Часть 1. Определение данных сети по IPv4-адресу
Умение работать с подсетями IPv4 и определять информацию о сетях и узлах на основе известного IP-адреса и маски подсети необходимо для понимания принципов работы IPv4-сетей. Цель первой части — закрепить знания о том, как рассчитывать IP-адрес сети на основе известного IP-адреса и маски подсети. Зная IP-адрес и маску подсети, вы всегда сможете установить следующие данные подсети:
• Общее количество битов узлов
• Количество узлов в подсети
Во второй части лабораторной работы вы определите следующие данные для указанного IP-адреса
и маски подсети:
• Сетевой адрес этой подсети
• Широковещательный адрес этой подсети
• Диапазон адресов узлов для этой подсети
• Количество созданных подсетей
• Количество узлов для каждой подсети
• 1 ПК (Windows 7, Vista или XP с выходом в Интернет)
• Дополнительно: калькулятор IPv4-адресов
Часть 1: Определение данных сети по IPv4-адресу
В части 1 вам необходимо определить сетевой и широковещательный адреса, а также количество узлов, зная IPv4-адрес и маску подсети.
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены.
В данном документе содержится общедоступная информация корпорации Cisco.
Лабораторная работа: расчёт подсетей IPv4
ОБЗОР . Чтобы определить сетевой адрес, выполните бинарную операциюи для IPv4-адреса, используя указанную маску подсети. В результате вы получите сетевой адрес. Совет: если маска подсети имеет в октете десятичное значение255, результатом ВСЕГДА будет исходное значение этого октета. Если маска подсети имеетв октете десятичное значение 0, результатом для этого октета ВСЕГДА будет 0.
Зная это, вы можете выполнить бинарную операцию И только для того октета, значение которого в маске подсети отличается от 255 или 0.
Проанализировав этот пример, вы увидите, что бинарная операция И требуется только для третьего октета. В этой маске подсети первые два октета дадут результат 172.30, а четвертый — 0.
Выполните бинарную операцию И для третьего октета.
Анализ этого примера снова даст следующий результат:
Рассчитать количество узлов для каждой сети в данном примере можно путём анализа маски подсети. Маска подсети будет представлена в десятичном формате с точкой-разделителем, например 255.255.192.0, или в формате сетевого префикса, например /18. IPv4-адрес всегда содержит 32 бита. Отняв количество битов, используемых сетевой частью (как показано в маске подсети), вы получите количество битов, используемых для узлов.
В нашем примере маска подсети 255.255.192.0 равна /18 в префиксной записи. Вычитание 18 бит сети из 32 бит даст нам 14 бит, оставшихся для узловой части. Исходя из этого, можно выполнить простой расчёт:
2 (количество битов узла) – 2 = количество узлов
2 14 = 16 384 – 2 = 16 382 узла
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены.
В данном документе содержится общедоступная информация корпорации Cisco.
Лабораторная работа: расчёт подсетей IPv4
Определите сетевые и широковещательные адреса и количество битов узлов для IPv4-адресов и префиксов, указанных в приведённой ниже таблице.
Часть 2: Расчёт данных сети по IPv4-адресу
Зная IPv4-адрес, а также исходную и новую маски подсети, можно определить следующие параметры:
• Сетевой адрес этой подсети
• Широковещательный адрес этой подсети
• Диапазон адресов узлов этой подсети
• Количество созданных подсетей
• Количество узлов в подсети
В приведённом ниже примере показана одна из задач и её решение.
Исходная маска подсети
Новая маска подсети
Количество битов подсети
Количество созданных подсетей
Количество битов узлов в подсети
Количество узлов в подсети
Сетевой адрес этой подсети
Адрес IPv4 первого узла в этой подсети
Адрес IPv4 последнего узла в этой
Широковещательный адрес IPv4 в этой
© Корпорация Cisco и/или её дочерние компании, 2014. Все права защищены.
В данном документе содержится общедоступная информация корпорации Cisco.
Лабораторная работа: расчёт подсетей IPv4
Давайте рассмотрим, как была получена такая таблица.
Исходная маска подсети имела вид 255.255.0.0 или /16. Новая маска подсети — 255.255.240.0 или /20. Полученная разница составляет 4 бита. Так как 4 бита были заимствованы, мы можем определить, что были созданы 16 подсетей, так как 2 4 = 16.
В новой маске, равной 255.255.240.0 или /20, остаётся 12 бит для узлов. Если для узлов осталось 12 бит, воспользуемся следующей формулой: 2 12 = 4096–2=4094 узла для каждой подсети.
Бинарная операция И поможет определить подсеть для этой задачи, в результате чего мы получим сеть 172.16.64.0.
В заключение необходимо установить первый узел, последний узел и широковещательный адрес для каждой подсети. Один из способов определения диапазона узлов — использовать двоичные значения для узловой части адреса. В нашем примере узловая часть — это последние 12 бит адреса. В первом узле для всех старших битов будет установлено значение 0, а для младшего бита — значение 1.
В последнем узле для всех старших битов будет установлено значение 1, а для младшего бита — значение 0. В этом примере узловая часть адреса находится в третьеми четвёртомоктетах.
Полезные советы для расчета сетевой IP адресации
 Очень часто при настройке сети дома или в офисе возникают вопросы, связанные с расчетом сетевой адресации: как разделить выделенную сеть на подсети, какого объема сети отвести для каждого отдела, какие адреса попадают в данную сеть, какая маска у этой сети.
Очень часто при настройке сети дома или в офисе возникают вопросы, связанные с расчетом сетевой адресации: как разделить выделенную сеть на подсети, какого объема сети отвести для каждого отдела, какие адреса попадают в данную сеть, какая маска у этой сети.
Быстрый расчет IP сетей
В сегодняшней статье мы постараемся отметить основные моменты для быстрого расчета IPv4 сетей. Хоть сейчас и идет постепенный переход на IPv6, все же IPv4 адресация еще долго будет в тренде и умение быстро рассчитывать IPv4 сети многим может пригодиться. Данная статья написана и оформлена совместно с моим коллегой и преподавателем сетевой академии CISCO — Кузьминым Евгением.
Все мы привыкли к отображению IP адреса в виде четырех десятичных чисел, разделенных точками (также их называют октетами, так как они формируются из 8 бит). Все мы знаем, что компьютер для расчетов использует двоичную систему счисления, поэтому для компьютера сетевой адрес, например 192.168.1.1, имеет вид:
11000000 10101000 00000001 00000001

Маска подсети в двоичном виде выглядит как последовательность единиц, а затем нулей и указывает на то, сколько первых битов IP-адреса будут относится к адресу сети (у всех компьютеров в одной сети они будут одинаковые), а остальные биты будут относится к адресу каждого узла (у всех компьютеров в одной сети они будут разные). Есть специальные адреса: адрес сети — адрес, у которого узловая часть состоит из одних нулей, и широковещательный адрес — это адрес, у которого узловая часть состоит из одних единиц. Например, маска вида 255.255.255.0 в двоичном виде выглядит:
11111111 11111111 111111111 00000000
и указывает на то, что первые 24 бита относятся к адресу сети, а последние восемь к адресу конкретного узла в этой сети. Маска сети также может быть записана, как просто число, указывающее количество первых битов, относящихся к адресу сети. В данном случае — 24.
Со стандартными маскам все легко, они имеют вид; 255.0.0.0, 255.255.0.0 и 255.255.255.0 и четко отделяют узловую часть от сетевой по границе каждого октета. Поэтому, для формировани адреса сети, октеты, у которых маска 255, мы не изменяем. а октеты у которых маска 0, превращаем в 0 (для широковещательного адреса в 255). Напимер, для адреса 192.168.25.128 с маской 255.255.0.0, адрес сети будет 192.168.0.0, а широковещательный – 192.168.255.255.
Но когда нужно разделить сети на более мелкие подсети или объединить несколько сетей в одну общую могут возникнуть сложности. Основное — это запомнить, что каждое десятичное число в адресе состоит из 8 двоичных битов, и нужно знать десятичное значение каждого бита, которое является степенью двойки.
Пример 1
Есть IP адрес 192.168.1.37/28, необходимо определить адрес сети и широковещательный адрес.
- Всего бит в адресе: 32, количество бит на адрес сети: 28, следовательно количество бит на адреса узлов: 32 – 28 = 4 бита.
- Количество возможных адресов для подсети: 2^4 = 16.
- Количество адресов для хостов (за минусом адреса сети и широковещательного адреса): 16 – 2 = 14.
- У адреса сети значения первых трех октетов будет таким же, как у адреса хоста, а значение последнего октета будет наибольшее число, не превышающее его значения в адресе хоста, кратное 16. И следовательно может формироваться из суммы: 128 или 64 или 32 или 16.
![]()
- Получаем адрес сети: 192.168.1.32
- Широковещательный адрес получаем прибавив к последнему октету адреса сети количество адресов сети минус 1: 192.168.1.<32+16-1>= 192.168.1.47
Пример 2
Есть IP адрес 192.168.1.37/255.255.255.240, необходимо определить адрес сети.
- Количество адресов для подсети можно получить: 256 — 240 = 16.
- Количество адресов для хостов 16 – 2 = 14.
- У адреса сети, как и в прошлом примере, значения первых трех октетов будет таким же, как у адреса хоста, а значение последнего октета будет наибольшее число, не превышающее его значения в адресе хоста, кратное 16. И следовательно может формироваться из суммы: 128 или 64 или 32 или 16.
![]()
Получаем адрес сети 192.168.1.32
Пример 3
Записать маску вида 255.255.255.240 в маску вида “/x”.
- 256 – 240 = 16.
- 16 = 2^4. 4 бита отводятся на адреса.
- А так как всего бит 32, то 32 – 4 = 28.
Значит 255.255.255.240 = /28
Пример 4
Записать маску вида /28 в маску вида XXX.XXX.XXX.XXX
- Всего бит: 32.
- Количество Бит на адреса: 32 – 28 = 4.
- 2^4=16. 16 адресов в подсети.
- 256 – 16 = 240.
Значит маска: 255.255.255.240.
Заключение
Как я уже говорил эта статья была написана и опубликована совместно c моим коллегой Евгением Кузьминым. В будущем мы планируем продолжить писать совместные статьи связанные с сетевыми технологиями и настройкой сетевого оборудования (маршрутизаторы, коммутаторы)
Если вам нужно что-то настроить или получить консультацию по медиасерверам и системам, можете обращаться ко мне и нашей команде через форму контактов.
Администрирование#01. Адресация в IP сетях
Некоторое введение: статьи о базовых понятиях я писала еще в универе по лекциям, затем их вычитывал мой научный руководитель (aka nixleader), поэтому тега «моё» не будет. Статьи не претендуют на оригинальность, есть множество других. Они, также, вероятно, могут встретится в сети (распространялись в универе и свободно висят в справочной системе на работе). Я постараюсь указывать места, где будет встречаться копипаста с других ресурсов (далее такое будет). Помимо простых вещей, попробую привести в литературную форму некоторые сложные маны, которые писала чисто для себя, и выложу их отдельно.
Администрирование#01. Адресация в IP сетях
В семействе протоколов TCP/IP используются три типа адресов: локальные (физические, аппаратные), IP-адреса и символьные (доменные) имена. Рассмотрим первые два типа адресов.
Основные термины:
Хост (Host) – устройство, работающее в сети на сетевом уровне модели OSI (компьютер, маршрутизатор и т.п.). Часто понятие путают с IP-адресом.
MAC-адрес — физический адрес компьютера (если точнее — сетевой карты или другого сетевого устройства). Размер адреса – 6 байт. Этот адрес должен быть уникальным для каждого устройства в локальной сети, и используется всеми устройствами для передачи данных внутри неё. (Как говорил мой преподаватель: «Вы еще не видели китайских сетевых карт: в одной серии карт может быть много повторяющихся MAC-адресов»).
IP-адрес — это 32 бита (4 байта), 4 октета, представляющие собой «логический» адрес хоста в сети (сетевой адрес). Нужно понимать, что у одного хоста может быть много IP-адресов.
IP-адреса обычно записываются в десятичной системе счисления виде четырёх октетов X1.X2.X3.X4, где X1 – старший байт адреса.
Есть консорциум IANA, который раздает IP-адреса по 5 организациям (ARIN, RIPE, APNIC, AfriNIC, LACNIC). Им выдаются сети класса А. Далее эти организации распределяют адреса по заявкам от организаций со статусом LIR (Local Internet Resource) подсетями /22 или крупнее, а в случае выделения провайдеро-независимого блока — /24 (класс C) и крупнее.
Маска подсети — указывает, какая часть IP-адреса приходится на адрес сети, а какая — на адрес хоста в ней. Без адреса сети или IP-адреса используется только в обсуждении количества используемых/необходимых адресов.
Маска — это последовательность скольких-то единичек в начале, а потом — нулей, составляющих в итоге 32 бита. Бит равный единице означает, что на его месте в IP-адресе бит будет входить в адрес сети. Нулевые биты в маске определяют позиции бит адреса хоста в IP-адресе.
Маска записывается через “/” после IP-адреса и может записываться как IP (например, 192.168.1.100/255.255.255.0; Здесь маска 255.255.255.0 — это 24 единички и 8 нулей (в двоичной системе), первые 24 символа будут адресом сети, оставшиеся 8 — адресом хоста), или как число от 0 до 32 (192.168.1.100/24 — здесь «/24» — это маска, то есть 24 единички в начале, остальные — нули).
