4) Учебное пособие по матрице R
Матрица – это двумерный массив, который имеет m строк и n столбцов. Другими словами, матрица – это комбинация двух или более векторов с одинаковым типом данных.
Примечание. С помощью R. можно создать более двух массивов измерений.
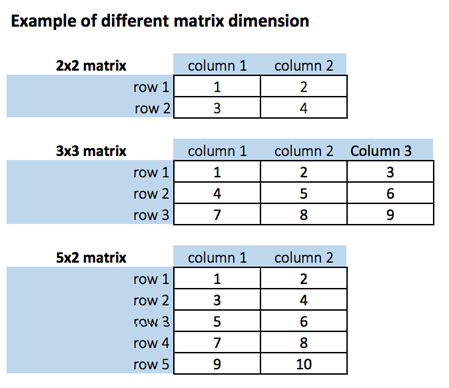
Как создать матрицу в R
Мы можем создать матрицу с помощью функции matrix (). Эта функция принимает три аргумента:
Аргументы:
- data : коллекция элементов, которые R будет размещать в строках и столбцах матрицы
- nrow : количество строк
- ncol : количество столбцов
- Byrow : строки заполняются слева направо. Мы используем `byrow = FALSE` (значения по умолчанию), если мы хотим, чтобы матрица заполнялась столбцами, т.е. значения заполнялись сверху вниз.
Построим две матрицы 5×2 с последовательностью чисел от 1 до 10, одну с byrow = TRUE и одну с byrow = FALSE, чтобы увидеть разницу.
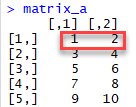
Распечатать размер матрицы с помощью dim ()
Построить матрицу из 5 строк, которые содержат числа от 1 до 10 и byrow = FALSE
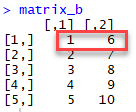
Распечатать размер матрицы с помощью dim ()
Примечание . Использование команды matrix_b <-matrix (1:10, byrow = FALSE, ncol = 2) будет иметь тот же эффект, что и выше.
Вы также можете создать матрицу 4×3, используя ncol. R создаст 3 столбца и заполнит строку сверху вниз. Проверьте пример
Пример:
Добавить столбец в матрицу с помощью cbind ()
Вы можете добавить столбец в матрицу с помощью команды cbind (). cbind () означает привязку столбца. cbind () может объединять столько матриц или столбцов, сколько указано. Например, в нашем предыдущем примере была создана матрица 5×2. Мы объединяем третий столбец и проверяем размер 5×3
Пример:
Пример:
Пример:
Мы также можем добавить более одного столбца. Давайте посмотрим следующую последовательность чисел в матрице matrix_a2. Размерность новой матрицы будет 4х6 с числом от 1 до 24.
Пример:
ПРИМЕЧАНИЕ : количество строк матриц должно быть равным для работы cbind
cbind () объединяет столбцы, rbind () добавляет строки. Давайте добавим одну строку в нашу матрицу matrix_c и проверим размерность 5×3
Нарезать матрицу
Мы можем выбрать один или несколько элементов из матрицы, используя квадратные скобки []. Вот где нарезка входит в картину.
Основы программирования в R
Матрицы в R можно создавать разными способами. Выбор способа зависит от того, какую матрицу мы хотим создать: пустую матрицу (чтобы потом заполнять ее нужными значениями) или матрицу, составленную из уже имеющихся значений, например, из векторов.
Для того чтобы создать пустую матрицу, нужно определить, матрицу какой размерности мы хотим. Размерность матрицы – число строк и число столбцов в ней. Создадим для начала матрицу \(2 \times 3\) , состоящую из нулей:
Можем посмотреть на ее размерность:
Заполнять эту матрицу другими значениями мы пока не будем – это будет интереснее делать, когда мы узнаем про циклы. А сейчас посмотрим, как собрать матрицу из “готовых” векторов.
