

Стек? Я видел Стек в .NET и в Java! Что же, Вы частично правы. Стек существует, но он никогда не был апаратным в большинства процессорах. Например в MIPS его по просту нет. Спросите КАК ТАК ТО?! Ответ прост. Стек это просто доступ к памяти которую не нужно резервировать (очень грубое определение). Стек используется для вызова функций, передачи аргументов, сохранения регистров для того чтобы востановить их после выполнения функции и т.д.
Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно
1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.
Регистры

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Выравнивание
Что такое выравнивание? Оставлю-ка я этот вопрос вам 🙂
Конец
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )