Счетчики производительности. Часть 1
Производительность компьютера определяется скоростью, с которой компьютер выполняет поставленные задачи. На общую производительность системы влияет много факторов — вычислительная мощность процессора, количество доступной оперативной памяти, скорость дисковой подсистемы, пропускная способность сетевых интерфейсов и т.д.
Иногда при недостаточной производительности может потребоваться проанализировать ситуацию и отследить использование ресурсов приложениями или системными процессами, чтобы затем увеличить мощность системы в соответствии с возрастающими запросами.
Одним из самых мощных инструментов для обнаружения проблем с производительностью в Windows являются встроенные счетчики производительности (Performance Counters). О них и пойдет речь в этой статье.
Performance Monitor
Основным инструментом для управления счетчиками производительности в Windows является оснастка Монитор производительности (Performance Monitor), в более ранних версиях Windows известная как Системный монитор. Performance Monitor имеет несколько режимов отображения и позволяет выводить показания счетчиков производительности в режиме реального времени, а также сохранять данные в лог-файлы для последующего изучения.
Найти Performance Monitor можно в меню Пуск (стартовый экран в Server 2012) в разделе Administrative tools, либо нажав Win+R и в окне «Run» выполнить команду perfmon.msc. Стоит иметь в виду, что не все пользователи имеют права на использование этой оснастки. Кроме членов группы Administrators, которые имеют полные права и могут пользоваться всеми ее возможностями, есть еще две группы:
• Пользователи системного монитора (Performance Monitor Users) — могут просматривать (локально или удаленно) данные монитора производительности и изменять свойства отображения в реальном времени. Не имеют прав на создание и изменение групп сборщиков данных (Data Collector Set);
• Пользователи журналов производительности (Performance Log Users) — имеют все права предыдущей группы, а также могут создавать и изменять группы сборщиков данных.
Ну а обычные пользователи, входящие в группу Users, могут только открывать лог-файлы для просмотра в мониторе производительности.
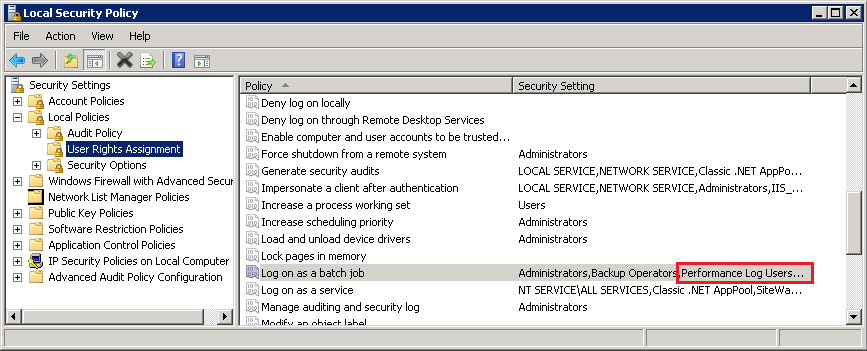
Важно. В соответствием с требованием инструментария управления Windows (WMI) группе Performance Log Users необходимо предоставить право входа в систему в качестве пакетного задания. Для этого надо открыть оснастку локальной политики безопасности (secpol.msc), в разделе «Local policies\User Rights Assignment» найти параметр Log on as batch job и добавить в список группу Performance Log Users.
Добавление счетчиков
Итак, первое что мы делаем, открыв Performance Monitor, это добавляем в окно мониторинга необходимые нам счетчики. По умолчанию в окне уже отображается один счетчик, показывающий общую загрузку процессора. Удалить ненужный счетчик можно, выделив его и нажав на красный крестик на панели инструментов, либо клавишей Delete. Для добавления счетчиков жмем зеленую кнопку либо Ctrl+N.
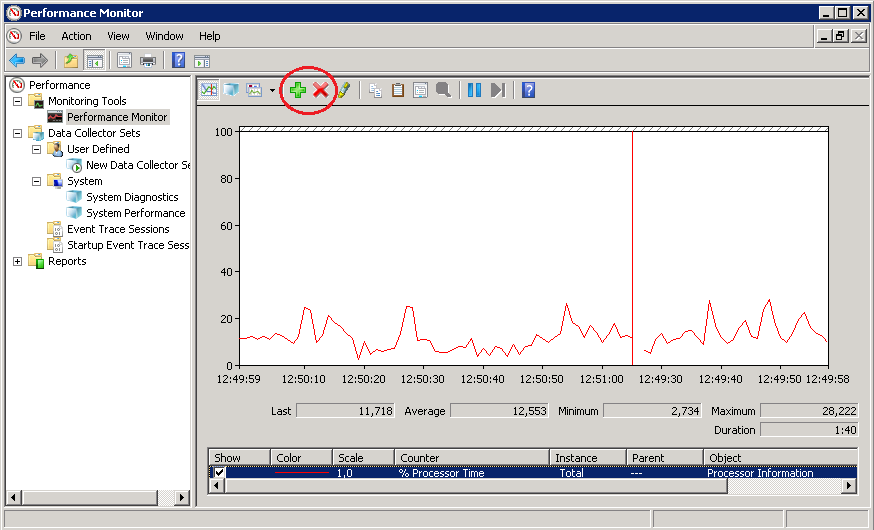
Открывается окно добавления счетчиков. В поле «Select counters from computer» задаем имя или IP-адрес компьютера, за которым будет вестись наблюдение. Кстати, Performance Monitor может отображать в одном окне счетчики с разных компьютеров.
Затем выбираем счетчики производительности из списка. Все счетчики объединены в группы, как правило содержащие в своем названии имя объекта производительности. Например, для мониторинга сетевой активности открываем группу Network Interface и выбираем счетчики, показывающие объем получаемого и передаваемого сетевого трафика, общий объем трафика и текущую пропускную способность.
Если вы сомневаетесь в назначении какого либо счетчика, то есть возможность посмотреть его описание. Для этого надо отметить чекбокс «Show description» в левом нижнем углу. Описание не очень подробное, но достаточно информативное.
Примечание. Количество счетчиков производительности довольно велико и зависит от версии операционной системы и установленых серверных ролей и компонентов. Так, например, в Windows Server 2012 добавлено большое количество счетчиков, предназначеных для мониторинга виртуальных машин. Кроме того, некоторые серверные продукты, такие как Exchange или SQL Server добавляют в систему собственные счетчики.
Выбрав объект мониторинга и выделив нужные счетчики, в поле «Instances of selected оbject» выбираем экземпляр (Instance) объекта. Так выбрав в качестве объекта сетевые интерфейсы, здесь мы указываем, за каким именно необходимо наблюдать. Можно выбрать один или несколько экземпляров, выбрав All Instance мы выведем данные для каждого экземпляра отдельно , а значение _Total выведет усредненное значение по всем экземплярам объекта.
Далее кнопкой «Add»добавляем выбранные счетчики в окно справа и сохраняем изменения кнопкой OK.
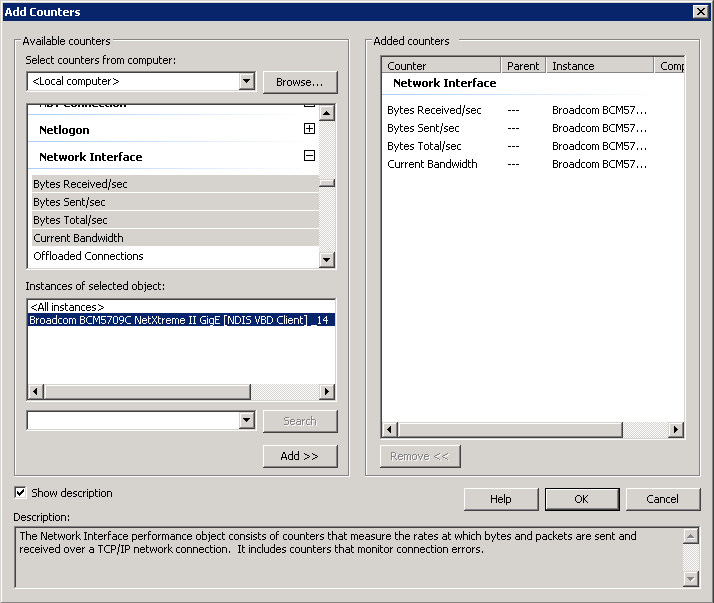
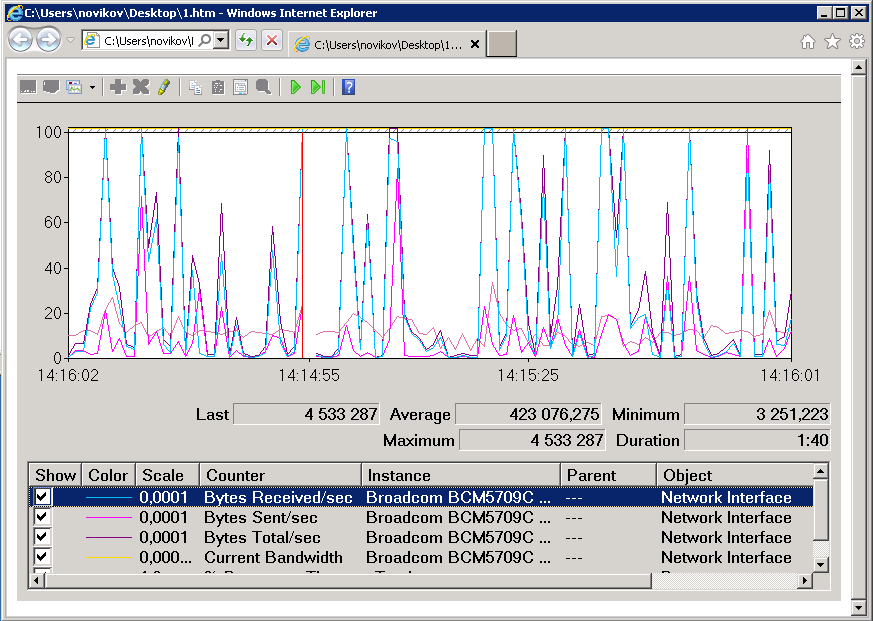
Вот так выглядит окно монитора производительности после добавления счетчиков. По умолчанию значения счетчиков производительности выводятся в виде линейного графика. Выбрав конкретный счетчик, можно посмотреть в панели текущее (last), минимальное (minimum), максимальное (maximum) и среднее (average) значения за указанный период времени.
Если одновременно используется большое число счетчиков, то следить за каждым из них может быть затруднительно. Поэтому при необходимости лишние счетчики лучше скрыть, для чего достаточно снять флажок в столбце Show.
Нажав соответствующую кнопку на панели инструментов, можно выбрать режим отображения в виде гистограммы (Histogram bar) или в виде отчета (Report). Также между режимами можно переключаться сочетанием клавиш Ctrl+G.

Так например, если необходимо постоянно отслеживать текущие значения счетчиков, то режим отчета более нагляден.
Как вариант, можно выделить конкретный счетчик, так чтобы он отражался более жирной линией. Для этого выбираем нужный счетчик и жмем на кнопку Highlight, расположенную в панели инструментов. Также для выделения можно воспользоваться сочетанием клавиш Ctrl+H.
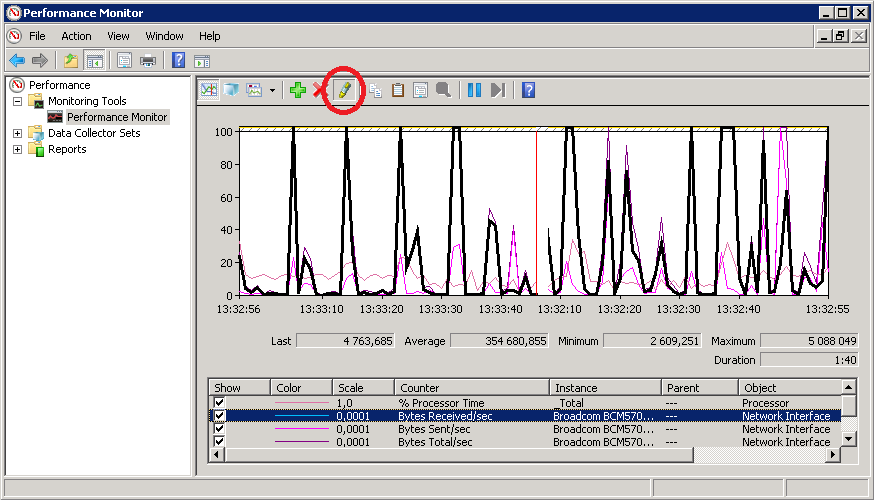
Настройка Performance Monitor
Performance Monitor имеет множество настроек, предназначенных для наилучшего отображения данных. Открыть диалоговое окно настроек монитора производительности можно, кликнув на нем правой клавишей мышки и выбрав пункт Properties, либо нажав на неприметную кнопку в панели инструментов, либо нажав Ctrl+Q.
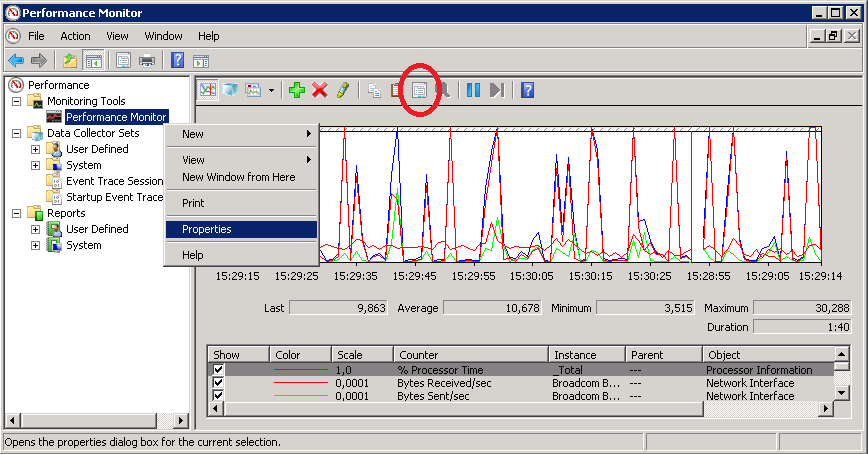
На вкладке General можно:
• Display Elements — удалить\добавить элементы, отображаемые в окне Performance Monitor;
• Report and Histogramm Data — изменить значения, отображаемые в режиме отчета и гистограммы. По умолчанию в них отображаются текущие значения счетчиков. Можно указать минимальное, максимальное или среднее значение, при этом отображаемые данные будут каждый раз пересчитываться;
• Sample Automaticaly — автоматический съем данных. По дефолту выборка данных производится автоматически, с заданным интервалом. Убрав галку, мы тем самым включим ручной режим, в котором снятие данных осуществляется кнопкой Update Data на панели инструментов, или сочетанием клавиш Ctrl+U. Также переключаться с ручного режима на автоматический и обратно можно клавишами Ctrl+F;
• Graph elements — элементы диаграммы. В поле Sample Every задается интервал обновления данных в автоматическом режиме, а в поле Duration — временной отрезок, отображаемый в окне Performance Monitor. По умолчанию данные обновляются каждую секунду, а отображаемый интервал составляет 100 секунд. Для более-менее длительного наблюдения эти значения желательно увеличить.
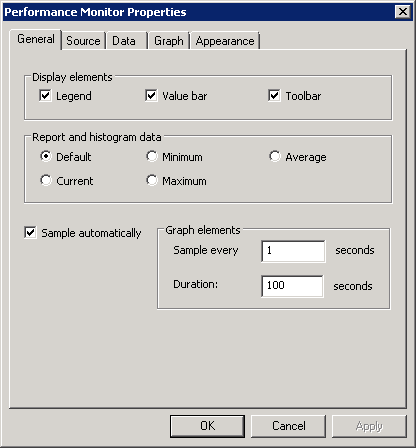
На вкладке Source (Источник) мы указываем, откуда брать данные:
• Current activity — текущая активность, выводится в окне Performance Monitor по умолчанию;
• Log files — здесь можно указать путь к сохраненному ранее файлу журнала;
• Database — использовать в качестве источника базу данных SQL. Performance Monitor позволяет записывать и извлекать данные о производительности в базу данных, конечно при наличии SQL сервера.
На вкладке Data можно отредактировать список счетчиков, а также изменить визуальные параметры отображения каждого счетчика — цвет (Color), масштаб (Scale), ширину линии (Width) и ее стиль (Style).
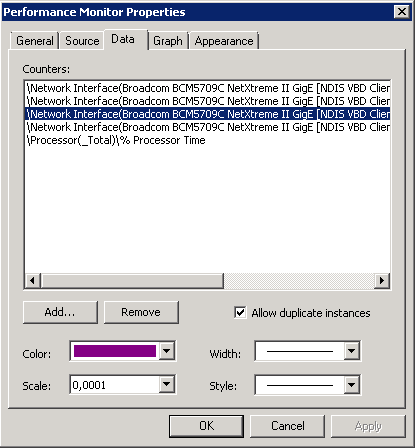
На вкладке Graph изменяем отображение графика:
• View — задаем режим отображения: график, гистограмма или отчет;
• Scroll style — тип прокрутки, указывающий направление прокрутки для линейного графика. Выбрав Wrap (Зацикливание) график будет прокручиваться слева направо, Scroll (Продвижение) — в обратном направлении;
• Title — название графика, отображаемое под панелью инструментов;
• Vertical axis — при помощи этого параметра можно дать название вертикальной оси координат;
• Show — включает отображение вертикальной и горизонтальной сетки и подписи со значениями для осей координат;
• Vertical scale — диапазон значений вертикальной шкалы. Здесь устанавливаем минимальное и максимальное значение, которые будут отображаться на графике.
Ну и на вкладке Appearance настраивается цветовое оформление и используемый шрифт.
Сохранение данных о производительности
Иногда может потребоваться сохранить полученные данные, например для предоставления отчета или для проведения дальнейшего анализа. Performance Monitor позволяет экспортировать полученные данные в файл. Для экспорта надо кликнуть правой клавишей мыши в окне и в открывшемся меню выбрать пункт «Save Settings As». По умолчанию отчет сохраняется в формате HTML, и его можно открыть в любом браузере.
Также можно выбрать для сохранения формат файла с расширением .tsv — файл с разделителями — знаками табуляции. Этот формат может использоваться для экспорта данных в электронные таблицы. А выбрав в контекстном меню пункт «Save Image As» можно сохранить содержимое экрана в виде изображения в формате GIF.
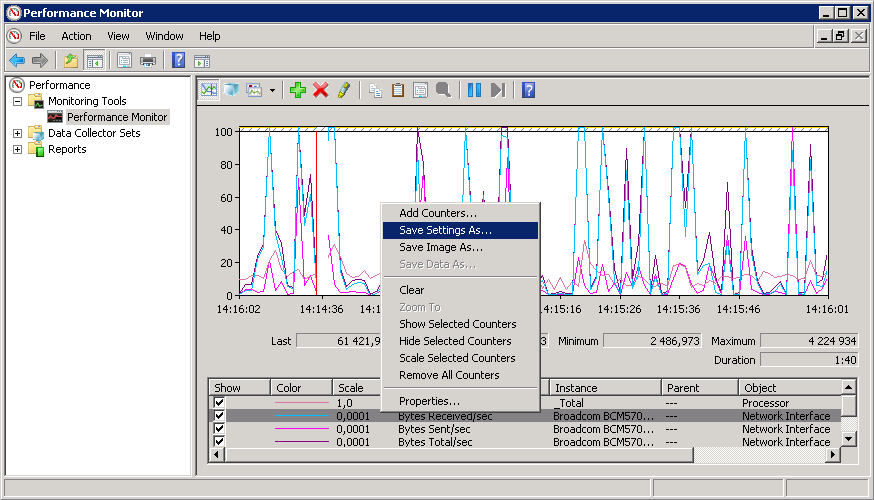
Вот так выглядит в браузере HTML-отчет. В нем сохранены все параметры монитора производительности, включая тип отображения, заголовки и т.п.
PowerShell
Значения счетчиков производительности можно посмотреть и из консоли PowerShell, где для этого есть специальный командлет Get-Counter . Хотя PowerShell имеет гораздо меньше возможностей для отображения счетчиков производительности, чем Performance Monitor, но зато может использоваться в режиме установки Server Core, при полном отсутствии графического интерфейса.
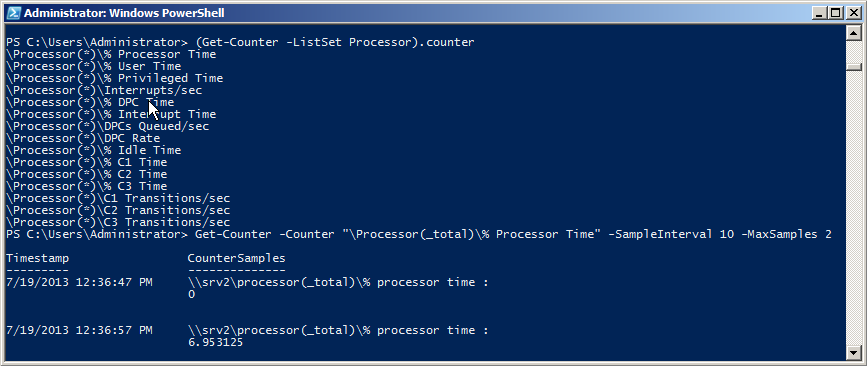
Предположим, мы хотим с его помощью посмотреть загрузку процессора. Сначала выведем все доступные счетчики для процессора:
(Get-Counter -ListSet Processor).counter
Затем выбираем нужный и выводим его значение:
Get-Counter -Counter ″\Processor(_total)\% Processor Time″ -SampleInterval 10 -MaxSamples 2
— В скобках указывается экземпляр счетчика (Instance), в данном примере это ядра процессора. Можно указать номер конкретного экземпляра, либо поставить звездочку (*), тогда будет выведена информация по каждому экземпляру, а указав параметр (_total), мы получим суммарную информацию по всем экземплярам.
— Параметр -SampleInterval указывает периодичность снятия данных, а -MaxSamples — количество попыток. Так в примере данные снимаются 2 раза с интервалом в 10 секунд. Если вместо этих параметров указать -Continuous , то данные будут сниматься непрерывно, пока вы не нажмете Ctrl+C;
— При необходимости можно вывести значения с нескольких счетчиков, указав их через запятую.
Заключение
Итак, сегодня мы рассмотрели некоторые способы использования счетчиков производительности для мониторинга серверов в режиме реального времени. В следующей статье речь пойдет о настройке групп сборщиков данных, сохранении данных в файлы журналов и последующем их анализе, а также о настройке уведомлений.
Анализ ключевых показателей производительности — часть 3, последняя, про системные и сервисные метрики
В первой статье цикла по анализу ключевых показателей производительности мы наладили контекст, теперь переходим к конкретным вещам. Во второй посмотрели на анализ пользовательских, бизнесовых показателей/метрик и показателей, необходимых к анализу внутри приложения. В этой, заключительной — про системные и сервисные (в т.ч. зависимых сервисов) метрики.
Итак,
Системные метрики.
Системные метрики позволяют определять, какие системные ресурсы используются и где могут возникать конфликты ресурсов. Эти метрики направлена на отслеживание ресурсов уровня машины, таких как память, сеть, процессор и утилизация диска. Эти метрики могут дать представление о внутренних конфликтах лежащих в основе компьютера.
Вы также можете отслеживать данные метрики для определения аспектов производительности – нужно понимать, если ли зависимость между системными показателями и нагрузкой на приложение. Возможно, вам потребуются дополнительные аппаратные ресурсы (виртуальные или реальные). Если при постоянной нагрузке происходит увеличение значений данных метрик, то это может быть обусловлено внешними факторами — фоновыми задачами, регулярно-выполняющимися заданиями, сетевой активностью или I/O устройства.
Как собирать
Вы можете использовать Azure Diagnostics для сбора данных диагностики для для отладки и устранения неполадок, измерения производительности, мониторинга использования ресурсов, анализа трафика, планирования необходимых ресурсов и аудита. После сбора диагностики ее можно перенести в Microsoft Azure Storage для дальнейшей обработки.
Другой способ для сбора и анализа диагностических данных — это использование PerfView. Этот инструмент позволяет исследовать следующие аспекты:
- CPU utilization. PerfView, используя технологию Sampling Tracing, периодически (миллисекундными интервалами) запрашивает стек выполняющегося в текущий момент времени кода и возвращает полный стектрейс потока. Далее PerfView агрегирует собранные стектрейсы различных потоков вместе, и вы, используя утилиту stack viewer, можете посмотреть что ваш код делает (и за какое процессорное время), а также убрать или исправить код который выполняется неправильно.
- Managed memory. PerfView может делать снапшоты управляемой кучи (Managed Heap), которая контролируется сборщиком мусора .net. Эти снапшоты конвертируются в графы объектов, позволяя вам проводить анализ времени жизни объектов.
- Unmanaged memory. PerfView может фиксировать события, когда операционная система выделяет или освобождает блоки памяти. Вы можете использовать эту информацию для отслеживания того, как ваше приложение работает с неуправляемой памятью.
- Timing and blockages. PerfView может отслеживать и визуализировать информацию о том, когда потоки засыпают и просыпаются. Вы можете использовать эту информацию для поиска различных блокировок в вашем приложении. Данный анализ особенно полезен, когда при низкой загрузке процессора наблюдаются проблемы производительности.
Изначально PerfView был предназначен для локального запуска, но теперь он может быть использован для сбора данных из Web и Worker ролей облачных сервисов Azure. Вы можете использовать NuGet-пакет AzureRemotePerfView для установки и запуска PerfView удаленно на серверах ролей, после чего скачать и проанализировать полученные данные локально.
Windows Azure Diagnostics и PerfView полезны для анализа используемых ресурсов “постфактум”. Однако, при применении таких практик как DevOps, необходимо мониторить “живые” данные производительности для обнаружения возможных проблем производительности еще до того, как они произойдут. APM-инструменты могут предоставлять такую информацию. Например, утилиты Troubleshooting tools для веб-приложений на портале Azure могут отображать различные графики, показывающие память, процессор и утилизацию сети.

На портале Azure есть “health dashboard”, показывающий общие системные метрики.

Аналогичным образом, панель Diagnostic позволяет отслеживать заранее настроенный набор наиболее часто используемых счетчиков производительности. Здесь вы можете определить специальные правила, при выполнении которых оператор будет получать специальные нотификации, например, когда значение счетчика сильно превысит определенное значение.

Веб-портал Azure может отображать данные о производительности в течении 7 дней. Если вам нужен доступ данных за более длительный период, то данные о производительности нужно выгружать напрямую в Azure Storage.
Websites Process Explorer позволяет вам просматривать детали отдельных процессов запущенных на веб-сайте, а также отслеживать корреляции между использованием различных системных ресурсов.
New Relic и многие другие APM имеют схожие функции. Ниже приведено несколько примеров.
Мониторинг системных ресурсов делится на категории, которые охватывают утилизацию памяти (физической и управляемой), пропускную способность сети, работу процессора и операции дискового ввода вывода (I/O). В следующих разделах описано, на что следует обратить внимание.
Использование физической памяти
- Зарезервированная память не связана с физической или страничной (paged) памятью, сохраненной в файле подкачки. Она просто описывает объем зарезервированной для процесса памяти, и записывается в дескрипторе виртуального адреса (VAD) для процесса. Эта память не связана с физическим хранилищем и во время мониторинга производительности может быть проигнорирована.
- Выделенная память связана с выделением физической памяти и/или страничной памяти файла подкачки. Использование выделенной памяти необходимо отслеживать.
- Memory\Commit Limit показывает максимальный объем памяти, который может быть выделен системой. Обычно это фиксированная величина, которая определяется операционной системой (подробнее How to determine the appropriate page file size for 64-bit versions of Windows) Например, на машине с 8Gb памяти эта цифра составит около 11Gb.
- Process\Private Bytes показывает объем выделенной памяти для процесса. Если сумма всех private bytes для всех процессов превысит предел памяти, описанный выше, это значит, что в системе образовалась нехватка памяти и приложения будут отказывать.
- Memory \% Committed Bytes in Use представляет собой соотношение величин Memory/Committed Bytes и Memory\Commit Limit. Высокое значение этого счетчика указывает, что в системе наблюдается большая нагрузка на память.
Примечание: В Windows есть счетчик Process\Virtual Bytes. Этот счетчик показывает общее количество виртуальной памяти, которое использует процесс, однако к нему нужно относиться очень аккуратно, т.к. на самом он показывает сумму зарезервированной и выделенной памяти процесса. Для примера, исследуя счетчики Process/Virtual Bytes и .NET CLR Memory\# total reserved bytes при старте процесса w3wp, данный счетчик может показывать 18 Гб, хотя его общий объем памяти составляет 185 Мб.
Зарезервированная память может расширяться за счет динамической ОЗУ и процессы могут преобразовывать эту память в физическую.
Существует две основные причины ошибки OutOfMemory – процесс превышает выделенное для него пространство виртуальной памяти либо операционная система оказывается неспособной выделить дополнительную физическую память для процесса. Второй случай является самым распространенным.
Вы можете использовать описанные ниже счетчики производительности для оценки нагрузки на память:
- Memory\Available Mbytes. В идеале значение данного счетчика должно превышать 10% от объема физической памяти, установленной на машине. Если объем доступной памяти слишком мал, то есть вероятность, что система начнет использовать для активных процессов файл подкачки. Если системе не хватает физической памяти, то результатом этого могут быть значительные задержки и/или полное зависание системы.
- Memory\% Committed Bytes In Use. Предел выделенной памяти будет расти, если общий объем выделенной памяти приблизится к 90% от предельного значения — если же значение достигнет 95%, то предел вероятно перестанет расти, и появится вероятность возникновения ошибки OutOfMemory. Как только объем выделенной памяти достигнет предела, то система больше не сможет выделять память для процессов. Большинство процессов не справится с данным поведением системы и прекратят свое выполнение. Поэтому очень важно следить за этим счетчиком.
- Memory\Pages/sec. Этот счетчик показывает, на сколько система использует файл подкачки. Вы можете определить, какое влияние оказывает подкачка на физическую память — для этого надо умножить значение данного счетчика на значение счетчика Physical Disk\Avg.Disk sec/Transfer. Результат данной операции окажется между 0 и 1, и будет характеризовать долю времени доступа к диску, которое затрачивается на чтение и запись виртуальных страниц в файл подкачки. Значение 0.1 означает, что система тратит больше 10% от всего времени доступа к диску на работу с файлом подкачки. Если это значение является постоянной величиной, то это может указывать на проблемы с физической памятью.
Также следует учитывать, что большие объемы памяти могут привести к фрагментации (когда свободной физической памяти в соседних блоках недостаточно), поэтому система, которая показывает, что имеет достаточно свободной памяти, может оказаться не в состоянии выделить эту память для конкретного процесса.
Многие APM-инструменты предоставляют сведения об использовании процессами системной памяти без необходимости глубокого понимания о принципах работы памяти. На графике ниже показана пропускная способность (левая ось) и время отклика (правая ось) для приложения, находящегося под постоянной нагрузкой. Примерно после 6 минут производительность внезапно падает, и время отклика начинает “прыгать”, по прошествии нескольких минут происходит показателей.

Результаты нагрузочного тестирования приложения
Записанная с помощью New Relic телеметрия показывает избыточное выделение памяти, которое вызывает сбой операций с последующим восстановлением. Использованная память растет за счет файла подкачки. Такое поведение является классическим симптомом утечки памяти.

Телеметрия, показывающая избыточное выделение памяти
Примечание: В статье Investigating Memory Leaks in Azure Web Sites with Visual Studio 2013 содержится инструкция, показывающая как использовать Visual Studio и Azure Diagnostics для мониторинга использования памяти в веб-приложении в Azure.
Использование управляемой памяти
.NET приложения используют управляемую память, которая контролируется CLR (Common Language Runtime). Среда CLR проецирует управляемую память на физическую. Приложения запрашивают у CLR управляемую память, и CLR отвечает за выделение требуемой и освобождение неиспользуемой памяти. Перемещая структуры данных по блокам, CLR обеспечивает компоновку этого типа памяти, уменьшая тем самым фрагментацию.
Управляемые приложения имеют дополнительный набор счетчиков производительности. В статье Investigating Memory Issues содержится детальное описание ключевых счетчиков. Ниже описаны наиболее важные счетчики производительности:
- .NET CLR Memory# Total Committed Bytes память процесса, которая опирается на физическую память и страничное место на диске. Данный счетчик отображает количество выделенной памяти процесса и должен быть очень похож на значение счетчика Process/Private Bytes.
- .NET CLR Memory# Total Reserved Bytes указывает на объем зарезервированной памяти для процесса. Он должен быть примерно равен значению счетчика Process\Virtual Bytes и быть меньше значения Process\Private Bytes.
- .NET CLR Memory\Allocated Bytes/sec, показывает на изменчивость управляемой кучи. Значение этого счетчика может быть положительным или отрицательным в зависимости от того, создает или уничтожает приложение объекты. Это счетчик обновляется после каждого цикла сборки мусора. Постоянно-положительное значение этого счетчика может указывать на утечку памяти.
- .NET CLR Memory# Bytes in all Heaps показывает на общий размер управляемой кучи для процесса.
- .NET CLR Memory\% Time in GC процент времени, который был затрачен на выполнение последнего цикла сборки мусора. Хорошим показателем этого счетчика является значение <10%.
Латентность сети на веб-сервере
Производительность сеть особенно важна для облачных приложений, т.к. это проводник, через который проходит вся информация. Сетевые проблемы могу привести к снижению производительности, которое вызовет неудовольствие пользователей, так как сетевые задержки приводят к увеличению длительности выполнения запросов. В настоящее время Windows не предоставляет счетчиков производительности для измерения латентности запросов отдельных приложений. Однако есть Resource Monitor, являющийся отличным инструментом для анализа сетевого трафика на локальной машине (вы можете настроить Remote Desktop во время деплоя ваших облачных сервисов и залогиниться на сервер ваших Web или Worker ролей). Resource Monitor предоставляет информацию о потерянных пакетах или информацию об общей задержке активных TCP/IP сессий. Потеря пакетов дает представление о качестве соединения. Задержка показывает время, требуемое для полного прохождения маршрута TCP/IP пакетом. На рисунке показана Network tab в Resource Monitor.
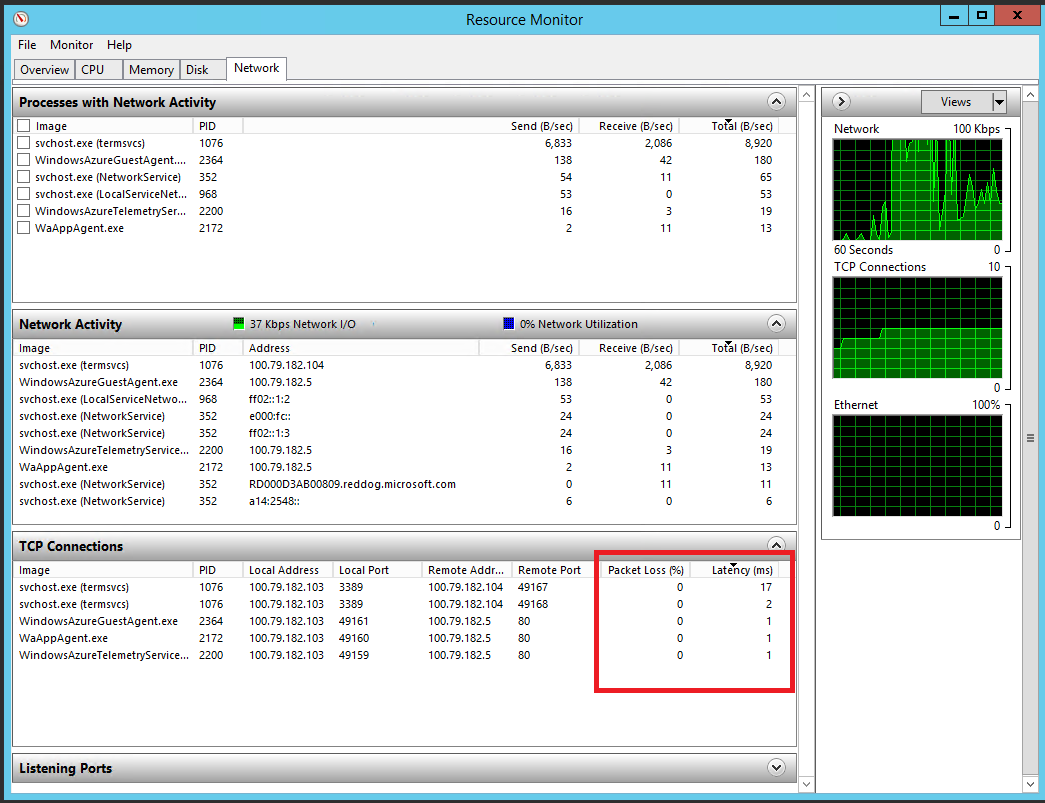
Resource Monitor, показывающий активность локальной сети
Использование сети на веб-сервере
- Network Adapter\Bytes Sent/sec и Network Adapter\Bytes Received/sec показывает скорость передачи и получения данных сетевым адаптером
- Network Adapter\Current Bandwidth используется для оценки допустимой полосы пропускания (в байтах в секунду) сетевого адаптера
- %Network utilization for Bytes Sent = ((Bytes Sent/sec * 8) / Current Bandwidth) * 100
- %Network utilization for Bytes Received = ((Bytes Received/sec * 8) / Current Bandwidth) * 100
Если эти значения окажутся около 100%, то это может свидетельствовать о перегрузке сети. В этом случаем может понадобиться распределить сетевой трафик на несколько экземпляров облачного приложения.
Портал Azure может показывать утилизацию сети всех экземплярами облачных сервиса, а также конкретного экземпляра роли. На портале доступны счетчики Network In и Network Out, предоставляющие информацию по количеству полученных и отправленных байт в секунду.

