5.3.3. Таблицы маршрутизации в ip-сетях
Программные модули протокола IP устанавливаются на всех конечных станциях и маршрутизаторах сети. Для продвижения пакетов они используют таблицы маршрутизации.
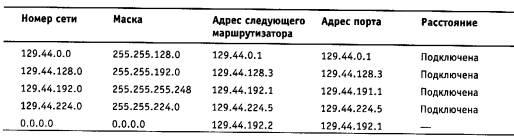
Если представить, что в качестве маршрутизатора Ml в данной сети работает штатный программный маршрутизатор MPR операционной системы Microsoft Windows NT, то его таблица маршрутизации могла бы иметь следующий вид (табл. 5.9).
Таблица 5.9. Таблица программного маршрутизатора MPR Windows NT

Если на месте маршрутизатора М1 установить аппаратный маршрутизатор NetBuilder II компании 3 Com, то его таблица маршрутизации для этой же сети может выглядеть так, как показано в табл. 5.10.
Таблица 5.10. Таблица маршрутизации аппаратного маршрутизатора NetBuilder II компании 3  Com
Com
Таблица 5.11 представляет собой таблицу маршрутизации для маршрутизатора Ml, реализованного в виде программного маршрутизатора одной из версий операционной системы Unix.
Т  аблица 5.11. Таблица маршрутизации Unix-маршрутизатора
аблица 5.11. Таблица маршрутизации Unix-маршрутизатора
Назначение полей таблицы маршрутизации
Несмотря на достаточно заметные внешние различия, во всех трех таблицах есть все те ключевые параметры (три параметра), необходимые для работы маршрутизатора :
• адрес сети назначения (столбцы «Destination» в маршрутизаторах NetBuilder и Unix или «Network Address» в маршрутизаторе MPR) и
• адрес следующего маршрутизатора (столбцы «Gateway» в маршрутизаторах NetBuilder и Unix или «Gateway Address» в маршрутизаторе MPR).
• адрес порта, на который нужно направить пакет, в некоторых таблицах указывается прямо (поле «Interface» в таблице Windows NT), а в некоторых — косвенно. Так, в таблице Unix-маршрутизатора вместо адреса порта задается его условное наименование — 1е0 для порта с адресом 198.21.17.5, lei для порта с адресом 213.34.12.3 и 1о0 для внутреннего порта с адресом 127.0.0.1.
В маршрутизаторе NetBuilder II поле, обозначающее выходной порт в какой-либо форме, вообще отсутствует. Это объясняется тем, что адрес выходного порта всегда можно косвенно определить по адресу следующего маршрутизатора.
Остальные параметры, которые можно найти в представленных версиях таблицы маршрутизации, являются необязательными для принятия решения о пути следования пакета.
Наличие или отсутствие поля маски в таблице говорит о том, насколько современен данный маршрутизатор. Стандартным решением сегодня является использование поля маски в каждой записи таблицы, как это сделано в таблицах маршрутизаторов MPR Windows NT (поле «Netmask») и NetBuilder (поле «Mask»). Отсутствие поля маски говорит о том, что либо маршрутизатор рассчитан на работу только с тремя стандартными классами адресов, либо он использует для всех записей одну и ту же маску, что снижает гибкость маршрутизации.
Метрика, как видно из примера таблицы Unix-маршрутизатора, является необязательным параметром. В остальных двух таблицах это поле имеется, однако оно используется только в качестве признака непосредственно подключенной сети.
Источники и типы записей в таблице маршрутизации (подробнее – см. [1] стр. 56—58):
1-ый — ПО стека TCP/IP. При инициализации маршрутизатора это ПО автоматически заносит в таблицу несколько записей, в результате чего создается так называемая минимальная таблица маршрутизации.
• Это, во-первых, записи о непосредственно подключенных сетях и маршрутизаторах по умолчанию (default)
• Во-вторых, ПО автоматически заносит в таблицу м-ции записи об адресах особого назначения.
— Особый адрес 127.0.0.0 (loopback), который используется для локального тестирования стека TCP/IP. Пакеты, направленные в сеть с номером 127.0.0.0, не передаются протоколом IP на канальный уровень для последующей передачи в сеть, а возвращаются в источник — локальный модуль IP.
— Записи с адресом 224.0.0.0 требуются для обработки групповых адресов (multicast address).
— Кроме того, в таблицу могут быть занесены адреса, предназначенные для обработки широковещательных рассылок
2-ой — администратор, непосредственно формирующий запись с пом. некоторой сист. утилиты, например программы route, имеющейся в ОС Unix и Windows NT. В аппаратных м-рах также всегда имеется команда для ручного задания записей таблицы м-ции. Заданные вручную записи всегда являются статическими, то есть не имеют срока истечения жизни. Эти записи могут быть как постоянными, то есть сохраняющимися при перезагрузке маршрутизатора, так и временными, хранящимися в таблице только до выключения устройства. Часто администратор вручную заносит запись default о м-ре по умолчанию. Таким же образом в таблицу м-ции может быть внесена запись о специфичном для узла маршруте. Специфичный для узла маршрут содержит вместо номера сети полный IP-адрес, то есть адрес, имеющий ненулевую информацию не только в поле номера сети, но и в поле номера узла. Предполагается, что для такого конечного узла маршрут должен выбираться не так, как для всех остальных узлов сети, к которой он относится. В случае когда в таблице есть разные записи о продвижении пакетов для всей сети и ее отдельного узла, при поступлении пакета, адресованного узлу, маршрутизатор отдаст предпочтение записи с полным адресом узла.
3-ий — протоколы м-ции, такие как RIP или OSPF. Такие записи всегда являются динамическими, то есть имеют ограниченный срок жизни. Программные м-ры Windows NT и Unix не показывают источник появления той или иной записи в таблице, а м-р NetBuilder использует для этой цели поле «Source». В приведенном в табл. 5.10 примере первые две записи созданы программным обеспечением стека на основании данных о конфигурации портов маршрутизатора — это показывает признак «Connected». Следующие две записи обозначены как «Static», что указывает на то, что их ввел вручную администратор. Последняя запись является следствием работы протокола RIP, поэтому в ее поле «TTL» имеется значение 160.
Маршрутизация с использованием масок [1] стр. 61 – 70
Рис. 5.15. Разделение адресного пространства сети класса В 129.44.0.0 на четыре равные части путем использования масок одинаковой длины 255.255.192.0
спользование масок для структуризации сети (Маршрутизация с использованием масок одинаковой длины [1] стр. 61 – 65)
Р ассмотрим, как изменяется работа модуля IP, когда становится необходимым учитывать наличие масок. Во-первых, в каждой записи таблицы маршрутизации появляется новое поле — поле маски.
ассмотрим, как изменяется работа модуля IP, когда становится необходимым учитывать наличие масок. Во-первых, в каждой записи таблицы маршрутизации появляется новое поле — поле маски.
Во-вторых, меняется алгоритм определения маршрута по таблице маршрутизации. После того как IP-адрес извлекается из очередного полученного IP-пакета, необходимо определить адрес следующего маршрутизатора, на который надо передать пакет с этим адресом. Модуль IP последовательно просматривает все записи таблицы маршрутизации. С каждой записью производятся следующие действия.
• Маска М, содержащаяся в данной записи, накладывается на IP-адрес узла назначения, извлеченный из пакета.
• Полученное в результате число является номером сети назначения обрабатываемого пакета. Оно сравнивается с номером сети, который помещен в данной записи таблицы маршрутизации.
•  Если номера сетей совпадают, то пакет передается маршрутизатору, адрес которого помещен в соответствующем поле данной записи. [1] стр. 65
Если номера сетей совпадают, то пакет передается маршрутизатору, адрес которого помещен в соответствующем поле данной записи. [1] стр. 65
Рис. 5.16. Маршрутизация с использованием масок одинаковой длины

Таблица 5.12. Таблица маршрутизатора М2 в сети с масками одинаковой длины
Использование масок переменной длины (Технология VLSM. Variable Length Subnet Mask)
В предыдущем примере использования масок (см. рис. 5.15 и 5.16) все подсети имеют одинаковую длину поля номера сети — 18 двоичных разрядов, и, следовательно, для нумерации узлов в каждой из них отводится по 14 разрядов. То есть все сети являются очень большими и имеют одинаковый размер. Однако в этом случае, как и во многих других, более эффективным явилось бы разбиение сети на подсети разного размера. В частности, большое число узлов, вполне желательное для пользовательской подсети, явно является избыточным для подсети, которая связывает два маршрутизатора по схеме «точка-точка». В этом случае требуются всего два адреса для адресации двух портов соседних маршрутизаторов. В предыдущем же примере для этой вспомогательной сети Ml — М2 был использован номер, позволяющий адресовать 214 узлов, что делает такое решение неприемлемо избыточным. Администратор может более рационально распределить имеющееся в его распоряжении адресное пространство с помощью масок переменной длины.
На рис. 5.17 приведен пример распределения адресного пространства, при котором избыточность имеющегося множества IP-адресов может быть сведена к минимуму. Половина из имеющихся адресов (215) была отведена для создания сети с адресом 129.44.0.0 и маской 255.255.128.0. Следующая порция адресов, составляющая четверть всего адресного пространства (214), была назначена для сети 129.44.128.0 с маской 255.255.192.0. Далее в пространстве адресов был «вырезан» небольшой фрагмент для создания сети, предназначенной для связывания внутреннего маршрутизатора М2 с внешним маршрутизатором Ml.
В IP-адресе такой вырожденной сети для поля номера узла как минимум должны быть отведены два двоичных разряда. Из четырех возможных комбинаций номеров узлов: 00, 01,10 и 11 два номера имеют специальное назначение и не могут быть присвоены узлам, но оставшиеся два 10 и 01 позволяет адресовать порты маршрутизаторов. В нашем примере сеть была выбрана с некоторым запасом — на 8 узлов. Поле номера узла в таком случае имеет 3 двоичных разряда, маска в десятичной нотации имеет вид 255.255.255.248, а номер сети, как видно из рис. 5.17, равен в данном конкретном случае 129.44.192.0. Если эта сеть является локальной, то на ней могут быть расположены четыре узла помимо двух портов маршуртизаторов.

Рис. 5.17. Разделение адресного пространства сети класса В 129.44.0.0 на сети разного размера путем использования масок переменной длины
ПРИМЕЧАНИЕ Заметим, что глобальным связям между маршрутизаторами типа «точка-точка» не обязательно давать IP-адреса, так как к такой сети не могут подключаться никакие другие узлы, кроме двух портов маршрутизаторов. Однако чаще всего такой вырожденной сети все же дают IP-адрес. Это делается, например, для того, чтобы скрыть внутреннюю структуру сети и обращаться к ней по одному адресу входного порта маршрутизатора, в данном примере по адресу 129.44.192.1. Кроме того, этот адрес может понадобиться при туннелировании немаршрутизируемых протоколов в IP-пакеты, что будет рассмотрено ниже.
О  ставшееся адресное пространство администратор может «нарезать» на разное количество сетей разного объема в зависимости от своих потребностей. Из оставшегося пула (214 — 4) адресов администратор может образовать еще одну достаточно большую сеть с числом узлов 213. При этом свободными останутся почти столько же адресов (213 — 4), которые также могут быть использованы для создания новых сетей. К примеру, из этого «остатка» можно образовать 31 сеть, каждая из которых равна размеру стандартной сети класса С, и к тому же еще несколько сетей меньшего размера. Ясно, что разбиение может быть другим, но в любом случае с помощью масок переменного размера администратор всегда имеет возможность гораздо рациональнее использовать все имеющиеся у него адреса.
ставшееся адресное пространство администратор может «нарезать» на разное количество сетей разного объема в зависимости от своих потребностей. Из оставшегося пула (214 — 4) адресов администратор может образовать еще одну достаточно большую сеть с числом узлов 213. При этом свободными останутся почти столько же адресов (213 — 4), которые также могут быть использованы для создания новых сетей. К примеру, из этого «остатка» можно образовать 31 сеть, каждая из которых равна размеру стандартной сети класса С, и к тому же еще несколько сетей меньшего размера. Ясно, что разбиение может быть другим, но в любом случае с помощью масок переменного размера администратор всегда имеет возможность гораздо рациональнее использовать все имеющиеся у него адреса.
Рис. 5.18. Сеть, структурированная с использованием масок переменной длины
Таблица маршрутизации М2, соответствующая структуре сети, показанной на рис. 5.18, содержит записи о четырех непосредственно подключенных сетях и запись о маршрутизаторе по умолчанию (табл. 5.13). Процедура поиска маршрута при использовании масок переменной длины ничем не отличается от подобной процедуры, описанной ранее для масок одинаковой длины.
Таблица 5.13. Таблица маршрутизатора М2 в сети с масками переменной длины
Некоторые особенности масок переменной длины проявляются при наличии так называемых «перекрытий». Под перекрытием понимается наличие нескольких маршрутов к одной и той же сети или одному и тому же узлу. В этом случае адрес сети в пришедшем пакете может совпасть с адресами сетей, содержащихся сразу в нескольких записях таблицы маршрутизации.
Рассмотрим пример. Пусть пакет, поступивший из внешней сети на маршрутизатор Ml, имеет адрес назначения 129.44.192.5. Ниже приведен фрагмент таблицы маршрутизации маршрутизатора Ml. Первая из приведенных двух записей говорит о том, что все пакеты, адреса которых начинаются на 129.44, должны быть переданы на маршрутизатор М2. Эта запись выполняет агрегирование адресов всех подсетей, созданных на базе одной сети 129.44.0.0. Вторая строка говорит о том, что среди всех возможных подсетей сети 129.44.0.0 есть одна, 129.44.192.0, для которой пакеты можно направлять непосредственно, а не через м-р М2.

Если следовать стандартному алгоритму поиска маршрута по таблице, то сначала на адрес назначения 129.44.192.5 накладывается маска из первой строки 255.255.0.0 и получается результат 129.44.0.0, который совпадает с номером сети в этой строке. Но и при наложении на адрес 129.44.192.5 маски из второй строки 255.255.255.248 полученный результат 129.44.192.0 также совпадает с номером сети во второй строке. В таких случаях должно быть применено следующее правило: «Если адрес принадлежит нескольким подсетям в базе данных маршрутов, то продвигающий пакет маршрутизатор использует наиболее специфический маршрут, то есть выбирается адрес подсети, дающий большее совпадение разрядов».
В данном примере будет выбран второй маршрут, то есть пакет будет передан в непосредственно подключенную сеть, а не пойдет кружным путем через маршрутизатор М2.
Механизм выбора самого специфического маршрута является обобщением понятия «маршрут по умолчанию». Поскольку в традиционной записи для маршрута по умолчанию 0.0.0.0 маска 0.0.0.0 имеет нулевую длину, то этот маршрут считается самым неспецифическим и используется только при отсутствии совпадений со всеми остальными записями из таблицы маршрутизации.
ПРИМЕЧАНИЕ В IP-пакетах при использовании механизма масок по-прежнему передается только IP-адрес назначения, а маска сети назначения не передается. Поэтому из IP-адреса пришедшего пакета невозможно выяснить, какая часть адреса относится к номеру сети, а какая — к номеру узла. Если маски во всех подсетях имеют один размер, то это не создает проблем. Если же для образования подсетей применяют маски переменной длины, то маршрутизатор должен каким-то образом узнавать, каким адресам сетей какие маски соответствуют. Для этого используются протоколы маршрутизации, переносящие между маршрутизаторами не только служебную информацию об адресах сетей, но и о масках, соответствующих этим номерам. К таким протоколам относятся протоколы RIPv2 и OSPF, а вот, например, протокол RIP маски не распространяет и для использования масок переменной длины не подходит.
Технология бесклассовой междоменной маршрутизации CIDR
За последние несколько лет в сети Internet многое изменилось: резко возросло число узлов и сетей, повысилась интенсивность трафика, изменился характер передаваемых данных. Из-за несовершенства протоколов маршрутизации обмен сообщениями об обновлении таблиц стал иногда приводить к сбоям магистральных маршрутизаторов из-за перегрузки при обработке большого объема служебной информации. Так, в 1994 году таблицы магистральных маршрутизаторов в Internet содержали до 70 000 маршрутов.
На решение этой проблемы была направлена, в частности, и технология бес-классовой междоменной маршрутизации (Classless Inter-Domain Routing, CIDR), впервые о которой было официально объявлено в 1993 году, когда были опубликованы RFC 1517, RFC 1518, RFC 1519 и RFC 1520.
Суть технологии CIDR заключается в следующем. Каждому поставщику услуг Internet должен назначаться непрерывный диапазон в пространстве IP-адресов. При таком подходе адреса всех сетей каждого поставщика услуг имеют общую старшую часть — префикс, поэтому маршрутизация на магистралях Internet может осуществляться на основе префиксов, а не полных адресов сетей. Агрегирование адресов позволит уменьшить объем таблиц в маршрутизаторах всех уровней, а следовательно, ускорить работу маршрутизаторов и повысить пропускную способность Internet.

