Закон о безопасности КИИ в вопросах и ответах
1 января, с приходом нового 2018 года, в нашей стране вступил в действие закон «О безопасности критической информационной инфраструктуры» (далее – Закон). Начиная с 2013 года, еще на этапе проекта, этот закон бурно обсуждался ИБ-сообществом и вызывал много вопросов относительно практической реализации выдвигаемых им требований. Теперь, когда эти требования вступили в силу и многие компании столкнулись с необходимостью их выполнения, мы постараемся ответить на самые животрепещущие вопросы.
Для чего нужен Закон?
Новый Закон предназначен для регулирования отношений в области обеспечения безопасности объектов информационной инфраструктуры РФ, функционирование которых критически важно для экономики государства. Такие объекты в законе называются объектами критической информационной инфраструктуры (далее – объекты КИИ). Согласно Закону, к объектам КИИ могут быть отнесены информационные системы и сети, а также автоматизированные системы управления, функционирующие в сфере:
- здравоохранения;
- науки;
- транспорта;
- связи;
- энергетики;
- банковской и иных сферах финансового рынка;
- топливно-энергетического комплекса;
- атомной энергии;
- оборонной и ракетно-космической промышленности;
- горнодобывающей, металлургической и химической промышленности.
Объекты КИИ, а также сети электросвязи, используемые для организации взаимодействия между ними, составляют понятие критической информационной инфраструктуры.
Что является целью Закона и как он должен работать?
Главной целью обеспечения безопасности КИИ является устойчивое функционирование КИИ при проведении в отношении нее компьютерных атак. Одним из главных принципов обеспечения безопасности является предотвращение компьютерных атак.
Объекты КИИ или КСИИ?
До появления нового закона о КИИ в сфере ИБ существовало похожее понятие ключевых систем информационной инфраструктуры (КСИИ). Однако с 1 января 2018 года понятие КСИИ было официально заменено на понятие «значимые объекты КИИ».
Какие организации попадают в сферу действия Закона?
Требования Закона затрагивают те организации (государственные органы и учреждения, юридические лица и индивидуальных предпринимателей), которым принадлежат (на праве собственности, аренды или ином законном основании) объекты КИИ или которые обеспечивают их взаимодействие. Такие организации в Законе называются субъектами КИИ.
Какие действия должны предпринять субъекты КИИ для выполнения Закона?
Согласно закону, субъекты КИИ должны:
- провести категорирование объектов КИИ;
- обеспечить интеграцию (встраивание) в Государственную систему обнаружения, предупреждения и ликвидации последствий компьютерных атак на информационные ресурсы Российской Федерации (ГосСОПКА);
- принять организационные и технические меры по обеспечению безопасности объектов КИИ.
Что подлежит категорированию?
Категорированию подлежат объекты КИИ, которые обеспечивают управленческие, технологические, производственные, финансово-экономические и (или) иные процессы в рамках выполнения функций (полномочий) или осуществления видов деятельности субъектов КИИ.
Что в себя включает категорирование объектов КИИ?
Категорирование объекта КИИ предполагает определение его категории значимости на основе ряда критериев и показателей. Всего устанавливается три категории – первая, вторая или третья (в порядке убывания значимости). Если объект КИИ не соответствует ни одному из установленных критериев, ему категория не присваивается. Те объекты КИИ, которым была присвоена одна из категорий, называются в законе значимыми объектами КИИ.
По завершению категорирования сведения о его результатах должны направляться субъектом КИИ во ФСТЭК России для ведения реестра значимых объектов КИИ. В реестр включается следующая информация:
- наименование значимого объекта КИИ;
- наименование субъекта КИИ;
- сведения о взаимодействии значимого объекта КИИ и сетей электросвязи;
- сведения о лице, эксплуатирующем значимый объект КИИ;
- присвоенная категория значимости;
- сведения о программных и программно-аппаратных средствах, используемых на значимом объекте КИИ;
- меры, применяемые для обеспечения безопасности значимого объекта КИИ.
Важно отметить, что если в процессе категорирования было определено отсутствие категории значимости у объекта КИИ, результаты категорирования все равно должны быть представлены во ФСТЭК России. Регулятор проверяет представленные материалы и при необходимости направляет замечания, которые должен учесть субъект КИИ.
Если субъект КИИ не предоставит данные о категорировании, ФСТЭК России вправе потребовать эту информацию.
Порядок ведения реестра значимых объектов КИИ определяется приказом ФСТЭК России от 06.12.2017 №227 «Об утверждении Порядка ведения реестра значимых объектов критической информационной инфраструктуры Российской Федерации».
Как проводить категорирование объектов КИИ?
Показатели критериев значимости, а также порядок и сроки категорирования определены в «Правилах категорирования объектов критической информационной инфраструктуры Российской Федерации» утверждённых соответствующим постановлением правительства от 8 февраля 2018 г. № 127 (далее – Правила). Правила регламентируют процедуру категорирования, а также содержат перечень критериев и их показатели для значимых объектов КИИ первой, второй и третьей категории.
Согласно Правилам, процедура категорирования включает в себя:
- Определение субъектом КИИ перечня всех процессов, выполняемых в рамках своей деятельности.
- Выявление критических процессов, то есть тех процессов, нарушение и (или) прекращение которых может привести к негативным социальным, политическим, экономическим, экологическим последствиям, последствиям для обеспечения обороны страны, безопасности государства и правопорядка.
- Определение объектов КИИ, которые обрабатывают информацию, необходимую для обеспечения критических процессов, управления и контроля ими.
- Формирование перечня объектов КИИ, подлежащих категорированию. Перечень объектов для категорирования подлежит согласованию с ведомством-регулятором, утверждается субъектом КИИ и в течение 5 рабочих дней после утверждения направляется во ФСТЭК России.
- Оценку масштаба возможных последствий в случае возникновения компьютерных инцидентов на объектах КИИ в соответствии с показателями, указанных в Правилах. Всего предусматривается 14 показателей, определяющих социальную, политическую, экономическую значимость объекта КИИ, а также его значимость для обеспечения правопорядка, обороны и безопасности страны.
- Присвоение каждому из объектов КИИ одной из категорий значимости в соответствии с наивысшим значением показателей, либо принятие решения об отсутствии необходимости присвоения категории.
Категорирование должно проводиться как для существующих, так и для создаваемых или модернизируемых объектов КИИ специальной комиссией под председательством руководителя субъекта КИИ (или уполномоченного им лица), его работников и, при необходимости, приглашённых специалистов ведомств-регуляторов в соответствующей сфере. Решение комиссии оформляется соответствующим актом и в течение 10 дней после его утверждения направляется во ФСТЭК России. Предоставленные материалы в тридцатидневный срок со дня получения проверяются регулятором на соответствие порядку осуществления категорирования и оценивается правильность присвоения категории.
Максимальный срок категорирования объектов КИИ – 1 год со дня утверждения субъектом КИИ перечня объектов КИИ.
Категория значимого объекта КИИ может быть изменена по мотивированному решению ФСТЭК России в рамках государственного контроля безопасности значимых объектов КИИ, в случае изменения самого объекта КИИ, а также в связи с реорганизацией субъекта КИИ (в том числе ликвидацией, изменением его организационно-правовой формы и т.д.).
Что такое ГосСОПКА и для чего она нужна?
ГосСОПКА представляет собой единый территориально распределенный комплекс, включающий силы и программно-технические средства обнаружения, предупреждения и ликвидации последствий компьютерных атак (далее – силы и средства ОПЛ КА).
К силам ОПЛ КА относятся:
- уполномоченные подразделения ФСБ России;
- национальный координационный центр по компьютерным инцидентам, который создается ФСБ России для координации деятельности субъектов КИИ по вопросам обнаружения, предупреждения и ликвидации последствий компьютерных инцидентов;
- подразделения и должностные лица субъектов КИИ, которые принимают участие в обнаружении, предупреждении и ликвидации последствий компьютерных атак и в реагировании на компьютерные инциденты.
ГосСОПКА предназначена для обеспечения и контроля безопасности КИИ в Российской Федерации и в дипломатических представительствах страны за рубежом.
В данной системе должна собираться и агрегироваться вся информация о компьютерных атаках и инцидентах, получаемая от субъектов КИИ. Перечень информации и порядок ее предоставления в ГосСОПКА будет определен соответствующим приказом, проект которого был представлен на общественное обсуждение. Согласно текущей версии документа, срок предоставления информации о кибератаке составляет 24 часа с момента обнаружения.
Кроме того, в рамках ГосСОПКА организуется обмен информацией о компьютерных атаках между всеми субъектами КИИ, а также международными организациями, осуществляющими деятельность в области реагирования на компьютерные инциденты.
Технически ГосСОПКА будет представлять собой распределённую систему из центров ГосСОПКА, развёрнутых субъектами КИИ, объединённых в иерархическую структуру по ведомственно-территориальному признаку, и подключённых к ним технических средств (средств ОПЛ КА), установленных в конкретных объектах КИИ. При этом центры ГосСОПКА могут быть ведомственными, то есть организованными государственными органами, а также корпоративными – построенными государственными и частными корпорациями, операторами связи и другими организациями-лицензиатами в области защиты информации.
Кто является собственником ГосСОПКА?
Для ГосСОПКА не предусматривается единый собственник: каждый из центров ГосСОПКА будет принадлежать отдельному владельцу, вложившему свои средства в его построение. Государство же будет выступать только в качестве регулятора и координатора.
Что подразумевается под интеграцией с ГосСОПКА?