Мониторинг использования сети на портале управления Azure
Если сетевые задержки очень высоки, но при этом утилизация низкая, то сеть вряд ли является узким местом. Высокая утилизация CPU экземпляров приложения может означать, что требуется больше мощностей, и нагрузку следует распараллелить между несколькими экземплярами. Если же утилизация CPU низкая, то это может быть связано с влиянием внешних сервисов. Например, сложные запросы, отправленные в БД Azure SQL, могут долго выполняться. В этой ситуации распределение сетевого трафика между экземплярами может усугубить проблемы производительности из-за перегрузки сервера БД, что в дальнейшем приведет к увеличению задержки. Вы должны быть готовы отслеживать использование внешних сервисов.
Примечание: Для получения подробной информации о сетевых задержках и ширине канала рекомендуем ознакомиться с инструментом PsPing от Windows Sysinternals.
Объемы сетевого трафика
Другой частой причиной задержек является большой объем сетевого трафика. Вы должны исследовать объемы трафика на внешние сервисы. Многие APM-инструменты позволяют отслеживать трафик, направленный в сторону облачных сервисов и веб-приложений. На рисунке показан пример, взятый из New Relic, на котором показан входящий и исходящий сетевой трафик службы Web API. Большой объем общего трафика (
200 Мб/cек) приводит к высокой латентности для клиентов.
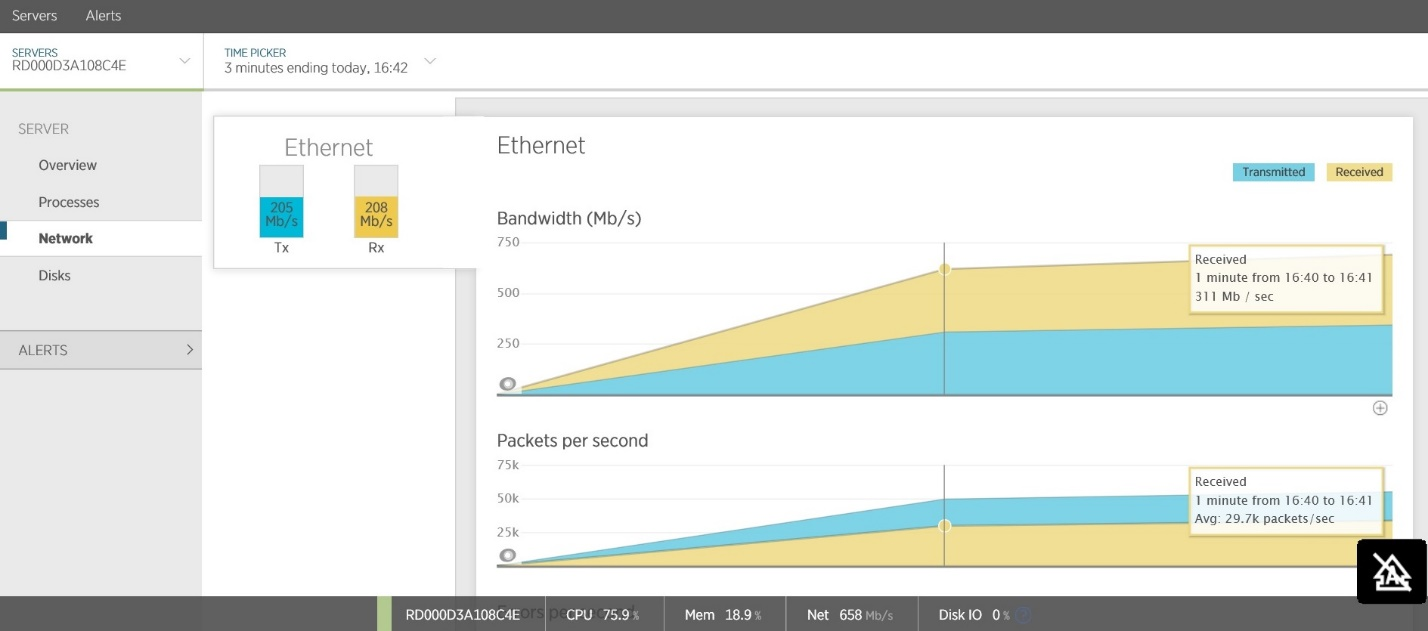
Портал управления Azure также содержит инструменты для просмотра утилизации внешних сервисов, таких как Azure SQL БД и Azure Storage.
Сетевые оверхеды и расположение клиентов
Высокие сетевые задержки могут быть связаны с такими накладными расходами, как взаимодействие протоколов, потери пакетов и эффекты маршрутизации. Латентность и пропускная способность может сильно зависить от расположения клиентов и сервисов, с которыми они работают. Если клиенты расположены в разных регионах, то следует расмотреть вопрос распределения экземпляров сервисов по регионам, убедившись что в каждом регионе будет достаточно мощностей для обработки требуемой нагрузки.
На графиках ниже показано, как географическая распределенность пользователей может повлиять на пропускную способность и латентность. Постоянный поток запросов в течении трех минут отправлялся на сервис. Данный сценарий использовался для двух тестов — в первом клиенты и сервер были расположены в одном регионе, а во втором — в разных. На обоих графиках левая ось показывает производительность в операциях в секунду, а правая — время отклика в секундах.
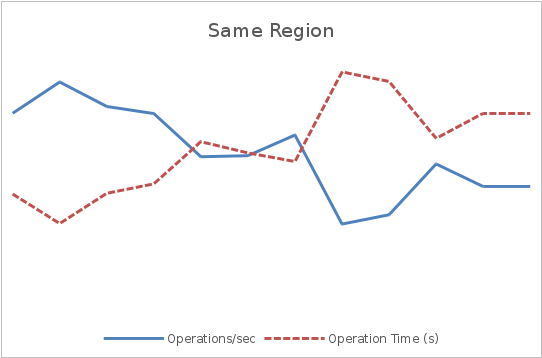
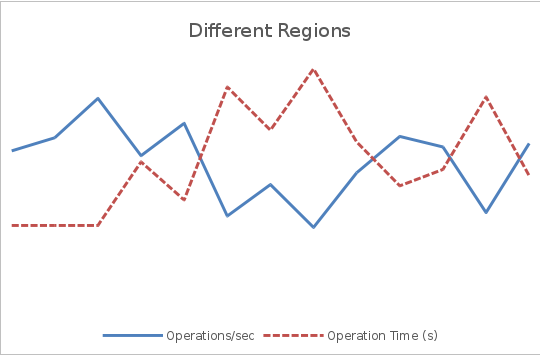
На первом графике средняя пропускная способность оказывается в несколько раз выше, чем во втором, а время отклика составляет примерно ¼ времени отклика второго графика.
Размер полезной нагрузки сообщения, проходящего по сети
Размер тела запросов и ответов может оказать существенное влияние на пропускную способность. XML-запросы могут быть существенно больше, чем их эквиваленты в формате JSON. Бинарно-сериализованные данные могут быть более компактными, но менее гибкими. Помимо потребления полосы пропускания, большие запросы приводят к дополнительной нагрузке на CPU, затрачиваемой на разбор или десериализацию данных.
Следующие графики иллюстрируют влияние различных размеров запросов на пропускную способность и время отклика. Как и прежде, на обоих графиках использовался один и тот же тестовый сервис. Клиенты и сервис расположены в одном регионе.


Здесь видно, что увеличение размера сообщения в 10 раз привело к снижению пропускной способности и увеличению времени отклика. Следует отметить, что это искусственный тест, ориентированный на демонстрацию сетевого трафик. Здесь не учитываются дополнительные процессы, необходимые для обработки запросов, а также отсутствует влияние стороннего сетевого трафика, генерируемого другими клиентами или сервисами.
«Болтливость» в сети
“Болтливость” (chattiness) является другой распространенной причиной сетевых задержек. Болтливостью называют частоту сетевых сессий, необходимых для выполнения бизнес-операции.
Для обнаружения “болтливости” все операции должны включать телеметрию, фиксирующую частоту вызова, а также кем и когда они были вызваны. Телеметрия должна включать размер сетевых запросов на входе и выходе операции. Большое число относительно мелких запросов в короткий промежуток времени, отправленных одним и тем же клиентом, может указывать на необходимость оптимизации системы путем объединения этих запросов в один или несколько. В качестве примера, на рисунке показана телеметрия тестового Web API сервиса. На каждый вызов API происходит один или более запросов в Azure SQL. Во время проведения мониторинга средняя пропускная способность составляла 13900 запросов в минуту. На рисунках также видна телеметрия БД, на которой видно, что за этот промежуток времени сервис сделал более 250000 запросов к БД. Эти цифры указывают на то, что при каждом вызове Web API в среднем происходит 18 вызовов к БД.


Вызовы к БД, происходящие при запросах к приложению
Использование CPU на уровне сервера и экземпляра
Загрузка (утилизация) CPU является мерой, измеряющей количество работы машины, а “доступность” CPU показывает количество запасных мощностей процессора, которые имеет машина для обработки дополнительной нагрузки. Используя APM, вы можете получать эту информацию для конкретного сервера, на котором запущен веб-сервис или облачное приложение. Рисунок показывает статистику New Relic.

Веб-портал Azure позволяет просматривать данные CPU для каждого экземпляра сервиса.

Использование CPU для экземпляров сервиса на портале Azure
Высокая утилизация CPU может быть следствием большого количества исключений, генерация которых перегружает процессор.
Вы можешь отслеживать частоту возниковения исключений, используя подходы, описанные ранее в соответствующих секциях. Чрезмерная утилизация процессора может быть обусловлена приложениями, в которых происходит частая сборка мусора больших объектов. Вы должны исследовать счетчики CLR Garbage Collections согласно описанию в разделе «Использование управляемой памяти», чтобы оценить влияние сборщика мусора (GC) на общую загрузку процессора. Вы также должны убедиться, что в вашей системе правильно настроена политика сборки мусора (подробнее см. Fundamentals of Garbage Collection).
Низкая утилизация CPU в совокупности с высокой латентностью может быть связана с различными блокировками, что может означать наличие проблем в коде, таких как неправильное использование блокировок или ожиданий выполнения синхронных I/O операций (подробнее см. антипаттерн Synchronous I/O).
Процессорное свойство affinity (привязка процесса к конкретному процессору) может привести к тому, что процессор или ядро процессора окажется узким местом. Такая ситуация может возникнуть в облачном приложении в Azure с Worker-ролью. Запросы от Web-роли могут всегда направляться на кокретную Worker-роль в обход балансировщика нагрузки.
Использование CPU на конкретном сервере
- Processor\%Privileged Time количество времени, которое тратит процессор на работу в привилегированном режиме. Постоянно-высокое значение этого счетчика показывает, что система тратит значительное время, выполняя функции операционной системы и может быть вызвано большими объемами операций I/O, постоянными блокировками процессов или потоков, чрезмерной подкачкой или накладными расходами при управлении памятью (например, при сборке мусора).
- Processor\%User Time, время, котрое тратит процессор на выполнение кода приложения, а не системных функций.
- Processor\%Processor Time общая загрузка процессора (в пользовательском и привилегированном режимах). Обычно загрузка процессора колеблется между высокими и низкими значениями, но постоянно высокий уровень (свыше 80%) означает, что процессор может являться узким местом. Например, антипаттерн Busy Front End показывает ситуацию, когда нагрузка изначально сосредоточена на одной Web-роли, а также рассказывает то, как улучшить время отклика при использовании очереди для переноса обработки данных на отдельные рабочие роли.
Процессы, активно потребляющие CPU
Вы можете исследовать возможные причины высокой загрузки процесса в тестовой среде во время нагрузочного тестирования. Такой подход должен помочь ликвидировать влияние внешних факторов. Многие APM-инструменты поддерживают профилировку потоков для анализа выполнения процессором стека операций. Рисунок показывает пример профилировки в New Relic.
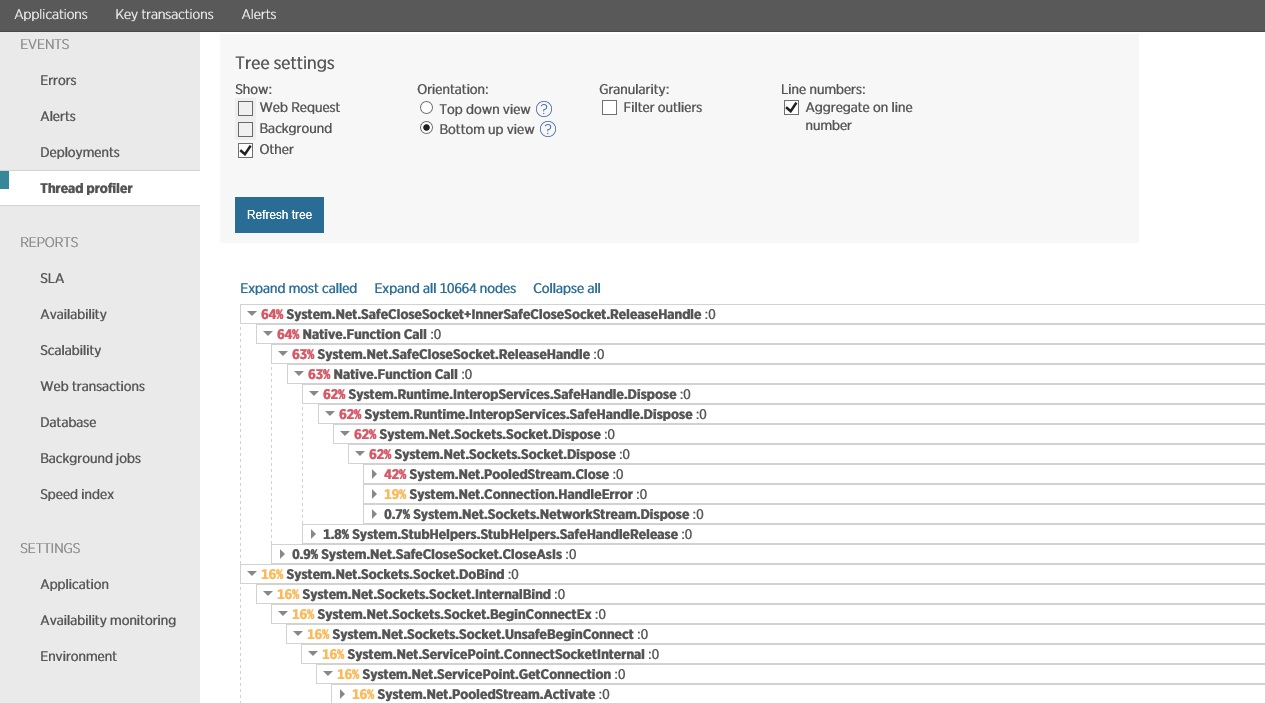
Профилировка в New Relic
После проведения профилировки за определенный период времени, New Relic позволяет анализировать эту информацию и исследовать операции которые затрачивают наибольшее процессорное время. Полученная информация может стать сигналом к оптимизации кода.
Эта техника является очень мощным инструментом, но она может оказывать существенное влияние на производительность реальных пользователей. Таким образом, при проведении данного процесса на реальной среде, вы должны сразу выключать профилировщик после сбора данных.
Использование диска
Высокая частота операций ввода-вывода (I/O) обычно вызвана такими задачами, как бизнес-аналитика или обработка изображений. Кроме того, многие сервисы хранения данных (например, Azure SQL БД, Azure Storage и Azure DocumentDB) активно используют ресурсы диска. Если вы создаете виртуальные машины для запуска ваших сервисов, то вам может понадобиться мониторинг доступа к диску. Это нужно, чтобы убедиться, что вы выбрали правильную конфигурацию диска для обеспечения хорошей производительности.
Приложения с интенсивным использованием памяти также могут инициировать значительную дисковую активность. Перерасход памяти может привести к увеличению размеру и, как следствите, уменьшению производительности. В этом случае может потребоваться горизонтальное масштабирование роли, для перераспределения нагрузки по нескольким экземплярам, но перед этим следует проанализировать ваше приложение на предмет правильного использования памяти (причиной может быть банальная утечка).
В Azure виртуальные диски (которые используются в виртуальных машинах) создаются в Azure Storage. На сегодняшний день существует два типа Azure Storage: стандартный и Premium. Производительность вирутальных дисков измеряется в количестве операций ввода-вывода в секунду, а пропускная способность в МБ в секунду. IOPS (количество операций ввода/вывода – от англ. Input/Output Operations Per Second) – это стандартный показатель производительности различных видов хранилищ. Стандартное хранилище позволяет обрабатывать до 500 операций ввода-вывода в секунду при максимальной производительности 60 Мб/сек. Premium-хранилище основано на SSD-накопителях и может работать со скоростью до 5000 операций ввода-вывода и обеспечивать пропускную способность в 200 Мб/сек.
Использование RAID-дисков в конфигурациях виртальных машин может увеличить пропускную способность, но в этом случае контроль за выполнением I/O запросов будет осуществляться на уровне самой виртуальной машины. Подробнее см. Sizes for Virtual Machines.
Примечание: IOPS и пропускная способность измеряют разные аспекты производительности I/O-операций. Приложение, выполняющее большое число небольших дисковых операций, скорее всего, упрется в лимит по IOPS вне зависимости от пропускной способности. Приложение, выполняющее мало операций с большими данными, может достичь лимита пропускной способности прежде чем достигнет лимита по IOPS. Для максимальной производительности приложениям необходимо балансировать между частотой I/O операций и размерами данных.
Вы можете измерять производительность различных дисков (конфигураций) используя SQLIO Disk Subsystem Benchmark Tool. Для примера, если запустить данную утилиту на виртуальной машине на стандартных дисках, то вы получите следующий результат:

Производительность I/O одного стандартного диска на виртуальной машине
Видно, что диск, как и ожидалось, может обрабатывать порядка 500 операций ввода вывода. Этот же тест, но на RAID-массиве, состоящем из 4-х дисков (каждый из которых находится в стандартном Azure Storage) показывает следующие результаты.

Производительность I/O на striped-диске
В этом случае производительность достигает 1400 IOPS. Используя данную технологию с дисками Premium-хранилища, вы можете достичь производительности 80000 IOPS и низкой задержки операций чтения.
Обратите внимание, что за регулирование (ограничение) пропускной способности отвечает сама платформа Azure. Оно может возникать, если ваше приложение превысит IOPS или пропускную способность Premium-диска (5000 IOPS) или если суммарный трафик через все диски (в случае RAID) превысит дисковый предел виртуальной машины. Чтобы избежать этого, вы должны ограничить количество незавершенных (ожидающих) I/O запросов к диску максимальным значением IOPS используемого вида стораджа или же общей дисковой пропускной способности вашей виртуальной машины. Подробнее см. Premium Storage: High-Performance Storage for Azure Virtual Machine Workloads.
Портал Azure позволяет контролировать общую пропускную способность I/O операций виртуальной машины. Многие же APM-инструменты предоставляют информацию об активности отдельных дисков. На примере ниже показана производительность диска, полученная в New Relic. Собираемая статистика включает количество I/O-операций, позволяя вам увидеть, насколько вы близко к лимитам. Обратите внимание, что, когда утилизация диска составляет 100%, то показатель IOPS равен примерно 1500. Это соответствует максимальной пропускной способности для RAID`а из 4-х дисков (стандартное хранилище):
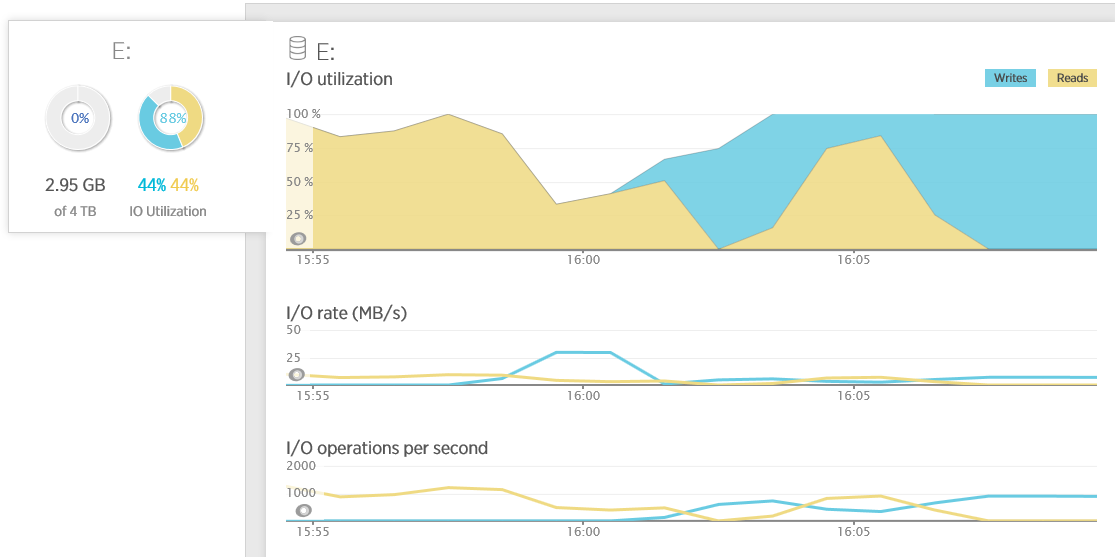
- Avg. Disk sec/Read и Avg. Disk sec/Write. Это среднее время (в секундах) операций чтения и записи. Время ожидания диска сильно зависит от программного обеспечения и дискового кеша, но данные счетчики являются надежными показатели производительности диска. Для содержимого (payload) размером меньше 64 КБ пороговое значение этих счетчиков меньше 15 мс является очень хорошим значением. Однако из-за неустойчивой модели I/O операций в устройствах хранения данных, вполне нормально увидеть, что периодически это значение в пике может оказаться в несколько раз выше ожидаемого.
- Disk Transfers/sec. Это скорость выполнения диском операций чтения и записи. Следует отметить, что данная скорость для одного диска, в зависимости от размера данных, может оказаться выше его IOPS. Этот счетчик поможет определить суммарную пропускную способность I/O-операций на диске. Оборудование диска и производительность могут значительно отличаться, поэтому нет никакого универсального порогового значения для данного счетчика. С учетом выше сказанного попробуем установить уровень производительности для диска а затем сравним его с базовым. Например, если вы знаете, что диск поддерживает 100 обращений в секунду при времени отклика 10 мс, то при тестировании вы можете найти время отклика в 50 мс и пропускную способность 20 обращений в секунду. Это указывает на существенное замедление оборудования диска (например, физический диск используют несколько серверов). В этом случае может потребоваться распределить нагрузку на несколько дисков или перейти на более мощные виртуальные машины.
- Disk Bytes/Sec, Disk Read Bytes/sec и Disk Writes Bytes/sec. Вы можете использовать данные счетчики для определения того, как размер запросов влияет на производительность. Запрос размером в 1 MB в 256 раз больше запроса размером в 4 КВ, поэтому для его обработки требуется больше времени. Если вы обнаружите, что среднее время выполнения запросов окажется больше 15 мс, то следует проверить средний размер I/O запросов, используя счетчики Avg. Disk Bytes/Read и Avg. Disk Bytes/Write
- Avg. Disk Queue Length, Avg. Disk Read Queue Length, and Avg. Disk Write Queue Length. Эти счетчики измеряют количество дисковых I/O операций, ожидающих обработки (в очереди). Эти счетчики вычисляются по формуле:
- Avg. Disk Queue Length = (Disk Transfers/sec) * ( Disk sec/Transfer)
Эти счетчики очень важны для приложений с большой дисковой активностью, т.к. есть вероятность появления в таких приложениях длинных очередей доступа к диску. - % Idle Time. Этот счетчик показывает процент времени простаивания диска. Диск простаивает при отсутствии запросов. Этот счетчик не такой полезный, как кажется. Пока длина очереди диска 1 или более, то %idle time для этого диска 0. Используя данный счетчик, вы можете определить только промежутки времени, когда диск ничего не делал, а не общую занятость диска (для этой цели используйте счетчики длины очереди).
Сервисные метрики
Большинство облачных приложений и сервисов Azure зависят от одного или нескольких внешних сервисов, выполняющих функции хранения, кэширования и обмена сообщениями. Производительность этих сервисов может оказать значительное влияние на систему, поэтому очень важно отслежить их работу.
Общий вопрос, рассматриваемый в этом разделе, связан с внешним давлением (backend pressure). Это явление, которое происходит, когда приложение отправляет внешним сервисам объем работы, который они не могут выполнить. Это может привести к увеличению латентности и снижению пропускной способности приложения. Кроме того, временами подключения к внешим сервисам могут обрываться или же сервисы могут выбрасывать исключения.
Как собирать?
Портал Azure предоставляет информацию по различных сервисам Azure (Storage, SQL DB, Service Bus и т.п.). Зачастую данная информация оказывается более подробной собираемой сторонними APM.
Зависимые сервисы могут также предоставлять свои собственные метрики уровня приложения. Данные метрики часто бывают полезными для определения доступности или приближения к лимиту пропускной способности. Примеры включают в себя информацию об использовании соединений, возникновении исключений проверки подлинности для служб безопасности, приближении к ограниченям квоты хранилища. Эти исключения очень важны в контексте распределенных систем, потому что могут указывать на наличие высокого внешнего давления или ошибок сервисов.
Все внешние службы, участвующие в выполнении бизнес-операций, следует контролировать на предмет сбоев и нарушений SLA. По возможности следует также перехватывать детали исключений. Ниже кратко описан мониторинг некоторых часто- используемых сервисов Azure. Обратите внимание, что описана будет только часть из наиболее важнейших показателей, т.к. охватить их все не представляется возможным.
Латентность Azure Storage
Многие приложения для хранения данных в табличном и блоб представлениях используют Azure Storage. Например, диски для виртуальных машин создаются в блоб-хранилище. Cквозной (end-to-end) мониторинг задержки операций Azure Storage может дать вам понимание, почему приложение работает медленно.
Портал Azure предоставлят диагностику Azure Storage, которая включает сквозную задержку запросов к хранилищу и среднюю задержку сервера блоб-объектов. Сквозная задержка измеряется на стороне клиента и влючает различные сетевые задержки, в то время как серверная измеряется только на стороне сервера.

Метрики латентности на портале Azure
Объем трафика и троттлинг в Azure Storage
Вы должны анализировать размер и скорость обработки запросов хранилищем. Azure Storage масштабируется и имеет целевые показатели производительности. Данные показатели основаны на типе хранилища (Premium имеет более высокие показатели производительности). Если ваше приложение достигнет предельного значения целевого показателя вашего типа хранилища, то производительность будет автоматически снижена. Важно понимать, что лимиты базируются на определенном размере запросов, а размеры запросов вашего приложения могут быть различными.
Вы можете просматривать объем входящих и исходящих данных в хранилище с помощью портала Azure. Кроме этого, вы можете контролировать число происходящих ошибок автоматического регулирования. Частое регулирование указывает на необходимость оптимизации вашего приложения либо перехода на более мощный тип хранилища.

Входящие и исходящий трафик в хранилище, а также ошибки на портале Azure
Ошибки подключения к Azure SQL
Частые сбои подключений к таким сервисам, как Azure SQL Database, могут означать, что сама база по какой-то причине недоступна или количество доступных подключений исчерпано. Вы можете просматривать состоянии базы данных в портале Azure как показано ниже.