Рис. 5.19. Технологии CIDR

Рис. 5.20. Выигрыш в количестве записей в маршрутизаторе при использовании технологии CIDR
еление IP-адреса на номер сети и номер узла в технологии CIDR происходит не на основе нескольких старших бит, определяющих класс сети (А, В или С), а на основе маски переменной длины, назначаемой поставщиком услуг. На рис. 5.19 показан пример некоторого пространства IP-адресов, которое имеется в распоряжении гипотетического поставщика услуг. Все адреса имеют общую часть в k старших разрядах — префикс. Оставшиеся п разрядов используются для дополнения неизменяемого префикса переменной частью адреса. Диапазон имеющихся адресов в таком случае составляет 2n. Когда потребитель услуг обращается к поставщику услуг с просьбой о выделении ему некоторого количества адресов, то в имеющемся пуле адресов «вырезается» непрерывная область S1, S2, S3 или S4 соответствующего размера. Причем границы этой области выбираются такими, чтобы для нумерации требуемого числа узлов хватило некоторого числа младших разрядов, а значения всех оставшихся (старших) разрядов было одинаковым у всех адресов данного диапазона. Таким условиям могут удовлетворять только области, размер которых кратен степени двойки, А границы выделяемого участка должны быть кратны требуемому размеру.
Рассмотрим пример. Пусть поставщик услуг Internet располагает пулом адресов в диапазоне 193.20.0.0-193.23.255.255 (1100 0001.0001 0100.0000 0000.0000 0000-11000001.0001 0111.11111111.11111111) с общим префиксом 193.20(11000001.0001 01) и маской, соответствующей этому префиксу 255.252.0.0.
Если абоненту этого поставщика услуг требуется совсем немного адресов, например 13, то поставщик мог бы предложить ему различные варианты: сеть 193.20.30.0, сеть 193.20.30.16 или сеть 193.21.204.48, все с одним и тем же значением маски 255.255.255.240. Во всех случаях в распоряжении абонента для нумерации узлов имеются 4 младших бита.
Рассмотрим другой вариант, когда к поставщику услуг обратился крупный заказчик, сам, возможно собирающийся оказывать услуги по доступу в Internet. Ему требуется блок адресов в 4000 узлов. В этом случае поставщик услуг мог бы предложить ему, например, диапазон адресов 193,22.160.0-193.22.175.255 с маской 255.255.240.0. Агрегированный номер сети (префикс) в этом случае будет равен 193.22.160.0.
Администратор маршрутизатора М2 (рис. 5.20) поместит в таблицу маршрутизации только по одной записи на каждого клиента, которому был выделен пул адресов, независимо от количества подсетей, организованных клиентом. Если клиент, получивший сеть 193.22.160.0, через некоторое время разделит ее адресное пространство в 4096 адресов на 8 подсетей, то в маршрутизаторе М2 первоначальная информация о выделенной ему сети не изменится.
Для поставщика услуг верхнего уровня, поддерживающего клиентов через маршрутизатор Ml, усилия поставщика услуг нижнего уровня по разделению его адресного пространства также не будут заметны. Запись 193.20.0,0 с маской 255.252.0,0 полностью описывает сети поставщика услуг нижнего уровня в маршрутизаторе Ml.
Итак, внедрение технологии CIDR позволяет решить две основные задачи.
• Более экономное расходование адресного пространства. Действительно, получая в свое распоряжение адрес сети, например, класса С, некоторые организации не используют весь возможный диапазон адресов просто потому, что в их сети имеется гораздо меньше 255 узлов. Технология CIDR отказывается от традиционной концепции разделения адресов протокола IP на классы, что позволяет получать в пользование столько адресов, сколько реально необходимо. Благодаря технологии CIDR поставщики услуг получают возможность «нарезать» блоки из выделенного им адресного пространства в точном соответствии с требованиями каждого клиента, при этом у клиента остается пространство для маневра на случай его будущего роста.
• Уменьшение числа записей в таблицах маршрутизаторов за счет объединения маршрутов — одна запись в таблице маршрутизации может представлять большое количество сетей. Действительно, для всех сетей, номера которых начинаются с одинаковой последовательности цифр, в таблице маршрутизации может быть предусмотрена одна запись (см. рис. 5.20). Так, маршрутизатор М2 установленный в организации, которая использует технику CIDR для выделения адресов своим клиентам, должен поддерживать в своей таблице маршрутизации все 8 записей о сетях клиентов. А маршрутизатору Ml достаточно иметь одну запись о всех этих сетях, на основании которой он передает пакеты с префиксом 193.20 маршрутизатору М2, который их и распределяет по нужным портам.
Если все поставщики услуг Internet будут придерживаться стратегии CIDR, то особенно заметный выигрыш будет достигаться в магистральных маршрутизаторах.
Технология CIDR уже успешно используется в текущей версии IPv4 и поддерживается такими протоколами маршрутизации, как OSPF, RIP-2, BGP4. Предполагается, что эти же протоколы будут работать и с новой версией протокола IPv6. Следует отметить, что в настоящее время технология CIDR поддерживается магистральными маршрутизаторами Internet, а не обычными хостами в локальных сетях.
Использование CIDR в сетях IPv4 в общем случае требует перенумерации сетей. Поскольку эта процедура сопряжена с определенными временными и материальными затратами, для ее проведения пользователей нужно каким-либо образом стимулировать. В качестве таких стимулов рассматривается, например, введение оплаты за строку в таблице маршрутизации или же за количество узлов в сети. При использовании классов сетей абонент часто не полностью занимает весь допустимый диапазон адресов узлов — 254 адреса для сети класса С или 65 534 адреса для сети класса В. Часть адресов узлов обычно пропадает. Требование оплаты каждого адреса узла поможет пользователю решиться на перенумерацию, с тем чтобы получить ровно столько адресов, сколько ему нужно.
Что такое роутинг или маршрутизация простыми словами для чайников

Маршрутизатор или роутер — это аппаратное средство, которое обрабатывает отправляемые или получаемые потоки данных. В роли маршрутизаторов часто выступают отдельные устройства , что обеспечивает максимально быструю работу с данными , или обычные компьютеры с правильно настроенным специализированным программным обеспечением.
Роутинг — это сложный механизм передачи данных
-
Прямой роутинг — это когда данные могут передаваться внутри одной сети, минуя IP-маршрутизацию. При таком подходе перед отправкой данных узел отправителя проверяет, находится ли получатель с ним в одной сети. И если это так, тогда отправитель отправляет на адрес получателя необходимый пакет данных. Для «определения адреса» в таком подходе есть даже собственный протокол ARP (Address Resolution Protocol).
-
Косвенный роутинг — это когда пакеты с данными передаются между разными IP-сетями. В этом случае при передаче пакетов есть «посредник», он же маршрутизатор, он же роутер. При таком подходе отправитель передает пакет с данными маршрутизатору, а тот уже доставляет данные по нужному адресу.
-
Как правило, к одному роутеру подключа е т ся несколько различных интерфейсов разных сетей. Поэтому роутеру в первую очередь необходимо определить , в какой интерфейс отправлять пакет данных.
-
Следующим шагом роутер должен выяснить, что конкретно нужно сделать с данными. Тут у роутера есть 2 решения: либо он передает пакет данных сразу в сеть, либо он передает данные другому маршрутизатору в этой сети. Когда он передает данные другому роутеру, то ему нужно точно знать , какому именно передать , ч тобы именно к передаваемому роутеру была подключена сеть с получателем.
Таблицы роутинга
-
Адрес шлюза — это адрес самого роутера и других роутеров, на которые отправляются пакеты с данными.
-
Интерфейс — это физические порты, по которым осуществляется движение пакетов.
-
Метрику — числовое значение, определяющее приоритет маршрута.
-
Маску подсети — это битовое значение, которое помогает определить по заданному IP-адресу адреса отдельных узлов подсети и адрес самой подсети.
-
Сетевой адрес — это ID устройства, подключенного к общей сети.
Как записываются данные в таблицу?
-
Роутер сам прописывает маршрут передачи и осуществляет записи в таблицу. Такой способ применим по «прямому маршруту», когда передача данных осуществляется внутри одной сети.
-
Маршруты можно прописать «вручную». При таком подходе прописывается адрес следующего соседнего роу те ра, которому передаются пакеты данных, а он уже распределяет их по подключенным к нему сетям.
-
Маршруты прописываются автоматически, используя протоколы маршрутизации. Данные протоколы самостоятельно отслеживают изменения в компоновке сети и вносят соответствующие коррективы в таблицу маршрутов.
Как рассчитывается маршрут роутинга
-
возможности полосы пропускания;
-
время, необходимое для перемещения пакета от отправителя к получателю;
-
загруженность канала передачи информации в момент времени;
-
насколько надежен потенциальный канал передачи, то есть есть ли в нем какие-либо ошибки;
-
потенциальное количество переходов между роутерами.
Заключение
Роутинг — это неосязаемый процесс, который виден , только если его специально просмотреть. Даже сейчас, читая нашу статью, вы просто не замечаете , сколько незримых процессов происходит, а их происходит очень много.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Лекция 2 — Статическая маршрутизация
В самом начале развития сети было принято решение раздавать IP-адреса блоками, было создано три вида блока, и зарезервировано под эти блоки адреса:
Типы адресов:
unicast — уникальный адрес, адрес конкретного хоста.
broadcast — широковещательный адрес, адрес для все хостов.
multicast — групповой адрес, адрес для группы хостов.
Классы адресов
| Класс | Длина сетевой части адреса в байтах | Первое число | Количество IP — адресов в блоке | Пример блока |
| A | 1 | 0-127 | 16 777 216 | 122.0.0.0/255.0.0.0 или 122.0.0.0/8 |
| B | 2 | 128-191 | 65 536 | 152.126.0.0/255.255.0.0 или 122.126.0.0/16 |
| C | 3 | 192-223 | 256 | 83.149.236.0/255.255.255.0 или 122.149.236.0/24 |
| Специальные адреса | ||||
| D | — | 224-239 | групповые адреса | |
| E | — | 240-255 | для экспериментальных целей | |
Пояснение, откуда появились именно такие адреса
Как показала практика, такое распределение оказалось не эффективным. Самая большая потребность именно в сетях класса C, а не в B и A. Но классы B и A «съели» большую часть адресов, и их стало не хватать.
Поэтому была принята бесклассовая раздача адресов, которая позволяет, например, дать блок в несколько адресов, либо блок из 256 и еще 64 адресов.
Это пока спасает ситуацию до перехода на IPv6.
Для того, что бы выделить четыре адреса в блок, используют маску подсети, например:
выделим адреса с 83.149.236.0 по 83.149.236.31 в отдельный блок, чтоб задать 32 адреса нужно 5 бит (2^5=32)
83.149.236.0/255.255.255.224 или 83.149.236.0/27 (32-5=27)
Почему называется маска?
01010011 10010101 11101100 00000000 — сеть 83.149.236.0
Наложим маску на адрес (логическое И, 1и1=1, 1и0=0, 0и0=0)
01010011 10010101 11101100 00010000 — проверяемый адрес 83.149.236.16
11111111 11111111 11111111 11100000 — маска 255.255.255.224
01010011 10010101 11101100 00000000 — получаем сеть 83.149.236.0 (в двоичном, см. выше)
Это был адрес принадлежащий сети.
Возьмем адрес не принадлежащий сети — 83.149.236.64
01010011 10010101 11101100 01000000 — проверяемый адрес 83.149.236.64
11111111 11111111 11111111 11100000 — маска 255.255.255.224
01010011 10010101 11101100 01000000 — не получаем сеть 83.149.236.0, значит адрес не принадлежит сети.
Адреса зарезервированные для закрытых локальных сетей (в Интернете их не видно):
Специальные адреса (зарезервированные).
127.0.0.1 — это адрес обратной связи (loopback) — пакеты по нему реально в сеть не отправляются. Этому адресу по умолчанию назначают имя localhost.
255.255.255.255 — широковещательный адрес, для всех сетей. Используется для DHCP.
Широковещательный (broadcast) адрес сети.
Пакеты посланные на широковещательный адрес, должны принимать все компьютеры этой сети.
Принято назначать широковещательным — последний адрес сети.
для сети 83.149.236.0/24
83.149.236.255 — broadcast адрес сети 83.149.236.0/24.
83.149.236.0 — адрес сети, unicast-адреса с таким номером быть не должно. Т.е. минимальный размер подсети может быть в 4 адреса.
Кроме случая, когда используется маска 32, для указания одного unicast-адреса, например — 83.149.236.36/32
Групповой адрес (multicast).
Предназначен для группы хостов.
Например, адрес 224.0.0.5 — адрес OSPF — маршрутизаторов, т.е. все OSPF — маршрутизаторы обязаны принимать пакеты с адресом назначения 224.0.0.5.
Статическая маршрутизация.
Для маршрутизации нужна маршрутная информация, куда (на какой интерфейс) пакет отправлять, зная адрес назначения.
Статическая маршрутизация — это когда таблица маршрутизации формируется «вручную».
Таблицы маршрутизации.
Для получения таблицы маршрутизации используется команда route.
Рассмотрим таблицы маршрутизации самой простой сети.
Столбцы таблицы маршрутизации:
Destination — адрес сети назначения
Gateway — адрес шлюза
Genmask — маска сети назначения
Flags — флаги
U — показывает, что маршрут активен.
G — показывает, что маршрут проходит через промежуточный маршрутизатор (Gateway).
H — специфический маршрут, маршрут к этому хосту отличается от маршрута ко всей этой сети.
Metric — метрика, если для отправки можно использовать несколько маршрутов, позволяет делать выбор.
Метрика =0 обозначает, что эта сеть непосредственно подключена к данному интерфейсу.
Ref — сколько раз ссылались на данный маршрут при обработке пакетов
Use — количество пакетов, переданное по данному маршруту.
Iface — интерфейс для отправки пакетов.
Таблица (linux) маршрутизации на 192.168.0.6
В таблице прописаны два правила:
Пакеты для сети 192.168.0.0/255.255.255.0 посылать напрямую, т.е. не через маршрутизатор.
Пакеты для всех остальных сетей посылать на default-маршрутизатор с адресом 192.168.0.1.
Таблица (linux) маршрутизации на 192.168.0.1
В таблице прописаны три правила:
Пакеты для сети 192.168.0.0/255.255.255.0 посылать напрямую, через интерфейс eth1.
Пакеты для сети 83.149.236.64/255.255.255.224 посылать напрямую, через интерфейс eth0.
Пакеты для всех остальных сетей посылать на default-маршрутизатор с адресом 83.149.236.92, через интерфейс eth0.
В разных системах таблицы немного отличаются, но в целом очень похожи.
Пример таблицы маршрутизации в Windows
Источники информации для таблицы маршрутизации:
Ручная настройка сетевых интерфейсов.
Ручная настройка default маршрутизатора.
Ручная настройка настройка маршрутов.
Динамические протоколы — RIP, OSPF и т.д.
Рассмотрим intranet сеть (без выхода в Интернет) из четырех сегментов.
Таблица (linux) маршрутизации на маршрутизаторе.
Таблица (linux) маршрутизации на 192.168.0.6.
Таблица (linux) маршрутизации на 192.168.1.128.
Таблица (linux) маршрутизации на 192.168.2.32.
Таблица (linux) маршрутизации на 192.168.3.64.
Маршрутизация без маски (на классах).
Таблица (linux) маршрутизации без использования маски
Маршрутизация с маской (CIDR).
Это позволяет создавать непрерывное адресное пространство с разным количеством адресов, и маршрут к нему, что уменьшает записей в таблице и оптимальнее распределять адресное пространство.
Сети для самых маленьких. Часть восьмая. BGP и IP SLA
До сих пор мы варились в собственном соку – VLAN’ы, статические маршруты, OSPF. Плавно росли над собой из зелёных студентов в крепких инженеров.
Теперь отставим в сторону эти игрушки, пришло время BGP.
- Разбираемся с протоколом BGP: виды, атрибуты, принципы работы, настройка
- Подключаемся к провайдеру по BGP
- Организуем резервирование и распределение нагрузки между несколькими линками
- Рассмотрим вариант резервирования без использования BGP – IP SLA
Сначала освежим в памяти основы протоколов динамической маршрутизации.
Бывает два вида протоколов: IGP (внутренние по отношению к вашей автономной системе) и EGP (внешние).
И те и другие опираются на один из двух алгоритмов: DV (Distance Vector) и LS (Link State).
Внутренние мы уже рассматривали. К ним относятся ISIS/OSPF/RIP/EIGRP. Нужны они для того, чтобы обеспечить распространение маршрутной информации внутри вашей сети.
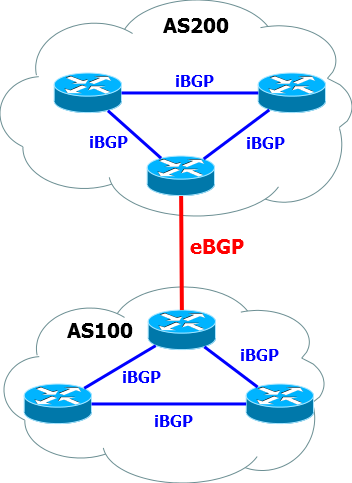
EGP представляет только один протокол – BGP – Border Gateway Protocol. Он призван обеспечивать передачу маршрутов между различными сетями (автономными системами).
Грубо говоря, стык между Балаган-Телекомом и его аплинковым провайдером будет точно организован через BGP.
То есть схема применения примерно такая:

Автономномые системы – AS
BGP неразрывно связан с понятием Автономной Системы (AS – Autonomous System), которое уже не раз встречалось в нашем цикле.
Согласно определению вики, АС — это система IP-сетей и маршрутизаторов, управляемых одним или несколькими операторами, имеющими единую политику маршрутизации с Интернетом.
Чтобы было немного понятнее, можно, например, представить, что город – это автономная система. И как два города связаны между собой магистралями, так и две АС связываются между собой BGP. При этом внутри каждого города есть своя дорожная система – IGP.
Вот как это выглядит с небольшого отдаления:

В BGP AS – это не просто какая-то абстрактная вещь для удобства. Эта штука весьма формализована, есть специальные окошки в собесе, где можно в будние дни с 9 до 6 получить номер автономной системы. Выдачей этих номеров занимаются RIR (Regional Internet Registry) или LIR (Local Internet Registry).
Вообще глобально этим занимается IANA. Но чтобы не разорваться, она делегирует свои задачи RIR – это региональные организации, каждая из которых отвечает за определённую часть планеты (Для Европы и России – это RIPE NCC)

LIR’ом может стать почти любая желающая организация при наличии необходимых документов. Они нужны для того, чтобы RIR’у не пришлось напрягаться с запросами от таких мелких контор, как ЛинкМиАп.
Ну вот, например, Балаган-Телеком мог бы быть LIR’ом. И у него мы и взяли ASN (номер АС) – 64500, например. А у самого у него AS 64501.
До 2007 года были возможны только 16-ибитные номера AS, то есть всего было доступно 65536, номеров. 0 и 65535 – зарезервированы.
Номера 64512 до 65534 предназначены для приватных AS, которые не маршрутизируются глобально – что-то вроде приватных IP-адресов.
Номера 64496-64511 – для использования в примерах и документации, чем мы и воспользуемся.
Сейчас возможно использование 32битных номеров AS. Этот переход значительно легче, чем IPv4->IPv6.
Опять же нельзя говорить об автономных системах без привязки к блокам IP-адресов. На практике с каждой AS должен быть связан какой-то блок адресов.
PI и PA адреса
На самом деле PI – это Provider Independent.
В обычной ситуации, когда вы подключаетесь к провайдеру, он выдаёт вам диапазон публичных адресов – так называемые PA-адреса (Provider Aggregatable).
Получить их – раз плюнуть, но если вы не являетесь LIR’ом, то при смене провайдера придётся возвращать и PA-адреса. Тем более фактически допускается подключение только к одному провайдеру.
И если вы решите сменить провайдера, то старые адреса уйдут вместе с ним, а новый провайдер выдаст новые. Ну и где тут гибкость?
У LIR вы можете приобрести повайдеро-независимый блок адресов (PI) и обязательно ASN. В нашем случае пусть это будет блок 100.0.0.0/23, который мы будем анонсировать по BGP своим соседям. И эти адреса уже чисто наши и никакие провайдеры нам не страшны: не понравился один – ушли к другому с сохранением своих адресов.
Получить PI-адреса всегда было не очень просто. Вам нужно подготовить массу документов, обосновать необходимость такого блока итд.
Сейчас с исчерпанием IPv4 получить большие блоки становится всё сложнее. RIR их уже не выдаёт, а LIR раздают последнее.
Таким образом и номера AS и PI-адреса можно получить в одних их тех же конторах.
Предположим, что в нашем случае компания ЛинкМиАп получила блок адресов 100.0.0.0/23 и AS 64500. Возвращаясь к нашей аналогии, мы дали городу имя и снабдили его диапазоном индексов.
Так вот для того, чтобы нам из своей AS передать информацию об этих публичных адресах в другую AS (читай в Интернет) и используется BGP. И если вы думаете, что яндекс или майкрософт использует какие-то небесные технологии для подключения своих ЦОДов к Интернету, то вы ошибаетесь – всё тот же BGP.
Теперь главный вопрос, который интересует всегда новичков: а зачем BGP, почему не взять пресловутый OSPF или вообще статику?
Наверное, большие дяди могут очень подробно и обстоятельно объяснить это, мы же постараемся дать поверхностное понимание.
– Если говорить о OSPF/IS-IS, то это Link-State алгоритмы, которые подразумевают (внимание!), что каждый маршрутизатор знает топологию всей сети. Представляем себе миллионы маршрутизаторов в Интернете и отказываемся от идеи использовать Link State для этих целей вообще.
RIP, EIGRP… Кхе-кхе. Ну, тут всё понятно.
– IGP – это нечто интимное и каждому встречному ISP показывать его не стоит. Даже без AS ситуация, когда клиент поднимает IGP с провайдером, крайне редкая (за исключением L3VPN). Дело в том, что IGP не имеют достаточно гибкой системы управления маршрутами – для LS-протоколов это вообще знать всё или ничего (опять же можно фильтровать на границе зоны, но гибкости никакой).
В итоге оказывается, что придётся открывать кому-то чужому потаённые части своей приватной сети или настраивать хитрые политики импорта между различными IGP-процессами.
– В данный момент в интернете более 450 000 маршрутов. Если бы даже OSPF/ISIS могли хранить всю топологию Интернета, представьте сколько времени заняла бы работа алгоритма SPF.
Вот наглядный пример, чем может быть опасно использование IGP там, где напрашивается нечто глобальное.
Поэтому нужен свой специальный протокол для взаимодействия между AS.
Во-первых, он должен быть дистанционно-векторным – это однозначно. Маршрутизатор не должен делать расчёт маршрута до каждой сети в Интернете, он лишь должен выбрать один из нескольких предложенных.
Во-вторых, он должен иметь очень гибкую систему фильтрации маршрутов. Мы должны легко определять, что светить соседям, а что не нужно выносить из избы.
В-третьих, он должен быть легко масштабируемым, иметь защиту от образования петель и систему управления приоритетами маршрутов.
В-четвёртых, он должен обладать высокой стабильностью. Поскольку данные о маршрутах будут передаваться через среду, которая не всегда может обладать гарантированным качеством (за стык отвечают по крайней мере две организации), необходимо исключить возможные потери маршрутной информации.
Ну и логичное, в-пятых, он должен понимать, что такое AS, отличать свою AS от чужих.
Встречайте: BGP.
Вообще описание работы этого поистине грандиозного протокола мы разобьём на две части. И сегодня рассмотрим принципиальные моменты.
BGP делится на IBGP и EBGP.
IBGP необходим для передачи BGP-маршрутов внутри одной автономной системы. Да, BGP часто запускается и внутри AS, но об этом мы плотненько поговорим в другой раз.
EBGP – это обычный BGP между автономными системами. На нём и остановимся.
Установление BGP-сессии и процедура обмена маршрутами
Возьмём типичную ситуацию, когда у нас подключение к провайдерскому шлюзу организовано напрямую.

Устройства, между которыми устанавливается BGP-сессия называются BGP-пирами или BGP-соседями.
BGP не обнаруживает соседей автоматически – каждый сосед настраивается вручную.
Процесс установления отношений соседства происходит следующим образом:
I) Изначальное состояние BGP-соседства – IDLE. Ничего не происходит.

BGP находится в соcтоянии IDLE, если нет маршрута к BGP-соседу.
II) Для обеспечения надёжности BGP использует TCP.
Это означает, что теоретически BGP-пиры могут быть подключены не напрямую, а, например, так.
Но в случае подключения к провайдеру, как правило, берётся всё же прямое подключение, таким образом маршрут до соседа всегда есть, как подключенный непосредственно.
BGP-маршрутизатор (их также называют BGP-спикерами/speaker или BGP-ораторами) слушает и посылает пакеты на 179-й TCP порт.
Когда слушает – это состояние CONNECT. В таком состоянии BGP находится очень недолго.
Когда отправил и ожидает ответа от соседа – это состояние ACTIVE.

R1 отправляет TCP SYN на порт 179 соседа, инициируя TCP-сессию.
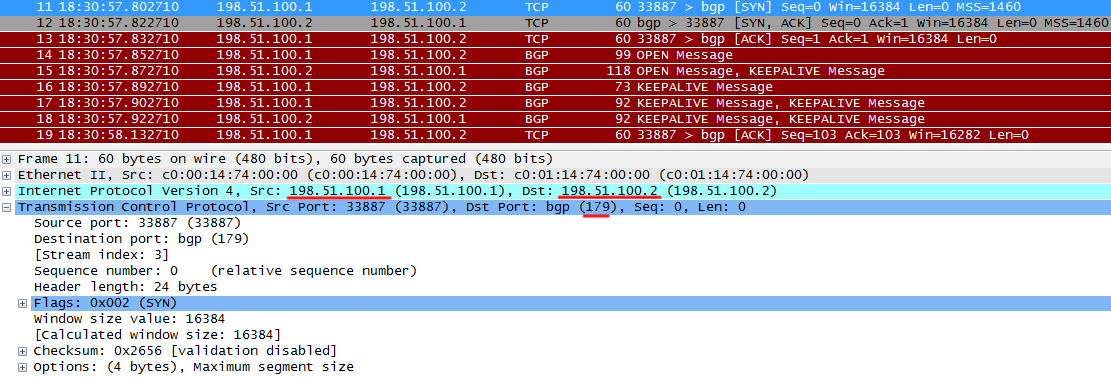
R2 возвращает TCP ACK, мол, всё получил, согласен и свой TCP SYN.

R1 тоже отчитывается, что получил SYN от R2.
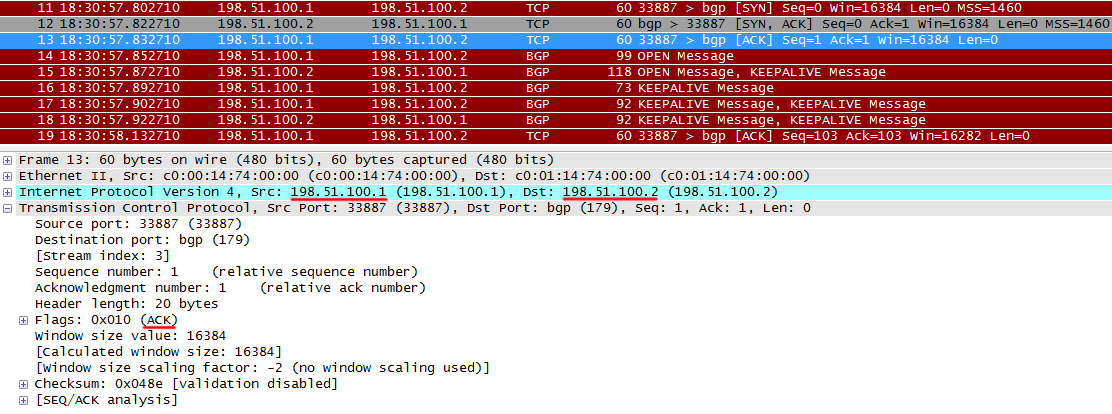
После этого TCP-сессия установлена.
- нет IP-связности с R2
- BGP не запущен на R2
- порт 179 закрыт ACL
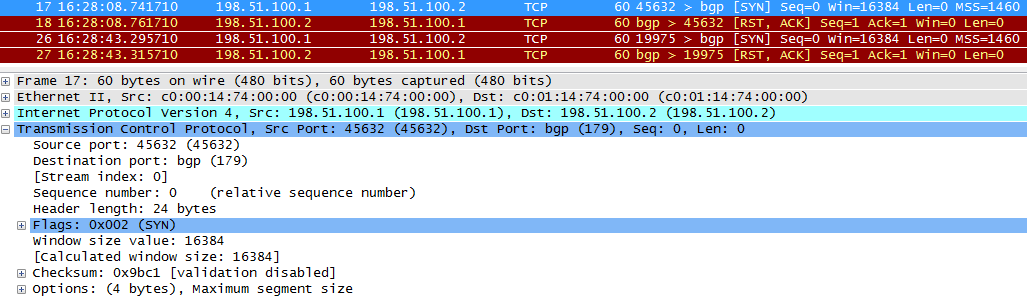
На R2 не запущен BGP, и R2 возвращает ACK, что получен SYN от R1 и RST, означающий, что нужно сбросить подключение.