Интеграция в ГосСОПКА требует от субъекта КИИ:
- информировать о компьютерных инцидентах ФСБ России, а также Центральный Банк Российской Федерации, если организация осуществляет деятельность в банковской сфере и иных сферах финансового рынка;
- оказывать содействие ФСБ России в обнаружении, предупреждении и ликвидации последствий компьютерных атак, установлении причин и условий возникновения компьютерных инцидентов.
Кроме того, по решению субъекта КИИ на территории объекта КИИ может быть размещено оборудование ГосСОПКА. В этом случае субъект дополнительно обеспечивает его сохранность и бесперебойную работу. Иными словами, субъектом КИИ может быть организован собственный центр ГосСОПКА.
Может ли субъект КИИ не создавать собственный центр ГосСОПКА?
Решение о создании собственного центра ГосСОПКА субъект КИИ принимает самостоятельно. То есть создание центра ГосСОПКА не является обязательным, и, более того, данный шаг должен быть согласован с ФСБ России.
Однако для значимых объектов КИИ субъектам КИИ придется реализовать меры по обнаружению и реагированию на компьютерные инциденты. А для этого в любом случае потребуются специальные технические средства и квалифицированный персонал, которые, по сути, и являются составляющими собственного центра ГосСОПКА.
Что требуется для построения собственного центра ГосСОПКА?
Согласно документу «Методические рекомендации по созданию ведомственных и корпоративных центров ГосСОПКА», для построения собственного центра ГосСОПКА необходимо обеспечить функционирование совокупности технических средств и процессов, выполняющих следующие функции:
- инвентаризация информационных ресурсов;
- выявление уязвимостей информационных ресурсов;
- анализ угроз информационной безопасности;
- повышение квалификации персонала информационных ресурсов;
- прием сообщений о возможных инцидентах от персонала и пользователей информационных ресурсов;
- обеспечение процесса обнаружения компьютерных атак;
- анализ данных о событиях безопасности;
- регистрация инцидентов;
- реагирование на инциденты и ликвидация их последствий;
- установление причин инцидентов; анализ результатов устранения последствий инцидентов.
Для этого в составе технических средств ОПЛ КА могут использоваться:
- средства обнаружения и предотвращения вторжений, в том числе обнаружения целевых атак;
- специализированные решения по защите информации для индустриальных сетей, финансового сектора;
- средства выявления и устранения DDoS-атак;
- средства сбора, анализа и корреляции событий;
- средства анализа защищенности;
- средства антивирусной защиты;
- средства межсетевого экранирования;
- средства криптографической защиты информации для защищенного обмена информацией с другими центрами ГосСОПКА.
Технические средства должны быть интегрированы в единый комплекс, управляемый из центра ГосСОПКА и взаимодействующий с другими центрами ГосСОПКА.
Помимо технического обеспечения для создания центра ГосСОПКА необходимо разработать соответствующие методические документы, включающие настройки средств обеспечения ИБ, решающие правила средств обнаружения компьютерных атак, правила корреляции событий, инструкции для персонала и т.п.
Центр ГосСОПКА может быть реализован субъектом КИИ как самостоятельно (с использованием собственных технических и кадровых ресурсов), так и с привлечением сторонних специалистов путем передачи на аутсорсинг части функций, например, анализ угроз информационной безопасности, повышение квалификации персонала, прием сообщений об инцидентах, анализ защищенности и расследование инцидентов.
Что требуется для обеспечения безопасности объектов КИИ?
Для объектов КИИ, не являющихся значимыми, в обязательном порядке должна быть обеспечена только интеграция с ГосСОПКА (канал обмена информацией). Остальные мероприятия по обеспечению безопасности объекта КИИ реализуются на усмотрение соответствующего субъекта КИИ.
Для значимых объектов КИИ, помимо интеграции в ГосСОПКА субъекты КИИ должны:
- Cоздать систему безопасности значимого объекта КИИ;
- Реагировать на компьютерные инциденты. Порядок реагирования на компьютерные инциденты должен быть подготовлен ФСБ России до конца апреля текущего года;
- Предоставлять на объект КИИ беспрепятственный доступ регуляторам и выполнять их предписания по результатам проверок. Законом предусматриваются как плановые, так и внеплановые проверки.
Система безопасности значимого объекта КИИ представляет собой комплекс организационных и технических мер.
Порядок создания системы и требования к принимаемым мерам безопасности определяются приказом ФСТЭК России от 21.12.2017 №235 «Об утверждении Требований к созданию систем безопасности значимых объектов критической информационной инфраструктуры Российской Федерации и обеспечению их функционирования».
Кто контролирует выполнение требований Закона?
Основные функции контроля в области обеспечения безопасности объектов КИИ, включая нормативно-правовое регулирование, возложены на ФСТЭК России и ФСБ России.
ФСТЭК России отвечает за ведение реестра значимых объектов КИИ, формирование и контроль реализации требований по обеспечению их безопасности.
ФСБ России обеспечивает регулирование и координацию деятельности субъектов КИИ по развёртыванию сил и средств ОПЛ КА, осуществляет сбор информации о компьютерных инцидентах и оценку безопасности КИИ, а также разрабатывает требования к средствам ОПЛ КА.
В отдельных случаях, касающихся сетей электросвязи и субъектов КИИ в банковской и иных сферах финансового рынка, разрабатываемые ФСТЭК России и ФСБ России требования должны согласовываться с Минкомсвязью России и Центральным Банком Российской Федерации соответственно.
Порядок госконтроля в области обеспечения безопасности значимых объектов КИИ определен постановлением Правительства Российской Федерации от 17.02.2018 №162 «Об утверждении Правил осуществления госконтроля в области обеспечения безопасности значимых объектов КИИ РФ».
А если требования Закона не будут выполнены?
Вместе с утверждением ФЗ «О безопасности КИИ» в УК РФ была добавлена новая статья 274.1, которая устанавливает уголовную ответственность должностных лиц субъекта КИИ за несоблюдение установленных правил эксплуатации технических средств объекта КИИ или нарушение порядка доступа к ним вплоть до лишения свободы сроком на 6 лет. Пока данная статья не предусматривает ответственности за невыполнение необходимых мероприятий по обеспечению безопасности объекта КИИ, однако в случае наступления последствий (аварий и чрезвычайных ситуаций, повлекших за собой крупный ущерб) непринятие таких мер подпадает по состав 293 статьи УК РФ «Халатность». Дополнительно следует ожидать внесения изменений в административное законодательство в части определения штрафных санкций для юридических лиц за неисполнение Закона. С большой долей уверенности можно говорить о том, что именно введение существенных денежных штрафов будет стимулировать субъекты КИИ к выполнению требований Закона.
MultipleAuthors\Classes\Objects\Author Object ( [term_id] => 1189 [term:MultipleAuthors\Classes\Objects\Author:private] => [metaCache:MultipleAuthors\Classes\Objects\Author:private] => [userObject:MultipleAuthors\Classes\Objects\Author:private] => [hasCustomAvatar:MultipleAuthors\Classes\Objects\Author:private] => [customAvatarUrl:MultipleAuthors\Classes\Objects\Author:private] => [avatarUrl:MultipleAuthors\Classes\Objects\Author:private] => [avatarBySize:MultipleAuthors\Classes\Objects\Author:private] => Array ( ) ) [1] => MultipleAuthors\Classes\Objects\Author Object ( [term_id] => 1196 [term:MultipleAuthors\Classes\Objects\Author:private] => [metaCache:MultipleAuthors\Classes\Objects\Author:private] => [userObject:MultipleAuthors\Classes\Objects\Author:private] => [hasCustomAvatar:MultipleAuthors\Classes\Objects\Author:private] => [customAvatarUrl:MultipleAuthors\Classes\Objects\Author:private] => [avatarUrl:MultipleAuthors\Classes\Objects\Author:private] => [avatarBySize:MultipleAuthors\Classes\Objects\Author:private] => Array ( ) ) [2] => MultipleAuthors\Classes\Objects\Author Object ( [term_id] => 1178 [term:MultipleAuthors\Classes\Objects\Author:private] => [metaCache:MultipleAuthors\Classes\Objects\Author:private] => [userObject:MultipleAuthors\Classes\Objects\Author:private] => [hasCustomAvatar:MultipleAuthors\Classes\Objects\Author:private] => [customAvatarUrl:MultipleAuthors\Classes\Objects\Author:private] => [avatarUrl:MultipleAuthors\Classes\Objects\Author:private] => [avatarBySize:MultipleAuthors\Classes\Objects\Author:private] => Array ( ) ) ) —>

Руководитель группы аналитиков по информационной безопасности, Kaspersky ICS CERT
MTBF (наработка на отказ) и гарантия в мире компьютеров. Что важно?
Разработчик – производитель – продавец – покупатель. Этот стандартный путь проходит любое устройство, будь то электронный блок для космического телескопа или ПК на вашем рабочем столе. И на каждом этапе используются результаты анализа, выполненного с помощью теории надежности.
Как известно, покупатели делятся на две принципиально разные категории: частные лица и фирмы. Корпоративный покупатель обеспечен внимательным отношением, так как он умеет не только защищаться, но и выбирать продавца с подходящей репутацией. А обычный покупатель и защищен плохо, и считать ему приходится каждый рубль. О нем и пойдет речь.
Не все вещи доживают до конца гарантии
Когда такой покупатель приходит в магазин компьютерной техники, один из главных вопросов, который его волнует – надежность устройства. Каждому хочется, чтобы его ПК устарел морально и физически, будучи в рабочем состоянии, и чтобы не пришлось через месяц после окончания гарантийного срока мучиться вопросом «что полетело?» и «во что обойдется теперь ремонт?».
Что такое MTBF, "наработка на отказ" или "ресурс"
Согласно ГОСТ 27.002-89 для оценки надежности используются следующие термины, с которыми мы сталкиваемся в магазине: «наработка на отказ» – наработка от окончания восстановления работоспособного состояния после отказа до возникновения следующего отказа. Это в случае ремонтопригодной продукции. Эквивалент в английской литературе – MTBF (Mean (operating) time between failures) – среднее время между отказами. В случае продукции не подлежащей ремонту используется термин «наработка до отказа» – наработка от начала эксплуатации до возникновения первого отказа. Эквивалент в английской литературе – MTTF (Mean (operating) time to failures) – среднее время до отказа.
Часто встречается также термин Lifetime warranty. Это, как правило, гарантия соответствия параметров изделия на все время его эксплуатации. Некоторые фирмы ограничивают гарантию каким то количеством лет (обычно не больше пяти) после прекращения выпуска данного изделия или изделия способного его заменить. Поэтому, если эти нюансы принципиальны, то в спецификации желательно прочесть, что подразумевает производитель под lifetime warranty.
100 лет может прожить только танк. в мирное время
Покупая то или иное устройство, мы можем, наряду с гарантийным сроком, столкнуться с упомянутой терминологией. Если продавец сообщает, что у выбранного вами процессора, который не подлежит ремонту, MTBF составляет 500000 часов – это неправильно. Для процессора должно быть указано MTTF. MTBF должно употребляться только для ремонтопригодных устройств.
Терминология, используемая производителем и продавцом, употребляется иногда достаточно вольно, так как юридически все определяет описание того в каком значении применен данный термин к данному устройству. Это должно присутствовать в прилагаемых документах. «Уши» такого подхода «растут» из принципов регулирования главного рынка планеты – США, которые вырабатываются Федеральной Комиссией по Торговле (The Federal Trade Commission).
Как оценивается MTBF? Это иллюстрирует нижеследующая диаграмма, где приведена U-образная кривая интенсивности отказов (bathtub curve) для электронного устройства некоего научного оборудования, чтобы читатель мог видеть, что можно иметь в идеале при покупке электроники, в том числе компьютерной.
По вертикальной оси отложена вероятность выхода устройства из строя. По горизонтальной оси – время без соблюдения масштаба. Левая кривая перед красной границей соответствует длительности времени в течение которого большая часть устройств выходит из строя при наличии брака. На этом этапе бракованные устройства для научного оборудования отсеиваются сразу же, на заводе при стрессовых испытаниях. Это возможно, т.к. длительность выявления брака не превышает 50 часов и число устройств не велико.
Для комплектующих обычных компьютеров длительность нисходящей кривой значительно больше. В этом случае, для получения информации о длительности периода, когда проявляется заводской брак, очень важны рекламации от покупателя, потому что невозможно выискивать дефекты в течение месяцев на заводе у многих тысяч устройств. К тому же, некоторые наименования комплектующих ПК за год устаревают и сходят с рынка.
Далее следует вторая горизонтальная часть кривой, когда вероятность отказа примерно постоянна. Длительность ее и есть MTBF. Половина этой длительности часто берется производителем в качестве ориентира для определения гарантийного срока.
Справа от красной границы, после окончания срока MTBF, кривая демонстрирует увеличение вероятности отказов. Имеются ввиду не только поломки, но и отклонение параметров работы изделия от требуемых. Это увеличение вероятности выхода обусловлено тем, что ряд элементов в устройстве достигает своего жизненного предела из-за технологии изготовления, т.е. наступает технологический износ элементной базы. Таким образом, время MTBF статистически определяет время работоспособной жизни устройства при заданных условиях эксплуатации.
КИИ — что это? Безопасность объектов критической информационной инфраструктуры

Друзья, в предыдущей статье мы узнали о системах IRP, а до этого познакомились с основными концепциями информационной безопасности, Центрами SOC и системами SIEM. В рамках описания функционала систем IRP мы упомянули о том, что в большинстве случаев при обработке инцидентов ИБ крайне важна скорость реагирования, особенно когда речь идет о безопасности информационных систем отдельных отраслей экономики или всего государства. Для подобных систем есть даже свой термин: КИИ — критическая информационная инфраструктура. Если вам интересно, что такое КИИ и как защищать КИИ — читайте дальше!
Начнем наше повествование с предыстории. Наука о защите информации существует и применяется уже не одну сотню лет: начиная с древних времен правителям и военачальникам нужно было сохранять в тайне важные военные, экономические и политические сведения. Шло время, и на смену пергаментам с тайнописью пришли информационные технологии и криптография, но цели государственных деятелей не меняются: сохранить правительственные и промышленные секреты, защитить информацию от посягательств разведчиков, не допустить аварий и катастроф из-за кибератак диверсантов. Почти никакие важные сведения сейчас уже не хранятся в бумажном виде и не обрабатываются в аналоговых (нецифровых) системах, поэтому и методы их защиты должны быть цифровыми. Мероприятия по киберзащите секретной государственной информации проводятся уже не один десяток лет, но всепроникающее развитие информационных технологий привело к тому, что цифровые технологии стали широко применяться не только в правительственных учреждениях, но и в промышленности, транспорте, медицине, финансовых и научных учреждениях. Информационные системы подобных отраслей экономики все чаще становятся объектом кибератак, проводимых в том числе и спонсируемыми другими государствами хакерами, которые ставят своей целью похищение ценных сведений и новейших разработок, а иногда — вывод из строя атакуемых систем и даже диверсии. Разумеется, игнорировать подобные угрозы было бы легкомысленно, поэтому принятие защитных мер, о которых мы поговорим далее, стало логичной ответной реакцией.
Итак, определимся с терминологией, расскажем про закон о КИИ и ответим на вопрос, что такое КИИ. Критическая информационная инфраструктура (сокращенно — КИИ) — это информационные системы, информационно-телекоммуникационные сети, автоматизированные системы управления субъектов КИИ, а также сети электросвязи, используемые для организации их взаимодействия. В свою очередь, субъекты КИИ — это компании, работающие в стратегически важных для государства областях, таких как здравоохранение, наука, транспорт, связь, энергетика, банковская сфера, топливно-энергетический комплекс, в области атомной энергии, оборонной, ракетно-космической, горнодобывающей, металлургической и химической промышленности, а также организации, обеспечивающие взаимодействие систем или сетей КИИ. Компьютерная атака на КИИ определяется как целенаправленное вредоносное воздействие на объекты КИИ для нарушения или прекращения их функционирования, а компьютерный инцидент — как факт нарушения или прекращения функционирования объекта КИИ и/или нарушения безопасности обрабатываемой объектом информации.
Таким образом, был определен список областей экономики страны, в которых государство требует обеспечивать безопасность КИИ, и дано определение самих атак и инцидентов, от которых предстоит защищаться. Данные нормы были введены Федеральным Законом от 26 июля 2017 г. № 187-ФЗ «О безопасности критической информационной инфраструктуры Российской Федерации», который вступил в силу с 1 января 2018 года. Кроме подписания данного Закона о КИИ, были назначены федеральные органы исполнительной власти (сокращенно — ФОИВ), отвечающие за реализацию норм данного закона. Так, Федеральная Служба по Техническому и Экспортному Контролю (ФСТЭК) России была назначена уполномоченным ФОИВ в области обеспечения безопасности критической информационной инфраструктуры РФ. На Федеральную Службу Безопасности (ФСБ) РФ были возложены функции обеспечения функционирования государственной системы обнаружения, предупреждения и ликвидации последствий компьютерных атак на информационные ресурсы РФ (далее – система ГосСОПКА). Кроме этого, приказом ФСБ РФ в 2018 году был создан Национальный координационный центр по компьютерным инцидентам (НКЦКИ), который координирует деятельность субъектов КИИ и чья техническая инфраструктура используется для функционирования системы ГосСОПКА. Говоря максимально упрощенно, НКЦКИ — это Центр SOC в государственном масштабе, а система ГосСОПКА — это такая большая система SIEM для всей страны. При этом в работе системы ГосСОПКА есть особенность, о которой мы говорили в публикации про IRP: информация по произошедшему компьютерному инциденту должна быть передана субъектом КИИ в систему ГосСОПКА в течение 24 часов, при этом удобнее делать это автоматизированно, например, с помощью API системы IRP.
Также как и во всех случаях защиты информации, важно определить меры по защите информации в КИИ, а для того, чтобы это осуществить, следует понять, какие объекты КИИ являются более важными и, соответственно, требуют большей защиты, а какие — не столь важны. Для этого было введено понятие категорирования объектов КИИ и подписано Постановление Правительства РФ от 8 февраля 2018 г. №127 «Об утверждении Правил категорирования объектов критической информационной инфраструктуры Российской Федерации, а также Перечня показателей критериев значимости объектов критической информационной инфраструктуры Российской Федерации и их значений». В данном документе приведены требования для субъектов КИИ по осуществлению категорирования объектов КИИ и указан перечень критериев значимости объектов КИИ, т.е. количественных показателей для корректного выбора категории значимости.
Категория значимости объекта КИИ может принимать одно из трех значений (где самая высокая категория — первая, самая низкая — третья) и зависит от количественных показателей значимости этого объекта в социальной, политической, экономической и оборонной сферах. Например, если компьютерный инцидент на объекте КИИ может привести к причинению ущерба жизни и здоровью более 500 граждан, то объекту присваивается максимальная первая категория, а если услуги связи в результате инцидента КИИ могут стать недоступны для 3 тыс. — 1 млн. абонентов, то объекту присваивается минимальная третья категория. Процесс категорирования объектов КИИ проводится внутренней комиссией по категорированию субъекта КИИ, в результате чего формируется список объектов КИИ с категориями значимости и затем отправляется в ФСТЭК России, где полученные сведения вносятся в специальный реестр объектов КИИ. Таким образом, категорирование КИИ состоит из нескольких взаимосвязанных шагов, результатом которых является составление субъектом КИИ Акта категорирования КИИ и наполнение реестра объектов КИИ данными с соответствующими категориями значимости.
Поговорим теперь о расследовании инцидентов в КИИ и об отправке информации о них в систему ГосСОПКА. Начнем с того, что опишем основные функции ГосСОПКА: это как методическая и техническая подготовка к обработке инцидентов информационной безопасности (например, инвентаризация ресурсов, выявление уязвимостей и угроз), так и непосредственно расследование инцидентов ИБ (прием сообщений о возможных атаках и их обнаружение, регистрация инцидентов, помощь в проведении расследования и анализе причин). При этом Центры ГосСОПКА могут быть как ведомственными, так и корпоративными: ведомственные защищают информацию органов государственной власти, а корпоративные — расследуют инциденты в своих системах и могут предоставлять такие услуги на коммерческой основе. Центры ГосСОПКА — это, упрощенно говоря, еще один пример государственного Центра SOC, по аналогии с НКЦКИ. Сразу отметим, что создание своего корпоративного Центра ГосСОПКА потребует не только закупки средств защиты (например, систем SIEM и IRP) и найма специалистов-аналитиков ИБ, но и получения лицензии ФСТЭК России на осуществление деятельности по мониторингу информационной безопасности, а также налаживания взаимодействия с НКЦКИ для обмена информацией об инцидентах КИИ.
Кроме уже указанных выше документов, ФСТЭК России выпустил ряд нормативных документов, которые детально описывают процесс защиты информации в КИИ. Например, один из основных документов — это Приказ ФСТЭК России от 25 декабря 2017 г. № 239 «Об утверждении Требований по обеспечению безопасности значимых объектов критической информационной инфраструктуры Российской Федерации». Его требуется применять тогда, когда организация-субъект КИИ провела процедуру категорирования своих объектов КИИ и пришла к выводу, что среди них есть значимые объекты критической информационной инфраструктуры (сокращенно — ЗОКИИ).
Какие же меры следует предпринимать для защиты значимых объектов критической информационной инфраструктуры (ЗОКИИ)? Приказ №239 говорит, что разработка мер защиты информации значимого объекта КИИ должна включать в себя анализ угроз безопасности и разработку модели угроз безопасности КИИ:
1. Анализ угроз включает в себя выявление источников угроз, оценку возможностей нарушителей (т.е. создание модели нарушителя), анализ уязвимостей используемых систем, определение возможных способов реализации угроз и их последствий. Модель нарушителя строится на основе предположений о потенциале атакующих, т.е. о мере усилий, затрачиваемых нарушителем при реализации угроз безопасности информации в информационной системе (при этом потенциалы нарушителей можно условно разделить на высокий, средний и низкий).
Анализ уязвимостей можно произвести при помощи тестов на проникновение — пентестов (англ. PenTest, сокращение от Penetration Test). При проведении пентестов проверяющие определяют слабые места инфраструктуры компании, выявляют уязвимости в системах защиты, проводят контролируемую эмуляцию настоящей хакерской атаки — в общем, наглядно показывают, что компания — заказчик этого тестирования может быть взломана. Далее заказчик получает рекомендации по устранению выявленных в ходе пентеста недочетов, и через какое-то время пентест повторяется. При проведении анализа уязвимостей и способов реализации угроз рекомендуется использовать Банк Данных Угроз (сокращенно – БДУ) ФСТЭК России — это официальный государственный справочник различных уязвимостей и способов атак, который регулярно пополняется и поддерживается в актуальном состоянии.
2. Под построением модели угроз безопасности КИИ при защите КИИ подразумевается описание свойств или характеристик угроз безопасности информации, а под угрозой безопасности — совокупность условий и факторов, создающих потенциальную или реально существующую опасность нарушения безопасности информации (т.е. базовых свойств информации, о которых мы уже говорили). Целью моделирования угроз КИИ является нахождение всех условий и факторов, проводящих к нарушению безопасности информации и работы ИТ-систем. Модель угроз может строиться на основе следующего классического подхода: актуальная угроза информационной безопасности возникает при наличии источника угрозы (внешний/внутренний нарушитель или третьи силы), уязвимости актива, способа реализации угрозы, объекта воздействия и самого вредоносного воздействия. Кроме того, совсем недавно ФСТЭК России выпустил проект новой методики моделирования угроз безопасности информации, которую можно применять для моделирования угроз в критической информационной инфраструктуре. В соответствии с данной Методикой, угроза безопасности информации является актуальной, если существует источник угрозы, условия и сценарий для её реализации, а воздействие на активы приведет к негативным последствиям. В Методике сказано, что процесс моделирования угроз ИБ состоит из следующих этапов:
определение возможных негативных последствий от реализации угроз по результатам оценки рисков нарушения законодательства, бизнес-процессов и/или нарушения защищенности информации, что может привести к таким негативным последствиям, как нарушение законодательства, экономический или репутационный ущерб;
определение условий для реализации угроз безопасности информации, т.е. выявление уязвимостей, недекларированных возможностей, доступов к ИТ-системам, которые могут быть использованы злоумышленниками;
определение сценариев реализации угроз с помощью таблицы тактик и техник атакующих, приведенной в Методике;
оценка уровня опасности угроз безопасности информации путем анализа типа доступа, необходимого для реализации атаки, сложности сценария атаки и уровня важности атакуемых активов.
Вернемся к Приказу №239. После анализа и моделирования угроз следует переходить к внедрению контрмер. При этом следует иметь в виду, что внедряемые меры защиты не должны оказывать негативного влияния на функционирование самого объекта КИИ – этим подчеркивается, что приоритетом является непрерывность технологических процессов, остановка которых может сама по себе привести к инциденту на КИИ, например, к выходу оборудования из строя или даже аварии.
В списке организационных и технических мер, предусмотренных положениями данного приказа в зависимости от категории значимости объекта КИИ и угроз безопасности информации, указаны следующие пункты:
идентификация и аутентификация;
ограничение программной среды;
защита машинных носителей информации;
предотвращение вторжений (компьютерных атак);
защита технических средств и систем;
защита информационной (автоматизированной) системы и ее компонентов;
планирование мероприятий по обеспечению безопасности;
управление обновлениями программного обеспечения;
реагирование на инциденты информационной безопасности;
обеспечение действий в нештатных ситуациях;
информирование и обучение персонала.
Кроме этого, в Приказе №239 особо оговорено, что при использовании СЗИ для защиты КИИ приоритет отдается штатному защитному функционалу, а при реагировании на компьютерные инциденты в критической информационной инфраструктуре требуется отправлять информацию о них в систему ГосСОПКА. Указывается также на важность использования СЗИ, которые обеспечиваются гарантийной и/или технической поддержкой, а также на возможные ограничения по использованию программного/аппаратного обеспечения или СЗИ (видимо, имеются ввиду санкционные риски). Также указано, что на значимом объекте КИИ требуется запретить удаленный и локальный бесконтрольный доступ для обновления или управления лицами, не являющимися работниками субъекта КИИ, а также запретить бесконтрольную передачу информации из объекта КИИ производителю или иным лицам. Кроме этого, все программные и аппаратные средства объекта КИИ первой категории значимости должны располагаться на территории РФ (за исключением оговоренных законодательством случаев).
Отметим, что Приказ №239 применяется в случае, если объект КИИ признан значимым (т.е. ему присвоена одна из трех категорий значимости). Если же объект КИИ признан незначимым (т.е. ни одна из категорий значимости не была присвоена), то по решению субъекта КИИ можно применять как Приказ №239 по КИИ, так и Приказ ФСТЭК России от 14 марта 2014 г. № 31 «Об утверждении Требований к обеспечению защиты информации в автоматизированных системах управления производственными и технологическими процессами на критически важных объектах, потенциально опасных объектах, а также объектах, представляющих повышенную опасность для жизни и здоровья людей и для окружающей природной среды». Данный Приказ №31 посвящен защите АСУТП — автоматизированных систем управления производственными и технологическими процессами, а положения данного Приказа близки к нормам Приказа №239.
Итак, как мы увидели из данной публикации, защита КИИ — критической информационной инфраструктуры — представляет из себя сложную, но интересную задачу. Это достаточно новое направление в информационной безопасности. Как мы уже упоминали выше, для реагирования на инциденты ИБ в КИИ создана система ГосСОПКА — государственная система обнаружения, предупреждения и ликвидации последствий компьютерных атак на информационные ресурсы РФ. В систему ГосСОПКА следует отправлять данные из средств защиты и обработки инцидентов ИБ в КИИ, причем осуществлять это целесообразнее всего с применением автоматизированных средств, таких как системы SIEM и IRP с модулем API-интеграции с ГосСОПКА. Субъектам КИИ необходимо подключаться к ведомственным или корпоративным Центрам ГосСОПКА, либо создавать свои Центры ГосСОПКА, что потребует существенных затрат. Для защиты информации в КИИ требуется выполнять комплекс организационных и технических мер по обеспечению безопасности информации в КИИ, перечисленных в том числе в Приказах №239 и №31 ФСТЭК России.
Критичная персональная компьютерная наработка что это

Просто удивительно то, насколько велико непонимание вокруг такого широко распространенного понятия, как MTBF (Mean Time Between Failure — «Время между сбоями» или «наработка на отказ» ), насколько смысла этой величины не понимают, зачастую, даже специалисты в области хранения данных.
Казалось бы — что может быть проще. «Наработка на отказ» это время беспроблемной работы, от первого включения нового диска, до момента отказа, посчитанная в часах.
Почти любой, кто поинтересуется значением, приводимым производителями, в качестве MTBF современных дисков, и с легкостью сделает несложные подсчеты, будет удивлен странной его величиной.
На сегодня величина MTBF приводится в миллион или даже полтора миллиона часов.
В году — примерно 8760 часов, значит, исходя из нашего понимания «физического смысла» этого значения, производитель планирует «наработку на отказ» для любого такого диска более ста лет (114 лет, для миллиона часов MTBF), что является очевидной нелепостью для каждого, у кого подыхали жесткие диски.
Тогда что это за «миллион часов», где и каким образом он измерен?
Конечно же производитель не гоняет диск 114 лет, оценка производится искусственно, но откуда вообще взялась величина в «миллион часов»?
Дело в том, что MTBF измеряется для всей эксплуатируемой «дисковой популяции», и распространяется на период объявленного гарантийного срока для данного типа дисков. Оба выделенных момента являются важными, и часто опускаются в описании, что и приводит к принципиальному непониманию.
Представим себе, что мы поставили в сервер жесткий диск, который проработал 3 года гарантийного срока, и, будучи исправным, был заменен на новый. Следующий проработал три года, и был заменен по истечении гарантийного срока, и так далее. И вот на 38-м диске вы вправе ожидать, что до конца гарантийного срока он не доработает.
Или же представим себе чуть более приближенную к реальности ситуацию.
Допустим, для простоты подсчета, у нас есть система хранения на 115 дисков. Для каждого диска производитель приводит MTBF равный миллиону часов. Но надо принять во внимание то, что в большой дисковой популяции общий MTBF, то есть вероятность отказа, растет, с увеличением количества используемых дисков.
Для 115 дисков, исходя из приводимой вендором величины MTBF, мы вправе ожидать, что хотя бы один диск из популяции в 115 выйдет из строя до конца трехлетнего гарантийного срока.
Этот вариант уже куда более похож на правду.
Строго говоря, на практике, вместо MTBF гораздо практичнее пользоваться параметром AFR — Annual Failure Rate, или «ежегодная вероятность сбоев», выводимом из MTBF.
Он вычисляется как: AFR = 1-exp(-8760/MTBF)
Величина AFR для диска с миллионом часов MTBF составляет 0,87%, что, в принципе, хоть и чуть завышено (Google в известном исследовании 2007 года показывает для новых дисков в пределах гарантийного срока как раз AFR в районе 1%), но, все же уже довольно хорошо согласуется с практикой.
Любопытно, что, например, такой производитель жестких дисков как WD теперь вовсе перестал указывать величину MTBF, перейдя на указание другого параметра: «power on/off cycles», по видимому не в последнюю очередь именно в связи с явно видимым непониманием и неочевидностью применения указываемой величины MTBF пользователями.
Критичная персональная компьютерная наработка что это
Согласно ГОСТ 27.002-89 для оценки надежности используются следующие термины, с которыми мы сталкиваемся в магазине: «наработка на отказ» – наработка от окончания восстановления работоспособного состояния после отказа до возникновения следующего отказа. Это в случае ремонтопригодной продукции. Эквивалент в английской литературе – MTBF (Mean (operating) time between failures) – среднее время между отказами. В случае продукции не подлежащей ремонту используется термин «наработка до отказа» – наработка от начала эксплуатации до возникновения первого отказа. Эквивалент в английской литературе – MTTF (Mean (operating) time to failures) – среднее время до отказа.
Для комплектующих обычных компьютеров длительность нисходящей кривой значительно больше. В этом случае, для получения информации о длительности периода, когда проявляется заводской брак, очень важны рекламации от покупателя, потому что невозможно выискивать дефекты в течение месяцев на заводе у многих тысяч устройств. К тому же, некоторые наименования комплектующих ПК за год устаревают и сходят с рынка.
Далее следует вторая горизонтальная часть кривой, когда вероятность отказа примерно постоянна. Длительность ее и есть MTBF. Половина этой длительности часто берется производителем в качестве ориентира для определения гарантийного срока.
Покупателю, не сталкивающемуся с большими объемами продукции, MTBF мало о чем говорит, скорее может ввести в заблуждение. Более понятным и не требующим гаданий был бы вероятностный показатель времени наработки на отказ. Например, “за время работы 3 года вероятность отказа составит не менее 95%”. Т.е., за 3 года работы должны поломаться не более 5% устройств данного типа. И покупатель сразу же знал бы, что из 100 устройств, подобных купленному, есть большая вероятность, что 5 может поломаться в течение 3 лет. И никто не даст гарантию, что это будет не ваш винчестер.
Как определяется надежность компьютерных компонентов? Производитель, как правило, определяет наработку на отказ на основании заявленной надёжности используемых компонентов, кратковременных интенсивных испытаний партии изделий и сложных многофакторных расчетов, учитывающих множество меняющихся во времени причин, которые влияют на термин надежности изделия. Для этого применяется ряд методик, которые хорошо обкатаны военными.
Схематически это выглядит так. В течение года тестировалось 1000 изделий. За время теста 10 вышло из строя. Отсюда MTBF будет равно 1год х (1000шт/10шт) = 100 годам = 876580 часам (1 год = 8765.8 часов). Производитель округлит и напишет 900000 часов, потому что продавец все равно даст гарантию 2-3 года. 900000 часов – это срок, по истечению которого существует высокая вероятность того, что изделие из данной серии выйдет из строя.
Это все статистика. Кроме нее есть еще ряд субъективных причин, определяющих несколько дополнительных факторов ненадежности устройств, вопреки тому, что из-за жесткости конкуренции, все производители постоянно совершенствуют свою продукцию, стараясь сделать ее еще более надежной не увеличивая стоимости.
Пример. В начале этого года компания Seagate получила статус авторизованного субъекта экономической деятельности (Authorized Economic Operator, AEO) в Европейском Союзе. Этот статус предоставляет привилегии при прохождении таможенных служб, так как 27 государств ЕС признали Seagate надежным оператором. Это не только экономит фирме деньги, но и стимулирует ввоз качественной продукции, потому как является одним из факторов высокой репутации.
Вторая причина. С одной стороны производить «вечные» комплектующие для ПК, которые морально и функционально устаревают через 3 года, бессмысленно, а с другой стороны, технологическое удлинение срока жизни работы устройства вызывает значительное удорожание продукции.
Третья проблема связана с тем, что любой производитель свою продукцию тестирует и часть приходится браковать. Иногда тестирует и оптовый покупатель. В случае обнаружения дефекта, бракуется вся партия. Иногда за спиной этого процесса пасутся «умники», которые скупают такую продукцию по дешевке, отбирают или собирают работающие экземпляры, сортируют, упаковывают и поставляют легально или контрабандой в третьи страны. Цена ПК, собранного на «левой» элементной базе будет, естественно, не ниже чем в США или Англии. А прибыль выше.
Следующая диаграмма качественно демонстрирует зависимость затрат производителя по устранению дефектов на разных этапах производственного процесса: разработка (design), тестирование (evaluation), производство (production).
Как видно из диаграммы, наибольшие затраты по выявлению дефектов производитель несет при производстве изделия. Именно на этом этапе возможна максимальная экономия средств, т.е. удешевление продукции и за счет этого повышение ее конкурентоспособности, а значит и прибыли. Это добавляет дополнительный фактор, снижающий качество продукции.
Например, MTBF для винчестера в среднем равно 500000 часам или 57 годам. Но фирма дала гарантию всего 1 год, а почему так – скромно умолчала. Придя домой с новым винтом и сбросив на него все свои файлы, покупатель с ужасом может обнаружить, что через 3 месяца его новый HDD со всеми фильмами, фотографиями и прочим приказал долго жить и ремонту не подлежит. Продавец, конечно, его заменит, но кто восстановит потерянное? Именно вышеприведенные причины часто являются тем фактором, о котором продавец скромно умалчивает и почему дает гарантию всего на 1 год.
Почему производитель не пишет MTBF, например, 100 лет вместо 50? Кто возьмется это проверять, если реально цикл жизни составляет, например, 3 года из-за морального устаревания устройства и прекращения его выпуска? В первую очередь это происходит потому, что производитель опирается на результаты натурных стрессовых испытаний и математического моделирования. Данные исследования проводятся независимыми лабораториями, с выдачей сертификатов, и эти данные мы уже читаем, как декларируемый ресурс изделия. Но результаты исследований дают на выходе только вероятность выхода из строя. Какие-то экземпляры устройств могут прожить значительно дольше срока MTBF, и мы с этим иногда сталкиваемся, но вероятность такого события после окончания MTBF резко падает со временем.
Когда мы приходим покупать ПК, нас убеждают, что то, что должно поломаться из-за заводских дефектов, поломается в первый год, и поэтому достаточно годовой гарантии. Из практических исследований известно, что наибольшая часть комплектующих действительно вылетает или в первый год эксплуатации или через несколько лет на стадии уже начавшегося износа. Но это только часть правды, т.к. продавец скрывает главное, а именно: у хорошего товара пики максимальной вероятности выхода из строя также приходятся на первый год и на год износа в будущем, но эта вероятность такова, что экономически все равно выгодно остается давать 2-3 годичный гарантийный срок. Если на ПК 1 год гарантии, значит товар не лучшего качества.
Приведем упрощенный вариант расчета параметра MTBF для ПК собранного в фирме, которая использует обычные комплектующие и дает гарантию на изделие 1 год.
Компоненты ПК______MTBF-MTTF (часы)______MTBF-MTTF (годы)_____Вероятность отказа за год
Системная плата____100000_________________11________________ ___0.09
RAM, модуль №1_____500000_________________60__________________ _0.01
RAM, модуль №2_____500000_________________60__________________ _0.01
Вентилятор №1______55000__________________6__________________ __0.17
Вентилятор №2______55000__________________6__________________ __0.17
Блок питания________100000_________________11__________ _________0.09
Итого __________________________________________________ ________S = 0.89
MTBF (наработка на отказ) и гарантия в мире компьютеров. Что важно?