Доступность базы данных на портале Azure
Azure SQL Database контролируется Microsoft. Microsoft же обеспечивает SLA, гарантирующий доступность БД на уровне 99.9%. Следовательно, наиболее вероятной причиной сбоя соединений (за исключением использования неправильных строчек подключений) является отсутствие доступных ресурсов для подключения.
Ресурсы подключений могут истощаться, если экземпляр приложения делает слишком много одновременных подключений или наоборот, если число экземпляров превышает число соединений, которое поддерживает ваша БД или приложение (например, размер пула соединения слишком маленький). Вы можете отслеживать количество ошибок подключений с помощью APM, которая контролирует взаимодействие между вашим приложением и базой данных. Пример ниже показывает отчет New Relic по ряду ошибок соединений и связанных с ними исключений. В этом случае приложение использует слишком много соединений из пула, в результате чего некоторые последующие запросы падают в тайм-ауте.
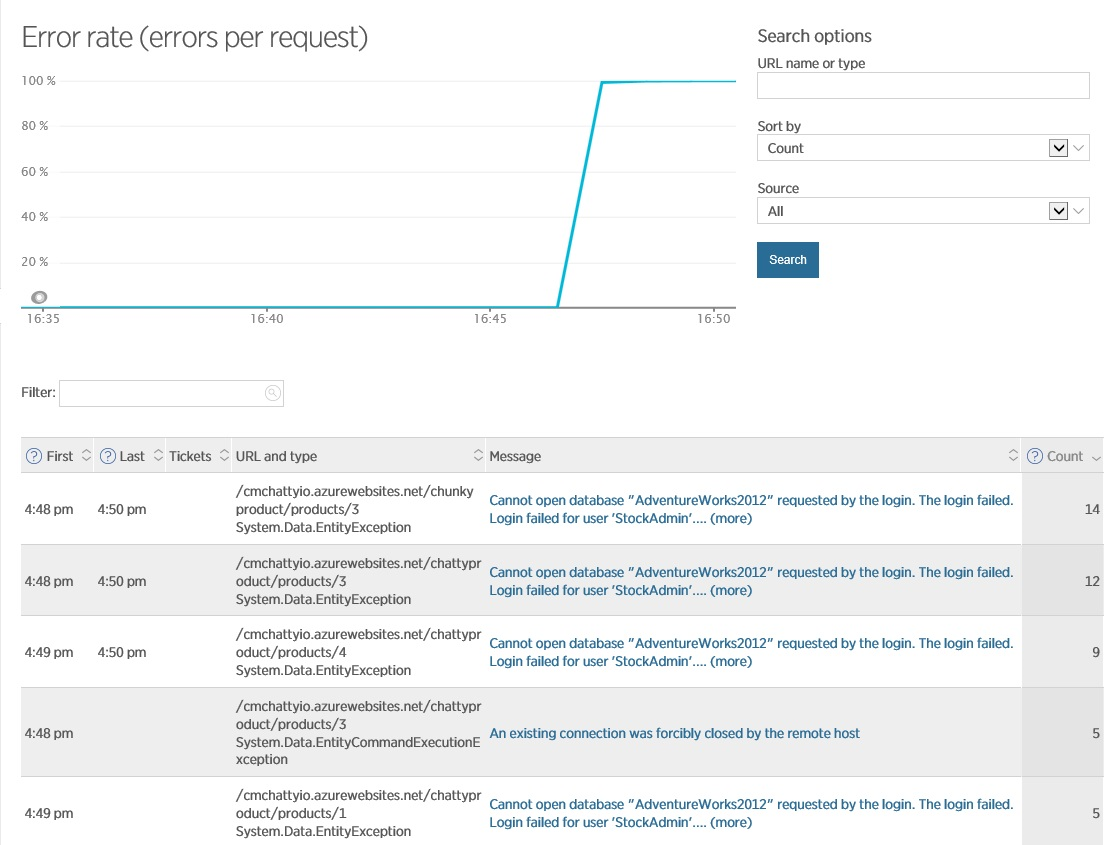
Ошибки подключения к базе данных в New Relic
Регулирование подключений может осуществиться и на уровне базы данных, если скорость поступающих запросов существенно возрастет. Это механизм безопасности для предотвращения серверных сбоев. Регулирование подключений может быть вызвано большим объемом запросов, каждый из которых требует значительных ресурсов процессора (например, с участием сложных запросов, хранимых процедур или триггеров). Вы можете контролировать частоту регулирования на портале Azure.
Azure SQL Database DTU
Выделение ресурсов для экземпляров AZURE SQL database измеряется в Database Throughput Units, или DTU. DTU является метрикой, сочетающей в себе использование процессора, памяти и I/O операций. Вы приобретаете базу данных SQL Azure, выбирая определенный уровень производительности. Различные уровени производительности включают различное количество DTUs (от 5 DTU на базовом уровне и до 1750 на уровне Premium/P11). Если приложение превышает выбранную для него квоту DTU, то включается автоматический механизм регулирования, который может замедлять или прерывать запросы. Вы можете отслеживать, как ваше приложение использует DTU базы данных, через портал Azure. На рисунке показано, как большая вспышка активности использования базы данных влияет на использование ресурсов.

Мониторинг DTU на портале Azure
Переиспользование ресурсов Azure SQL
Более высокие уровни производительности дают больше мощностей процессора, памяти и доступного места, но и являются более дорогими, поэтому вы должны внимательно следить за тем, как ваше приложение использует ресурсы базы данных. Доступ к базе данных тщательного регулируется для обеспечения необходимых ресурсов в пределах выбранного уровня производительности. Если нагрузка превышает допустимый предел для одного из показателей CPU, Data I/O, Log I/O, то вы, вероятно, продолжите получать ресурсы, но латентность будет выше. Эти ограничения не приведут к ошибкам, но при дальнейшем повышении нагрузки замедление начнет приводить к таймаутам запросов (как описано ранее).
Вы можете использовать Dynamic SQL для получения статистических данных о ресурсах, запросах и различных операциях, которые выполнялись в базе данных за последний час. В следующем запросе происходит получение данные из динамического административного представления sys.dm_db_resource_stats, и вы можете видеть, как потребление ресурсов базой данных соотносится с выбранным вами уровнем производительности (здесь предполагается, что ваша база данных должна использовать ресурсы в пределах 80%).
Если этот запрос для любой из 3-х запрашиваемых метрик вернет значение меньше 99.9%, то вам следует рассмотреть вопрос о переходе на более высокий уровень производительности БД либо произвести оптимизацию по снижению нагрузки на БД.
Эта информацию также доступна на портале Azure:

Статистика Azure SQL на портале Azure
Производительность запросов
Неэффективные запросы к базе данных могут существенно влиять на латентность и пропускную способность, а также могут служить причиной чрезмерного потребления ресурсов. Вы можете извлекать информацию о запросах из динамичесих представлений и визуализировать эти данные на портале Azure SQL На странице Query Performance отображены совокупные статитические данные по выполненным запросам за последний час, включая использование процессора и I/O операции для каждого запроса:

Производительность запросов на портале Azure SQL
Вы можете производить детализацию наиболее тяжелых запросов, просматривая планы их выполнения. Эти данные могут помочь определить причины долгого выполнения запросов, а также выполнить их оптимизацию.

План выполнения запросов на портале Azure SQL
Большое количество запросов к БД
Большие объемы трафика между приложением и базой данных могут указывать на отсутствие кэширования. Вы должны анализировать извлекаемые данные, т.е., например, когда ваше приложение постоянно запрашивает и обновляет одни и те же данные, кэшировать их локально в приложении или в общем распределенном кэше. Страница Query Performance на портале Azure SQL предоставляет полезную информацию в виде графа выполнения, а также количества выполнений (Run Count) для каждого запроса.
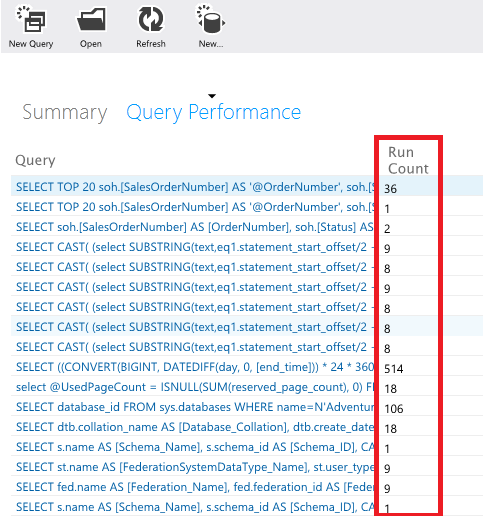
Мониторинг частоты запросов на портале Azure SQL
Запросы, которые выполняются очень часто (имеют высокий Run Count) не обязательно возвращают одни и те же данные (некоторые запросы параметризированы специальным оптимайзером), но могут выступать в качестве отправной точки для определения кандидатов для кэширования.
Дедлоки в Azure SQL
В некоторых неоптимальных транзакциях могут возникать взаимоблокировки (дедлоки). При возникновении дедлока, необходимо провести откат транзакции (rollback) и повторно выполнить ее позднее. Частые дедлоки могут привести к существенному снижению производительности. Вы можете отслеживать дедлоки на портале Azure SQL, и при их возникновении анализировать трассировку приложения в рантайме для определения причины.
Латентность Service Bus
Высокие уровни задержки при доступе к Service Bus (слушебная шина, далее SB) могут оказаться боттлнеком производительности. Они могут быть обусловлены рядом причин, в том числе сетевых (например, потеря пакетов, связанных с удаленностью пространства имен SB от клиента), конкурентностью внутри SB (топиков, очередей, подписок, event hubs и ошибок доступа. Портал Azure предоставляет ограниченный набор метрик производительности SB для очередей, топиков и концентраторов событий. Тем не менее, можно получить более подробную информацию о производительности (латентность операций отправки и получения, ошибок соединения и т.п.), добавив в код вашего приложения сбор счетчиков Microsoft Azure Service Bus Client Side Performance Counters (https://www.nuget.org/packages/WindowsAzure.ServiceBus.PerformanceCounters)
Отказ в подключении к Service Bus и троттлинг
Очереди, топики и подписки SB имеют квоты, которые могут ограничивать их пропускную способность. Например, к ним относится максимальный размер очереди или топика, количество одновременных соединений и одновременных запросов. При превышении данных квот SB начнет отвергать дальнейшие запросы. Подробнее см. azure.microsoft.com/documentation/articles/service-bus-quotas. Вы можете контролировать объем трафика, проходящий через очереди и топики SB, на портале портал Azure.
Объем концентратора событий определяется в пропускных единицах и устанавливается при создании. Одна пропускная единица приравнивается к скорости 1 MB/s для входящего трафика (ingress) и 2 MB/s для исходящего трафика (egress). Если приложение превышает установленное количество пропускных единиц, то скорость получения и отправки данных будет урезана. Как в случае с очередями и топиками, вы можете контролировать скорость концентратора событий на портале Azure. Следует отметить, что квоты на входящий и исходящий трафик применяются отдельно.
Проваленные запросы и Poison Message в Service Bus
Контролируйте частоту ошибок обработки сообщений и общий объем ядовитых (poison) сообщений, для которых превышено допустимое число обработок. В зависимости от проектирования приложения, даже одно ошибочное сообщение может затормозить всю систему. Анализируйте неудачные запросы и poison-сообщения.
Исключения, связанные с квотами Event Hub
Облачные приложения могут использовать концентратор событий Azure как хранилище для агрегирования больших объемов данных (в виде асинхронных событий), получаемых от клинтов. Концентратор событий поддерживает высокую скорость входящих событий с низкой задержкой и высокой достуностью, и используется в сочетании с другими сервисами, которым он передает события для дальнейшей обработки.
Емкость концентратора событий контролируется количеством единиц пропускной способности, которые устанавливаются во время покупки. Одна единица поддерживает:
* Ingress: до 1MB данных в секунду или 1000 событий в секунду.
* Egress: до 2MB в секунду.
Входящий трафик регулируется количество доступных единиц пропускной способности. При превышении возникают исключения «quota exceeded». При превышении исходящего трафика исключения не происходят, но скорость ограничивается объемом единиц пропускной способности (в базовом варианте 2 MB в секунду).
Вы можете контролировать работу концентратора событий путем просмотра панели мониторинга на портале Azure:

Мониторинг Event Hubs на портале Azure
Если вы наблюдаете появление исключений, связанных с количеством публикаций или не видите ожидаемых показателей исходящего трафика, проверьте количество единиц пропускной способности, установленном для вашего проекта, на портале Azure на странице Scale.