Периодически R1 будет пытаться снова установить TCP-сессию.
III) После того, как TCP-сессия установлена, BGP-ораторы начинают обмен сообщениями OPEN.
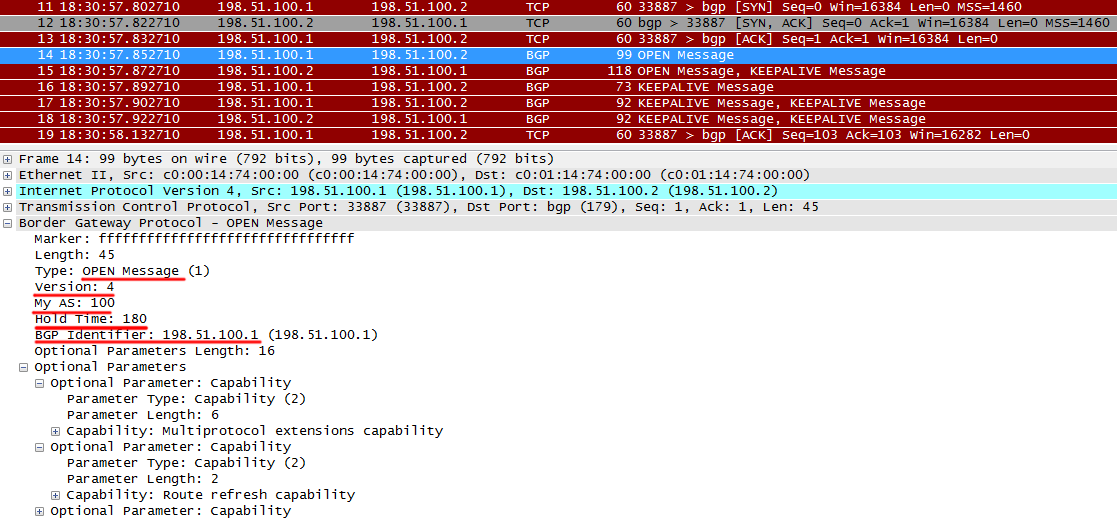
- Версии протокола должна быть одинаковой. Маловероятно, что это будет иначе
- Номера AS в сообщении OPEN должны совпадать с настройками на удалённой стороне
- Router ID должны различаться
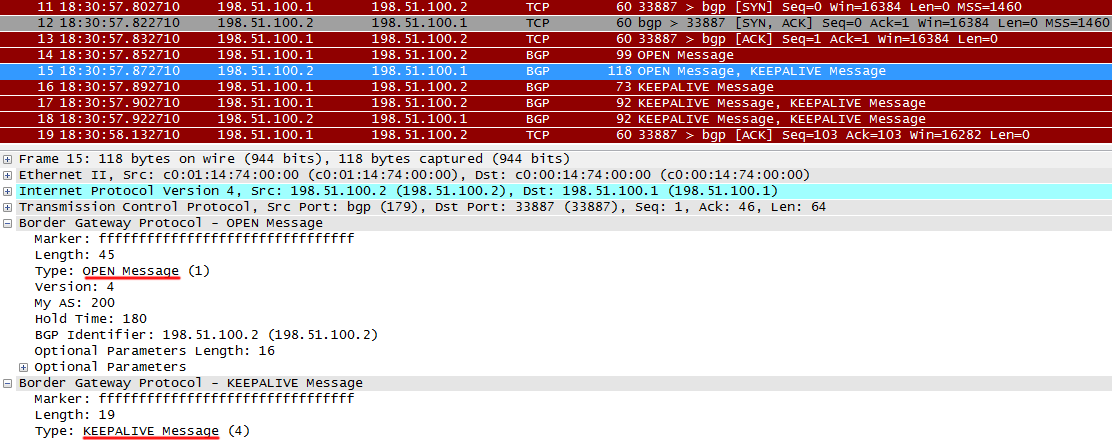
Получив OPEN от R1, R2 отправляет свой OPEN, а также KEEPALIVE, говорящий о том, что OPEN от R1 получен – это сигнал для R1 переходить к следующему состоянию – Established.
Вот примеры неконсистентности параметров:
а) некорректная AS (На R2 настроена AS 300, тогда, как на R1 считается, что данный сосед находится в AS 200):
R2 отправляет обычный OPEN
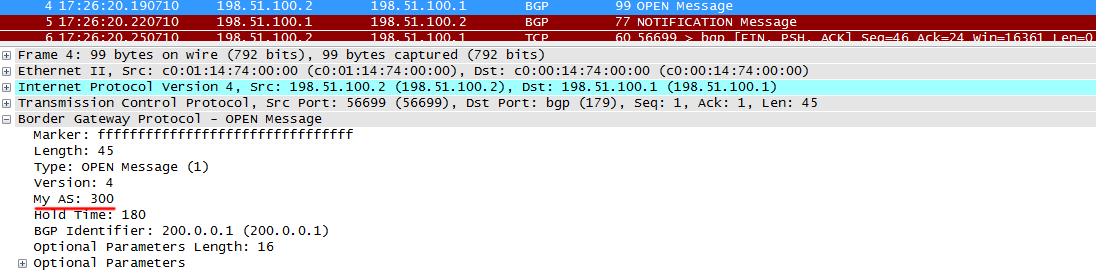
R1 замечает, что AS в сообщении не совпадает с настроенным, и сбрасывает сессиию, отправляя сообщение NOTIFICATION. Они отправляются в случае каких-либо проблем, чтобы разорвать сессию.
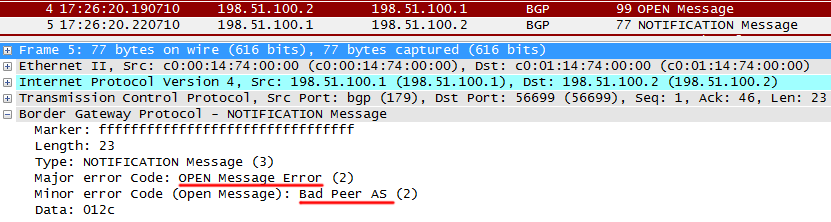
При этом в консоли R1 появляются следующие сообщения:

 б) одинаковый Router ID
б) одинаковый Router ID
R2 отправляет в OPEN Router ID, который совпадает с ID R1:
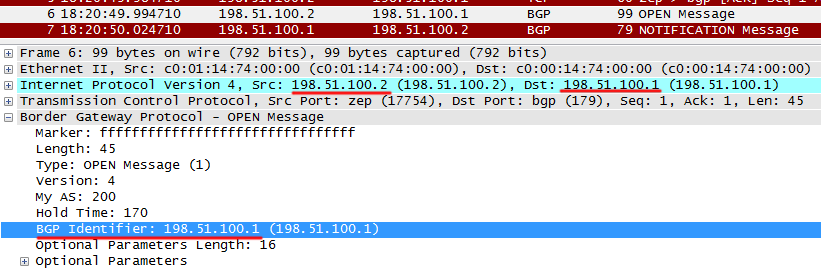
R1 возвращает NOTIFICATION, мол, опух?!

При этом в консоли будут следующего плана сообщения:


После таких ошибок BGP переходит сначала в IDLE, а потом в ACTIVE, пытаясь заново установить TCP-сессию и затем снова обменяться сообщениями OPEN, вдруг, что-то изменилось?
Когда сообщение Open отправлено – это состояние OPEN SENT.
Когда оно получено – это сотояние OPEN CONFIRM.
Если Hold Timer различается, то выбран будет наименьший. Поскольку Keepalive Timer не передаётся в сообщении OPEN, он будет рассчитан автоматически (Hold Timer/3). То есть Keepalive может различаться на соседях
Вот пример: на R2 настроены таймеры так: Keepalive 30, Hold 170.

R2 отправляет эти параметры в сообщении OPEN. R1 получает его и сравнивает: полученное значение – 170, своё 180. Выбираем меньшее – 170 и вычисляем Keepalive таймер:

Это означает, что R2 свои Keepalive’ы будет рассылать каждые 30 секунд, а R1 – 56. Но главное, что Hold Timer у них одинаковый, и никто из них раньше времени не разорвёт сессию.
Увидеть состояние OPENSENT или OPENCONFIRM практически невозможно – BGP на них не задерживается.
IV) После всех этих шагов они переходят в стабильное состояние ESTABLISHED.
Это означает, что запущена правильная версия BGP и все настройки консистентны.
Для каждого соседа можно посмотреть Uptime – как долго он находится в состоянии ESTABLISHED.
 V) В первые мгновения после установки BGP-сессии в таблице BGP только информация о локальных маршрутах.
V) В первые мгновения после установки BGP-сессии в таблице BGP только информация о локальных маршрутах.

Можно переходить к обмену маршрутной информацией.
Для это используются сообщения UPDATE

Разберём их поподробнее.
R1 передаёт маршрутную информацию на R2.
Первый плюсик в сообщении UPDATE – это атрибуты пути. Мы их подробно рассмотрим позже, но вам уже должны быть поняты два из них. AS_PATH означает, что маршрут пришёл из AS с номером 100.
NEXT_HOP – что логично, информация для R2, что указывать в качестве шлюза для данного маршрута. Теоретически здесь может быть не обязательно адрес R1.
- IGP – задан вручную командой network или получен по BGP .
- EGP – этот код вы никогда не встретите, означает, что маршрут получен из устаревшего протокола, который так и назывался – “EGP”, и был полностью повсеместно заменен BGP
- Incomplete – чаще всего означает, что маршрут получен через редистрибьюцию
Второй плюсик – это собственно информация о маршрутах – NLRI – Network Layer Reachability Information. Собственно, наша сеть 100.0.0.0/23 тут и указана.
Ну и UPDATE от R2 к R1. 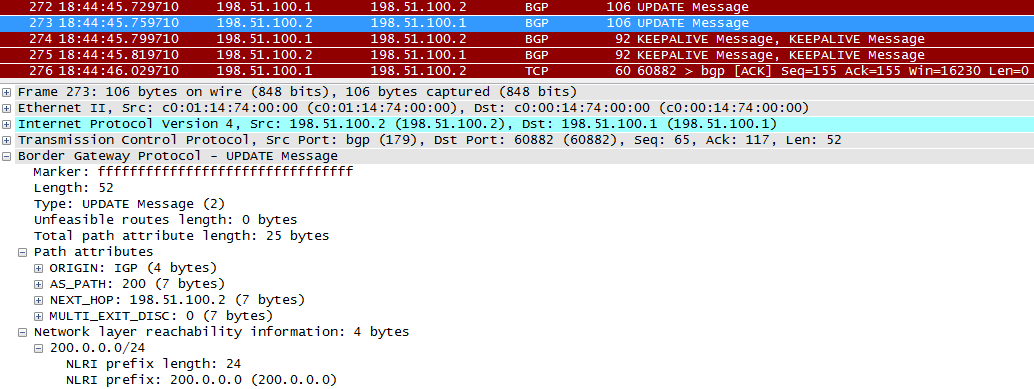
Нижеидущие KEEPALIVIE – это своеобразные подтверждения, что информация получена.
Информация о сетях появилась теперь в таблице BGP:

И в таблице маршрутизации:

UPDATE передаются при каждом изменении в сети до тех пор пока длится BGP-сессия. Заметьте, никаких синхронизаций таблиц маршрутизации нет, в отличии от какого-нибудь OSPF. Это было бы технически глупо – полная таблица маршрутов BGP весит несколько десятков мегабайтов на каждом соседе.
VI) Теперь, когда всё хорошо, каждый BGP-маршрутизатор регулярно будет рассылать сообщения KEEPALIVE. Как и в любом другом протоколе это означает: «Я всё ещё жив». Это происходит с истечением таймера Keepalive – по умолчанию 60 секунд.
Ещё один тип сообщений BGP – ROUTE REFRESH – позволяет запросить у своих соседей все маршруты заново без рестарта BGP процесса.
Подробнее обо всех типах сообщений BGP.
Полная FSM (конечный автомат) для BGP выглядит так:
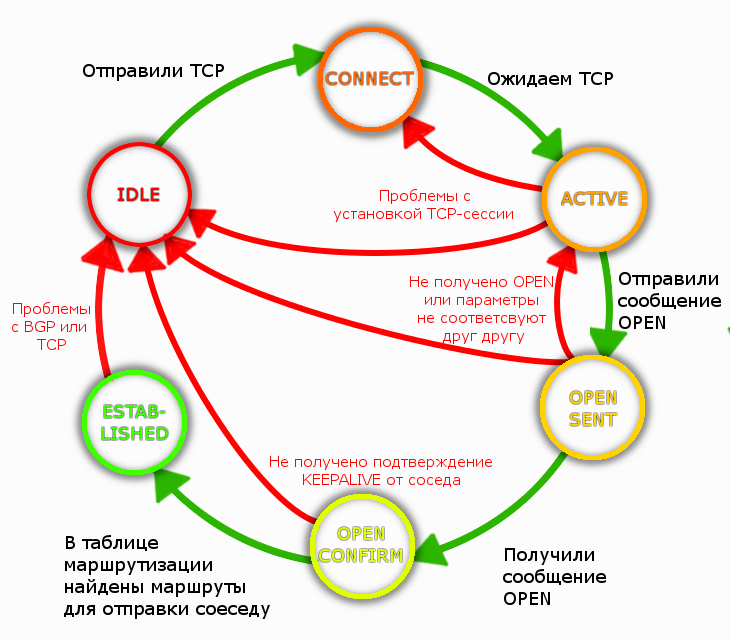 Нашёл в сети подробное описание каждого шага.
Нашёл в сети подробное описание каждого шага.
Вопрос на засыпку: Предположим, что Uptime BGP-сессии 24 часа. Какие сообщения гарантировано не передавались между соседями последние 12 часов?
Теперь расширим наш кругозор до вот такой сети:
Картинки без подсетей 
И посмотрим, что из себя представляет таблица маршрутов BGP на маршрутизаторе R1:

Как видите, маршрут представляет из себя вовсе не только NextHop или просто список устройств до нужной подсети. Это список AS. Иначе он называется AS-Path.
То есть, чтобы попасть в сеть 123.0.0.0/24 мы должны отправить пакет наружу, преодолеть AS 200 и AS 300.
AS-path формируется следующим образом:
а) пока маршрут гуляет внутри AS, список пустой. Все маршрутизаторы понимают, что полученный маршрут из этой же AS
б) Как только маршрутизатор анонсирует маршрут своему внешнему соседу, он добавляет в список AS-path номер своей AS. 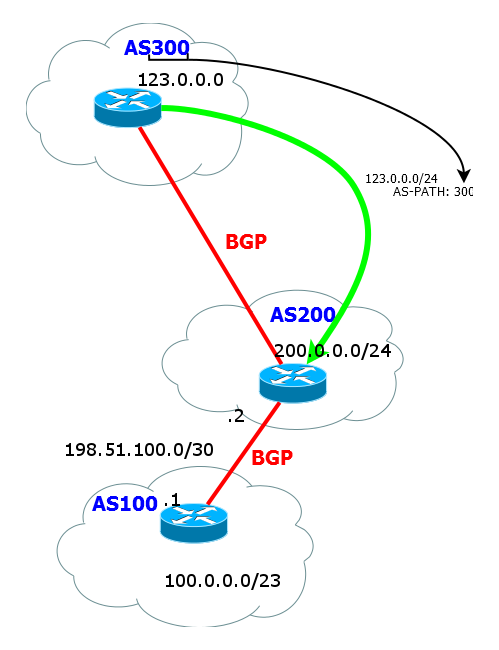
в) внутри соседской AS, список не меняется и содержит только номер изначальной AS
г) когда из соседской AS маршрут передаётся дальше в начало списка добавляется номер текущей AS.
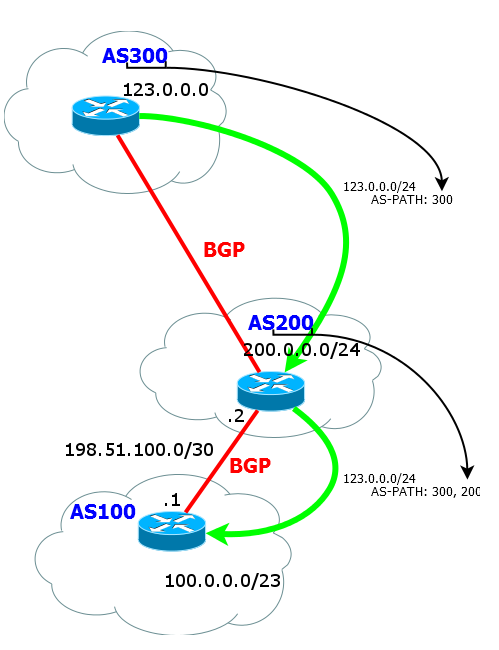
И так далее. При передаче маршрута внешнему соседу номер AS всегда добавляется в начало списка AS-path. То есть фактически это стек.
AS-path нужен не просто для того, чтобы маршрутизатор R1 знал путь до конечной сети – ведь по сути Next Hop достаточно – каждый маршрутизатор решение по-прежнему принимает на основе таблицы маршрутизации. На самом деле тут преследуются две более важные цели:
1) Предотвращение петель маршрутизации. В AS-Path не должно быть повторяющихся номеров
2) Выбор наилучшего маршрута. Чем короче AS-Path, тем предпочтительнее маршрут, но об этом позже
Настройка BGP и практика
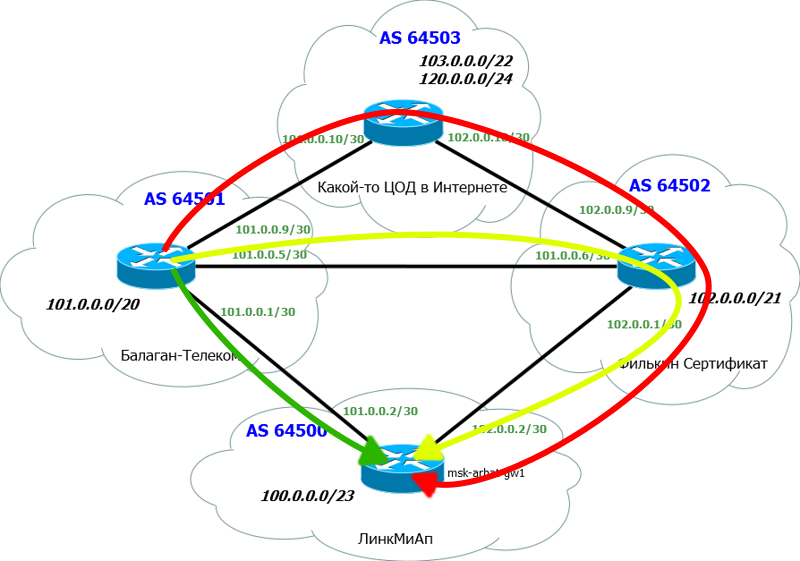
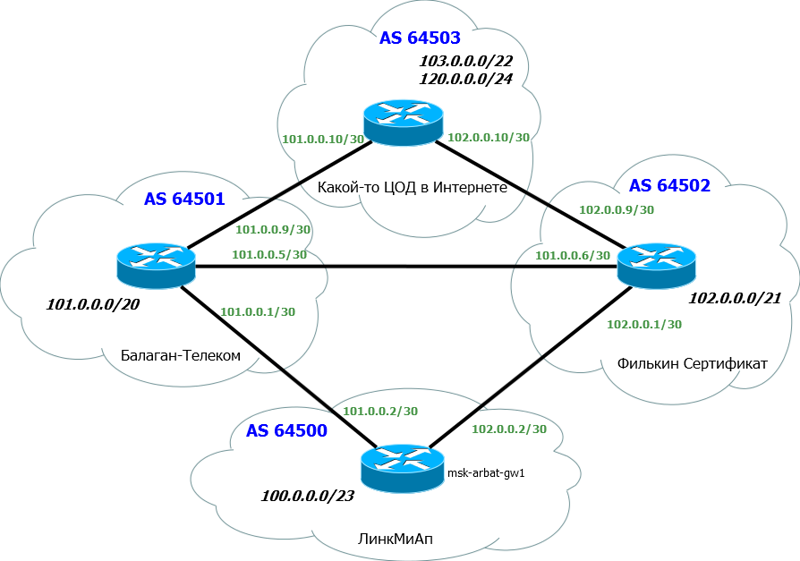
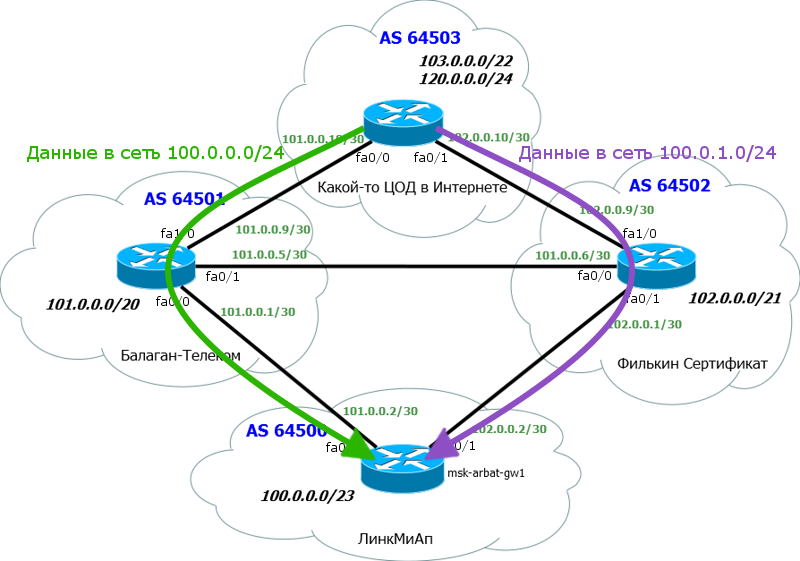
В этом выпуске мы смешаем теорию с практикой, потому что так будет проще всего понять. Собственно сейчас обратимся к нашей сети ЛинкМиАп.
Как обычно, отрезаем всё лишнее и добавляем необходимое: 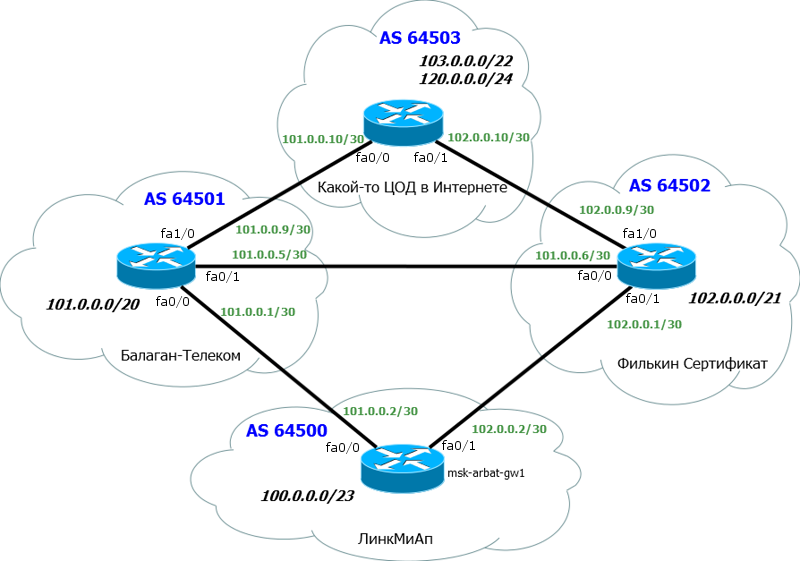
Внизу наш главный маршрутизатор msk-arbat-gw1. Для упрощения настройки и понимания, мы отрешимся от всех старых настроек и освободим интерфейсы.
Выше два наших старых провайдера – Балаган Телеком и Филькин Сертификат.
Разумеется, у каждого провайдера здесь своя AS. Мы добавили ещё одну тупиковую AS – до неё и будем проверять, пусть, это например, ЦОД в Интернете.
Для простоты полагаем, что каждая AS представлена только одним маршрутизатором, никаких ACL, никаких промежуточных устройств.
Мы поднимаем BGP-сессию с обоими провайдерами.
Нам важна следующая информация:
1) Номер нашей AS и блок IP-адресов. Их мы уже получили: AS64500 и блок: 100.0.0.0/23.
2) Номер AS «Балаган Телеком» и линковая подсеть с ним. AS64501 и линковая сеть: 101.0.0.0/30.
3) Номер AS «Филькин Сертификат» и линковая подсеть с ним. AS64502 и линковая сеть: 102.0.0.0/30.
При подключении по BGP в качестве линковых адресов используются обычно публичные с маской подсети /30 и выдаёт их нам вышестоящий провайдер.
Делается это по той простой причине, чтобы ваш трафик везде следовал по публичным адресам и в трассировке посередине не появлялись всякие 10.Х.Х.Х. Не то, чтобы это что-то запрещённое, но обычно-таки придерживаются этого правила.
Начнём с банального.
Настройка интерфейсов: 

Теперь назначим какой-нибудь адрес на интерфейс Loopback, чтобы потом проверить связность:
Черёд BGP. Тут заострим внимание на каждой строчке.
Сначала мы запускаем BGP процесс и указываем номер AS. Именно тот номер, который выдал LIR. Это вам не OSPF – вольности недопустимы.
Теперь поднимаем пиринг.
Командой neighbor мы указываем, с кем устанавливать сессию. Именно на адрес 101.0.0.1 маршрутизатор будет отсылать сначала TCP-SYN, а потом OPEN. Также мы обязаны указать номер удалённой Автономной Системы – 64501.
Конфигурация с обратной стороны симметрична:
Уже по одному сообщению
можно судить, что BGP поднялся, но давайте проверим его состояние:
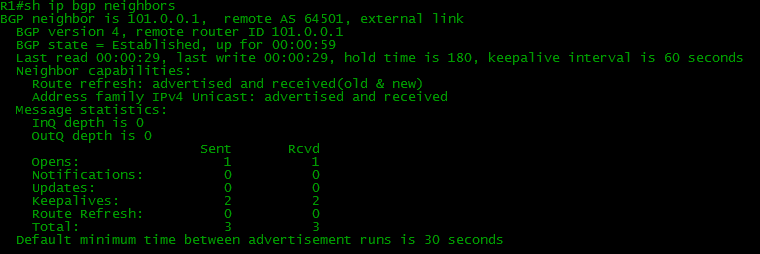
Вот они пробежали по всем состояниям и сейчас их статус Established.
Получал и отправлял наш маршрутизатор по одному OPEN и успел за это время отослать и принять уже 2 KEEPALIVE.
Командой sh ip bgp можно посмотреть какие сети известны BGP:
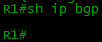
Пусто. Надо указать, что есть у нас вот эта сеточка 100.0.0.0/23 и передать её провайдерам?
Для этого существует три варианта:
– определить сети командой network
– импортировать из другого источника (direct, static, IGP)
– создать аггрегированный маршрут командой aggregate-address
Забегая вперёд, заметим, что network имеет больший приоритет, а с импортированием нужно быть аккуратнее, чтобы не хватануть лишку.
Смотрим появилась ли наша сеть в таблице:
Странно, но нет, ничего не появилось. На R2 тоже.
А дело тут в том, что в ту сеть, которую вы прописали командой network должен быть точный маршрут, иначе она не будет добавлена в таблицу BGP – это обязательное условие. Конечно, такого маршрута нет. Откуда ему взяться:

Поскольку реально у нас некуда прописывать такой маршрут – кроме одного Loopback-интерфейса, нигде этой сети нет, мы можем поступить следующим образом:
Данный маршрут говорит о том, что все пакеты в эту подсеть будут отброшены. Но, не пугайтесь, нормальная работа не будет нарушена. Если у вас есть более точные маршруты (с маской больше /23, например, /24, /30, /32), то они будут предпочтительнее согласно правилу Longest Prefix Match.
И теперь в таблице BGP есть наш локальный маршрут:

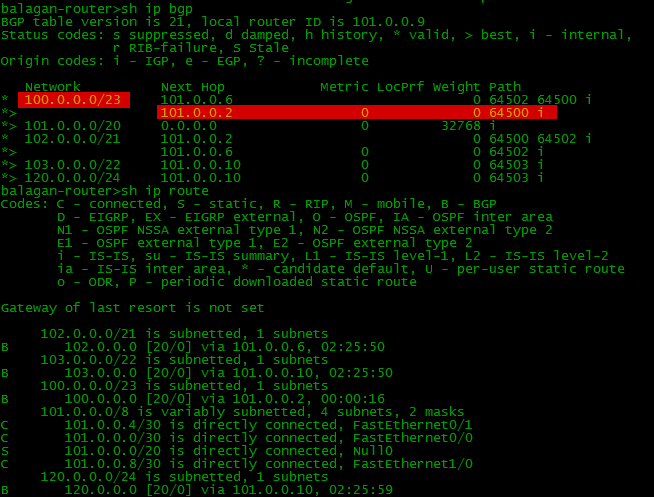
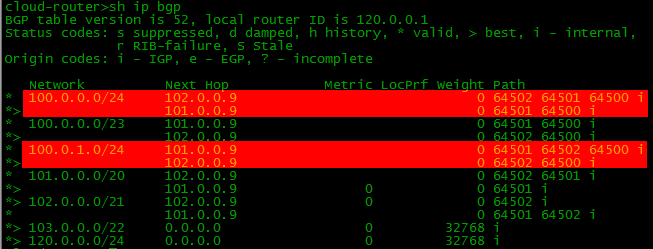
Если настроить BGP и нужные маршруты на всех устройствах нашей схемы, то таблицы BGP и маршрутизации на нашем бордере (border – маршрутизатор на границе сети) будут выглядеть так:
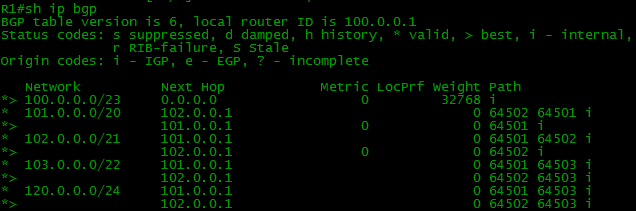

Обратите внимание, что в таблице BGP по 2 маршрута к некоторым сетям, а в таблице маршрутизации только один. Маршрутизатор выбирает лучший из всех и только его переносит в таблицу маршрутизации. Об этом поговорим позже.
Это необходимый минимум, после которого уже будет маленькое счастье.