Адрес сети – зарезервированный IP адрес, используемый для обозначения всей сети (совместно с указанием маски сети). В адресе сети на месте адреса хоста все биты выставляются в нули.
Широковещательный запрос — отправка пакета всем устройствам в сети. Для реализации такой рассылки назначается специальный широковещательный адрес: в IP-адрес после адреса сети (вместо адреса хоста) все биты выставляются в единицы.
Соответственно, максимально возможное количество хостов в сети вычисляется по формуле 2^(32-маска)-2. (Так как, когда вместо адреса хоста все нули — это адрес сети, а когда все единички — это широковещательный запрос, соответственно, теряем два адреса из всех вариантов)
Дополнительные сведения:
Маска /32 — указывает, что написан адрес одного и ровно 1 (одного) хоста
Маска /31 — используется для маршрутизации для соединения точка-точка, или если два адреса на один комп (это делается для экономии адресов и для сокращения количества записей о маршрутизации соответственно).
0.0.0.0/0 — весь интернет.
255.255.255.255 — широковещательный запрос всем в локальной сети. Используется обычно в случаях, когда хосту неизвестны настройки локальной сети.
Адреса, которые запрещены в сети интернет, или же «локальные» адреса, которые можно использовать для себя без ограничений (так называемые, «серые» адреса):
Для собственных локальных сетей:
127.0.0.0/8 – loopback – адреса которые доступны только внутри одного хоста
Классификация сетей
В сети класса А 2^24-2 хостов в одной сети, в B — 2^16-2, в C – 256 -2=254 хоста.
Адреса класса D используются для многоадресной (multicast) передачи.
Остальные адреса на данный момент зарезервированы и не используются.
Стоит отметить, что ранее классы использовались для маршрутизации. Теперь же вся маршрутизация «бесклассовая» и классы сетей указываются только для указания размера сети (например, “сеть класса C” обозначает сеть с 256 адресами (с маской /24) (любую, даже 10.2.4.0/24!!))

1K поста 15.4K подписчиков
Правила сообщества
# mount -o remount,rw /sysadmins_league
— # mount /dev/good_story /sysodmins_league
— # mount /dev/photo_it /sysodmins_league
— # mount /dev/best_practice /sysodmins_league
— # mount /dev/tutorial /sysodmins_league
2017 год, а никак не могут забыть про классы сетей.
Почти 20 лет назад это уже считало анахронизмом и упоминалось только чтобы если вдруг встретится кривой древний софт чтобы подстроиться под него.
Классификация сетей давно не используется
А в дальнейшем будет про vlan’ы, транки, 802.1Q, и все в таком ключе?
И, собственно, примеры простейших маршрутизаций))) (ведь это же конечная цель всех Ваших работ? что бы пакеты бегали по маршрутам и мы все, прочтя статьи, понимали как они бегают и по каким законам и принципам).
В целом да, но очень сумбурно. Не надо тут этого.
Начиная с мак-адреса, который служит для адресации устройства на L2 (грубо говоря в езернет-сегменте, образованном L2-устройствами) и должен быть уникальным В МИРЕ (ваш препод еще не видел материнок, в которых на всей серии в интегрированных сетевухах может быть один и тот-же мак) для чего существует OUI. И ни слова о разных способах записи MAC-адресов, отличающихся в разных ситуациях/оборудовании
И заканчивая тем, маска может записываться в dot-decimal notation, а не только в slash-notation, как-то путано. И тем, что IANA уже не выделяет сети класса А и вообще редко что-то выдаёт. Адреса v4 кончились, куда там целую А! На днях RIPE получил от IANA у кого-то отобранную за ненадобностью /19 и то большое счастье

35 лет DNS, системе доменных имён

В 1987 году произошло много событий, так или иначе повлиявших на развитие информационных технологий: CompuServe разработала GIF-изображения, Стив Возняк покинул Apple, а IBM представила персональный компьютер PS/2 с улучшенной графикой и 3,5-дюймовым дисководом. В это же время незаметно обретала форму ещё одна важная часть интернет-инфраструктуры, которая помогла создать Интернет таким, каким мы знаем его сегодня. В конце 1987 года в качестве интернет-стандартов был установлен набор протоколов системы доменных имен (DNS). Это было событием которое не только открыло Интернет для отдельных лиц и компаний во всем мире, но и предопределило возможности коммуникации, торговли и доступа к информации на поколения вперёд.
Сегодня DNS по-прежнему имеет решающее значение для работы Интернета в целом. Он имеет долгий и весомый послужной список благодаря работе пионеров Интернета и сотрудничеству различных групп по созданию стандартов.
❯ Масштабирование Интернета для всех
История этого конкретного протокола восходит к 1970-м годам. DNS следовал схеме, используемой многими другими сетевыми протоколами того времени, в том смысле, что он был открытым (не зашифрованным). Он также не устанавливал подлинность того, с кем коннектился, и клиент просто верил в любые ответы, полученные в результате запроса. В защиту того, что сегодня сочли бы очевидным недостатком, скажу, что в то время не конструировали окончательный вариант будущей глобальной коммуникационной инфраструктуры. Как выяснилось, 35 лет назад протокол DNS был доверчив до наивности, и любой решительный злоумышленник мог вторгнуться в трафик запросов DNS. Но тогда DNS был всего лишь небольшим экспериментом.
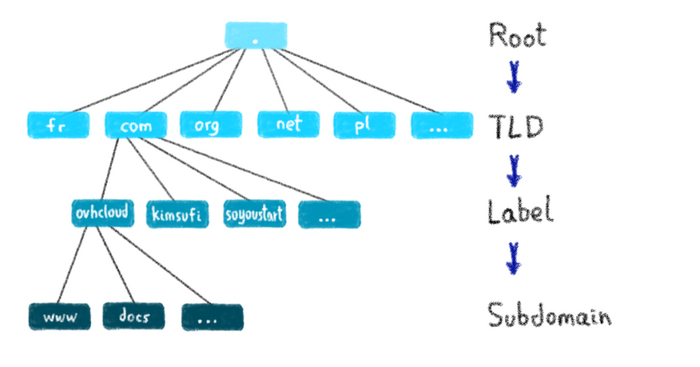
Иерархия DNS
До 1987 года Интернет в основном использовался военными, государственными учреждениями и представителями научных кругов. В то время Сетевой информационный центр, управляемый SRI International, вручную поддерживал каталог хостов и сетей. Хоть ранний Интернет и был революционным и дальновидным, не у всех был к нему доступ.
В тот же период сеть Агентства перспективных исследовательских проектов США, предтеча Интернета, который мы сейчас знаем, превратилась в быстрорастущую среду, в связи с чем предлагались новые схемы именования и адресации. Увидев тысячи заинтересованных учреждений и компаний, желавших изучить возможности сетевых вычислений, группа исследователей ARPANET поняла, что им необходим более современный автоматизированный подход к организации системы именования сети для ожидаемого быстрого роста.