Выделение пропускной способности для Event Hub
Ошибки с лизингом Event Hub
Приложение может использовать объект __EventProcessorHost_ для распределения рабочей нагрузки по потребителям (consumers) событий. Объект __EventProcessorHost_ создает блокировку блоба Azure Storage для каждого раздела концентратора событий и использует эти блобы для управления разделами (получение и отправка событий). Каждый экземпляр _EventProcessorHost_ выполняет две функции:
1. Продление блокировок: блокировка в настоящее время находится в собственности экземпляра и при необходимости периодически продлевается
2. Создание блокировок: каждый экземпляр непрерывно проверяет все существующие блокировки на предмет просроченности и если такие находятся, то происходит их блокировка
Вы должны следить за частотой возникновения повторных обработок сообщений и блокировок блобов.
Использование зависимых сервисов
Помимо Storage, SQL Database и Service Bus, существует большое количество сервисов Azure, и их число постоянно растет. Не представляется возможным охватить каждый сервис, но вы должны быть готовы контролировать ключевые аспекты, которые предоставляет каждый из используемых вами сервисов. В качестве примера, если вы используете Azure Redis Cache для реализации общего кэша, вы можете определить его эффективность, анализируя следующие вопросы:
* Cколько данных попадает и не попадает в кэш каждую секунду?
Эта информация доступна на портале Azure:
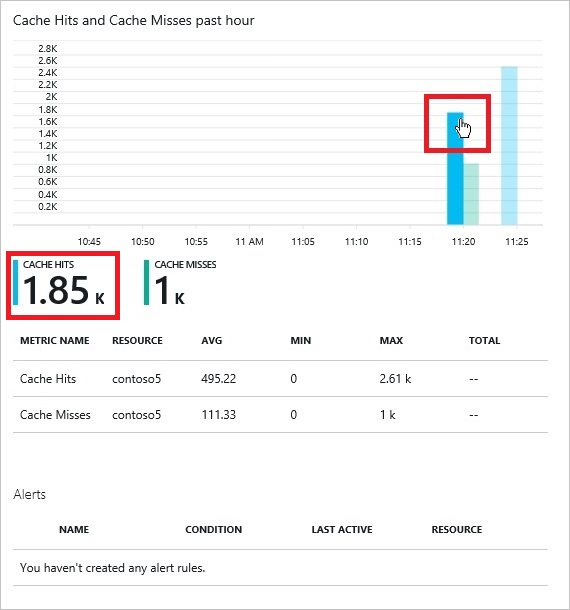
Мониторинг Azure Redis Cache на портале Azure
После того как система достигла полностью рабочего состояния, и при этом коэфициент кэширования оказывается низким, то, возможно, вам необходимо скорректировать стратегию кэширования.
Cколько клиентов подключается к распределенному кэшу?
Вы можете контролировать количество подключенных клиентов с помощью портала Azure.
Лимит одновременных подключений составляет 10000. При достижении данного предела последующие попытки подключения обрываются. Если ваше приложение постоянного достигает этого предела, то вам следует рассмотреть возможность распределения кэша между пользователями.
Сколько операций (получения и записи) происходят в кластере кэша каждую секунду?
Вы можете просматривать счетчики Gets и Sets на портале Azure.
Сколько данных хранится в кластере кэша?
Счетчик Used Memory на портале Azure показывает размер кэша. Общий допустимый размер кэша устанавливается во время создания.
Какой уровень задержек при доступе к кэшу?
Вы можете отслеживать счетчики Cache Read и Cache Write на портале Azure для определения скорости чтения и записи кэша (измеряется в KB/s).
На сколько занят сервер кэша?
Контролируйте счетчик Server Load на портале Azure. Этот счетчик показывает процент времени, когда Redis Cache сервер занят обработкой запросов. Если этот счетчик достигнет значения 100%, то это значит, что процессорное время Redis Cache сервера достигло максимума, и сервер не сможет работать быстрее. Если вы наблюдаете устойчивую высокую нагрузку на сервер, то, вероятно, некоторые запросы будут падать в таймауте. В этом случае вам следует рассмотреть возможность увеличения ресурсов кэша или произвести секционирование данные по нескольким кэшам.
5.1. Счетчики производительности
В объектах, выполняющих мониторинг производительности, содержатся функциональные элементы, которые называются счетчиками производительности. Они производят анализ определенных параметров. Например, объект жесткого диска может вычислять скорость передачи, в то время как объект процессора может вычислять процессорное время.
Чтобы получить доступ к данным или начать их сбор, вначале необходимо создать объект и получить доступ к его функциям. Это осуществляется с помощью вызова пользовательского интерфейса или другого процесса функции create (создать). Как только объект создан и вызваны его функции сбора данных, он начинает собирать данные и сохранять их в различных свойствах. Данные могут направляться на диск, в файлы, в память (оперативную) и другие компоненты, которые их обрабатывают и представляют в определенном виде. На основе объектов производительности реализуются два метода сбора данных и подготовки отчета. Любая из этих форм отнимает определенные ресурсы системы.
1. Объекты могут осуществлять выборки данных. Это означает, что сбор данных производится периодически, а не тогда, когда происходит определенное событие. Преимущество такого отбора – память задействуется не постоянно, а через определенные периоды времени. Недостаток – полученные данные не всегда точно отображают ситуацию, так как активность системы может наблюдаться между осуществлением выборок.
2. Другим методом сбора данных является трассировка событий. Она дает возможность собирать данные тогда, когда происходят определенные события. Например, можно наблюдать за использованием памяти каким-то приложением, когда оно выполняет определенную функцию, или отслеживать, при каких условиях оно освобождает память. Достоинство – данный метод не позволяет пропускать ни одно событие. Недостаток – для отслеживания событий требуется гораздо больше ресурсов, чем для реализации выборок.
Счетчики могут сообщать свои значения одним из двух способов: осуществляя непрерывный подсчет; осуществляя подсчет средних значений. Непрерывный счетчик показывает данные по мере их поступления. Он дает мгновенный снимок этих данных. При подсчете средних значений их приходится получать с помощью подсчета и вычислений. Таким образом можно узнать количество бит в секунду, страниц в секунду и т.д. Некоторые счетчики могут выдавать процентное соотношение или разницу.
5.2. Мониторинг системы
Чтобы поддержать должный уровень обслуживания и чтобы серверы и приложения были в полной готовности, необходимо иметь информацию не только о характеристиках ЭВМ, но и о работающих приложениях или ресурсах. При этом недостаточно иметь субъективное мнение о том, как предположительно работает система. Необходимо знать точные параметры этой работы. Если вы только начинаете мониторинг системы, то вам ее, в основном, не с чем сравнивать. Лишь после того как накоплено значительное количество данных, на их основе следует выработать базовый критерий, на который можно опираться при последующих наблюдениях. Если производительность системы отклоняется от установленных базовых критериев, значит, в системе появляются узкие места. Рассмотрим минимальный рекомендуемый набор требований, необходимых при мониторинге производительности. Определим следующие параметры мониторинга.
1. Ресурс – диск, объект – логический диск, пороговое значение счетчика свободного пространства – 15 %. Так как не для всех процессов можно установить блокировку дискового пространства, то необходимо ограничить расходование пространства логического диска квотой 85 %. При этом необходимо сделать настройку сигналов тревоги, которые оповещали бы о превышении порогового значения.
2. Ресурс – диск, объект – логический диск, пороговое значение времени использования – 80 %. Имеется ввиду, что диск не должен использоваться более 80 % всего времени работы системы. При этом необходимо проверить, соответствует ли это значение рекомендациям производителя.
3. Ресурс – диск, объект – физический диск, пороговое значение счетчика операций чтения диска выбирается исходя из спецификации производителя. Информация о скорости считывания диска печатается на корпусе самого диска. Программа передает оповещение, если монитор производительности сообщает о том, что значение частоты обращения к диску превысило то, которое указано на диске.
4. Ресурс – память, объект – оперативная память, пороговое значение счетчика объема доступных файлов – 4 Мбайта. Если объем памяти снижается ниже 4 Мбайт, то страничный обмен начинает возрастать, а скорость реакции системы начинает идти на спад. Необходимо выработать сообщение об ошибке, в котором отразить, что системных ресурсов осталось мало.
5. Ресурс – память, объект – оперативная память, пороговое значение счетчика вывода страниц в секунду – 20. Если использование памяти растет, необходимо проверить, не превышает ли это пороговое значение базового показателя.
6. Ресурс – сеть, объект – сегмент сети, пороговое значение счетчика использования сети – 30 %. Это значение существенно зависит от типа сети.
7. Ресурс – процессор, объект – процессор, пороговое значение времени использования процессора – 85 %. Значение счетчика процент времени процессора (% Processor Time) можно наблюдать в панели диспетчера задач. Использование процессора свыше 80 % общего времени является поводом для беспокойства администратора.
8. Ресурс – процессор, объект – процессор, пороговое значение счетчика прерываний в секунду – 1500. Если значение счетчика резко увеличивается без соответствующего увеличения активности процессора сервера, то причиной этого могут быть неисправности аппаратной части ИС, дискового контроллера, сетевого интерфейса и т.д.
9. Ресурс – сервер, объект – сервер, пороговое значение счетчика Byte total/sec определяется максимальной скоростью передачи в сети. Для всех серверов в сети можно просуммировать значения их соответствующих счетчиков и, если суммарный результат равен или превышает максимальную скорость передачи, допустимую в сети, то требуется выработать соответствующий тревожный сигнал.
10. Ресурс – сервер, объект – рабочие очереди сервера, пороговое значение счетчика длины очереди 4. Данный счетчик может указывать на “узкое место” процессора. Значение длины очереди необходимо наблюдать в течение нескольких интервалов выборки.
11. Ресурс – многопроцессорная система, объект – система, пороговое значение очереди процессора равно 2. Если в течение нескольких интервалов наблюдения значение счетчика превышает 2, то системному администратору следует разобраться в причинах такой работы системы.
Счетчики процессора и процессов
В следующей таблице приведены сведения о счетчиках процессора и процессов.
Процессор(_Total)\% загруженности процессора
Показывает время выполнения процессором приложения или процессов операционной системы (в процентах). Используется, если процессор выполняет операции.
В среднем значение должно быть меньше 75%.
Процессор(_Total)\% времени в пользовательском режиме
Показывает время работы процессора в пользовательском режиме (в процентах). Пользовательский режим — это ограниченный режим работы процессора, предназначенный для приложений, подсистем обеспечения среды и интегрируемых подсистем.
Должно быть меньше 75%.
Процессор(_Total)\% времени в привилегированном режиме
Показывает время работы процессора в привилегированном режиме (в процентах). Привилегированный режим — это режим работы процессора, предназначенный для компонентов операционной системы и драйверов устройств. Этот режим обеспечивает прямой доступ к оборудованию и всей памяти.
Должно быть меньше 75%.
Если для общей загруженности процессоров отображается большое значение, используйте этот счетчик, чтобы определить, какой процесс вызывает высокую загрузку ЦП.
Процесс(*)\% загруженности процессора
Показывает время процессора (в процентах), затраченное всеми потоками процессов на выполнение инструкций. Инструкция — это элементарная единица выполняемых компьютером действий. Поток — это объект, выполняющий инструкции, а процесс — это объект, который создается при выполнении программы. Данное значение может учитывать код, выполненный при обработке некоторых аппаратных прерываний и исключений.
Если для общей загруженности процессоров отображается большое значение, используйте этот счетчик, чтобы определить, какой процесс вызывает высокую загрузку ЦП.
Система\Длина очереди процессора (все экземпляры)
Показывает количество потоков, которые обслуживает каждый процессор. Счетчик «Длина очереди процессора» можно использовать, чтобы определить, не вызваны ли проблемы с процессором или высокая загрузка ЦП тем, что его мощности недостаточно для обработки назначенной ему нагрузки. Этот счетчик показывает количество задержанных потоков в очереди процессора «Готово», которые ожидают планирования выполнения. Указанное значение — это последнее зарегистрированное значение во время измерения.
Значение не должно превышать 5 (для каждого процессора).
На компьютере с одним процессором очередь, длина которой больше 5, является признаком того, что объем загрузки превышает возможности обработки процессора. Если данное число больше 10, это явный показатель того, что ресурсы процессора практически исчерпаны, особенно если это значение сопровождается высокой загрузкой ЦП.
Для многопроцессорных систем необходимо разделить длину очереди на число физических процессоров. Если в многопроцессорной системе соответствие процессов задано жестко (то есть процессы назначены определенным ядрам ЦП) и очередь имеет большую длину, это может указывать на то, что конфигурация не сбалансирована.
Хотя счетчик «Длина очереди процессора» не используется для планирования загрузки, его можно применять для определения того, справляются ли системы в среде с нагрузкой и требуется ли приобрести дополнительные или более производительные процессоры для будущих серверов.
Счетчики памяти
В следующей таблице описываются общие счетчики памяти.
Показывает объем физической памяти в мегабайтах (МБ), непосредственно доступной для выделения процессу или использования системой. Эта величина равна сумме памяти, выделенной для резервной памяти (кэша), свободной памяти и обнуленных страниц памяти. Подробное описание работы диспетчера памяти см. на сайте Microsoft Developer Network (MSDN) или в главе «Руководство по обеспечению производительности системы и устранению неполадок» комплекта ресурсов для Windows Server 2003.
Всегда должно превышать 100 МБ.
Память\Байт в невыгружаемом страничном пуле
Включает в себя виртуальные адреса системы, которые гарантированно постоянно находятся в физической памяти и к которым можно получать доступ из любого адресного пространства без операций ввода-вывода с файлом подкачки. Как и выгружаемый пул, невыгружаемый пул создается во время инициализации системы и используется компонентами, работающими в режиме ядра, для выделения системной памяти.
Память\Байт в выгружаемом страничном пуле
Показывает часть общей системной памяти, которую можно выгрузить в файл подкачки на диске. Выгружаемый пул создается во время инициализации системы и используется компонентами, работающими в режиме ядра, для выделения системной памяти.