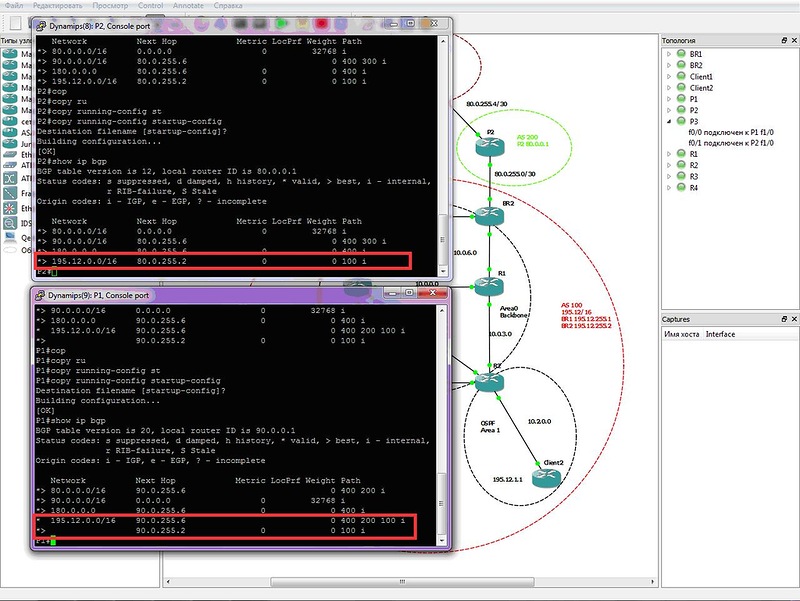
Условие:
Настройки маршрутизаторов несущественны. Никаких фильтров маршрутов не настроено. Почему на одном из соседей отсутствует альтернативный маршрут в сеть 195.12.0.0/16 через AS400?
Full View и Default Route
Говоря о BGP и подключении к провайдерам, нельзя не затронуть эту тему. Когда ЛинкМиАп, имея уже AS и PI-адреса, будет делать стык с Балаган-Телекомом, одним из первых вопросов от них будет: “Фул вью или Дефолт?”. Тут главное не растеряться и не сморозить чепуху.
То, что вы видели до сих пор – это так называемый Full View – маршрутизатор изучает абсолютно все маршруты Интернета, пусть даже в нашем случае это пять-шесть штук. В реальности их сейчас больше 400 000. Соответственно от одного провайдера вы получите 400k маршрутов, от второго столько же. Подчас бывает и третий резервный – плюс ещё 400k. Итого больше миллиона.
Ну не покупать же теперь маленькому недоинтерпрайзу циску старших серий только для этого?
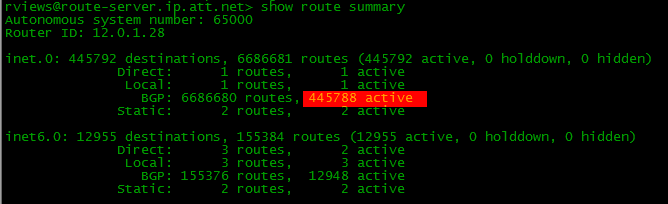 * вывод таблицы маршрутизации с одного из публичных серверов (дуступен по telnet route-server.ip.att.net)
* вывод таблицы маршрутизации с одного из публичных серверов (дуступен по telnet route-server.ip.att.net)
На самом деле, далеко не каждому, кто имеет AS, нужен Full View. Обычно для таких компаний, как наша вполне достаточно Default Route, по названиям вполне понятно, чем они отличаются. В последнем случае от каждого провайдера приходит только один маршрут по умолчанию, вместо сотен тысяч специфических (хотя вообще-то может и вместе).
-
Full View. Вы обладаетe полным чистейшим знанием о структуре Интернета. До любого адреса в Интернете вы можете просмотреть путь от себя:
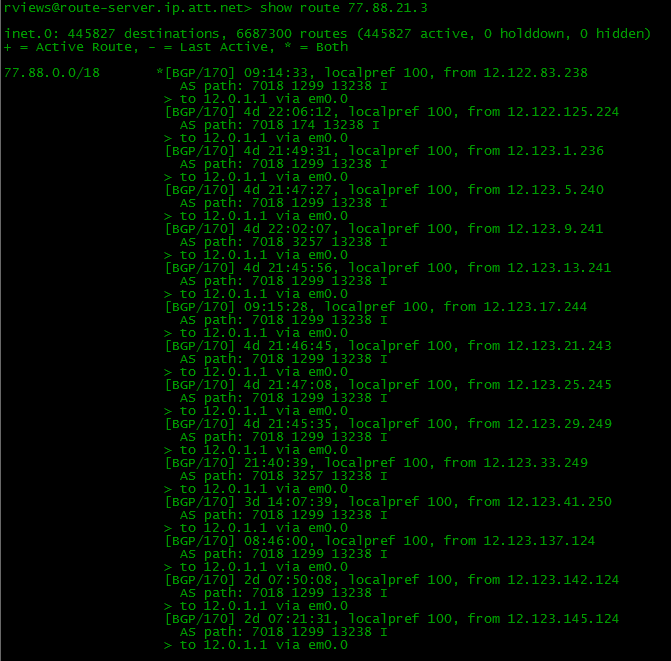
Вы знаете, какие к нему ведут AS. Через сайт RIPE можно посмотреть какие провайдеры обеспечивают транзит. Вы следите за всеми изменениями. Если вдруг у кого-то что-то упадёт через первый линк (даже не у вас или у провайдера, а где-то там, дальше), BGP это отследит и перестроит свою таблицу маршрутизации для передачи данных через второго провайдера.
При этом вы очень гибко можете управлять маршрутами, вмешиваясь в стандартную процедуру выбора наилучшего пути.
Например, весь трафик на яндекс вы будете пускать через Балаган Телеком, а на гугл через Филькин Сертификат. Это называется распределением нагрузки.
Достигается это путём настройки, например, приоритетов маршрутов для определённых префиксов.
В общем, очень грубый совет прозвучит так:
Если вы не собираетесь организовывать через себя транзит (подключать клиентов со своими АС) и нет нужды в тонком распределении исходящего трафика, то вам хватит Default Route.
Но уж точно нет смысла принимать от одного провайдера Full View, а от другого Default – в этом случае один линк будет всегда простаивать на исходящий трафик, потому что маршрутизатор будет выбирать более специфический путь.
При этом от всех провайдеров вы можете брать Default плюс определённые префиксы (например, именно этого провайдера). Таким образом до нужных ресурсов у вас будут специфические маршруты без Full View.
Вот пример настройки передачи Default Route нижестоящему маршрутизатору:
И вот как после этого выглядит таблица маршрутов на нашем бордере:
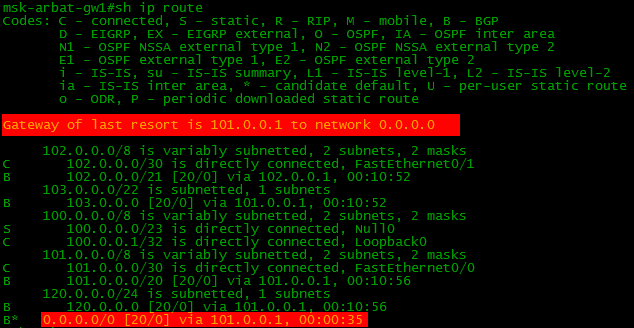
То есть помимо обычных маршрутов (Full View) передаётся ещё маршрут по умолчанию.
Схема: Общая схема сети
Задание:
Настроить фильтрацию со стороны провайдера таким образом, чтобы он передавал нам только маршрут по умолчанию и ничего лишнего.
То есть, чтобы таблица BGP выглядела так: 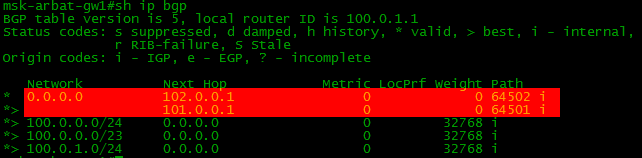
Looking Glass и другие инструменты
Одним из очень мощных инструментов работы с BGP – Looking Glass. Это сервера, расположенные в Интернете, которые позволяют взглянуть на сеть извне: проверить доступность, просмотреть через какие AS лежит путь в вашу автономную систему, запустить трассировку до своих внутренних адресов.
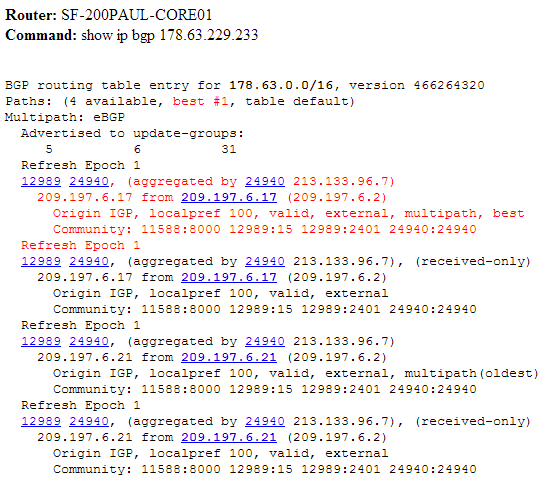

Это как если бы вы попросили кого-то: “слушай, а посмотри, как там мои анонсы видятся?”, только просить никого не нужно.
Существуют также специальные организации, которые отслеживают анонсы BGP в Интернете и, если вдруг происходит что-то неожиданное, может уведомить владельца сети – BGPMon, Renesys, RouterViews.
Благодаря им было предотвращено несколько глобальных аварий.
С помощью сервиса BGPlay можно визуализировать информацию о распространении маршрутов.
На nag.ru можно почитать о самых ярких случаях, когда некорректные анонсы BGP вызывали глобальные проблемы в Интернете, таких как ”AS 7007 Incident” и “Google’s May 2005 Outage”.
Очень хорошая статья по разнообразным прекраснейшим инструментам для работы с BGP.
Список серверов Looking Glass.
Control Plane и Data Plane
Перед тем, как окунуться в глубокий омут управления маршрутами, сделаем последнее лирическое отступление. Надо разобраться с понятиями в заголовке главы.
В своё время, читая MPLS Enabled Application, я сломал свой мозг на них. Просто никак не мог сообразить, о чём авторы ведут речь.
Итак, дабы не было конфузов у вас.
Это не уровни модели, не уровни среды или моменты передачи данных – это весьма абстрактное деление.
Управляющий уровень (Control Plane) – работа служебных протоколов, обеспечивающих условия для передачи данных.
Например, когда запускается BGP, он пробегает все свои состояния, обменивается маршрутной информацией итд.
Или в MPLS-сети LDP распределяет метки на префиксы.
Или STP, обмениваясь BPDU, строит L2-топологию.
Всё это примеры процессов Control Plane. То есть это подготовка сети к передаче – организация коммутации, наполнение таблицы маршрутизации.
Передающий уровень (Data Plane) – собственно передача полезных данных клиентов.
Часто случается так, что данные двух уровней ходят в разных направлениях, “навстречу друг другу”. Так в BGP маршруты передаются из AS100 в AS200 для того, чтобы AS200 могла передать данные в AS100.
Более того, на разных уровнях могут быть разные парадигмы работы. Например, в MPLS Data Plane ориентирован на создание соединения, то есть данные там передаются по заранее определённому пути – LSP.
А вот сам этот путь подготавливается по стандартным законам IP – от хоста к хосту.
Важно понять назначение уровней и в чём разница.
Для BGP это принципиальный вопрос. Когда вы анонсируете свои маршруты, фактически вы создаёте путь для входящего трафика. То есть маршруты исходят от вас, а трафик к вам.
Выбор маршрута
Ситуация с маршрутами у нас такая.
Есть BGP-таблица, в которой хранятся абсолютно все маршруты, полученные от соседей.
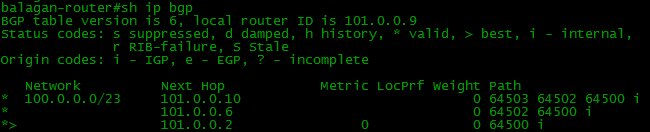 То есть если есть у нас несколько маршрутов, до сети 100.0.0.0/23, то все они будут в BGP-таблице, независимо от “плохости” оных:
То есть если есть у нас несколько маршрутов, до сети 100.0.0.0/23, то все они будут в BGP-таблице, независимо от “плохости” оных:
А есть знакомая нам таблица маршрутизации, хранящая только лучшие из лучших. Точно также BGP анонсирует не все приходящие маршруты, а только лучшие. То есть от одного соседа вы никогда не получите два маршрута в одну сеть.
- Максимальное значение Weight (локально для маршрутизатора, только для Cisco)
- Максимальное значение Local Preference (для всей AS)
- Предпочесть локальный маршрут маршрутизатора (next hop = 0.0.0.0)
- Кратчайший путь через автономные системы. (самый короткий AS_PATH)
- Минимальное значение Origin Code (IGP
- Минимальное значение MED (распространяется между автономными системами)
- Путь eBGP лучше чем путь iBGP
- Выбрать путь через ближайшего IGP-соседа
Если это условие выполнено, то происходит балансировка нагрузки между несколькими равнозначными линками
Как видите, очень много критериев выбора. Причём они довольно сложные и с ходу их все понять непросто. Втягивайтесь потихоньку.
О некоторых упомянутых атрибутах мы поговорим ниже, а конкретно на выборе маршрутов остановимся в отдельной статье.
Схема: Общая схема сети
Условие: Full View на всех маршрутизаторах
Если вы сейчас посмотрите таблицу BGP на маршрутизаторе провайдера Балаган Телеком, то увидите 3 маршрута в сеть 102.0.0.0/21 – сеть Филькина Сертификата. И один из маршрутов ведёт через нашу сети ЛинкМиАп.