Пусть у нас есть три вектора
и мы хотим объединить их в матрицу. Векторы будут столбцами матрицы:
А теперь векторы будут строками матрицы:
Другой способ создавать матрицы — разбивать на строки один длинный вектор. Возьмем вектор:
Посиотрим, сколько в нем элементов:
А теперь превратим вектор в матрицу из трех строк и четырех столбцов:
Конечно, если бы потребовали от R невозможное – матрицу, произведение числа строк и столбцов которой не равно длине вектора, из которого мы пытаемся эту матрицу создать – мы бы получили ошибку:
Столбцам и строкам матрицы можно дать названия. Посмотрим еще раз на матрицу m1:
А теперь дадим столбцам этом матрицы названия.
А теперь назовем строки матрицы:
Можно, конечно, присваивать названия сразу и строкам, и столбцам. Проделаем это с матрицей M_cols.
О том, что такое list – поговорим чуть позже.
Элементы матрицы
Для того, чтобы обратиться к элементу матрицы, необходимо указать строку и столбец, на пересечении которых он находится:
Если нам нужна отдельная строка (одна строка, все столбцы), то номер столбца нужно не указывать, просто оставить позицию пустой:
Аналогично для столбцов:
Списки
Список предсталяет собой “вектор векторов” в терминах R. Для тех, кто знаком с программированием, может показаться, что списки похожи на массивы. Это так, но списки, в отличие от массивов, могут содержать элементы разных типов. Например, в списке может быть сохранен вектор имен студентов (текстовый, тип character) и вектор их оценок (целочисленный, тип integer).
Пример списка с числовыми значениями:
А вот пример списка с элементами разных типов:
Так как в списках может храниться большое число разных векторов, для удобства им можно давать названия. Список grades можно было записать и так:
И тогда отдельные вектора из списка можно было бы вызывать удобным образом:
И если мы бы запросили у R структуру этого списка, мы бы увидели названия векторов, которые в него входят.
Можно подумать: зачем нужно знать про списки, если на практике мы обычно будем сталкиваться с другими объектами – базами данных? На самом деле, со списками мы тоже будем встречаться. Многие статистические функции выдают результат в виде списков. Когда результаты выводятся на экран, это не всегда заметно, но если мы захотим заглянуть внутрь, то увидим, что та же регрессионная выдача представляет собой объект, похожий на список, из которого можно выбрать вектор коэффициентов (coefficients), вектор остатков (residuals), предсказанных значений (fitted.values) и так далее.
А как обращаться к элементам списка, если вектора в нем никак не названы?
Для обращения к элементам списка необходимо использовать двойные квадратные скобки:
Если нужно обратиться к “элементу элемента” списка (например, к числу 8 в этом примере) нужно сначала указывать номер вектора, в котором находится элемент, а потом номер самого элемента в этом векторе.
Можно заметить, что список похож на матрицу: для того, чтобы обратиться к элементу, нужно указать “строку” (вектор) и “столбец” (положение в векторе).
Для того, чтобы добавить элемент в список, нужно четко понимать положение элемента в этом списке: будет ли это элементом самого списка или “элементом элемента”:
Аналогичным образом можно изменять элементы списка:
Если в списке всего один элемент, при необходимости его можно быстро превратить в обычный вектор с помощью unlist() :
То же можно делать и со списками из нескольких векторов, тогда все склеится в один длинный вектор:
R — язык для статистической обработки данных. Часть 2/3
Предыдущую часть мы закончили темой векторов, а в этой — переходим к матрицам.
9. Что такое матрица?
Матрица, как структура данных, тоже часто встречается в R.
Её можно рассматривать как расширение понятия вектора. У матрицы может быть множество строчек и столбцов. Все элементы матрицы должны иметь один тип данных.
Чтобы создать матрицу, пользуйтесь конструктором matrix(), а функции nrow и ncol пригодятся вам, чтобы определить количество строк и столбцов соответственно:
Так получается матричная переменная под названием x с 4-мя строками и 4-мя столбцами. Вектор можно трансформировать в матрицу, используя для этого конструктор matrix. Результирующая матрица будет заполняться по столбцам:
Так получится матрица с одним столбцом и тремя строками (по одной для каждого элемента):
Если нам нужно заполнить матрицу по строкам или столбцам, тогда мы можем явно передать их количество при помощи параметра byrow:
Этот код создаёт матрицу с 2-мя столбцами и строчками. Заполняется матрица построчно.
10. Что такое списки и факторы?
Если мы хотим создать множество, в котором будут элементы разных типов, то нам стоит сделать список.
Списки
Списки — это очень важная структура данных в R. Чтобы создать список, пользуйтесь конструктором list():
Эта строчка кода иллюстрирует то, как создаётся список из трёх элементов с разными типами данных.
Мы можем получить доступ к любому элементу при помощи указателя. Например, так:
Этот код в результате напишет “hello”.
Ещё мы можем назвать каждый элемент. К примеру, так:
Факторы
Факторы — это категориальные данные. Например: “да”, “нет” или “мужской”, “женский”, или “красный”, “синий”, “зелёный” и т.д.
Тип данных “фактор” можно использовать для представления факторного множества данных:
Факторы также можно упорядочить (отсортировать):
А ещё можем вывести факторы в формате таблицы:
Это даст следующий результат:
А сейчас давайте разберёмся с вопросами, связанными со статистикой.
11. Что такое датафреймы?
Многим, даже практически всем, научным проектам по работе с данными нужно на вход подавать таблицы. Датафрейм — это структура, которая нужна для представления табличных данных в R. В каждом столбце — список элементов. В разных столбцах могут быть разные типы (данных).
Чтобы создать датафрейм из 2-х столбцов и 5-ти строк, напишите следующее:
12. Различные логические операции в R
В этом разделе рассмотрим общепринятые операторы.
OR (или): первое | второе
Этот оператор проверяет, верно ли первое, или второе. Это дизъюнкция.
AND (и): первое & второе
Этот оператор проверяет, верно ли первое и второе. Это называется конъюнкция.
NOT: !input
Этот оператор возвращает true, если было введено false. И наоборот. Операцию ещё называют инверсией.
Также можем пользоваться операторами:
< меньше, чем;
<= меньше или равно;
=> больше или равно;
> больше, чем;
isTRUE(input) верно для вводимого;
и другие.
13. Функции и область действия переменных в R
Иногда нам нужно, чтобы код решал не одну, а сразу комплекс задач. Эти задачи можно группировать в формате функций. А функции — это очень важные объекты в R.
В функцию можно передавать аргументы, а она может возвращать объект.
В установленном пакете R есть определенное количество встроенных функций, в том числе: length(), mean() и т.д.
Каждый раз, когда мы объявляем функцию (или переменную) и вызываем её, она ищется в текущем окружении, а также рекурсивно ищется в родительских окружениях до тех пор, пока значение не будет найдено.
У функции есть имя. Оно хранится в окружении R. В теле функции находятся её операторы.
Функция может возвращать значение и может принимать ряд аргументов (второе опционально).
Чтобы создать функцию, нам нужно написать следующее:
К примеру, мы можем создать функцию, которая берёт два целых числа и возвращает их сумму:
Чтобы вызвать функцию, нам нужно передать ей аргументы:
Так на выходе получим 3.
Ещё мы можем установить значения по умолчанию для аргумента таким образом, чтобы оно было использовано в случае, когда значение аргументу не присвоено:
Значение по умолчанию y — 2. Так что мы можем вызвать функцию без присвоения значения y.
Запомните ключевое: используйте фигурные скобки <…>.
Давайте посмотрим на сложный случай, в котором мы будем использовать логический оператор.
Предположим, что нужно создать функцию, которая принимает следующие аргументы: Mode (режим), x и y.
- Если значение Mode равно True (истинно), то складываем x и y.
- Если Mode False (ложное), то мы производим операцию вычитания между x и y.
Чтобы вызвать функцию сложения x и y, можем сделать так:
Разберём код ниже. В частности, посмотрим, где наше print(z):
Ключевой момент в том, что z выводится после закрытия скобок.
Будет ли переменная z доступна здесь? Это подводит нас к теме области действия в функциях.
Функция может быть объявлена внутри другой функции:
В примере выше some_func и another_func — это две функции. another_func объявляется внутри функции some_func. В результате another_func() является частной по отношению к some_func(). Следовательно она недоступна внешнему миру.
Если я выполню функцию another_func() снаружи функции some_func, как это показано ниже:
Мы получим ошибку:
Ошибка в функции another_func() : невозможно найти функцию “another_func”.