Необходимо отслеживать увеличение числа байт в выгружаемом пуле, которое может указывать на утечку памяти.
Показывает текущий размер кэша файловой системы (в байтах). По умолчанию кэш использует до 50% доступной физической памяти. Значение счетчика является суммой значений счетчиков «Память\Резидентных байт системного кэша», «Память\Резидентных байт системных драйверов», «Память\Резидентных байт системного кода» и «Память\Байт в резидентном страничном пуле».
Это значение не должно изменяться после того, как приложения используют определенную часть памяти для кэша. Отслеживайте значительное снижение значения этого счетчика, которое может быть связано с очисткой рабочего набора и чрезмерным использованием подкачки.
Используется каталогом индекса содержимого и при копировании журналов непрерывной репликации.
Память\Байт выделенной виртуальной памяти
Показывает объем выделенной виртуальной памяти (в байтах). Выделенная память — это физическая память, для которой зарезервировано место в файлах подкачки на диске. На каждом физическом диске может быть один или несколько файлов подкачки. Этот счетчик указывает только последнее зарегистрированное значение, а не среднее.
Определяет объем используемой выделенной памяти (в байтах).
Память\% использования выделенной памяти
Показывает отношение значения «Память\Байт выделенной виртуальной памяти» к значению «Память\Предел выделенной виртуальной памяти». Выделенная память — это используемая физическая память, для которой зарезервировано место в файле подкачки на тот случай, если возникнет необходимость ее записи на диск. Предел выделенной виртуальной памяти определяется размером файла подкачки. При увеличении размера файла подкачки предел выделенной виртуальной памяти увеличивается, а соотношение уменьшается. Этот счетчик указывает только текущее значение в процентах, а не среднее.
Если это значение очень велико (более 90%), могут возникать сбои при фиксации. Это явный признак того, что в системе недостаточно памяти.
Счетчики подкачки памяти
В следующей таблице описываются общие счетчики подкачки памяти.
Память>Переходных многоцелевых страниц/с
Указывает на загрузку системного кэша.
В среднем значение должно быть меньше 100. Пиковые значения не должны превышать 1000.
Память\Операций чтения страниц/с
Указывает на то, что данные должны читаться с диска, а не из памяти. Означает, что памяти недостаточно, из-за чего начинается подкачка. Значение больше 30 страниц в секунду указывает на то, что сервер больше не справляется с нагрузкой.
В среднем значение должно быть меньше 100.
Показывает скорость чтения страниц с диска и их записи на диск при устранении ошибок страниц физической памяти. Этот счетчик является основным показателем типов сбоев, которые вызывают задержки во всей системе. Он представляет собой сумму значений «Память\Ввод страниц/с» и «Память\Вывод страниц/с». Он измеряется в числе страниц, и поэтому его значение можно сравнивать со значениями других счетчиков страниц, таких как «Память\Ошибок страницы/с», без преобразования. Значение включает в себя страницы, полученные для устранения ошибок кэша файловой системы (который обычно запрашивается приложениями) и некэшированных файлов, непосредственно отображаемых в память.
В среднем значение должно быть меньше 1000.
Значения, которые возвращаются счетчиком «Обмен страниц/с», могут превышать ожидаемые показатели. Они могут быть не связаны с активностью файла подкачки или кэша, а вызваны приложением, которое последовательно читает файл, непосредственно отображаемый в память.
Для определения объема ввода-вывода для файла подкачки используйте счетчики «Память\Ввод страниц/с» и «Память\Вывод страниц/с».
Показывает скорость чтения страниц с диска при устранении ошибок страниц физической памяти. Ошибки страниц физической памяти возникают в том случае, когда процесс ссылается на страницу в виртуальной памяти, которая не относится к его рабочему набору или не находится в физической памяти, и ее требуется получить с диска. При ошибке страницы система пытается считать несколько смежных страниц в память, чтобы максимально эффективно использовать операцию чтения. Чтобы определить среднее число страниц, которые считываются в память при каждой операции чтения, сравните значение «Память\Ввод страниц/с» и «Память\Операций чтения страниц/с».
В среднем значение должно быть меньше 1000.
Показывает скорость записи страниц на диск для освобождения физической памяти. Страницы записываются обратно на диск только в том случае, если они были изменены в физической памяти, поэтому они, скорее всего, содержат данные, а не код. Высокая скорость вывода страниц может свидетельствовать о нехватке памяти. Microsoft Windows записывает больше страниц обратно на диск, чтобы освободить физическую память, если ее недостаточно. Этот счетчик показывает число страниц, и его значение можно сравнивать со значениями других счетчиков страниц без преобразования.
В среднем значение должно быть меньше 1000.
Счетчики использования памяти
В следующей таблице описываются общие счетчики использования памяти процессами.
Процесс(*)\Байт исключительного пользования
Показывает текущее число байт, выделенных процессу, которые не могут совместно использоваться с другими процессами.
Этот счетчик можно использовать для выявления утечек памяти для процессов.
Для процесса банка данных сравните значение этого счетчика с размером кэша базы данных, чтобы определить наличие утечки памяти в процессе банка данных. Повышение числа байтов исключительного пользования для банка данных, сопровождаемое таким же увеличением объема кэша базы данных, свидетельствует о правильном поведении (утечки памяти не происходит).
Процесс(*)\Байт виртуальной памяти
Показывает объем виртуального адресного пространства (в байтах), которое в данный момент использует процесс.
Применяется для определения того, не используют ли процессы большой объем виртуальной памяти.
Счетчик рабочего набора процесса
В следующей таблице описывается общий счетчик рабочего набора процесса.
Показывает текущий размер кэша рабочего набора процесса (в байтах). Рабочий набор — это набор страниц памяти, которые недавно использовались потоками процесса. Если объем свободной памяти на компьютере превышает пороговое значение, неиспользуемые страницы сохраняются в рабочем наборе события процесса. Когда объем свободной памяти становится ниже порогового значения, страницы удаляются из рабочих наборов. Если они потребуются, то будут переданы в рабочий набор при разрешении ошибки ОЗУ перед тем, как будут выгружены из оперативной памяти.
Значительное увеличение или снижение значения размера рабочих наборов приводит к подкачке.
Убедитесь, что для файла подкачки установлено рекомендуемое значение «ОЗУ + 10». Если происходит удаление из рабочих наборов, добавьте счетчик «Процесс(*)\Рабочий набор», чтобы определить, какие процессы подвержены проблеме. Этот счетчик может указывать как на общесистемные проблемы, так и на проблемы, связанные с определенным процессом. Сравните это значение со значением счетчика «Память\Резидентных байт системного кэша», чтобы определить, не происходит ли общесистемное удаление страниц из рабочих наборов.
Счетчик дескрипторов процесса
В следующей таблице описывается общий счетчик дескрипторов процесса.
Показывает общее число дескрипторов, открытых в настоящий момент процессом. Это число является суммой дескрипторов, открытых каждым потоком процесса.
Увеличение числа дескрипторов для определенного процесса может быть признаком сбоя процесса в связи с утечкой дескрипторов, который вызывает проблемы с производительностью на сервере. Это не всегда является проблемой, но данное значение необходимо отслеживать в течении некоторого периода, чтобы определить, не происходит ли утечка дескрипторов.
Счетчики .NET Framework
В следующей таблице описываются счетчики Microsoft .NET Framework.
Память CLR .NET(*)\% времени на сборку мусора
Показывает, когда произошла сборка мусора. Если значение счетчика больше порогового значения, это указывает на то, что происходит очистка ЦП и он не используется эффективно для обработки нагрузки. Для улучшения ситуации рекомендуется увеличить объем памяти на сервере.
В среднем значение должно быть меньше 10%.
Если этот счетчик имеет высокое значение, возможно, некоторые объекты не были очищены при сборке мусора поколения 1 и были переданы в поколение 2. Для сборки мусора для поколения 2 требуется очистка всего глобального каталога. Чтобы определить, является ли это причиной проблемы, добавьте другие счетчики памяти .NET Framework.
Исключения CLR .NET(*)\Число исключений/с
Показывает число исключений, происходящих в секунду. К ним относятся как исключения .NET Framework, так и неуправляемые исключения, которые преобразуются в исключения .NET Framework. Например, исключение ссылки на пустой указатель в неуправляемом коде будет происходить повторно в управляемом коде как .NET Framework System.NullReferenceException. Этот счетчик учитывает как необрабатываемые, так и обрабатываемые исключения.
Должно быть меньше 5% общего количества запросов в секунду (Веб-сервер(_Total)\Попыток подключения/с * 0,05).
Исключения должны возникать в редких ситуациях и не входить в обычный поток управления программы. Этот счетчик служит индикатором потенциальных проблем с производительностью, на которые указывает высокая частота исключений (> 100 в секунду). Значение этого счетчика не является средним. Он показывает разницу между значениями, зарегистрированными в двух последних выборках, разделенную на длительность интервала выборки.
Память CLR .NET(*)\Байт во всех кучах
Показывает сумму четырех других счетчиков: «Размер кучи поколения 0», «Размер кучи поколения 1», «Размер кучи поколения 2» и «Размер кучи для массивных объектов». Этот счетчик показывает текущий объем памяти (в байтах), выделенной в кучах сборки мусора.
Эти области памяти имеют тип MEM_COMMIT. Значение этого счетчика всегда меньше значения «Процесс\Байт исключительного пользования», который учитывает все области MEM_COMMIT для процесса. Значение «Байт исключительного пользования» за вычетом значения «Байт во всех кучах» — это число байт, выделенных всем неуправляемым объектам.
Этот счетчик позволяет отслеживать возможные утечки памяти или чрезмерное использование памяти управляемыми и неуправляемыми объектами.
Счетчики сети
В следующей таблице описываются общие счетчики сети.
Сетевой интерфейс(*)\Всего байт/с
Показывает скорость, с которой сетевой адаптер обрабатывает данные. Этот счетчик включает в себя данные всех приложений и файлов, а также данные протоколов, такие как заголовки пакетов.
Для 100-мегабайтного сетевого адаптера значение не должно превышать 6–7 Мбайт/с.
Для 1000-мегабитного сетевого адаптера значение не должно превышать 60–70 Мбит/с.
Сетевой интерфейс(*)\Исходящих пакетов с ошибками
Показывает количество исходящих пакетов, которые не удалось передать из-за ошибок.
Всегда должно равняться 0.
Показывает число подключений TCP с текущим состоянием ESTABLISHED или CLOSE-WAIT. Количество подключений TCP, которые можно установить, ограничено размером невыгружаемого пула. При истощении невыгружаемого пула новые подключения установить невозможно.
Определяет текущую пользовательскую нагрузку.
Показывает число подключений TCP с текущим состоянием ESTABLISHED или CLOSE-WAIT. Количество подключений TCP, которые можно установить, ограничено размером невыгружаемого пула. При истощении невыгружаемого пула новые подключения установить невозможно.
Определяет текущую пользовательскую нагрузку.
Показывает число переходов подключений TCP в состояние CLOSED непосредственно из состояний ESTABLISHED или CLOSE-WAIT.
Увеличение числа сбросов или постоянно растущая частота сбросов могут указывать на нехватку пропускной способности.
Некоторые браузеры отправляют пакеты TCP Reset (RST), поэтому используйте этот счетчик при определении частоты сброса с осторожностью.
Показывает число переходов подключений TCP в состояние CLOSED непосредственно из состояний ESTABLISHED или CLOSE-WAIT.
Увеличение числа сбросов или постоянно растущая частота сбросов могут указывать на нехватку пропускной способности.
Некоторые браузеры отправляют пакеты TCP Reset (RST), поэтому используйте этот счетчик при определении частоты сброса с осторожностью.
Счетчики подключений контроллеров домена Exchange
В следующей таблице описываются счетчики подключений контроллеров домена Exchange.
Кэши MSExchange ADAccess(*)\Операций поиска LDAP/с
Показывает количество операций поиска LDAP, выполненных в секунду.
Используется для определения текущей частоты поиска в LDAP.
Контроллеры домена MSExchange ADAccess(*)\Время чтения LDAP
Показывает время в миллисекундах, затраченное на отправку запроса на чтение LDAP в указанный контроллер домена и получение ответа.
В среднем значение должно быть меньше 50 мс. Пиковые (максимальные) значения не должны превышать 100 мс.
Контроллеры домена MSExchange ADAccess(*)\Время поиска LDAP
Показывает время (в мс), затраченное на отправку запроса на поиск в LDAP и получение ответа.
В среднем значение должно быть меньше 50 мс. Пиковые (максимальные) значения не должны превышать 100 мс.
Процессы MSExchange ADAccess(*)\Время чтения LDAP
Показывает время (в мс), затраченное на отправку запроса на чтение LDAP в указанный контроллер домена и получение ответа.
В среднем значение должно быть меньше 50 мс. Пиковые (максимальные) значения не должны превышать 100 мс.
Процессы MSExchange ADAccess(*)\Время поиска LDAP
Показывает время (в мс), затраченное на отправку запроса на поиск в LDAP и получение ответа.
В среднем значение должно быть меньше 50 мс. Пиковые (максимальные) значения не должны превышать 100 мс.
Контроллеры домена MSExchange ADAccess(*)\Операций поиска LDAP с превышением времени ожидания в минуту
Показывает количество операций поиска в LDAP за последнюю минуту, которые вернули ошибку LDAP_Timeout.
Всегда должно быть меньше 10 для всех ролей. Более высокое значение может указывать на проблемы с ресурсами Служба каталогов Active Directory.
Контроллеры домена MSExchange ADAccess(*)\Длинных операций LDAP/мин
Показывает количество операций LDAP на этом контроллере домена за минуту, которые заняли больше времени, чем указанное пороговое значение (по умолчанию — 15 секунд).
Всегда должно быть меньше 50.
Более высокое значение может указывать на проблемы с ресурсами Служба каталогов Active Directory.