Вероятностный показатель ненадёжности
Покупателю, не сталкивающемуся с большими объемами продукции, MTBF мало о чем говорит, скорее может ввести в заблуждение. Более понятным и не требующим гаданий был бы вероятностный показатель времени наработки на отказ. Например, “за время работы 3 года вероятность отказа составит не менее 95%”. Т.е., за 3 года работы должны поломаться не более 5% устройств данного типа. И покупатель сразу же знал бы, что из 100 устройств, подобных купленному, есть большая вероятность, что 5 может поломаться в течение 3 лет. И никто не даст гарантию, что это будет не ваш винчестер.
Как определяется надежность компьютерных компонентов? Производитель, как правило, определяет наработку на отказ на основании заявленной надёжности используемых компонентов, кратковременных интенсивных испытаний партии изделий и сложных многофакторных расчетов, учитывающих множество меняющихся во времени причин, которые влияют на термин надежности изделия. Для этого применяется ряд методик, которые хорошо обкатаны военными.
Схематически это выглядит так. В течение года тестировалось 1000 изделий. За время теста 10 вышло из строя. Отсюда MTBF будет равно 1год х (1000шт/10шт) = 100 годам = 876580 часам (1 год = 8765.8 часов). Производитель округлит и напишет 900000 часов, потому что продавец все равно даст гарантию 2-3 года. 900000 часов – это срок, по истечению которого существует высокая вероятность того, что изделие из данной серии выйдет из строя.
Надёжность и рынки сбыта
Это все статистика. Кроме нее есть еще ряд субъективных причин, определяющих несколько дополнительных факторов ненадежности устройств, вопреки тому, что из-за жесткости конкуренции, все производители постоянно совершенствуют свою продукцию, стараясь сделать ее еще более надежной не увеличивая стоимости.
Пример. В начале этого года компания Seagate получила статус авторизованного субъекта экономической деятельности (Authorized Economic Operator, AEO) в Европейском Союзе. Этот статус предоставляет привилегии при прохождении таможенных служб, так как 27 государств ЕС признали Seagate надежным оператором. Это не только экономит фирме деньги, но и стимулирует ввоз качественной продукции, потому как является одним из факторов высокой репутации.
Вторая причина. С одной стороны производить «вечные» комплектующие для ПК, которые морально и функционально устаревают через 3 года, бессмысленно, а с другой стороны, технологическое удлинение срока жизни работы устройства вызывает значительное удорожание продукции.
Третья проблема связана с тем, что любой производитель свою продукцию тестирует и часть приходится браковать. Иногда тестирует и оптовый покупатель. В случае обнаружения дефекта, бракуется вся партия. Иногда за спиной этого процесса пасутся «умники», которые скупают такую продукцию по дешевке, отбирают или собирают работающие экземпляры, сортируют, упаковывают и поставляют легально или контрабандой в третьи страны. Цена ПК, собранного на «левой» элементной базе будет, естественно, не ниже чем в США или Англии. А прибыль выше.
Следующая диаграмма качественно демонстрирует зависимость затрат производителя по устранению дефектов на разных этапах производственного процесса: разработка (design), тестирование (evaluation), производство (production).
Как видно из диаграммы, наибольшие затраты по выявлению дефектов производитель несет при производстве изделия. Именно на этом этапе возможна максимальная экономия средств, т.е. удешевление продукции и за счет этого повышение ее конкурентоспособности, а значит и прибыли. Это добавляет дополнительный фактор, снижающий качество продукции.
Например, MTBF для винчестера в среднем равно 500000 часам или 57 годам. Но фирма дала гарантию всего 1 год, а почему так – скромно умолчала. Придя домой с новым винтом и сбросив на него все свои файлы, покупатель с ужасом может обнаружить, что через 3 месяца его новый HDD со всеми фильмами, фотографиями и прочим приказал долго жить и ремонту не подлежит. Продавец, конечно, его заменит, но кто восстановит потерянное? Именно вышеприведенные причины часто являются тем фактором, о котором продавец скромно умалчивает и почему дает гарантию всего на 1 год.
Почему производитель не пишет MTBF, например, 100 лет вместо 50? Кто возьмется это проверять, если реально цикл жизни составляет, например, 3 года из-за морального устаревания устройства и прекращения его выпуска? В первую очередь это происходит потому, что производитель опирается на результаты натурных стрессовых испытаний и математического моделирования. Данные исследования проводятся независимыми лабораториями, с выдачей сертификатов, и эти данные мы уже читаем, как декларируемый ресурс изделия. Но результаты исследований дают на выходе только вероятность выхода из строя. Какие-то экземпляры устройств могут прожить значительно дольше срока MTBF, и мы с этим иногда сталкиваемся, но вероятность такого события после окончания MTBF резко падает со временем.
Когда мы приходим покупать ПК, нас убеждают, что то, что должно поломаться из-за заводских дефектов, поломается в первый год, и поэтому достаточно годовой гарантии. Из практических исследований известно, что наибольшая часть комплектующих действительно вылетает или в первый год эксплуатации или через несколько лет на стадии уже начавшегося износа. Но это только часть правды, т.к. продавец скрывает главное, а именно: у хорошего товара пики максимальной вероятности выхода из строя также приходятся на первый год и на год износа в будущем, но эта вероятность такова, что экономически все равно выгодно остается давать 2-3 годичный гарантийный срок. Если на ПК 1 год гарантии, значит товар не лучшего качества.
Приведем упрощенный вариант расчета параметра MTBF для ПК собранного в фирме, которая использует обычные комплектующие и дает гарантию на изделие 1 год.
MTBF (наработка на отказ) и гарантия в мире компьютеров. Что важно?
Введение
Разработчик – производитель – продавец – покупатель. Этот стандартный путь проходит любое устройство, будь то электронный блок для космического телескопа или ПК на вашем рабочем столе. И на каждом этапе используются результаты анализа, выполненного с помощью теории надежности.
Как известно, покупатели делятся на две принципиально разные категории: частные лица и фирмы. Корпоративный покупатель обеспечен внимательным отношением, так как он умеет не только защищаться, но и выбирать продавца с подходящей репутацией. А обычный покупатель и защищен плохо, и считать ему приходится каждый рубль. О нем и пойдет речь.
Не все вещи доживают до конца гарантии
Когда такой покупатель приходит в магазин компьютерной техники, один из главных вопросов, который его волнует – надежность устройства. Каждому хочется, чтобы его ПК устарел морально и физически, будучи в рабочем состоянии, и чтобы не пришлось через месяц после окончания гарантийного срока мучиться вопросом «что полетело?» и «во что обойдется теперь ремонт?».
Что такое MTBF, «наработка на отказ» или «ресурс»
Согласно ГОСТ 27.002-89 для оценки надежности используются следующие термины, с которыми мы сталкиваемся в магазине: «наработка на отказ» – наработка от окончания восстановления работоспособного состояния после отказа до возникновения следующего отказа. Это в случае ремонтопригодной продукции. Эквивалент в английской литературе – MTBF (Mean (operating) time between failures) – среднее время между отказами. В случае продукции не подлежащей ремонту используется термин «наработка до отказа» – наработка от начала эксплуатации до возникновения первого отказа. Эквивалент в английской литературе – MTTF (Mean (operating) time to failures) – среднее время до отказа.
Часто встречается также термин Lifetime warranty. Это, как правило, гарантия соответствия параметров изделия на все время его эксплуатации. Некоторые фирмы ограничивают гарантию каким то количеством лет (обычно не больше пяти) после прекращения выпуска данного изделия или изделия способного его заменить. Поэтому, если эти нюансы принципиальны, то в спецификации желательно прочесть, что подразумевает производитель под lifetime warranty.
100 лет может прожить только танк. в мирное время
Покупая то или иное устройство, мы можем, наряду с гарантийным сроком, столкнуться с упомянутой терминологией. Если продавец сообщает, что у выбранного вами процессора, который не подлежит ремонту, MTBF составляет 500000 часов – это неправильно. Для процессора должно быть указано MTTF. MTBF должно употребляться только для ремонтопригодных устройств.
Терминология, используемая производителем и продавцом, употребляется иногда достаточно вольно, так как юридически все определяет описание того в каком значении применен данный термин к данному устройству. Это должно присутствовать в прилагаемых документах. «Уши» такого подхода «растут» из принципов регулирования главного рынка планеты – США, которые вырабатываются Федеральной Комиссией по Торговле (The Federal Trade Commission).
Как оценивается MTBF? Это иллюстрирует нижеследующая диаграмма, где приведена U-образная кривая интенсивности отказов (bathtub curve) для электронного устройства некоего научного оборудования, чтобы читатель мог видеть, что можно иметь в идеале при покупке электроники, в том числе компьютерной.
По вертикальной оси отложена вероятность выхода устройства из строя. По горизонтальной оси – время без соблюдения масштаба. Левая кривая перед красной границей соответствует длительности времени в течение которого большая часть устройств выходит из строя при наличии брака. На этом этапе бракованные устройства для научного оборудования отсеиваются сразу же, на заводе при стрессовых испытаниях. Это возможно, т.к. длительность выявления брака не превышает 50 часов и число устройств не велико.
Для комплектующих обычных компьютеров длительность нисходящей кривой значительно больше. В этом случае, для получения информации о длительности периода, когда проявляется заводской брак, очень важны рекламации от покупателя, потому что невозможно выискивать дефекты в течение месяцев на заводе у многих тысяч устройств. К тому же, некоторые наименования комплектующих ПК за год устаревают и сходят с рынка.