С другой же стороны, мы можем выполнить another_func() внутри some_func() и она сработает именно так, как и ожидалось.
Теперь рассмотрим этот код, чтобы понять, как работает область действия в R.
- Функция some_func_variable доступна и для функции some_func, и another_func.
- another_func_variable доступна только для функции another_func.
Выполнение этого кода приведёт к возникновению исключения в R-Studio:
Это значит примерно следующее: ошибка при выводе, объект ‘another_func_variable’ не обнаружен.
Как говорится в сообщении об ошибке, another_func_variable не обнаружена. Мы можем увидеть, что было выведено DEF, а это было значение, которое присвоили переменной some_func_variable.
Если мы хотим получить доступ и присвоить значения глобальной переменной, то будем пользоваться оператором <<. Переменная ищется во фрейме родительского окружения. Если переменная не найдена, то создаётся глобальная переменная.
Чтобы добавить неизвестное количество аргументов, напечатайте следующее:
14. Циклы в R
В языке R поддерживаются также управляющие структуры. Исследователи данных могут добавить логики в код R. В этом разделе я расскажу о самых важных управляющих структурах.
Циклы for
Иногда нам бывает нужно проитерировать элементы из множества. Синтаксис будет следующим:
В примере выше итератор может быть списком, вектором и так далее. Сниппет выше работает так, что в результате выводятся элементы множества.
Ещё мы можем написать цикл для своего множества при помощи функции seq_along(). Она обрабатывает множество и генерирует последовательность целых чисел.
Циклы while
Иногда нам нужен цикл, который выполняется, пока условие верно. А когда условие становится ложным, мы выходим из цикла.
Мы можем пользоваться циклом while, чтобы получить необходимую функциональность.
В коде ниже мы устанавливаем значения: x = 3, а z = 0. Впоследствии мы увеличиваем значение z на 1 каждый раз, пока значение z равно или больше, чем x.
If Else (опционально)
If Then Else часто используется в программировании.
Если коротко, условие оценивается в управляющем блоке. Если оно правдивое, то код будет выполнен, а иначе будет выполнен следующий блок, который может быть описан при помощи Else If или Else.
Также можем ввести опциональное else:
Repeat
Если мы хотим повторить последовательность операторов неизвестное количество раз (например, пока условие выполняется или пользователь продолжает вводить значения), тогда мы можем повторять/прерывать операторы. Команда break заканчивает итерацию.
Если нам нужно пропустить итерацию, то мы можем воспользоватся следующим оператором:
15. Чтение и запись внешних данных в R
R предлагает для работы ряд пакетов, которые позволяют читать и записывать внешние данные. Например, Excel-файлы и таблицы SQL. В текущем разделе я описываю способы реализации этого.
Читаем файл эксель
В результате отобразятся верхние строки:
Запись в Excel-файл
Создаётся новый файл Excel с таблицей под названием NewSheet:
Чтение таблицы SQL
Мы может читать данные из SQL-таблицы.
Запись в таблицу SQL
Можем записывать данные в SQL-таблицы.
16. Статистические вычисления в R
R известен как один из самых популярных языков программирования для статистической обработки данных. Встроенные статистические функции очень важно понимать. В этом разделе я расскажу о самых популярных статистических вычислениях, которые производят исследователи данных.
Заполнение недостающих значений
Одна из самых частых задач в проекте исследования данных — это заполнение пропущенных значений. Мы можем пользоваться is.na(), чтобы найти элементы, которые имеют нулевое значение (NA (Not Available — «не доступно») или NAN (Not a Number — «не число»)):
В результате выведется FALSE TRUE FALSE (ложно, истинно, ложно), указывая на второй элемент в NA.
Чтобы вы лучше разобрались, скажу, что is.na() возвращает все те элементы NA. А функция is.nan() вернёт все объекты NaN. Важно помнить, что NaN это NA, но не наоборот. NA не является NaN.
Заметка: многие статистические функции, например mean, median, и так далее, принимают аргумент na.rm — он указывает, хотим ли мы удалить (переместить) na (недостающие значения).