Два пронумерованных информационных документа RFC 1034 и RFC 1035, были опубликованы в 1987 году неофициальной сетевой рабочей группой, которая вскоре после этого превратилась в Инженерный совет Интернета (IETF). Эти RFC, автором которых являлся специалист по информатике Пол В. Мокапетрис, стали стандартами, на основе которых была построена реализация DNS. Именно Мокапетрис, занесённый в 2012 году в Зал славы Интернета, конкретно предложил пространство имён, в котором администрирование базы данных было чётко распределено, но могло также и развиваться по мере необходимости.

Пол Мокапетрис
Помимо предоставления организациям возможности вести свои собственные базы данных, DNS упростила процесс соединения имени, которое могли запомнить пользователи, с уникальным набором чисел — IP-адресом, — который необходим веб-браузерам для перехода на веб-сайт с использованием доменного имени. Всё, что подключёно к Интернету — компьютеры, ноутбуки, планшеты, мобильные телефоны — имеет IP-адрес. Ваш любимый веб-сайт может иметь IP-адрес, например, 12.32.12.32, но его людям, очевидно, запомнить нелегко. Однако такое доменное имя, как example.com, запомнить куда проще. Благодаря тому, что не нужно было запоминать, казалось бы, случайную последовательность чисел, пользователи могли легко перейти на нужный сайт, и всё больше людей по всему миру могли получить доступ к сети.
Благодаря совместной работе этих двух аспектов — широкого распространения и сопоставления имен и адресов — DNS быстро приобрела свою конечную форму и превратилась в ту систему, которую мы знаем сегодня.
❯ Заинтересованные стороны и грубый консенсус
Тридцать пять лет развития и прогресса DNS можно отнести к сотрудничеству множества заинтересованных сторон и групп — научных кругов, технического сообщества, правительств, правоохранительных органов и гражданского общества, а также представителей коммерческой и интеллектуальной собственности, — которые и сегодня продолжают открывать важные перспективы для развития DNS и Интернета. Их точки зрения нашли своё отражение в критических изменениях в области безопасности в DNS: от обеспечения защиты прав интеллектуальной собственности до недавних совместных усилий заинтересованных сторон по борьбе со злоупотреблениями в DNS.
Экосистема DNS
Другие важные совместные достижения связаны с IETF, которая не имеет официального списка членов или требований и отвечает за технические стандарты, составляющие набор интернет-протоколов, а также с Корпорацией по управлению доменными именами и IP-адресами (ICANN), которая играет центральную координирующую роль на базовом уровне. Без конструктивного и продуктивного добровольного сотрудничества Интернет, каким мы его знаем, был бы просто невозможен.
Действительно, эти совместные усилия выстроили бренд сотрудничества, известный сегодня как «грубый консенсус» (rough consensus). Этот термин был принят IETF в первые дни создания DNS для описания формирования доминирующего мнения рабочей группы и необходимости быстрого внедрения новых технологий, что не всегда допускает длительные дискуссии и дебаты. Этот подход используется и сегодня.
Когда 35 лет назад был изобретен DNS, его целью было обеспечение роста Интернета. Вопросы безопасности и конфиденциальности не рассматривались, так как Интернетом тогда ещё почти никто не пользовался. В последующие годы DNS была расширена за счёт возможности аутентификации информации, которую она несёт, с помощью DNSSEC, но вся информация продолжала циркулировать в Интернете в текстовом виде без шифрования. Любой элемент сети, способный считывать сетевой трафик, мог считывать, какие вопросы DNS задаёт каждый человек. В принципе, можно подумать, что это не имеет большого значения, ведь DNS указывает только сайт, который вы хотите посетить, или тот, на который вы хотите отправить электронное письмо. DNS является «просто метаданными».
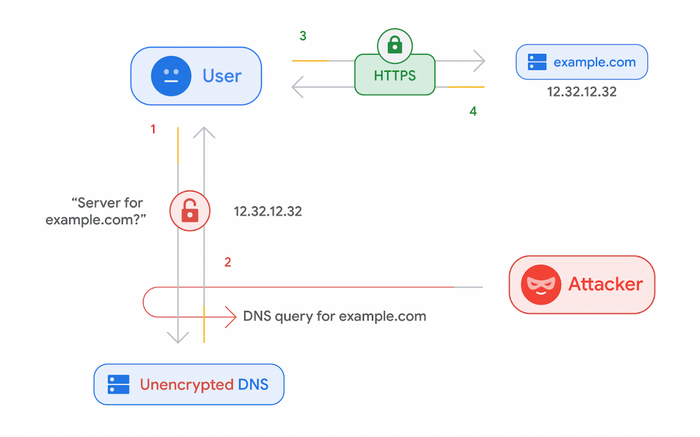
Со временем стало понятно, что эти метаданные предоставляют много информации для всех, кто хочет провести анализ, и люди начали говорить о том, как защитить DNS-трафик от «прослушек» в Интернете.
Первое предложение по исправлению этой ситуации было опубликовано Дэном Бернштейном под названием DNSCurve и было разработано для сокрытия информации при обмене данными между рекурсивными DNS-серверами (от провайдеров к клиентам) и авторитетными DNS-серверами (от веб-сайтов, TLD и т. д.). Он был опубликован вне IETF и широкого признания не получил, но OpenDNS реализовал связь между клиентами и их рекурсивными серверами.
С другой стороны, IETF начала работать над изменением транспортного протокола DNS (с самого начала это были UDP и TCP), путём добавления TLS для шифрования трафика, и таким образом родился DTLS (DNS поверх TLS). Все эти относительно простые модификации сохранили до сих пор известную DNS практически без изменений и скрыли информацию под защитной оболочкой.
Однако параллельно и независимо IETF начала работу над другим альтернативным вариантом. Известный как DNS поверх HTTPS (DoH), он отличается от традиционного DNS и скрывает сообщения DNS, как если бы они были данными, которые должны передаваться по HTTP с защитой TLS, как веб-данные любого сайта HTTPS. Сообщение становится не просто инкапсуляцией DNS, а новым типом сообщения через HTTPS.
Цель состоит не только в том, чтобы скрыть сообщения DNS с помощью шифрования, но и в том, чтобы скрыть сам трафик DNS вместе с остальным веб-трафиком. Таким образом можно избежать возможной блокировки доступа к DNS-серверам, которая используется правительствами по всему миру, а также труднее отличить DNS-трафик от другого HTTPS-трафика.
Технологии не бывают ни хорошими, ни плохими и зависят от того, как они используются. Для начала необходимо знать, как это влияет на конфиденциальность каждого из нас, а также на безопасность наших сетей. DoH, изменив способ обработки DNS, также может стать открытой дверью для нового этапа эволюции служб DNS в ближайшем будущем.