Это говорит о том, что наш бордер анонсирует чужие маршруты дальше, иными словами наша AS является транзитной.
Задание:
Настроить фильтрацию таким образом, чтобы наша AS64500 перестала быть транзитной.
Управление маршрутами
Прежде чем переходить к большой теме распределения нагрузки с помощью BGP просто необходимо разобраться с тем, каким образом мы вообще можем управлять маршрутами в этом протоколе.
Именно возможность такого управления обменом маршрутной информации делает BGP таким гибким и подходящим для взаимодействия нескольких различных провайдеров, в отличии от любого IGP.
- AS-Path ACL
- Prefix-list
- Weight
- Local Preference
- MED
Но только первые два из них позволяют фильтровать анонсируемые или принимаемые маршруты, остальные лишь устанавливают приоритеты.
AS-Path ACL
Весьма мощный, но не самый популярный механизм.
С помощью AS-Path ACL вы можете, например, запретить принимать анонсы маршрутов, принадлежащих AS 200. Ну вот просто не хотите – пусть они через другого провайдера будут известны, а через этого нет.
Самое сложное в таком подходе – запомнить все регулярные выражения и научиться их использовать. Сначала голова от них кругом:
| Знак | Значение |
|---|---|
| . | любой символ, включая пробел |
| * | ноль или больше совпадений с выражением |
| + | одно или больше совпадений с выражением |
| ? | ноль или одно совпадение с выражением |
| ^ | начало строки |
| $ | конец строки |
| _ | любой разделитель (включая, начало, конец, пробел) |
| \ | не воспринимать следующий символ как специальный |
| [ ] | совпадение с одним из символов в диапазоне |
| | | логическое или |
Чтобы было чуть более понятно, приведём несколько примеров:
1
| _200_ | Маршруты проходящие через AS 200 |
До и после номера AS идут знаки “_”, означающие, что в AS-path номер 200 может стоять в начале, середине или конце, главное, чтобы он был.
2
| ^200$ | Маршруты из соседней AS 200 |
“^” означает начало списка, а “$” – конец. То есть в AS-path всего лишь один номер AS – это означает, что маршрут был зарождён в AS 200 и оттуда сразу был передан нам.
3
| _200$ | Маршруты отправленные из AS 200 |
“$” означает конец списка, то есть это самая первая AS, из неё маршрут и зародился, знак “_” говорит о том, что неважно, что находится дальше, хоть ничего, хоть 7 других AS.
4
| ^200_ | Сети находящиеся за AS 200 |
Знак “^” означает, что ASN 200 была добавлена последней, то есть маршрут к нам пришёл из AS 200, но это не значит, что родился он в ней же – знак “_” говорит о том, что это может быть конец списка, а может пробел перед следующей AS.
5
| ^$ | Маршруты локальной AS |
Список AS-path пуст, значит маршрут локальный, сгенерированный внутри нашей AS.
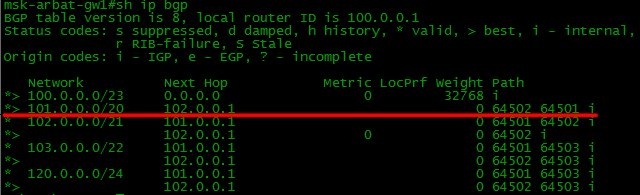
Пример
Вот в нашей сети отфильтруем маршруты, которые зародились в AS 64501. То есть мы будем от соседа 101.0.0.1 получать все интернетовские маршруты, но не будем получать их локальные.
 Конфигурация устройств.
Конфигурация устройств.
Prefix-list
Тут всё просто и логично. Ну почти.
Префикс-листы – это просто привычные нам сеть/маска, и мы указываем разрешить такие маршруты или нет.
Синтаксис команды:
list-name – название списка. Ваш КО. Обычно указывается, как name_in или name_out. Это подсказывает нам на входящие или исходящие маршруты будет действовать (но, конечно, на данном этапе никак не определяет).
seq – порядковый номер правила (как в ACL), чтобы проще было оперировать с ними.
deny/permit – определяем разрешать такой маршрут или нет
network/length – привычная для нас запись, вроде, 192.168.14.0/24.
А вот дальше, внимание, сложнее – возможны ещё два параметра: ge и le. Как и при настройке NAT (или в ЯП Фортран), это означает «greater or equal» и «less or equal».
То есть вы можете задать не только один конкретный префикс, но и их диапазон.
Например, такая запись
будет означать, что будут выбраны следующие маршруты.
10.0.0.0/10, 10.0.0.0/11, 10.0.0.0/12, 10.0.0.0/13, 10.0.0.0/14, 10.0.0.0/15, 10.0.0.0/16
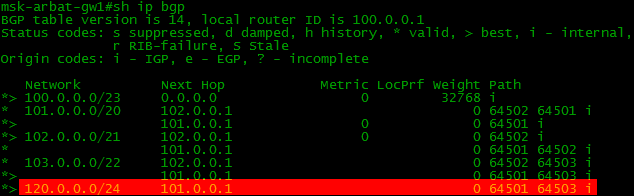
Пример
Сейчас мы запретим принимать анонс сети 120.0.0.0/24 через провайдер Филькин Сертификат, а все остальные разрешим. Запись 0.0.0.0/0 le 32 означает любые подсети с любой длиной маски (меньшей или равной 32 (0-32)).
Route Map
До сих пор все правила применялись безусловно – на все анонсы от пира или пиру.
С помощью карт маршрутов (у других вендоров они могут называться политиками маршрутизации) мы можем очень гибко применять правила, дифференцируя анонсы.
Синтаксис команды следующий:
map_name – имя карты
permit/deny – разрешаем или нет прохождение данных, подпадающих под условия route-map
seq – номер правила в route-map
match – условие подпадания трафика под данное правило.
expression:
| Критерий | Команда конфигурации |
|---|---|
| Network/mask | match ip address prefix-list |
| AS-path | match as-path |
| BGP community | match community |
| Route originator | match ip route-source |
| BGP next-hop address | match ip next-hop |
set – что сделать с отфильтрованными маршрутами
expression:
| Параметры | Команда конфигурации |
|---|---|
| AS path prepend | set as-path prepend |
| Weight | set weight |
| Local Preference | set local-preference |
| BGP community | set community |
| MED | set metric |
| Origin | set origin |
| BGP next-hop | set next-hop |
Пример применения
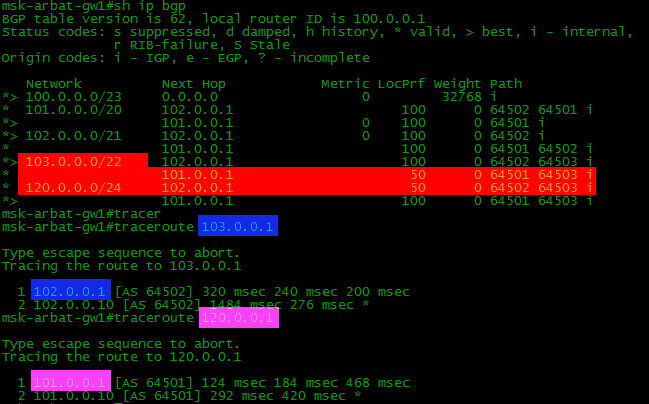
Укажем, что в подсеть 120.0.0.0/24 предпочтительно ходить через Филькин Сертификат, а в 103.0.0.0/22 через Балаган Телеком. Для этого воспользуемся атрибутом Local Preference. Чем выше значение этого параметра, тем выше приоритет маршрута.
Сначала мы создали обычным образом prefix-list, которым выделили подсеть 120.0.0.0/24. Permit означает, что на этот префикс в будущем будут действовать правила route-map. Как и в обычных ACL далее идёт неявное правило deny для всего остального. В данном случае оно означает, что под действие route-map подпадёт только 120.0.0.0/24 и ничего другого.
В созданной карте маршрутов BGP1_IN мы разрешили прохождение маршрутной информации (permit), подпадающей под созданный prefix-list (match ip address prefix-list TEST1_IN).
Для этих анонсов установим local preference в 50 – ниже, чем стандартные 100 (set local-preferеnce 50). То есть они будут менее «интересными».
И в конечном итоге привяжем карту к конкретному BGP-соседу (neighbor 102.0.0.1 route-map BGP1_IN in).
Что же получается в результате?
 Конфигурация устройств
Конфигурация устройств
Другие примеры рассмотрим в следующем разделе.
Схема: Общая схема сети
Условие: ЛинкМиАп получает Full View от обоих провайдеров.
Тема: Поиск неисправностей.
От провайдеров: полная таблица маршрутов BGP
На маршрутизаторе msk-arbat-gw1 настроено распределение исходящего трафика между провайдерами Балаган Телеком и Филькин Сертификат. Трафик идущий в сети провайдера Филькин Сертификат, должен идти через него, если он доступен. Остальной исходящий трафик, должен передаваться через провайдера Балаган Телеком, когда он доступен.
При проверке исходящего трафика, оказалось, что при отключении Балаган Телеком, исходящий трафик к ЦОД (103.0.0.1) не идет через Филькин Сертификат.
В остальном конфигурация стандартная.
Задание:
Исправить настройки так, чтобы исходящий трафик в сети провайдера ISP2, к его клиенту и в сеть удаленного офиса компании, шел через провайдера ISP2.
Балансировка и распределение нагрузки
“А какие вы знаете способы балансировки трафика в BGP?”
Это вопрос, который любят задавать на собеседованиях.
Начиная готовиться к этой статьей, я имел разговор с нашей Наташей, из которого стало понятно, что в BGP балансировка и распределение – это две большие разницы.
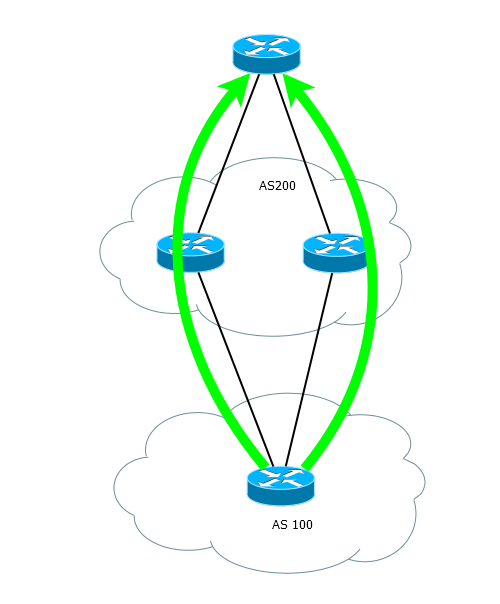
Балансировка нагрузки
Под балансировкой обычно понимается распределение между несколькими линками трафика, направленного в одну сеть.
Включается она просто
- Не менее двух маршрутов в таблице BGP для этой сети.
- Оба маршрута идут через одного провайдера
- Параметры Weight, Local Preference, AS-Path, Origin, MED, метрика IGP совпадают.
- Параметр Next Hop должен быть разным для двух маршрутов.
Последнее условие обходится скрытой командой
В этом случае умаляется также условие полного совпадения AS-path, но длина должна быть по-прежнему одинаковой.
Как мы можем проверить это на нашей сети? Нам ведь нужно убедиться, что балансировка работает.
Балансировка обычно осуществляется на базе потоков (IP-адрес/порт отправителя и IP-адрес/порт получателя), чтобы пакеты приходили в правильном порядке. Поэтому нам нужно создать два потока.
Нет ничего проще:
1) ping непосредственно с msk-arbat-gw1 на 103.0.0.1
2) подключаемся телнетом на msk-arbat-gw1 (не забыв настроить параметры) с любого другого маршрутизатора и запускаем пинг с указанием источника (чтобы потоки чем-то отличались друг от друга)
После этого один пинг пойдёт через один линк, а второй через другой. Проверено
По умолчанию никак не учитывается пропускная способность внешних каналов. Такая возможность однако реализована и запускается командами
Схема: Общая схема сети
Условие: ЛинкМиАп получает от обоих провайдеров маршрут по умолчанию.
Задание:
Настроить балансировку исходящего трафика между маршрутами по умолчанию от провайдеров Балаган Телеком и Филькин Сертификат в пропорции 3 к 1.
Распределение нагрузки
Совсем другая песня с распределением – это более тонкая настройка путей исходящего и входящего трафика.
Исходящий
Исходящий трафик направляется в соответствии с маршрутами, полученными свыше.
Соответственно ими и надо управлять.
Напомним схему нашей сети
Итак, есть следующие способы:
1) Настройка Weight. Это цисковский внутренний параметр – никуда не передаётся – работает в пределах маршрутизатора. У других вендоров тоже часто бывают аналоги (например, PreVal у Huawei). Тут ничего специфического – не будем даже останавливаться. (по умолчанию – 0)
Применение ко всем маршрутам полученным от соседа:
Применение через route-map: 
2) Local Preference. Это параметр стандартный. По умолчанию 100 для всех маршрутов. Если вы хотите трафик на определённые подсети направлять в определённые линки, то Local Preference незаменим.
Выше мы уже рассматривали пример использования данного параметра.
3) Вышеуказанная балансировка командой maximum-paths
Схема: Общая схема сети
Условие: ЛинкМиАп получает Full View от обоих провайдеров.
Задание:
Не используя атрибуты weight, local preference или фильтрацию, настроить маршрутизатор msk-arbat-gw1 так, чтобы для исходящего трафика Балаган Телеком был основным, а Филькин Сертификат резервным.
Входящий
Тут всё сложно.
Дело в том, что даже у крупных провайдеров исходящий трафик незначителен в сравнении со входящим. И там так остро не замечается неровное распределение.
Зато если речь идёт о Центрах Обработки Данных или хостинг-провайдерах, то ситуация обратная и вопрос балансировки стоит очень остро.
Тут мы крайне стеснены в средствах:
1) AS-Path Prepend
Один из самых частых приёмов – “ухудшение” пути. Нередко бывает так, что через одного провайдера ваши маршруты будут переданы с длиной AS-path больше, чем через другого. Разумеется, BGP выбирает первого, безапелляционно, и только через него будет передавать трафик. Чтобы выровнять ситуацию при анонсировании маршрутов можно добавить лишний “хоп” в AS-Path.
А бывает такая ситуация, что один провайдер предоставляет более широкий канал за небольшие деньги, но при этом путь через него длиннее и весь трафик уходит в другой – дорогой и узкий. Нам эта ситуация невыгодна и мы бы хотели, чтобы узкий канал стал резервным.
Вот её и разберём. Но придётся взять совершенно вырожденную ситуацию. К примеру, доступ из Балаган Телекома к сети ЛикМиАп.
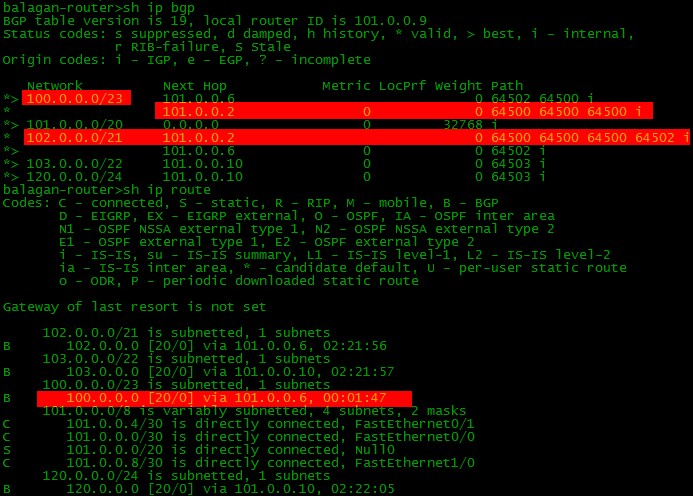
Вот так выглядит таблица BGP и маршрутизации на провайдере Балаган Телеком в обычной ситуации:
Если мы хотим ухудшить основной путь (прямой линк между ними), то нужно добавить AS в список AS-Path:
Тогда выглядеть картинка будет так
Разумеется, выбирается путь с меньшей длиной AS-Path, то есть через Филькин Сертификат (AS6502)
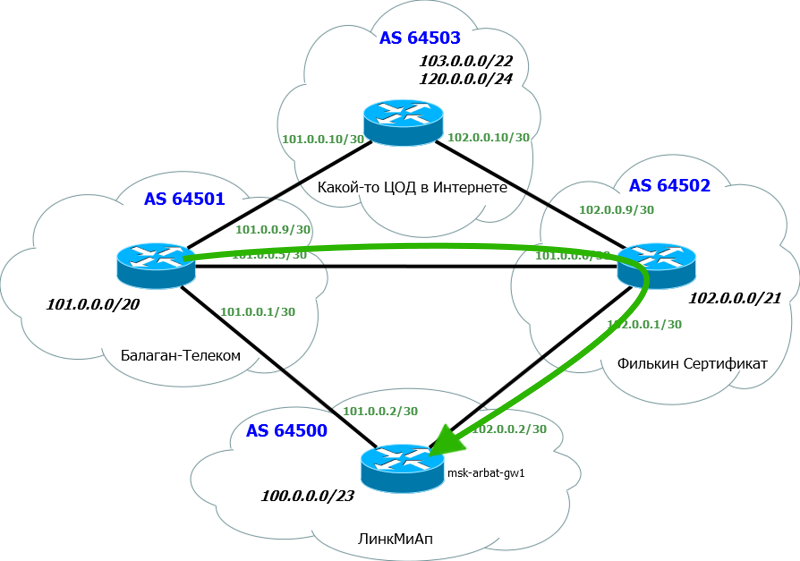
Этот маршрут и добавится в таблицу маршрутизации.
Заметим, что обычно в AS-Path добавляют именно свой номер AS. Можно, конечно, и чужую, но вас не поймут в приличном обществе.
Таким образом мы добились того, что трафик пойдёт намеченным нами путём.
Естественно, при падении одного из каналов трафик переключится на второй, независимо от настроенных AS-Path Prepend’ов.
2) MED
Multiexit Discriminator. В cisco он называется метрикой (Inter-AS метрика). MED является слабым атрибутом. Слабым, потому что он проверяется лишь на шестом шаге при выборе маршрута и оказывает по сути слабое влияние.
Если Local Preference влияет на выбор пути выхода трафика из Автономной системы, то MED передаётся в соседние AS и таким образом влияет на пути входа трафика.
Вообще MED и Local Preference часто путают новички, поэтому опишем в табличке разницу
| Local Preference | MED |
|---|---|
| Определяет приоритет пути для выхода трафика | Определяет приоритет пути для входа трафика |
| Действует только внутри AS. Никак не передаётся в другие AS | Передаётся в другие AS и намекает через какой путь передавать трафик предпочтительнее |
| Может работать при подключении к разным AS | Работает только при нескольких подключениях к одной AS |
| Чем больше значение, тем выше приоритет | Чем больше значение, тем ниже приоритет |
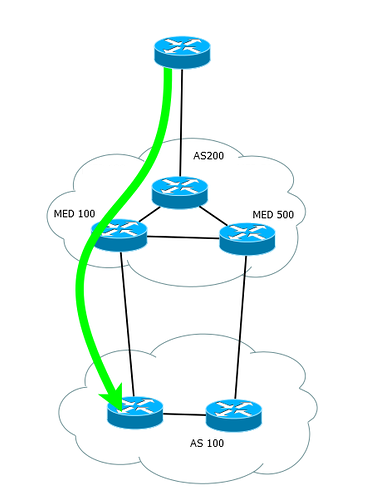
Не будем на нём останавливаться, потому что используют его редко, да и наша сеть для этого не подходит – должно быть несколько соединений между двумя AS, а у нас только по одному в каждую.
3) Анонс разных префиксов через разных ISP
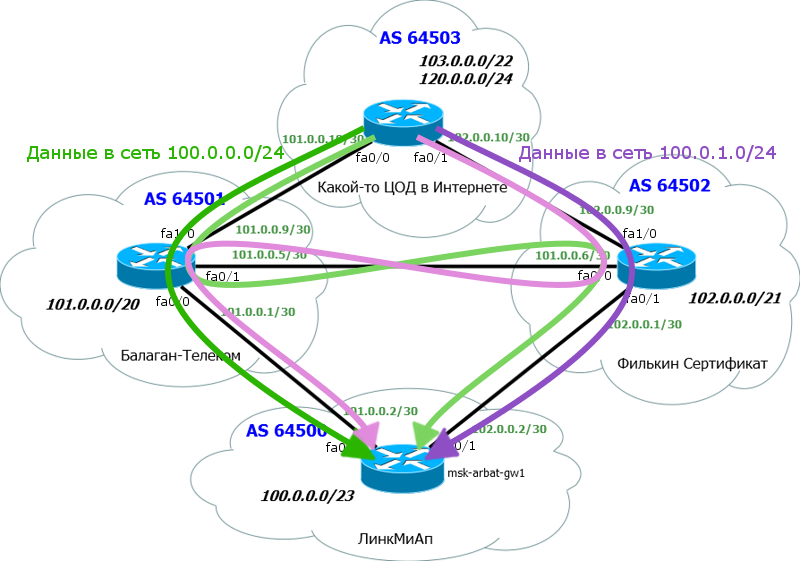
Ещё один способ распределить нагрузку – раздавать разные сети разным провайдерам.
Сейчас в сети ЦОДа наши анонсы выглядят так:

То есть наша сеть 100.0.0.0/23 известна через два пути, но в таблицу маршрутизации добавится только один. Соответственно и весь трафик назад пойдёт одним – лучшим путём.
Но!
Мы можем разделить её на две подсети /24 и одну отдавать в Балаган Телеком, а другую в Филькин Сертификат.
Соответственно ЦОД будет знать про эти подсети через разные пути:
Настраивается это так.
Во-первых, мы прописываем все свои подсети – все 3: одну большую /23 и две маленькие /24:
Для того, чтобы они могли быть анонсированы, нужно создать маршруты до этих подсетей.
А теперь создаём префикс-листы, которые разрешают каждый только одну подсеть /24 и общую /23.
Осталось привязать префикс-листы к соседям.
Привязываем мы их на OUT – на исходящий, потому что речь о маршрутах, которые мы отправляем вовне.
Итак, соседу 101.0.0.1 (Балаган Телеком) мы будем анонсировать сети 100.0.0.0/24 и 100.0.0.0/23.
А соседу 102.0.0.1 (Филькин Сертификат) – сети 100.0.1.0/24 и 100.0.0.0/23.
Результат будет таким:
Вроде бы, неправильно, потому что у нас по два маршрута в каждую сеть /24 – через Балаган Телеком и через Филькин Сертификат.
Но если приглядеться, то вы увидите, что согласно AS-Path у нас такие маршруты:
То есть, по сути всё правильно. Да и в таблицу маршрутизации всё помещается правильно:
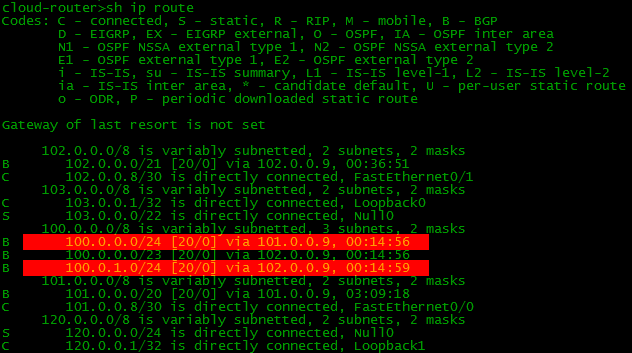
Теперь осталось ответить на вопрос какого лешего мы тащили за собой большую подсеть /23? Ведь согласно правилу Longest prefix match более точные маршруты предпочтительней, то есть /23, как бы и не нужен, когда есть /24.
Но вообразим себе ситуацию, когда падает сеть Балаган Телеком. Что при этом произойдёт? Подсеть 100.0.0.0/24 перестанет быть известной в интернете – ведь только Балаган Телеком что-то знал о ней благодаря нашей настройке. Соответственно, ляжет и часть нашей сети. Но! Нас спасает более общий маршрут 100.0.0.0/23. Филькин Сертификат знает о нём и анонсирует его в Интернет. Соответственно, хоть ЦОД и не знает про сеть 100.0.0.0/24, он знает про 100.0.0.0/23 и пустит трафик в сторону Филькина Сертификата.

То есть, слава Лейбницу, мы застрахованы от такой ситуации.
4) BGP Community
C помощью BGP Community можно давать провайдеру указания, что делать с префиксом, кому передавать, кому нет, какой local preference у себя ставить и т.д. Рассматривать этот вариант сейчас не будем, потому что тему коммьюнити мы перенесём в следующий выпуск.
Схема: Общая схема сети
Условие: На маршрутизаторе msk-arbat-gw1 настроено управление входящим и исходящим трафиком. Основной провайдер Балаган Телеком, резервый – Филькин Сертификат. При проверке настроек оказалось, что исходящий трафик передается правильно. При проверке входящего трафика, оказалось, что входящий трафик идет и через провайдера Балаган Телеком, но когда отключается Балаган Телеком, входящий трафик не идет через Филькин Сертификат.
Задание: Исправить настройки.
Наташа Самойленко — автор xgu.ru подготовила для нас презентацию.
http://www.slideshare.net/NatashaSamoylenko/linkmeup-bgpipslaВы можете её качать и использовать, как пожелаете с указанием авторства.
Все технологии маршрутизации, которые мы применяли до этого момента в наших статьях, будь то статическая маршрутизация, динамическая маршрутизация (IGP или EGP), в своей работе принимали во внимание только один признак пакета: адрес назначения. Все они, упрощенно, действовали по одному принципу: смотрели, куда идет пакет, находили в таблице маршрутизации наиболее специфичный маршрут до пункта назначения (longest match), и переправляли пакет в тот интерфейс, который был записан в таблице напротив этого самого маршрута. В этом, в общем-то, и состоит суть маршрутизации. А что, если такой порядок вещей нас не устраивает? Что, если мы хотим маршрутизировать пакет, отталкиваясь от адреса источника? Или нам нужно мальчики HTTP направо, девочки SNMP налево?
- Адрес источника (или комбинация адрес источника-адрес получателя)
- Информация 7 уровня (приложений) OSI
- Интерфейс, в который пришел пакет
- QoS-метки
- Вообще говоря, любая информация, используемая в extended-ACL (порт источника\получателя, протокол и прочее, в любых комбинациях). Т.е. если мы можем выделить интересующий нас трафик с помощью расширенного ACL, мы сможем его смаршрутизировать, как нам будет угодно.
- Все нужно писать руками, отсюда много работы и риск ошибки
- Производительность. На большинстве железок PBR работает медленнее, чем обычный роутинг (исключение составляют каталисты 6500, к ним есть супервайзер с железной поддержкой PBR)
- Выделение нужного трафика. Осуществляется либо с помощью ACL, либо в зависимости от интерфейса, в который трафик пришел. За это отвечает команда match в режиме конфигурации route map
- Применение действия к этому трафику. За это отвечает команда set
Имеем вот такую топологию:
В данный момент трафик R1-R5 и обратно идет по маршруту R1-R2-R4-R5, для удобства, адреса присвоены так, чтобы последняя цифра адреса была номером маршрутизатора:
Для примера, предположим, что нам нужно, чтобы обратно трафик от R5 (с его адресом в источнике) шел по маршруту R5-R4-R3-R1. По схеме очевидно, что решение об этом должен принимать R4. На нем сначала создаем ACL, который отбирает нужные нам пакеты:
Затем создаем политику маршрутизации с именем “BACK”:
Внутри нее говорим, какой трафик нас интересует:
И что с ним делать:
После чего заходим на интерфейс, который смотрит в сторону R5 (PBR работает с входящим трафиком!) и применяем на нем полученную политику:
Работает! А теперь посмотрим внимательно на схему и подумаем: все ли хорошо?
А вот и нет!
Следуя данному ACL, у нас заворачивается на R3 весь трафик с источником R5. А это значит, что если, например, R5 захочет попасть на R2, он, вместо короткого и очевидного маршрута R5-R4-R2, будет послан по маршруту R5-R4-R3-R1-R2. Поэтому, нужно очень аккуратно и вдумчиво составлять ACL для PBR, делая его максимально специфичным.
- set ip next-hop
- set interface
- set ip default next-hop
- set default interface
Условие: ЛинкМиАп использует статические маршруты к провайдерам (не BGP).
Схема и конфигурация. Маршрутизаторы провайдеров также не используют BGP.
Задание: Настроить переключение между провайдерами.
Маршрут по умолчанию к Балаган Телеком должен использоваться до тех пор, пока приходят icmp-ответы на пинг google (103.0.0.10) ИЛИ yandex (103.0.0.20). Запросы должны отправляться через Балаган Телеком. Если ни один из указанных ресурсов не отвечает, маршрут по умолчанию должен переключиться на провайдера Филькин Сертификат. Для того чтобы переключение не происходило из-за временной потери отдельных icmp-ответов, необходимо установить задержку переключения, как минимум, 5 секунд.
IP SLA
А теперь самое вкусное: представим, что в нашей схеме основной путь R4-R2-R1 обслуживает один провайдер, а запасной R4-R3-R1 – другой. Иногда у первого провайдера бывают проблемы с нагрузкой, которые приводят к тому, что наш голосовой трафик начинает страдать. При этом, другой маршрут ненагружен и хорошо бы в этот момент перенести голос на него. Ок, пишем роут-мап, как мы делали выше, который выделяет голосовой трафик и направляем его через нормально работающего провайдера. А тут – оп, ситуация поменялась на противоположную – опять надо менять все обратно. Будни техподдержки: “И такая дребедень целый день: то тюлень позвонит, то олень”. А вот бы было круто, если можно было бы отслеживать нужные нам характеристики основного канала (например, задержку или джиттер), и в, зависимости от их значения, автоматически направлять голос или видео по основному или резервному каналу, да? Так вот, чудеса бывают. В нашем случае чудо называется IP SLA.
Эта технология, по сути, есть активный мониторинг сети, т.е. генерирование некоего трафика с целью оценить ту или иную характеристику сети. Но мониторингом все не заканчивается – роутер может, используя полученные данные, влиять на принятие решений по маршрутизации, таким образом реагируя и разрешая проблему. К примеру, разгружать занятой канал, распределяя нагрузку по другим.
Без лишних слов, сразу к настройке. Для начала, нам нужно сказать, что мы хотим мониторить. Создаем объект мониторинга, назначаем ему номер:
Так-с, что мы тут можем мониторить?
Как видите, список внушительный, поэтому останавливаться не будем, для интересующихся есть подробная статья на циско.ком.
Условие: ЛинкМиАп использует статические маршруты к провайдерам (не BGP).
Схема и конфигурация. Маршрутизаторы провайдеров также не используют BGP.
Задание:
Настроить маршрутизацию таким образом, чтобы HTTP-трафик из локальной сети 10.0.1.0 шел через Балаган Телеком, а весь трафик из сети 10.0.2.0 через Филькин Сертификат. Если в адресе отправителя фигурирует любой другой адрес, трафик должен быть отброшен, а не маршрутизироваться по стандартной таблице маршрутизации (задание надо выполнить не используя фильтрацию с помощью ACL, примененных на интерфейсе).
Дополнительное условие: Правила PBR должны работать так только если соответствующий провайдер доступен (в данной задаче достаточно проверки доступности ближайшего устройства провайдера). Иначе должна использоваться стандартная таблица маршрутизации.
Обычно, работу IP SLA рассматривают на простейшем примере icmp-echo. То есть, в случае, если мы можем пинговать тот конец линии, трафик идет по ней, если не можем – по другой. Но мы пойдем путем чуть посложнее. Итак, нас интересуют характеристики канала, важные для голосового трафика, например, джиттер. Конкретнее, udp-jitter, поэтому пишем
В этой команде после указания вида проверки (udp-jitter) идет ip адрес, куда будут отсылаться пробы (т.е. меряем от нас до 192.168.200.1 – это лупбек на R1) и порт (от балды 55555). Затем можно настроить частоту проверок (по умолчанию 60 секунд):
и предельное значение, при превышении которого объект ip sla 1 рапортует о недоступности:
Некоторые виды измерений в IP SLA требуют наличия “на той стороне” так называемого “ответчика” (responder), некоторые (например, FTP, HTTP, DHCP, DNS) нет. Наш udp-jitter требует, поэтому, прежде чем запускать измерения, нужно подготовить R1:
Теперь нам нужно запустить сбор статистики. Командуем
Т.е. запускаем объект мониторинга 1 прямо сейчас и до конца дней.
Round Trip Time (RTT) for Index 1
Latest RTT: 36 milliseconds
Latest operation start time: *00:39:01.531 UTC Fri Mar 1 2002
Latest operation return code: OK
RTT Values:
Number Of RTT: 10 RTT Min/Avg/Max: 19/36/52 milliseconds
Latency one-way time:
Number of Latency one-way Samples: 0
Source to Destination Latency one way Min/Avg/Max: 0/0/0 milliseconds
Destination to Source Latency one way Min/Avg/Max: 0/0/0 milliseconds
Jitter Time:
Number of SD Jitter Samples: 9
Number of DS Jitter Samples: 9
Source to Destination Jitter Min/Avg/Max: 0/5/20 milliseconds
Destination to Source Jitter Min/Avg/Max: 0/16/28 milliseconds
Packet Loss Values:
Loss Source to Destination: 0 Loss Destination to Source: 0
Out Of Sequence: 0 Tail Drop: 0
Packet Late Arrival: 0 Packet Skipped: 0
Voice Score Values:
Calculated Planning Impairment Factor (ICPIF): 0
Mean Opinion Score (MOS): 0
Number of successes: 12
Number of failures: 0
Operation time to live: Forever
Теперь настраиваем так называемый track (неправильный, но понятный перевод “отслеживатель”). Именно к его состоянию привязываются впоследствии действия в роут-мапе. В track можно выставить задержку переключения между состояниями, что позволяет решить проблему, когда у нас по одной неудачной пробе меняется маршрутизация, а по следующей, уже удачной, меняется обратно. Указываем номер track и к какому номеру объекта ip sla мы его подключаем (rtr 1):
Это означает: если объект мониторинга упал и не поднялся в течение 15 секунд, переводим track в состояние down. Если объект был в состоянии down, но поднялся и находится в поднятом состоянии хотя бы 10 секунд, переводим track в состояние up.
Следующим действием нам нужно привязать track к нашей роут-мапе. Напомню, стандартный путь от R5 к R1 идет через R2, но у нас имеется роут-мапа BACK, переназначающая стандартное положение вещей в случае, если источник R5:
Если мы привяжем наш мониторинг к этой мапе, заменив команду set ip next-hop 192.168.3.3 на set ip next-hop verify-availability 192.168.3.3 10 track 1, получим обратный нужному эффект: в случае падения трека (из-за превышения показателя джиттера в sla 1), мапа не будет отрабатываться (все будет идти согласно таблице маршрутизации), и наоборот, в случае нормальных значений, трек будет up, и трафик будет идти через R3.
Как это работает: роутер видит, что пакет подпадает под условия match, но потом не сразу делает set, как в предыдущем примере с PBR, а промежуточным действием проверяет сначала состояние трека 1, а затем, если он поднят (up), уже делается set, если нет – переходит к следующей строчке роут-мапы.
Для того, чтобы наша мапа заработала, как надо, нам нужно как-то инвертировать значение трека, т.е. когда джиттер большой, наш трек должен быть UP, и наоборот. В этом нам поможет такая штука, как track list. В IP SLA существует возможность объединять в треке список других треков (которые, по сути, выдают на выходе 1 или 0) и производить над ними логические операции OR или AND, а результатом этих операций будет состояние этого трека. Кроме этого, мы можем применить логическое отрицание к состоянию трека. Создаем трек-лист:
Единственным в этом “списке” будет логическое отрицание значения трека 1:
Теперь привязываем роут-мап к этому треку
Цифра 10 после адреса некстхопа – это его порядковый номер (sequence number). Мы можем, к примеру, использовать его так:
Тут такая логика: выбираем трафик, подпадающий под ACL 100, затем идет промежуточная проверка track 1, если он up, ставим пакету некстхоп 192.168.3.3, если down, переходим к следующему порядковому номеру (20 в данном случае), опять же промежуточно проверяем состояние трека (уже другого, 2), в зависимости от результата, ставим некстхоп 192.168.2.2 или отправляем с миром (маршрутизироваться на общих основаниях).
Давайте теперь немножко словами порассуждаем, что же мы такое накрутили: итак, измерения джиттера у нас идут от источника R4 к респондеру R1 по маршруту через R2. Максимальное допустимое значение джиттера на этом маршруте у нас – 10. В случае, если джиттер превышает это значение и держится на этом уровне 15 секунд, мы переключаем трафик, генерируемый R5, на маршрут через R3. Если джиттер падает ниже 10 и держится там минимум 10 секунд, пускаем трафик от R5 по стандартному маршруту. Попробуйте для закрепления материала найти, в каких командах задаются все эти значения.
Итак, мы достигли цели: теперь, в случае ухудшения качества основного канала (ну, по крайней мере, значений udp-джиттера), мы переходим на резервный. Но что, если и там тоже не очень? Может, попробуем с помощью IP SLA решить и эту проблему?
Попробуем выстроить логику того, что мы хотим сделать. Мы хотим перед переключением на резервный канал проверять, как у нас обстоит дело с джиттером на нем. Для этого нам нужно завести дополнительный объект мониторинга, который будет считать джиттер на пути R4-R3-R1, пусть это будет 2. Сделаем его аналогичным первому, с теми же значениями. Условием переключения на резервный канал тогда будет: объект 1 down И объект 2 up. Чтобы измерять джиттер не по основному каналу, придется пойти на хитрость: сделать loopback-интерфейсы на R1 и R4, прописать статические маршруты через R3 туда-обратно, и использовать эти адреса для объекта SLA 2.
Теперь меняем условие трека 2, к которому привязана роут-мапа:
Вуаля, теперь трафик R5->R1 переключается на запасной маршрут только в том случае, если джиттер основного канала больше 10 и, в это же время, джиттер запасного меньше 10. В случае, если высокий джиттер наблюдается на обоих каналах, трафик идет по основному и молча страдает.
Состояние трека можно привязать также к статическому маршруту: например, мы можем командой ip route 0.0.0.0 0.0.0.0 192.168.1.1 track 1 сделать шлюзом по умолчанию 192.168.1.1, который будет связан с треком 1 (который, в свою очередь, может проверять наличие этого самого 192.168.1.1 в сети или измерять какие-нибудь важные характеристики качества связи с ним). В случае, если связанный трек падает, маршрут убирается из таблицы маршрутизации.
Также будет полезным упомянуть, что информацию, получаемую через IP SLA, можно вытащить через SNMP, чтобы потом можно было ее хранить и анализировать где-нибудь в вашей системе мониторинга. Можно даже настроить SNMP-traps.
Схема: как в других задачах по PBR. Конфигурация ниже.
Условие: ЛинкМиАп использует статические маршруты к провайдерам (не BGP).
На маршрутизаторе msk-arbat-gw1 настроена PBR: HTTP-трафик должен идти через провайдера Филькин Сертификат, а трафик из сети 10.0.2.0 должен идти через Балаган Телеком.
Указанный трафик передается правильно, но не маршрутизируется остальной трафик из локальной сети, который должен передаваться через провайдера Балаган Телеком.
Задание:
Исправить настройки таким образом, чтобы они соответствовали условиям.