Некоторые вычисления далее будут производиться на следующих двух векторах:
Оба вектора A и B содержат числовые значения 20-ти элементов.
Среднее арифметическое значение
Среднее арифметическое значение вычисляется путем сложения значения в множестве и затем делением на общее количество значений:
Медиана
Медиана — среднее значение в отсортированном множестве. Если количество значений четное, то медиана будет средним значением двух значений в середине:
Она показывает самое часто повторяющееся значение. В R нет стандартной встроенной функции для вычисления моды. Но при этом мы можем создать функцию для такого расчёта, смотрите на пример:
Вот, что происходит при выполнении этого кода:
- Вычисление отдельных значений из множества.
- Затем функция определяет частоту каждого элемента и создаёт на основе этих данных таблицу.
- И в конце она находит указатель на элемент, который имеет самую высокую частоту появления и возвращает ее в качестве моды.
Среднеквадратичное отклонение
Среднеквадратичное отклонение — это отклонение от значений среднего арифметического.
Дисперсия
Дисперсия — это среднеквадратичное отклонение в квадрате:
Корреляция
При помощи корреляции мы можем понять, связаны ли множества друг с другом и взаимодействуют ли они, если между ними значительная связь:
Мы можем пользоваться определенным методом корреляции, например, коэффициентом ранговой корреляции Кендалла или Спирмена. По умолчанию используется коэффициент корреляции Пирсона.
R — язык для статистической обработки данных. Часть 2/3

Предыдущую часть мы закончили темой векторов, а в этой — переходим к матрицам.
9. Что такое матрица?
Матрица, как структура данных, тоже часто встречается в R.
Её можно рассматривать как расширение понятия вектора. У матрицы может быть множество строчек и столбцов. Все элементы матрицы должны иметь один тип данных.
Чтобы создать матрицу, пользуйтесь конструктором matrix(), а функции nrow и ncol пригодятся вам, чтобы определить количество строк и столбцов соответственно:
Так получается матричная переменная под названием x с 4-мя строками и 4-мя столбцами. Вектор можно трансформировать в матрицу, используя для этого конструктор matrix. Результирующая матрица будет заполняться по столбцам:
Так получится матрица с одним столбцом и тремя строками (по одной для каждого элемента):
Если нам нужно заполнить матрицу по строкам или столбцам, тогда мы можем явно передать их количество при помощи параметра byrow:
Этот код создаёт матрицу с 2-мя столбцами и строчками. Заполняется матрица построчно.
10. Что такое списки и факторы?
Если мы хотим создать множество, в котором будут элементы разных типов, то нам стоит сделать список.
Списки
Списки — это очень важная структура данных в R. Чтобы создать список, пользуйтесь конструктором list():
Эта строчка кода иллюстрирует то, как создаётся список из трёх элементов с разными типами данных.
Мы можем получить доступ к любому элементу при помощи указателя. Например, так:
Этот код в результате напишет “hello”.
Ещё мы можем назвать каждый элемент. К примеру, так:
Факторы
Факторы — это категориальные данные. Например: “да”, “нет” или “мужской”, “женский”, или “красный”, “синий”, “зелёный” и т.д.
Тип данных “фактор” можно использовать для представления факторного множества данных:
Факторы также можно упорядочить (отсортировать):
А ещё можем вывести факторы в формате таблицы:
Это даст следующий результат:
А сейчас давайте разберёмся с вопросами, связанными со статистикой.
11. Что такое датафреймы?
Многим, даже практически всем, научным проектам по работе с данными нужно на вход подавать таблицы. Датафрейм — это структура, которая нужна для представления табличных данных в R. В каждом столбце — список элементов. В разных столбцах могут быть разные типы (данных).
Чтобы создать датафрейм из 2-х столбцов и 5-ти строк, напишите следующее:
12. Различные логические операции в R
В этом разделе рассмотрим общепринятые операторы.
OR (или): первое | второе
Этот оператор проверяет, верно ли первое, или второе. Это дизъюнкция.
AND (и): первое & второе
Этот оператор проверяет, верно ли первое и второе. Это называется конъюнкция.
NOT: !input
Этот оператор возвращает true, если было введено false. И наоборот. Операцию ещё называют инверсией.