❯ Проблемы DNS
Но DNS находится в относительно малоизвестном спектре Интернета. В отличие от браузеров, Всемирной паутины или приложений социальных сетей, DNS не так заметен или даже не виден пользователям. Протокол работает таким образом, что сбивает с толку даже конечного клиента. На простой вопрос о том, кто может видеть вашу онлайн-активность, часто бывает очень сложно ответить. Тем не менее, несмотря на то, что его внутренняя работа не ясна, задача DNS проста: система разрешения DNS берёт доменные имена и переводит их в сетевые адреса. Всё это может показаться достаточно очевидным, но у этой функции есть несколько аспектов, которые использовались и злоупотреблялись на протяжении многих лет, что и лежит в основе большей части сегодняшних проблем с DNS.
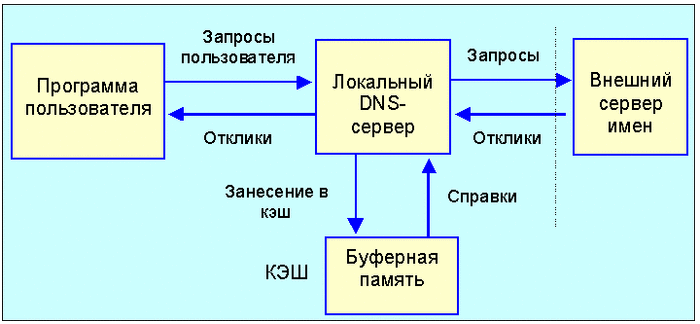
Когда Интернет стал играть более важную роль в сфере общественных коммуникаций, DNS пришёл вместе с ним и быстро стал уязвимым местом. Например, если бы я мог видеть ваши DNS-запросы и подделывать ответы DNS, я могу бы направить вас по ложному пути. Я мог бы отравить ваш кеш ненужной информацией в ответах DNS (спуфинг), которой вы были бы готовы поверить.
Однако вмешательство в DNS — это не просто инструмент для злоумышленников. Многие национальные режимы используют свои регулирующие и судебные полномочия, чтобы заставить интернет-провайдеров активно следить за пользователями, перехватывая запросы для определённых доменных имён и синтезируя ответ DNS, чтобы скрыть результаты, или перенаправлять конечного пользователя в другую точку обслуживания. Сегодня это очень распространено. Но, возможно, более тревожным, для некоторых членов технического сообщества (RFC 7258), составляющих ядро IETF, были разоблачения Сноудена в 2013 году, которые показали, что Интернет используется рядом национальных агентств, включая некоторые агентства США, для осуществления массовой слежки. Всё, что происходит в сети, начинается с обращения к DNS. Всё. Например, если мне удастся наблюдать за потоком ваших DNS-запросов, то для меня не останется никаких секретов про вас. Я действительно узнаю всё, что вы делаете в Интернете. И с кем.
Реакцией технических специалистов на документы Сноудена стало создание нового набора средств защиты вокруг DNS. Сообщения DNS шифруются, источники информации DNS аутентифицируются, запросы DNS очищаются от всей посторонней информации, а содержимое DNS подвергается проверке. Поддельные ответы DNS могут быть распознаны и отклонены. В наши дни мы рассматриваем, пожалуй, самые полные меры с двухуровневой аутентификацией, так что ни одна сторона не может сопоставить, кто запрашивает, и имя, которое запрашивается. Дело не в том, что такая информация хорошо скрыта — она больше не существует в изначальной форме, как только покидает приложение на устройстве пользователя.
Непонятно, что это означает в долгосрочной перспективе. Остаются ли незамеченными действия злоумышленников? Теряем ли мы видимость управления сетью? Что такое «безопасная» сеть и как её защитить, используя традиционные методы проверки трафика, когда весь сетевой трафик непрозрачен? Если мы больше не можем видеть внутреннюю часть DNS, то как мы можем определить, был ли (и если да, то когда?) DNS захвачен одним или двумя цифровыми гигантами?
Уже сейчас невероятно сложно найти данные DNS-запросов. Легко говорить об обеспечении части DNS, но чрезвычайно сложно выяснить, как используется DNS. Последствия обеспечения конфиденциальности слишком велики, чтобы сделать эти данные доступными, а запутывание делает их в значительной степени бесполезными. К чему мы движемся, так это к тому, что в DNS больше ничего нельзя увидеть. И никакая политика или регулирование не могут существенно изменить эту траекторию. Здесь мы говорим о действиях и поведении приложений. Попытка применить некоторые нормативные требования к поведению протокола DNS, примерно то же самое, что и попытка регулировать детальное поведение Microsoft Word или браузера Chrome.
Во многих смыслах как мотивы крупных операторов современного Интернета (Google, Apple и т. д.), так и их восприятие предпочтений пользователей совпали в том, что существует очевидное вновь обретённое уважение к конфиденциальности. С преобладанием уровня приложений в качестве доминирующего фактора в экосистеме Интернета приложения испытывают сильное неприятие того, чтобы позволить сети или платформе получить какое-либо представление о поведении приложения или содержании транзакций приложения. Протокол QUIC — хороший пример загрузки всей функции транспортных и контентных драйверов в приложение и сокрытия абсолютно всего от платформы и сети.
DNS движется в том направлении, где с помощью таких инструментов, как HTTPS и DNSSEC, мы можем полностью удалить DNS-запросы конечного пользователя и получить сервер для предварительной подготовки DNS-информации с помощью push-сервера. Если вы думали о DNS как об общей части инфраструктуры сетевого уровня, то это представление заменяется представлением о DNS как об артефакте приложения.
Если попытаться дать ответ на вопрос о том, каких данных не хватает для разработки основанных на фактических данных политик в отношении DNS, которые защитят доверие пользователей в Интернете, то ответ не совсем обнадёживает. Сегодня у нас действительно нет общедоступных данных, которые можно было бы использовать для этой цели, а необходимость всё более тщательного обращения с такими собранными данными и переход к более эффективному шифрованию и обфускации в DNS-запросах создают более чем достаточные препятствия для её сбора и распространения.
❯ Признание вехи
Тем не менее, оглядываясь назад на то, как появилась DNS, и на процессы, обеспечивающие её надёжное функционирование, важно признать работу, проделанную организациями и отдельными лицами, составляющими это сообщество. Мы также должны помнить, что усилия по-прежнему опираются на добровольное сотрудничество.
Празднование таких годовщин, как 35-летие протокола DNS, позволяет многочисленным заинтересованным сторонам и сообществам сделать паузу и задуматься об огромной работе и ответственности, стоящей перед нами. Благодаря новаторским умам, которые задумали и построили раннюю инфраструктуру Интернета, и, в частности, фундаментальному вкладу Пола Мокапетриса в набор протоколов DNS, мир смог создать устойчивую глобальную экономику, которую мало кто мог себе представить 35 лет назад.