Далее следует вторая горизонтальная часть кривой, когда вероятность отказа примерно постоянна. Длительность ее и есть MTBF. Половина этой длительности часто берется производителем в качестве ориентира для определения гарантийного срока.
Справа от красной границы, после окончания срока MTBF, кривая демонстрирует увеличение вероятности отказов. Имеются ввиду не только поломки, но и отклонение параметров работы изделия от требуемых. Это увеличение вероятности выхода обусловлено тем, что ряд элементов в устройстве достигает своего жизненного предела из-за технологии изготовления, т.е. наступает технологический износ элементной базы. Таким образом, время MTBF статистически определяет время работоспособной жизни устройства при заданных условиях эксплуатации.
MTBF, MTTR, MTTA и MTTF
Понимание некоторых из наиболее распространенных метрик инцидентов
В современном постоянно движущемся мире сбои в работе и технические инциденты становятся как никогда важными. Ошибки и простои ведут к реальным последствиям. Пропущенные сроки. Задержки оплаты. Задержки работы по проектам.
Вот почему для компаний важно количественно оценивать и отслеживать показатели безотказной работы, времени перебоя работы и того, как быстро и эффективно команды решают проблемы.
Некоторые из наиболее часто отслеживаемых в отрасли метрик: MTBF (средняя наработка на отказ), MTTR (среднее время восстановления, исправления, реагирования или устранения), MTTF (средняя наработка до отказа) и MTTA (среднее время подтверждения) — эти метрики предназначены для того, чтобы помочь техническим командам понять, как часто происходят инциденты и как быстро команда справляется с ними.
Многие эксперты спорят о действительной пользе этих метрик, если использовать их в отрыве от остальных показателей, потому что они не дают ответа на сложные вопросы о том, как устраняются инциденты, что работает, а что нет, и как, когда и почему проблемы обостряются или ослабляются.
С другой стороны, MTTR, MTBF и MTTF могут быть хорошей основой или эталоном, с которых стоит начинать обсуждение более глубоких и важных вопросов.

Как профессионалы реагируют на крупные инциденты
Получите наше бесплатное руководство по управлению инцидентами. Изучите все инструменты и методы, которые Atlassian использует для управления крупными инцидентами.
Оговорка об MTTR
Говоря об MTTR, можно предположить, что это один показатель с одним значением. В действительности за ним скрываются четыре разных показателя. «R» может означать решение (repair), реагирование (respond), устранение (resolve) или восстановление (recovery), и хотя эти четыре показателя перекрываются, каждый имеет собственный смысл и особенности.
Поэтому если вашей команде нужно отслеживать MTTR, рекомендуется уточнить, какой именно MTTR имеется в виду и как его определить. Прежде чем вы начнете отслеживать успехи и неудачи, у вашей команды должно быть общее понимание того, что именно вы отслеживаете.
MTBF: средняя наработка на отказ
Что такое средняя наработка на отказ?
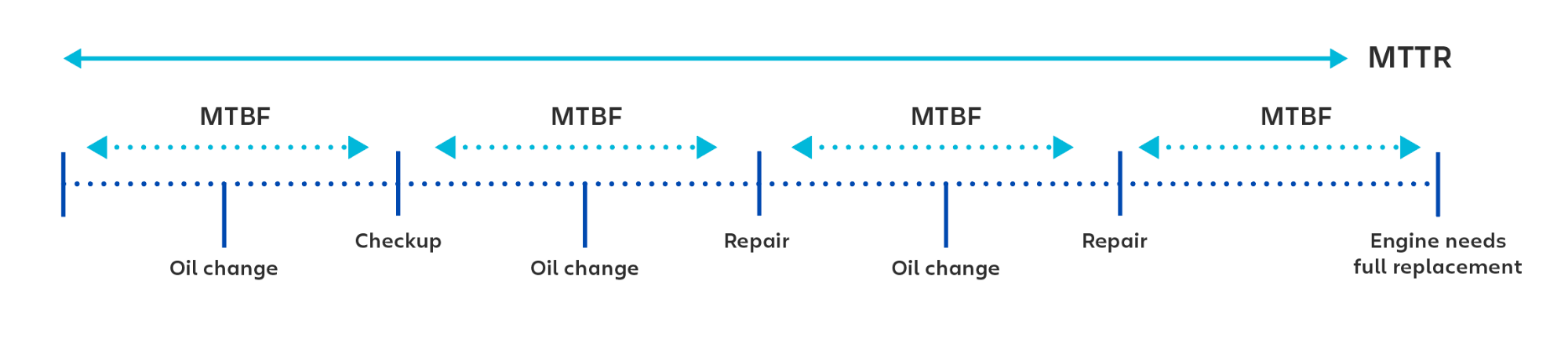
MTBF (средняя наработка на отказ) — это среднее время между исправляемыми сбоями технологического продукта. Эта метрика используется для отслеживания как доступности, так и надежности продукта. Чем больше времени проходит между отказами, тем надежнее система.
Цель для большинства компаний — сохранить наработку на отказ как можно выше, достигнув сотни тысяч (или даже миллионов) часов между инцидентами.
Как рассчитать среднюю наработку на отказ
MTBF рассчитывается с использованием среднего арифметического. По сути, вы должны взять данные за период, на который вы хотите рассчитать MTBF (можно за шесть месяцев, год, за пять лет), и поделить общее время работы за этот период на количество сбоев.
Итак, предположим, что мы оцениваем 24-часовой период и за этот период мы потеряли два часа из-за двух отдельных инцидентов. Наше общее время безотказной работы составляет 22 часа. Разделим на два и получаем 11 часов. Итак, наша наработка на отказ составляет 11 часов.
Поскольку эта метрика используется для отслеживания надежности, наработка на отказ не учитывает ожидаемое время простоя во время планового технического обслуживания. Вместо этого она фокусируется на неожиданных простоях и проблемах.
Происхождение понятия средней наработки на отказ
MTBF берет свое начало в авиационной отрасли, где системные сбои означают особенно серьезные последствия не только с точки зрения стоимости, но и человеческой жизни. С тех пор эта аббревиатура пробралась в различные технические и механические отрасли промышленности и особенно часто используется в производстве.
Как и когда использовать среднюю наработку на отказ
Время наработки на отказ полезно для покупателей, которые хотят быть уверены, что получают самый надежный продукт, полетят на самом надежном самолете или выберут самое безопасное производственное оборудование для своего завода.
Для внутренних команд эта метрика помогает выявлять проблемы и отслеживать успехи и неудачи. Она также может помочь компаниям разработать подробные рекомендации для клиентов, чтобы они знали, когда они должны заменить деталь, обновить систему или принести продукт на техническое обслуживание.
MTBF — это метрика для сбоев в восстанавливаемых системах. Для сбоев, требующих замены системы, обычно используют термин MTTF (средняя наработка до отказа).
Например, представьте двигатель автомобиля. При расчете времени между внеплановыми техническими обслуживаниями двигателя следует использовать MTBF (среднюю наработку на отказ). При расчете времени до полной замены двигателя вы должны использовать MTTF (среднюю наработку до отказа).
MTTR: среднее время исправления
Что такое среднее время исправления?
MTTR (среднее время ремонта) — это среднее время, необходимое для ремонта системы (обычно технического или механического). Оно включает в себя как время ремонта, так и любое время тестирования. В этой метрике учитывается все время до тех пор, пока система не будет снова полностью работоспособна.
Как рассчитать среднее время исправления
Вы можете рассчитать MTTR, суммируя общее время, затраченное на ремонт в течение любого заданного периода, а затем разделив это время на количество ремонтов.
Итак, предположим, мы считаем эту метрику для ремонта в течение недели. За это время было 10 простоев, и системы активно ремонтировались в течение четырех часов. Четыре часа — это 240 минут. 240 делим на 10 и получаем 24. Что означает, что среднее время ремонта в этом случае будет составлять 24 минуты.
Ограничения среднего времени исправления
Среднее время ремонта не всегда совпадает с тем же временем, что и время сбоя работы системы. В некоторых случаях ремонт начинается в течение нескольких минут после сбоя продукта или сбоя системы. В других случаях между собственно инцидентом, обнаружением инцидента и началом ремонта бывает некоторая задержка.
Эта метрика наиболее полезна при отслеживании того, как быстро обслуживающий персонал может устранить проблему. Она не предназначена для выявления проблем с системными оповещениями или задержками перед восстановлением, которые также являются важными факторами при оценке успехов и сбоев программы управления инцидентами.
Как и когда использовать среднее время исправления
MTTR — это метрика, которую используют команды поддержки и технического обслуживания для обеспечения восстановительных работ на нужном уровне. Цель состоит в том, чтобы этот показатель был как можно ниже за счет повышения эффективности процессов восстановления и продуктивности команд.
MTTR: среднее время восстановления
Что такое среднее время восстановления?
MTTR (среднее время восстановления или среднее время стабилизации) — это среднее время восстановления после сбоя работы продукта или системы. Оно включает в себя полное время простоя с момента выхода из строя системы или продукта до момента, когда они снова становятся полностью работоспособными.
Это основной показатель DevOps, который, по мнению программы DevOps Research and Assessment (DORA), можно использовать для оценки стабильности команды DevOps.
Как рассчитать среднее время восстановления
Среднее время восстановления рассчитывается путем суммирования всего времени простоя в работе за определенный период и деления его на количество инцидентов. Итак, предположим, что наши системы были отключены на 30 минут в течение двух отдельных инцидентов за 24-часовой период. 30 делим на два, получаем 15, так что наш MTTR составляет 15 минут.