Также можем пользоваться операторами:
< меньше, чем;
<= меньше или равно;
=> больше или равно;
> больше, чем;
isTRUE(input) верно для вводимого;и другие.
13. Функции и область действия переменных в R
Иногда нам нужно, чтобы код решал не одну, а сразу комплекс задач. Эти задачи можно группировать в формате функций. А функции — это очень важные объекты в R.
В функцию можно передавать аргументы, а она может возвращать объект.
В установленном пакете R есть определенное количество встроенных функций, в том числе: length(), mean() и т.д.
Каждый раз, когда мы объявляем функцию (или переменную) и вызываем её, она ищется в текущем окружении, а также рекурсивно ищется в родительских окружениях до тех пор, пока значение не будет найдено.
У функции есть имя. Оно хранится в окружении R. В теле функции находятся её операторы.
Функция может возвращать значение и может принимать ряд аргументов (второе опционально).
Чтобы создать функцию, нам нужно написать следующее:
К примеру, мы можем создать функцию, которая берёт два целых числа и возвращает их сумму:
Чтобы вызвать функцию, нам нужно передать ей аргументы:
Так на выходе получим 3.
Ещё мы можем установить значения по умолчанию для аргумента таким образом, чтобы оно было использовано в случае, когда значение аргументу не присвоено:
Значение по умолчанию y — 2. Так что мы можем вызвать функцию без присвоения значения y.
Запомните ключевое: используйте фигурные скобки <…>.
Давайте посмотрим на сложный случай, в котором мы будем использовать логический оператор.
Предположим, что нужно создать функцию, которая принимает следующие аргументы: Mode (режим), x и y.
- Если значение Mode равно True (истинно), то складываем x и y.
- Если Mode False (ложное), то мы производим операцию вычитания между x и y.
Чтобы вызвать функцию сложения x и y, можем сделать так:
Разберём код ниже. В частности, посмотрим, где наше print(z):
Ключевой момент в том, что z выводится после закрытия скобок.
Будет ли переменная z доступна здесь? Это подводит нас к теме области действия в функциях.
Функция может быть объявлена внутри другой функции:
В примере выше some_func и another_func — это две функции. another_func объявляется внутри функции some_func. В результате another_func() является частной по отношению к some_func(). Следовательно она недоступна внешнему миру.
Если я выполню функцию another_func() снаружи функции some_func, как это показано ниже:
Мы получим ошибку:
Error in another_func() : could not find function “another_func”
Ошибка в функции another_func() : невозможно найти функцию “another_func”.
С другой же стороны, мы можем выполнить another_func() внутри some_func() и она сработает именно так, как и ожидалось.
Теперь рассмотрим этот код, чтобы понять, как работает область действия в R.
- Функция some_func_variable доступна и для функции some_func, и another_func.
- another_func_variable доступна только для функции another_func.
Выполнение этого кода приведёт к возникновению исключения в R-Studio:
Это значит примерно следующее: ошибка при выводе, объект ‘another_func_variable’ не обнаружен.
Как говорится в сообщении об ошибке, another_func_variable не обнаружена. Мы можем увидеть, что было выведено DEF, а это было значение, которое присвоили переменной some_func_variable.
Если мы хотим получить доступ и присвоить значения глобальной переменной, то будем пользоваться оператором <<. Переменная ищется во фрейме родительского окружения. Если переменная не найдена, то создаётся глобальная переменная.
Чтобы добавить неизвестное количество аргументов, напечатайте следующее:
14. Циклы в R
В языке R поддерживаются также управляющие структуры. Исследователи данных могут добавить логики в код R. В этом разделе я расскажу о самых важных управляющих структурах.
Циклы for
Иногда нам бывает нужно проитерировать элементы из множества. Синтаксис будет следующим:
В примере выше итератор может быть списком, вектором и так далее. Сниппет выше работает так, что в результате выводятся элементы множества.
Ещё мы можем написать цикл для своего множества при помощи функции seq_along(). Она обрабатывает множество и генерирует последовательность целых чисел.
Циклы while
Иногда нам нужен цикл, который выполняется, пока условие верно. А когда условие становится ложным, мы выходим из цикла.