35-я годовщина публикации RFC 1034 и 1035 напоминает нам о вкладе DNS в рост и масштабирование того, что мы знаем сегодня как «Интернет». Это момент, который стоит отметить.

Подпишись на наш блог, чтобы не пропустить новые интересные посты!
С праздником коллеги!
Напоминаю, что сегодня день сисадмина! Всем причастным радоваться. А то забывать стали, что есть такой праздник.

Помогите с выбором бесплатной HelpDesk платформы для лицея
Всем привет. Пишу пост в надежде помощи ребят из IT-тусовки. Короче, нужно в образовательное учреждение (лицей) для сотрудников (учителей) автоматизировать подачу заявок на обслуживание. Честно скажу, беготня с листом бумаги — устаревший вариант времён дедушкиных подштанников. Так как в лицее работает все в доменной сети, есть выделенный IP-адрес, у всех есть компы с Windows 10 Pro на борту и смартфоны с Whatsapp и Telegram, появилась идея так или иначе привести эту сферу работы в порядок. Насмотрелся на разные системы подачи заявок, облизался и загрустил, когда увидел, сколько они стоят. Мне нужно не много, чтобы доменный пользователь, после авторизации в учётке, перешёл на сервер лицея, там ему выплюнули форму, дескать, опиши что нужно сделать, а мне потом его писанина была доступна с возможностью изменений статуса и так далее.
да, это я сейчас про идеальный вариант, само собой, способов как оставить заявку существует с десяток точно, через мессенджеры, почту, письмом и т.д. можно было бы и просто остановиться на письмах или сообщениях в личку, но хочется видеть некую структуру, упорядоченная история решения, так как некоторые проблемы бывают типовыми, и порой хочется посмотреть, как проблема решалась когда-то.
Из того, что успел пощупать, больше всего понравилась Intraservice, но там ограничено количество пользователей, а в моем случае их будет около 50 человек.
Прошу подсказать именно бесплатное решение, так как, честно, руководству и так норм, как говорится, а тетрадка меня ну совсем не устраивает. С работниками лицея пообщался, вариант автоматизации поддерживают, ждут предложения, а я жду вашей помощи, наверное кто-то что-то подходящее уже использует.
Вопрос по инвентаризации офисной техники
Я эникей в IT фирме по разработке ПО.
Достаточно давно висит вопрос об учете техники в компании. Может ли кто-нибудь подказать, какие решение используются у вас в компании?
По основым проблемам, комплектующие внутри ПК достаточно часто меняются между машинами. Машин чуть больше 200, не считая серверный парк.
Пробовал написать свою базу 1С, но ввиду небольшого опыта, получились костыли и всегда есть шанс упусть то или иное действие с техникой.
Фальшивый itшник
Я обычный казахский парень и как обычный казахский парень, я работаю devopsом. Ну у нас в степи обычно как бывает, когда человеку даже овец пасти не доверяют, а таксовать машины нет, приходится работать в it. Долгое время я прятался от степных волков и казашек которым пора замуж, на проекте в налоговой, притворно изображая администратора. Со временем я научился делать это так умело, что даже матёрые админы замечать перестали. Этот театр одного актера продолжался долгие 15 лет. Но однажды принудительно возвращенный в офис с удаленки, с удивлением обнаружил что половина отдела приходят со своими рабочими проблемами и мне приходится их решать. Посидев в роли наставника пару дней, понял, пора валить. Начал искать работу, где я смогу притворяться за ту же сумму но не так много. Однажды на одном из собеседований, когда я рассказывал какие мохинаций с bash я применял, что бы ничего не делать, hr мне поставил диагноз "так ты этот. как его. DevOps". Ого! подумал я "такими мы ещё не притворялись" и смело указал в резюме что DevOps. И с тех пор уже три года я успешно притворяюсь DevOps ом в разных фирмах. Это совсем просто прохожу одно собеседование за другим и когда появлялись вопросы на которые я не мог ответить, я просто иду читать ответы. А устроившись просто делал то что читал. И вот сегодня я вышел на новую работу в очередной раз я обманул devops senior-а рассказав как расцветёт его система с применением практик инфраструктурного кода. Он даже принял за чистую монету что ci на jenkins я использую, не потому что не знаю как это делается в gitlab, а потому что убежден что нельзя класть яйца репозитория и пайплайна в один сервис. Спустя какое то время, когда я выслушивал ответную его тираду "что микросервисы надо использовать только в том случае когда не можешь спрогнозировать нагрузку на систему". И тут меня осенило я имею дело с гениальным актером который научился притворяться на уровне senior DevOps. Придурка который открыл статью "какие вопросы надо задавать девопсу на собеседовании" я бы распознал сразу.
И вот первый рабочий день, начали мы как у них в обычаях со стендапа. Потому как он прошел закрались первые смутные сомнения. Senior в задачи погрузится не дал. На вопрос под какие ОС писать плейбуки? мне не внятно промычал и что то куда-то принялся писать. Какой вид бэкапа писать в плейбуке для mysql? сказали покамест не нужно писать его вообще. Из чего я понял что тех задание на испытательный месяц писали для меня на шару.
Senior поругал отвлеченого на посторонние разговоры в офисе девопса. Мол у нас дескать стендап, а ты отвлечен фу фу фу. Как бы показывая зубки альфача. А когда бета девопс начал что то тоже конкретизировать из серий "будет ли в плейбуке докер" последовал ответ он сам должен это спрашивать. А когда я повторил вопрос он не ответил. Ну думаю хрен с тобой senior помидор, самое место такому на rotten tomato's"
Где то два или три часа меня донимал бухгалтер требуя подписать все на свете.
Затем hr-ом я был запущен в корпоративный Битрикс где должен был ознакомиться с видео материалами. В сумбурные речи лекторов я вслушиваться не стал, в нашей профессии быстро учишься определять инфоциган торгующих рожей на фоне скрина какого-нибудь софта. Да мудрено ли с моим стажем в почти двадцать лет верить в сказки из серий "построение горизонтальных связей между работниками ускорит процесс согласования" ага щаз, вы мне ещё про "собор и базар" расскажите. Полтора часа ребята с видео, переливали из пустого в порожнюю, тыкая пальцем в схему о которой любая секретутка выразилась бы "ой бывала я в структурах и по больше". После увиденного смутные сомнения начали терзать с новой силой".
Окончательно точка поставлена была только во время прохождения материалов по логировнию, так они "протоколирование выполненных работ" у себя на иностранный манер обозвали. Снова и снова читая пяти страничный текст, я просто диву давался, как можно было простую мысль "записывайте за собой все что делаете" тонким слоем смысла натянуть на пять страниц с рисунками. Я всякое видел но такое, такое ощущение что у автора стояла задача зашифровать а не обьяснить. И когда я увидел тест в конце текста, все наконец-то встало на свой места.