Ограничения среднего времени восстановления
MTTR используется для измерения скорости полного процесса восстановления. Достаточно ли она высокая? А по сравнению с вашими конкурентами?
Эта общая метрика помогает определить, есть ли у вас проблемы. Однако если вы хотите диагностировать, в какой именно части вашего процесса есть проблема (проблема в вашей системе оповещений? команда слишком много времени работает над исправлением? кто-то слишком долго отвечает на запрос на исправление?), то вам понадобится больше данных. Потому что между сбоем и восстановлением может произойти много чего.
Проблема может быть связана с вашей системой оповещения. Существует ли задержка между сбоем и отправкой оповещения? Достаточно ли быстро оповещения доходят до нужного человека?
Проблема может быть в диагностике. Можете ли вы быстро выяснить, в чем проблема? Существуют ли процессы, которые можно было бы улучшить?
Или проблема может быть с самим процессом исправления. Достаточно ли эффективны ваши команды технического обслуживания? Если они тратят все свое время на исправление, то что именно их тормозит?
Вам нужно будет копнуть глубже, чем MTTR, чтобы ответить на эти вопросы, но среднее время восстановления может стать отправной точкой для диагностики того, существует ли проблема в процессе восстановления и требует ли она более глубокого анализа.
Как и когда использовать среднее время восстановления
MTTR является хорошей метрикой для оценки скорости общего процесса восстановления.
MTTR: среднее время разрешения
Что такое среднее время разрешения?
MTTR (среднее время разрешения) — это среднее время, необходимое для полного устранения сбоя. Оно включает в себя не только время, затраченное на обнаружение сбоя, диагностику проблемы и ее устранение, но и время, затраченное на предотвращение повторения проблемы.
Эта метрика расширяет ответственность команды, обрабатывающей исправление: она задает ожидания в плане повышения ее продуктивности в долгосрочной перспективе. В этом и заключается разница между простым тушением пожара и тушением пожара с последующей установкой противопожарной системы.
Существует сильная связь между этим MTTR и удовлетворенностью клиентов, так что этой метрике нужно уделить особое внимание.
Как рассчитать среднее время разрешения
Чтобы рассчитать этот MTTR, рассчитайте полное время разрешения в течение периода, который вы хотите отслеживать, и разделите на количество инцидентов.
Таким образом, если ваши системы были отключены в общей сложности 2 часа за 24-часовой период из-за одного инцидента и команды потратили еще 2 часа на исправление, чтобы гарантировать, что сбой системы не повторится, в сумме получается 4 часа, потраченных на решение проблемы. Это означает, что ваш MTTR составляет 4 часа.
Заметка об отслеживании среднего времени разрешения
Имейте в виду, что MTTR чаще всего рассчитывается с использованием рабочих часов (поэтому если вы восстановите работу в конце рабочего дня и потратите время на исправление основной проблемы первым делом на следующее утро, ваш MTTR не будет включать 16 часов, в течение которых вы не работали). Если у вас есть команды в разных часовых поясах и вы работаете круглосуточно или если у вас есть дежурные сотрудники, работающие во внеурочное время, важно определить, как вы будете отслеживать время для этой метрики.
Как и когда использовать среднее время разрешения
MTTR обычно используется, когда речь идет о незапланированных инцидентах, а не о запросах на обслуживание (которые обычно планируются).
MTTR: среднее время реагирования
Что такое среднее время реагирования?
MTTR (среднее время реагирования) — это среднее время, необходимое для восстановления после сбоя продукта или системы с момента первого оповещения об этом сбое. Оно не включает время задержки в вашей системе оповещения.
Как рассчитать среднее время реагирования
Чтобы рассчитать этот MTTR, рассчитайте полное время отклика с момента получения оповещения до того, когда продукт или услуга снова полностью функционируют. Затем разделите его на количество инцидентов.
Например: если у вас было 4 инцидента за 40-часовую рабочую неделю и вы потратили на них 1 час (от оповещения до исправления), то MTTR за эту неделю будет составлять 15 минут.
Как и когда использовать среднее время реагирования
MTTR часто используется в кибербезопасности при измерении успеха команды в нейтрализации атак на систему.
MTTA: среднее время подтверждения
Что такое среднее время подтверждения?
MTTA (среднее время подтверждения) — это среднее время, которое проходит с момента отправки оповещения до начала работы над исправлением. Эта метрика полезна для измерения скорости реагирования вашей команды и эффективности вашей системы оповещения.
Как рассчитать среднее время подтверждения
Чтобы рассчитать MTTA, посчитайте время между отправкой оповещения и подтверждением его получения, а затем разделите на количество инцидентов.
Например: если у вас было 10 инцидентов и в общей сложности прошло 40 минут между отправкой оповещения и подтверждением его получения для всех 10, вы поделите 40 на 10 и получите в среднем 4 минуты.
Как и когда использовать среднее время подтверждения
Метрика MTTA полезна для отслеживания отзывчивости. Ваша команда устала от оповещений и слишком долго отвечает на сообщения об инцидентах? Эта метрика поможет вам обнаружить и проанализировать эту проблему.
MTTF: средняя наработка до отказа
Что такое средняя наработка до отказа?
MTTF (средняя наработка до отказа) — среднее время между неремонтируемыми отказами технологического продукта. Например, если автомобильные двигатели марки X исправно работают в среднем 500 000 часов, до того как они полностью выйдут из строя и будут подлежать замене, MTTF двигателей будет составлять 500 000.
Эта метрика помогает понять, как долго система будет исправно работать, и определить, превосходит ли новая версия системы старую. Метрика позволяет предоставить клиентам информацию об ожидаемом сроке исправной работы и о том, когда следует запланировать проверку системы.
Как рассчитать среднюю наработку до отказа
Средняя наработка до отказа — это среднее арифметическое, которое определяется как сумма общего времени работы оцениваемых продуктов, деленная на общее количество устройств.
Например: предположим, вы рассчитываете MTTF лампочек. Как долго лампочки бренда Y в среднем работают, прежде чем они перегорают? Далее предположим, что для расчета у вас есть четыре лампочки (если вам нужны статистически значимые данные, вам понадобится гораздо больше, но, чтобы не перегружать вас расчетами, давайте возьмем всего четыре).
Лампочка А горит 20 часов. Лампочка B — 18. Лампочка C —21. И лампочка D —21 час. Это в общей сложности 80 часов горения лампочки. Делим на четыре и получаем MTTF в 20 часов.

Проблема, связанная со средней наработкой до отказа
Для таких случаев, как лампочки, смысл MTTF совершенно ясен. Мы можем включить лампочки и ждать до тех пор, пока не перегорит последняя, а затем использовать полученную информацию, чтобы сделать выводы о времени работы наших лампочек.
Но что происходит, когда мы измеряем что-то, что не перегорает так быстро? Что-то, что должно бесперебойно работать в течение долгих лет? Хотя MTTF часто используется и для этих случаев, эта метрика — не лучший выбор. Потому что мы не держим продукт включенным до тех пор, пока он не выйдет из строя; в основном мы запускаем продукт на определенный период времени и измеряем количество выходов из строя.
Например: предположим, что мы пытаемся получить статистику MTTF на планшетах бренда Z. Планшеты по-хорошему рассчитаны на долгие годы, но у бренда Z есть всего шесть месяцев для сбора данных. Поэтому тестируют 100 планшетов в течение шести месяцев. Допустим, один планшет ломается ровно на шестимесячной отметке.
Итак, мы умножаем общее время работы (полгода, умноженное на 100 планшетов) и получаем 600 месяцев. Только один планшет вышел из строя, так что мы разделим значение на один, и наш MTTR будет составлять 600 месяцев, то есть 50 лет.
Прослужат ли планшеты Brand Z в среднем 50 лет каждый? Маловероятно. И поэтому эта метрика не подходит в таких случаях.
Как и когда использовать среднюю наработку до отказа
MTTF хорошо работает, когда вы пытаетесь оценить средний срок службы продуктов и систем с коротким сроком службы (например, лампочек). Показатель предназначен только для случаев, когда оценивается полное прекращение работы продукта. При расчете времени между инцидентами, требующими восстановления, предпочтительной аббревиатурой является MTBF (средняя наработка на отказ).
MTBF, MTTR, MTTF и MTTA
Итак, какую метрику лучше использовать, когда дело доходит до отслеживания и улучшения управления инцидентами?
Хотя они иногда используются взаимозаменяемо, каждая метрика позволяет рассмотреть ситуацию с разных сторон. При совместном использовании они могут показать более полную картину и дать вам понять, насколько успешна ваша команда в управлении инцидентами и что она может улучшить.
![]()
Среднее время восстановления показывает, как быстро у вас получается возобновить работу ваших систем.
Рассчитайте среднее время реагирования, и вы получите представление о том, сколько времени восстановления тратится на работу вашей команды и сколько — на получение оповещения.
Потом рассчитайте среднее время исправления, и вы поймете, сколько времени команда тратит на исправление, а сколько на диагностику.
Теперь рассчитайте среднее время разрешения, и вы начнете понимать весь процесс исправления и решения проблем, выходящий за рамки самого простоя, который они вызывают.
Посчитайте среднюю наработку на отказ, и картина станет еще шире: вы увидите, насколько успешна ваша команда в предотвращении или сокращении будущих проблем.
А затем добавьте среднюю наработку до отказа, чтобы понять полный жизненный цикл продукта или системы.
Надлежащее управление запросами на обслуживание означает, что вы даете ИТ-команде возможность сосредоточиться на том, что наиболее важно для организации в целом, одновременно повышая качество обслуживания клиентов. Гибкий программный инструмент, такой как Jira Service Management, может помочь вашей команде навести порядок и настроить рабочие процессы согласно потребностям команды.