Мы можем пользоваться циклом while, чтобы получить необходимую функциональность.
В коде ниже мы устанавливаем значения: x = 3, а z = 0. Впоследствии мы увеличиваем значение z на 1 каждый раз, пока значение z равно или больше, чем x.
If Else (опционально)
If Then Else часто используется в программировании.
Если коротко, условие оценивается в управляющем блоке. Если оно правдивое, то код будет выполнен, а иначе будет выполнен следующий блок, который может быть описан при помощи Else If или Else.
Также можем ввести опциональное else:
Repeat
Если мы хотим повторить последовательность операторов неизвестное количество раз (например, пока условие выполняется или пользователь продолжает вводить значения), тогда мы можем повторять/прерывать операторы. Команда break заканчивает итерацию.
Если нам нужно пропустить итерацию, то мы можем воспользоватся следующим оператором:
15. Чтение и запись внешних данных в R
R предлагает для работы ряд пакетов, которые позволяют читать и записывать внешние данные. Например, Excel-файлы и таблицы SQL. В текущем разделе я описываю способы реализации этого.
Читаем файл эксель
В результате отобразятся верхние строки:
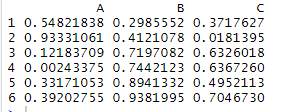 Сниппет показывает содержимое Excel-файла
Сниппет показывает содержимое Excel-файла
Запись в Excel-файл
Создаётся новый файл Excel с таблицей под названием NewSheet:
 Сниппет показывает содержимое Экселя
Сниппет показывает содержимое Экселя
Чтение таблицы SQL
Мы может читать данные из SQL-таблицы.
Запись в таблицу SQL
Можем записывать данные в SQL-таблицы.
16. Статистические вычисления в R
R известен как один из самых популярных языков программирования для статистической обработки данных. Встроенные статистические функции очень важно понимать. В этом разделе я расскажу о самых популярных статистических вычислениях, которые производят исследователи данных.
Заполнение недостающих значений
Одна из самых частых задач в проекте исследования данных — это заполнение пропущенных значений. Мы можем пользоваться is.na(), чтобы найти элементы, которые имеют нулевое значение (NA (Not Available — «не доступно») или NAN (Not a Number — «не число»)):
В результате выведется FALSE TRUE FALSE (ложно, истинно, ложно), указывая на второй элемент в NA.
Чтобы вы лучше разобрались, скажу, что is.na() возвращает все те элементы NA. А функция is.nan() вернёт все объекты NaN. Важно помнить, что NaN это NA, но не наоборот. NA не является NaN.
Заметка: многие статистические функции, например mean, median, и так далее, принимают аргумент na.rm — он указывает, хотим ли мы удалить (переместить) na (недостающие значения).
Некоторые вычисления далее будут производиться на следующих двух векторах:
Оба вектора A и B содержат числовые значения 20-ти элементов.
Среднее арифметическое значение
Среднее арифметическое значение вычисляется путем сложения значения в множестве и затем делением на общее количество значений:
Медиана
Медиана — среднее значение в отсортированном множестве. Если количество значений четное, то медиана будет средним значением двух значений в середине:
Она показывает самое часто повторяющееся значение. В R нет стандартной встроенной функции для вычисления моды. Но при этом мы можем создать функцию для такого расчёта, смотрите на пример:
Вот, что происходит при выполнении этого кода:
- Вычисление отдельных значений из множества.
- Затем функция определяет частоту каждого элемента и создаёт на основе этих данных таблицу.
- И в конце она находит указатель на элемент, который имеет самую высокую частоту появления и возвращает ее в качестве моды.
Среднеквадратичное отклонение
Среднеквадратичное отклонение — это отклонение от значений среднего арифметического.
Дисперсия
Дисперсия — это среднеквадратичное отклонение в квадрате:
Корреляция
При помощи корреляции мы можем понять, связаны ли множества друг с другом и взаимодействуют ли они, если между ними значительная связь:
Мы можем пользоваться определенным методом корреляции, например, коэффициентом ранговой корреляции Кендалла или Спирмена. По умолчанию используется коэффициент корреляции Пирсона.