Раз за разом проваливая тест на двух вопросах из шести, я разбирал ситуацию "Так значит ребята вы наняли инженера, час которого стоит как рандеву с путаной. И вместо того что бы дать доступ к aws, вы его талмудом от аутистов об тесты херачите? Сразу повеяло душком каворкинга родной нацкомпаний, в ней начальство так усердно делало вид что работает, что местами даже само в это верило. И вот эта вера и рождала в чреслах менеджмента, такие вот документы и тесты. Ну там то гос бюджет все понятно. А тут что происходит? А тут тоже самое, разница только в том весь этот театр для инвесторов. Через годик до инвестора дойдет что "царь не настоящий". А прибыль не женский оргазм, такое не сыграть. Если даже и получится, то на суде и бездарно как у Эмбер Херд. И пойду я с вами на hh собеседование клянчить. Подумал я и написал hr-у который как ни странно был самым настоящим "бро сори, но я сваливаю"
Потому что я притворяюсь почти 20 лет, уж я то в курсе как ложь огорчает, не умелая ложь бесит. А самообман это глупость вызывающая недоумение.
Сетевые технологии: IP-адреса, подсети и бесклассовая адресация CIDR
Понимание сетевых технологий крайне необходимо для настройки сложных сред, эффективного обмена информацией между серверами, управления нодами, а также при разработке безопасных сетевых политик.
Данная статья ознакомит вас с методами проектирования сетей и взаимодействия с компьютерами, которые подключены к сети. В частности здесь рассматриваются сетевые классы, подсети и CIDR-нотация для группирования IP-адресов.
Что такое IP-адрес?
Каждое устройство или место в сети должно иметь свой адрес – некоторое обозначение в рамках предопределенной системы адресов, по которому к этому устройству/месту можно получить доступ. В стандартной модели TCP/IP адресация обрабатывается на нескольких сетевых уровнях. Обычно в контексте сетевых технологий под сетевым адресом подразумевают IP-адрес.
IP-адреса позволяют получать сетевые ресурсы через сетевой интерфейс. Если один компьютер хочет установить связь с другим компьютером, он может передать информацию на IP-адрес удаленного компьютера. Если два компьютера находятся в одной сети и если компьютеры и устройства между ними могут преобразовывать сетевые запросы, компьютеры должны иметь возможность установить соединение и отправлять информацию.
Каждый IP-адрес должен быть уникальным в рамках своей сети. Сети можно изолировать, а можно соединить их между собой и преобразовать, чтобы обеспечить доступ к различным сетям. Преобразование сетевых адресов – это система, которая позволяет переписывать адреса пакетов, достигнувших границы сети, и передать их в указанное место назначения. Таким образом, один IP-адрес можно использовать в нескольких изолированных средах.
Разница между IPv4 и IPv6
Сегодня существует две версии протокола IP, которые широко применяются в системах. IPv4, четвёртая версия протокола, поддерживается большинством систем. Более новая версия, IPv6, набирает популярность благодаря улучшениям возможностей протокола и из-за нехватки доступных адресов IPv4 (проще говоря, сегодня в мире столько подключенных к сети устройств, что адресов IPv4 не хватает на всех).
Адреса IPv4 – 32-битные. Каждый байт, или 8-битовый сегмент адреса отделяется точкой и выражается числом в диапазоне 0-255. Несмотря на то, что эти числа обычно выражаются десятичным числом (чтобы упростить их восприятие), каждый сегмент называют октетом, чтобы выразить тот факт, что он представляет собой 8 бит.
Типичный адрес IPv4 выглядит примерно так:
Самым низким значением в октете является 0, а самым высоким – 255.
Также можно выразить этот адрес в двоичном коде, чтобы лучше понять строение адреса (в примере каждые 4 бита для удобочитаемости заменены пробелом, а точки пунктиром):
1100 0000 — 1010 1000 — 0000 0000 — 0000 0101
Оба приведённые выше формата выражают один и тот же адрес.
Несмотря на некоторые отличия в функциональности IPv4 и IPv6, наиболее заметным их отличием является адресное пространство. IPv6 выражает адреса как 128-битное число. Это означает, что IPv6 имеет в 7,9×1028 раз больше адресов, чем IPv4.
Чтобы выразить этот расширенный диапазон адресов, IPv6 обычно записывается как восемь сегментов из четырех шестнадцатеричных чисел. Шестнадцатеричные числа выражаются числами от 0 до 15, а также числами a-f (для более высоких значений). Типичный адрес IPv6 может выглядеть примерно так:
Этот адрес можно записать в компактном формате. Правила IPv6 позволяют удалять любые ведущие нули из каждого октета и заменять диапазоны обнуленных групп двойным двоеточием (: :).
К примеру, если в IPv6 есть такая группа:
Вы можете ввести просто:
Диапазон IPv6 с несколькими группами нулей:
можно сократить до:
Сокращение можно применять только один раз для каждого адреса, иначе полный адрес будет невозможно восстановить.
Сегодня всё чаще используется IPv6, но в остальных примерах статьи будут использоваться адреса IPv4, потому что с меньшим адресным пространством проще работать.
Классы и зарезервированные диапазоны IPv4
Обычно IP-адреса состоят из двух компонентов. Первая часть адреса определяет сеть, частью которой является адрес. Вторая часть используется для указания хоста в этой сети.
Граница между первым и вторым компонентом адреса определяется настройками сети.
Адреса IPv4 делятся на пять классов, предназначенных для дифференциации сегментов доступного адресного пространства IPv4. Они определяются первыми четырьмя битами каждого адреса. Вы можете определить, к какому классу принадлежит IP-адрес, просмотрев эти биты.
- Класс А: 0—. Если первый бит в адресе – 0, значит, адрес относится к диапазону А (это адреса от 0.0.0.0 до 127.255.255.255).
- Класс B: 10–. К этому классу относятся все адреса от 128.0.0.0 до 191.255.255.255. Это адреса, первый бит которых представлен единицей, а второй – нет.
- Класс C: 110-. Это адреса от 192.0.0.0 до 223.255.255.255. Их первые два бита представлены единицей, а третий – нет.
- Класс D: 1110. Первые три бита этого класса представлены единицей. Это адреса в диапазоне от 224.0.0.0 до 239.255.255.255.
- Класс Е: 1111. Это адреса в диапазоне от 224.0.0.0 до 239.255.255.255. Этот класс включает в себя все адреса, которые начинаются с 1111.
Адреса класса D зарезервированы для многоадресных протоколов, которые позволяют отправлять пакет группе нод в одной транзакции. Адреса класса E зарезервированы для будущих или экспериментальных целей и в основном не используются.
Классы А-С по-разному разделяют компонент сети и компонент хоста.
Адреса класса A использовали оставшуюся часть первого октета для представления сети, а остальная часть адреса использовалась для определения хостов. Такой адрес было удобно использовать для определения нескольких сетей с большим количеством хостов.
Адреса класса B использовали первые два октета (остаток от первого и весь второй) для определения сети, а остальные – для определения хостов в каждой сети. Адреса класса C использовали первые три октета для определения сети, а последний октет – для определения хостов в этой сети.
Изначально разделение IP-пространства на классы применялось как решение проблемы быстрого исчерпания адресов IPv4 (вы можете иметь несколько компьютеров с одним и тем же хостом, если они находятся в разных сетях). Сегодня существуют более современные решения.
Зарезервированные частные диапазоны
Некоторые части пространства IPv4 зарезервированы для конкретных целей.
Один из самых полезных зарезервированных диапазонов – это диапазон кольцевой проверки, определяемый адресами от 127.0.0.0 до 127.255.255.255. Этот диапазон используется каждым хостом для тестирования сети. Обычно он выражается первым адресом в этом диапазоне: 127.0.0.1.
Каждый обычный класс также имеет диапазон, который используется для обозначения адресов частной сети. Например, для класса A это адреса от 10.0.0.0 до 10.255.255.255. Для класса B этот диапазон составляет 172.16.0.0 – 172.31.255.255. Для класса C это диапазон от 192.168.0.0 до 192.168.255.255.
Любой компьютер, не подключенный к Интернету напрямую (т. е. компьютер, который проходит через маршрутизатор или другую систему NAT), может использовать эти адреса по своему усмотрению.
Больше о зарезервированных адресах можно узнать в Википедии.
Сетевые маски и подсети
Подсети – это сети, которые получаются в результате процесса деления сети на более мелкие сетевые разделы. Подсети используются для различных целей и помогают изолировать группы хостов и управлять ними.
Как говорилось выше, каждое адресное пространство делится на сетевую часть и часть хоста. Часть адреса, которую каждый из них занимает, зависит от класса, которому принадлежит адрес.
Например, для адресов класса C первые 3 октета используются для описания сети: в адресе 192.168.0.15 часть 192.168.0 описывает сеть, а 15 – хост.
По умолчанию каждая сеть имеет только одну подсеть, которая содержит все адреса нод.
Сетевая маска – это спецификация количества адресных битов, которые используются для части сети. Маска подсети – это еще одна сетевая маска, используемая для дальнейшего разделения сети.
Каждый бит адреса, который считается значимым для описания сети, должен быть представлен в сетевой маске как 1.
Например, адрес 192.168.0.15 можно выразить в бинарном коде:
1100 0000 — 1010 1000 — 0000 0000 — 0000 1111
Идентификатор сети в адресах класса C – это первые 3 октета, или первые 24 бита. Поскольку эти биты важны и их нужно сохранить, сетевая маска будет выглядеть следующим образом:
1111 1111 — 1111 1111 — 1111 1111 — 0000 0000
В обычном формате IPv4 это будет выглядеть так:
Каждый бит, отмеченный в бинарном представлении сетевой маски нулём, считается идентификатором хоста и может изменяться. Биты, отмеченные единицей, постоянны (хотя в сети или подсети это не всегда так).
Определить сетевую часть адреса можно с помощью поразрядной операции AND между адресом и сетевой маской. Поразрядная операция AND сохраняет сетевую часть адреса и отбрасывает часть хоста. В результате рассматриваемый нами адрес будет выглядеть так:
1100 0000 — 1010 1000 — 0000 0000 — 0000 0000
Его можно выразить как 192.168.0.0. Спецификация хоста является отличием между этим исходным значением и частью хоста. В данном случае это «0000 1111» или 15.
Подсети берут часть пространства хоста адреса и использует его как дополнительную сетевую спецификацию для дальнейшего разделения адресного пространства.
Например, сетевая маска 255.255.255.0 оставляет 254 хоста в сети (0 и 255 использовать нельзя – они зарезервированы). Чтобы разделить это пространство на две подсети, можно использовать один бит части хоста адреса в качестве маски подсети.
Продолжим работать с предыдущим примером. Часть сети:
1100 0000 — 1010 1000 — 0000 0000
Первый бит хоста можно использовать для обозначения подсети. Для этого нужно настроить маску подсети, вместо:
1111 1111 — 1111 1111 — 1111 1111 — 0000 0000
1111 1111 — 1111 1111 — 1111 1111 — 1000 0000
В традиционной нотации IPv4 это будет выглядеть так:
Теперь первый бит последнего октета отмечен как важный для адресации в сети. Это создает две подсети. Первая подсеть будет в диапазоне от 192.168.0.1 до 192.168.0.127. Вторая подсеть содержит хосты 192.168.0.129 до 192.168.0.255. Традиционно сама подсеть не должна использоваться в качестве адреса.
Бесклассовая адресация CIDR
Система CIDR (Classless Inter-Domain Routing) была разработана в качестве альтернативы традиционным подсетям. С помощью CIDR вы можете добавить спецификацию самого IP-адреса в число значимых битов, составляющих часть маршрутизации или сети.
Например, выразить связь IP-адреса 192.168.0.15 с сетевой маской 255.255.255.0 можно с помощью CIDR-нотации 192.168.0.15/24. Это означает, что первые 24 бита указанного IP-адреса считаются значимыми для сетевой маршрутизации.
CIDR можно использовать для обозначения «суперсетей». В этом случае имеется в виду более широкий диапазон адресов, что невозможно при использовании традиционной маски подсети. Например, в сети класса C (в предыдущем примере) объединять адреса из сетей 192.168.0.0 и 192.168.1.0 нельзя, потому что сетевая маска для адресов класса C – 255.255.255.0.
CIDR-нотация позволяет объединить эти блоки, определив этот блок как 192.168.0.0/23. Это значит, что 23 бита используются для части сети.
Таким образом, первая сеть (192.168.0.0) может быть представлена в двоичном коде так:
1100 0000 — 1010 1000 — 0000 0000 — 0000 0000
А вторая сеть (192.168.1.0) – так:
1100 0000 — 1010 1000 — 0000 0001 — 0000 0000
CIDR-адрес значит, что 23 бита используются в адресной части сети. Это эквивалентно сетевой маске 255.255.254.0, или:
1111 1111 — 1111 1111 — 1111 1110 — 0000 0000
Как видите, в этом блоке 24-й бит может быть 0 или 1, и такой адрес все равно подойдёт, так как ля сетевой части важны только первые 23 бита.
В целом, CIDR позволяет контролировать адресацию непрерывных блоков IP-адресов. Это намного удобнее, чем подсеть.
Заключение
Теперь вы знакомы с некоторыми механизмами адресации и основами протокола IP. Понимание сетевых технологий поможет правильно настроить программное обеспечение и его компоненты.
Существует много полезных онлайн-инструментов, которыми вы можете пользоваться при работе с сетями: