Реализация многозадачности на однопроцессорных компьютерах
Самым простым способом реализации многозадачности является принцип кооперативной многозадачности. При этом сама нить процесса решает, передавать или нет управление другой нити. Основным достоинством такой схемы является простота отладки планировщика процессов. Недостатком такой схемы является сложность реализации процесса при пропорциональном распределении времени между нитями.
Другим способом организации многозадачности является вытесняющая многозадачность. При этом сама операционная система решает, сколько времени будет работать та или иная нить процесса. При этом вытеснение текущей задачи происходит при возникновении какого-либо события или в связи с изменением приоритета процесса.
Внешние устройства
Все без исключения приложения вычислительных систем, так или иначе, связаны с использованием внешних, или периферийных устройств. Даже чисто вычислительные задачи нуждаются в устройствах для ввода исходных данных и вывода результата. Без преувеличения можно сказать, что процессор, не имеющий никаких внешних устройств, абсолютно бесполезен. У вычислительных систем первых поколений набор периферийных устройств часто исчерпывался упомянутыми устройствами для ввода исходных данных и вывода результата вычислений, поэтому до сих пор модули ОС, работающие с периферией, называют подсистемой ввода-вывода (input/output subsystem). У большинства современных компьютеров набор внешних устройств весьма обширен, и функции многих из них не могут или лишь с определенной натяжкой могут быть описаны как ввод и вывод.
С функциональной точки зрения внешние устройства, подключаемые к современным компьютерам, можно разделить на следующие категории:
Устройства внешней памяти, которые в свою очередь, можно разделить на два класса:
• Устройства памяти с произвольным доступом, главным образом магнитные диски. К этому же классу относятся дискеты, магнитооптические и оптические диски и практически не применяемые в настоящее время магнитные барабаны. Удачным универсальным обозначением для этого класса устройств является принятое в документации фирмы IBM сокращение DASD (Direct Access Storage Device – запоминающее устройство прямого доступа).
• Устройства памяти с последовательным доступом. В основном, это лентопротяжные устройства (стриммеры и др.).
Сетевые и телекоммуникационные устройства.
Устройства алфавитно-цифрового ввода-вывода: печатающие устройства, телетайпы, текстовые терминалы.
Устройства звукового ввода-вывода.
Устройства графического ввода-вывода: сканеры или видеодекодеры (ввод), графические дисплеи, плоттеры, графические принтеры или видеокодеры (вывод).
Позиционные устройства ввода: мыши, планшеты-дигитайзеры, световые перья и т. д.
Сенсорные и исполнительные устройства управляющих систем. Например, у бортового компьютера самолета сенсорными устройствами могут являться гироскопы или другие датчики ориентации, трубка Пито (датчик, определяющий скорость самолета относительно воздуха), радар и терминал глобальной системы позиционирования, а исполнительными устройствами – шаговые электромоторы, управляющие рулевыми плоскостями, топливные насосы двигателей и т. д.
Все перечисленные устройства либо передают информацию центральному процессору (и, таким образом, могут быть объявлены устройствами ввода), либо получают информацию от него (устройства вывода), либо могут как передавать, так и принимать информацию (устройства ввода-вывода). Эта классификация может показаться неестественной, потому что в соответствии с ней в одну категорию попадают столь функционально неродственные устройства,, как сетевой адаптер и жесткий диск (устройства ввода-вывода), или печатающее устройство и рулевая машинка летательного аппарата (устройства вывода), однако разработчику операционной системы во многих случаях этой классификации оказывается достаточно.
Нередко, впрочем, в эту классификацию вводят еще один уровень: устройства ввода делят на пассивные (выдающие данные только в ответ на явные запросы центрального процессора) и активные, или генераторы событий, которые могут порождать данные тогда, когда их об этом явно не просили. Ко второй категории относятся интерактивные устройства ввода (клавиатура, мышь), сетевые адаптеры, таймеры различного рода, а также многие датчики управляющих систем.
Организация многозадачности в ядре ОС
 Волею судеб мне довелось разбираться с организацией многозадачности, точнее псевдо-многозадачности, поскольку задачи делят время на одном ядре процессора. Я уже несколько раз встречала на хабре статьи по данной теме, и мне показалось, что данная тема сообществу интересна, поэтому я позволю себе внести свою скромную лепту в освещение данного вопроса.
Волею судеб мне довелось разбираться с организацией многозадачности, точнее псевдо-многозадачности, поскольку задачи делят время на одном ядре процессора. Я уже несколько раз встречала на хабре статьи по данной теме, и мне показалось, что данная тема сообществу интересна, поэтому я позволю себе внести свою скромную лепту в освещение данного вопроса.
Сначала я попытаюсь рассказать о типах многозадачности (кооперативной и вытесняющей). Затем перейду к принципам планирования для вытесняющей многозадачности. Рассказ рассчитан скорее на начинающего читателя, который хочет разобраться, как работает многозадачность на уровне ядра ОС. Но поскольку все будет сопровождаться примерами, которые можно скомпилировать, запустить, и с которыми при желании можно поиграться, то, возможно, статья заинтересует и тех, кто уже знаком с теорией, но никогда не пробовал планировщик “на вкус”. Кому лень читать, может сразу перейти к изучению кода, поскольку код примеров будет взят из нашего проекта.
Ну, и многопоточные котики для привлечения внимания.
Введение
В нем вводится понятие разделение ресурсов (resources sharing) и, собственно, планирование (scheduling). Именно о планировании (в первую очередь, процессорного времени) и пойдет речь в данной статье. В обоих определениях речь идет о планировании процессов, но я буду рассказывать о планировании на основе потоков.
 Таким образом, нам необходимо ввести еще одно понятие, назовем его поток исполнения — это набор инструкций с определенным порядком следования, которые выполняет процессор во время работы программы.
Таким образом, нам необходимо ввести еще одно понятие, назовем его поток исполнения — это набор инструкций с определенным порядком следования, которые выполняет процессор во время работы программы.
Поскольку речь идет о многозадачности, то естественно в системе может быть несколько этих самых вычислительных потоков. Поток, инструкции которого процессор выполняет в данный момент времени, называется активным. Поскольку на одном процессорном ядре может в один момент времени выполняться только одна инструкция, то активным может быть только один вычислительный поток. Процесс выбора активного вычислительного потока называется планированием (scheduling). В свою очередь, модуль, который отвечает за данный выбор принято называть планировщиком (scheduler).
- невытесняющие (кооперативные) — планировщик не может забрать время у вычислительного потока, пока тот сам его не отдаст
- вытесняющие — планировщик по истечении кванта времени выбирает следующий активный вычислительный поток, сам вычислительный поток также может отдать предназначенный для него остаток кванта времени
Давайте начнем разбираться с невытесняющего метода планирования, так как его очень просто можно реализовать.
Невытесняющий планировщик
Рассматриваемый невытесняющий планировщик очень простой, данный материал дан для начинающих, чтобы было проще разобраться в многозадачности. Тот, кто имеет представление, хотя бы теоретическое, может сразу перейти к разделу “Вытесняющий планировщик”.
Простейший невытесняющий планировщик
Представим, что у нас есть несколько задач, достаточно коротких по времени, и мы можем их вызывать поочередно. Задачу оформим как обычную функцию с некоторым набором параметров. Планировщик будет оперировать массивом структур на эти функции. Он будет проходиться по этому массиву и вызывать функции-задачи с заданными параметрами. Функция, выполнив необходимые действия для задачи, вернет управление в основной цикл планировщика.
Результаты вывода:
График занятости процессора:

Невытесняющий планировщик на основе событий
Понятно, что описанный выше пример слишком уж примитивен. Давайте введем еще возможность активировать определенную задачу. Для этого в структуру описания задачи нужно добавить флаг, указывающий на то, активна задача или нет. Конечно, еще понадобится небольшое API для управления активизацией.
Результаты вывода:
Second activated
First activated
График занятости процессора

Невытесняющий планировщик на основе очереди сообщений
Проблемы предыдущего метода очевидны: если кто-то захочет два раза активировать некую задачу, пока задача не обработана, то у него это не получится. Информация о второй активации просто потеряется. Эту проблему можно частично решить с помощью очереди сообщений. Добавим вместо флажков массив, в котором хранятся очереди сообщений для каждого потока.
Результаты работы:
Second activated
Message 2 to first
Message 1 to first
График занятости процессора

Невытесняющий планировщик с сохранением порядка вызовов
Еще одна проблема у предыдущих примеров в том, что не сохраняется порядок активизации задач. По сути дела, каждой задачи присвоен свой приоритет, это не всегда хорошо. Для решения этой проблемы можно создать одну очередь сообщений и диспетчер, который будет ее разбирать.
Результаты работы:
First create
Second create
Second create again
График занятости процессора

Прежде чем перейти к вытесняющему планировщику, хочу добавить, что невытесняющий планировщик используется в реальных системах, поскольку затраты на переключение задач минимальные. Правда этот подход требует большого внимания со стороны программиста, он должен самостоятельно следить за тем, чтобы задачи не зациклились во время исполнения.
Вытесняющий планировщик
 Теперь давайте представим следующую картину. У нас есть два вычислительных потока, выполняющих одну и ту же программу, и есть планировщик, который в произвольный момент времени перед выполнением любой инструкции может прервать активный поток и активировать другой. Для управления подобными задачами уже недостаточно информации только о функции вызова потока и ее параметрах, как в случае с невытесняющими планировщиками. Как минимум, еще нужно знать адрес текущей выполняемой инструкции и набор локальных переменных для каждой задачи. То есть для каждой задачи нужно хранить копии соответствующих переменных, а так как локальные переменные для потоков располагаются на его стеке, то должно быть выделено пространство под стек каждого потока, и где-то должен храниться указатель на текущее положение стека.
Теперь давайте представим следующую картину. У нас есть два вычислительных потока, выполняющих одну и ту же программу, и есть планировщик, который в произвольный момент времени перед выполнением любой инструкции может прервать активный поток и активировать другой. Для управления подобными задачами уже недостаточно информации только о функции вызова потока и ее параметрах, как в случае с невытесняющими планировщиками. Как минимум, еще нужно знать адрес текущей выполняемой инструкции и набор локальных переменных для каждой задачи. То есть для каждой задачи нужно хранить копии соответствующих переменных, а так как локальные переменные для потоков располагаются на его стеке, то должно быть выделено пространство под стек каждого потока, и где-то должен храниться указатель на текущее положение стека.
Эти данные — instruction pointer и stack pointer — хранятся в регистрах процессора. Кроме них для корректной работы необходима и другая информация, содержащаяся в регистрах: флаги состояния, различные регистры общего назначения, в которых содержатся временные переменные, и так далее. Все это называется контекстом процессора.
Контекст процессора
 Контекст процессора (CPU context) — это структура данных, которая хранит внутреннее состояние регистров процессора. Контекст должен позволять привести процессор в корректное состояние для выполнения вычислительного потока. Процесс замены одного вычислительного потока другим принято называть переключением контекста (context switch).
Контекст процессора (CPU context) — это структура данных, которая хранит внутреннее состояние регистров процессора. Контекст должен позволять привести процессор в корректное состояние для выполнения вычислительного потока. Процесс замены одного вычислительного потока другим принято называть переключением контекста (context switch).
Описание структуры контекста для архитектуры x86 из нашего проекта:
Понятия контекста процессора и переключения контекста — основополагающие в понимании принципа вытесняющего планирования.
Переключение контекста
Переключение контекста — замена контекста одного потока другим. Планировщик сохраняет текущий контекст и загружает в регистры процессора другой.
Выше я говорила, что планировщик может прервать активный поток в любой момент времени, что несколько упрощает модель. На самом же деле не планировщик прерывает поток, а текущая программа прерывается процессором в результате реакции на внешнее событие — аппаратное прерывание — и передает управление планировщику. Например, внешним событием является системный таймер, который отсчитывает квант времени, выделенный для работы активного потока. Если считать, что в системе существует ровно один источник прерывания, системный таймер, то карта процессорного времени будет выглядеть следующим образом: 
Процедура переключения контекста для архитектуры x86:
Машина состояний потока
Мы обсудили важное отличие структуры потока в случае с вытесняющим планировщиком от случая с невытесняющим планировщиком — наличие контекста. Посмотрим, что происходит с потоком с момента его создания до завершения: 
- Состояния init отвечает за то, что поток создан, но не добавлялся еще в очередь к планировщику, а exit говорит о том, что поток завершил свое исполнение, но еще не освободил выделенную ему память.
- Состояние run тоже должно быть очевидно — поток в таком состоянии исполняется на процессоре.
- Состояние ready же говорит о том, что поток не исполняется, но ждет, когда планировщик предоставит ему время, то есть находится в очереди планировщика.
Вот так можно представить обобщенную машину состояний: 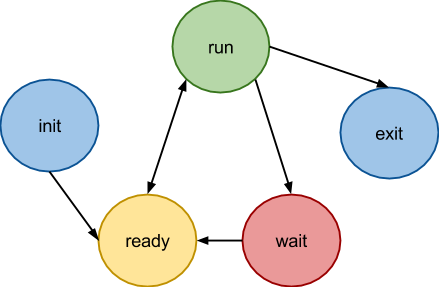
В этой схеме появилось новое состояние wait, которое говорит планировщику о том, что поток уснул, и пока он не проснется, процессорное время ему выделять не нужно.
Теперь рассмотрим поподробнее API управления потоком, а также углубим свои знания о состояниях потока.
Реализация состояний
Если посмотреть на схему состояний внимательнее, то можно увидеть, что состояния init и wait почти не отличаются: оба могут перейти только в состояние ready, то есть сказать планировщику, что они готовы получить свой квант времени. Таким образом состояние init избыточное.
Теперь посмотрим на состояние exit. У этого состояния есть свои тонкости. Оно выставляется планировщику в завершающей функции, о ней речь пойдет ниже. Завершение потока может проходить по двум сценариям: первый — поток завершает свою основную функцию и освобождает занятые им ресурсы, второй — другой поток берет на себя ответственность по освобождению ресурсов. Во втором случае поток видит, что другой поток освободит его ресурсы, сообщает ему о том, что завершился, и передает управление планировщику. В первом случае поток освобождает ресурсы и также передает управление планировщику. После того, как планировщик получил управление, поток никогда не должен возобновить работу. То есть в обоих случаях состояние exit имеет одно и то же значение — поток в этом состоянии не хочет получить новый квант времени, его не нужно помещать в очередь планировщика. Идейно это также ничем не отличается от состояния wait, так что можно не заводить отдельное состояние.
Таким образом, у нас остается три состояния. Мы будем хранить эти состояния в трех отдельных полях. Можно было бы хранить все в одном целочисленном поле, но для упрощения проверок и в силу особенности многопроцессорного случая, который здесь мы обсуждать не будем, было принято такое решение. Итак, состояния потока:
- active — запущен и исполняется на процессоре
- waiting — ожидает какого-то события. Кроме того заменяет собой состояния init и exit
- ready — находится под управлением планировщика, т.е. лежит в очереди готовых потоков в планировщике или запущен на процессоре. Это состояние несколько шире того ready, что мы видим на картинке. В большинстве случаев active и ready, а ready и waiting теоретически ортогональны, но есть специфичные переходные состояния, где эти правила нарушаются. Про эти случаи я расскажу ниже.
Создание
Создание потока включает в себя необходимую инициализацию (функция thread_init) и возможный запуск потока. При инициализации выделяется память для стека, задается контекст процессора, выставляются нужные флаги и прочие начальные значения. Поскольку при создании мы работаем с очередью готовых потоков, которую использует планировщик в произвольное время, мы должны заблокировать работу планировщика со структурой потока, пока вся структура не будет инициализирована полностью. После инициализации поток оказывается в состоянии waiting, которое, как мы помним, в том числе отвечает и за начальное состояние. После этого, в зависимости от переданных параметров, либо запускаем поток, либо нет. Функция запуска потока — это функция запуска/пробуждения в планировщике, она подробно описана ниже. Сейчас же скажем только, что эта функция помещает поток в очередь планировщика и меняет состояние waiting на ready.
Итак, код функции thread_create и thread_init:
Режим ожидания
Поток может отдать свое время другому потоку по каким-либо причинам, например, вызвав функцию sleep. То есть текущий поток переходит из рабочего режима в режим ожидания. Если в случае с невытесняющим планировщиком мы просто ставили флаг активности, то здесь мы сохраним наш поток в другой очереди. Ждущий поток не кладется в очередь планировщика. Чтобы не потерять поток, он, как правило, сохраняется в специальную очередь. Например, при попытке захватить занятый мьютекс поток, перед тем как заснуть, помещает себя в очередь ждущих потоков мьютекса. И когда произойдет событие, которое ожидает поток, например, освобождение мьютекса, оно его разбудит и мы сможем вернуть поток обратно в очередь готовых. Подробнее про ожидание и подводные камни расскажем ниже, уже после того, как разберемся с кодом самого планировщика.
Завершение потока
Здесь поток оказывается в завершающем состоянии wait. Если поток выполнил функцию обработки и завершился естественным образом, необходимо освободить ресурсы. Про этот процесс я уже подробно описала, когда говорила об избыточности состояния exit. Посмотрим же теперь на реализацию этой функции.
Трамплин для вызова функции обработки
Мы уже не раз говорили, что, когда поток завершает исполнение, он должен освободить ресурсы. Вызывать функцию thread_exit самостоятельно не хочется — очень редко нужно завершить поток в исключительном порядке, а не естественным образом, после выполнения своей функции. Кроме того, нам нужно подготовить начальный контекст, что тоже делать каждый раз — излишне. Поэтому поток начинает не с той функции, что мы указали при создании, а с функции-обертки thread_trampoline. Она как раз служит для подготовки начального контекста и корректного завершения потока.
Резюме: описание структуры потока
- информацию о регистрах процессора (контексте).
- информацию о состоянии задачи, готова ли она к выполнению или, например, ждет освобождения какого-либо ресурса.
- идентификатор. В случае с массивом это индекс в массиве, но если потоки могут добавляться и удаляться, то лучше использовать очередь, где идентификаторы и пригодятся.
- функцию старта и ее аргументы, возможно, даже и возвращаемый результат.
- адрес куска памяти, который выделен под стек, поскольку при выходе из потока его нужно освободить.
Cоотвественно, описание структуры у нас в проекте выглядит следующим образом:
В структуре есть поля не описанные в статье (sigstate, local, cleanups) они нужны для поддержки полноценных POSIX потоков (pthread) и в рамках данной статьи не принципиальны.
Планировщик и стратегия планирования
Напомним, что теперь у нас есть структура потока, включающая в том числе контекст, этот контекст мы умеем переключать. Кроме того, у нас есть системный таймер, который отмеряет кванты времени. Иными словами, у нас готово окружение для работы планировщика.
Задача планировщика — распределять время процессора между потоками. У планировщика есть очередь готовых потоков, которой он оперирует для определения следующего активного потока. Правила, по которым планировщик выбирает очередной поток для исполнения, будем называть стратегией планирования. Основная функция стратегии планирования — работа с очередью готовых потоков: добавление, удаление и извлечение следующего готового потока. От того, как будут реализованы эти функции, будет зависеть поведение планировщика. Поскольку мы смогли определить отдельное понятие — стратегию планирования, вынесем его в отдельную сущность. Интерфейс мы описали следующим образом:
Рассмотрим реализацию стратегии планирования поподробнее.
Пример стратегии планирования
В качестве примера я разберу самую примитивную стратегию планирования, чтобы сосредоточиться не на тонкостях стратегии, а на особенностях вытесняющего планировщика. Потоки в этой стратегии буду обрабатываться в порядке очереди без учета приоритета: новый поток и только что отработавший свой квант помещаются в конец; поток, который получит ресурсы процессора, будет доставаться из начала.
Очередь будет представлять из себя обычный двусвязный список. Когда мы добавляем элемент, мы вставляем его в конец, а когда достаем — берем и удаляем из начала.
Планировщик
Теперь мы перейдем к самому интересному — описанию планировщика.
Запуск планировщика
Первый этап работы планировщика — его инициализация. Здесь нам необходимо обеспечить корректное окружение планировщику. Нужно подготовить очередь готовых потоков, добавить в эту очередь поток idle и запустить таймер, по которому будут отсчитываться кванты времени для исполнения потоков.
Код запуска планировщика:
Пробуждение и запуск потока
Как мы помним из описания машины состояний, пробуждение и запуск потока для планировщика — это один и тот же процесс. Вызов этой функции есть в запуске планировщика, там мы запускаем поток idle. Что, по сути дела, происходит при пробуждении? Во-первых, снимается пометка о том, что мы ждем, то есть поток больше не находится в состоянии waiting. Затем возможны два варианта: успели мы уже уснуть или еще нет. Почему это происходит, я опишу в следующем разделе “Ожидание”. Если не успели, то поток еще находится в состоянии ready, и в таком случае пробуждение завершено. Иначе мы кладем поток в очередь планировщика, снимаем пометку о состоянии waiting, ставим ready. Кроме того, вызывается перепланирование, если приоритет пробужденного потока больше текущего. Обратите внимание на различные блокировки: все действо происходит при отключенных прерываниях. Для того, чтобы посмотреть, как пробуждение и запуск потока происходит в случае SMP, советую вам обратиться к коду проекта.
Ожидание
Переход в режим ожидания и правильный выход из него (когда ожидаемое событие, наконец, случится), вероятно, самая сложная и тонкая вещь в вытесняющем планировании. Давайте рассмотрим ситуацию поподробнее.
Прежде всего, мы должны объяснить планировщику, что мы хотим дождаться какого-либо события, причем событие происходит естественно асинхронного, а нам нужно его получить синхронно. Следовательно, мы должны указать, как же планировщик определит, что событие произошло. При этом мы не знаем, когда оно может произойти, например, мы успели сказать планировщику, что ждем события, проверили, что условия его возникновения еще не выполнены, и в этот момент происходит аппаратное прерывание, которое и вырабатывает наше событие. Но поскольку мы уже выполнили проверку, то эта информация потеряется. У нас в проекте мы решили данную проблему следующим образом.
Код макроса ожидания
Поток у нас может находиться сразу в суперпозиции состояний. То есть когда поток засыпает, он все еще является активным и всего лишь выставляет дополнительный флаг waiting. Во время пробуждения опять же просто снимается этот флаг, и только если поток уже успел дойти до планировщика и покинуть очередь готовых потоков, он добавляется туда снова. Если рассмотреть описанную ранее ситуацию на картинке, то получится следующая картина. 
A — active
R — ready
W — wait
На картинке буквами обозначено наличие состояний. Светло-зеленый цвет — состояние потока до wait_prepare, зеленый — после wait_prepare, а темно-зеленый — вызов потоком перепланирования.
Если событие не успеет произойти до перепланирования, то все просто — поток уснет и будет ждать пробуждения: 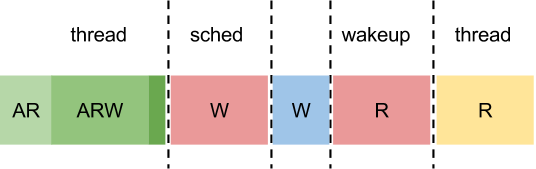
Перепланирование
Основная задача планировщика — планирование, прошу прощения за тавтологию. И мы наконец подошли к моменту когда можно разобрать как этот процесс реализован у нас в проекте.
Во-первых перепланирование должно выполняться при заблокированном планировщике. Во-вторых мы хотим дать возможность разрешить вытеснение потока или нет. Поэтому мы вынесли логику работы в отдельную функцию окружили ее вызов блокировками и вызвали ее указав, что в этом месте мы не позволяем вытеснение.
Далее идут действия с очередью готовых потоков. Если активный на момент перепланирования потока не собирается уснуть, то есть если у него не выставлено состояние waiting, мы просто добавим его в очередь потоков планировщика. Затем мы достаем самый приоритетный поток из очереди. Правила нахождения этого потока реализуются с помощью стратегии планирования.
Затем если текущий активный поток совпадает с тем который мы достали из очереди, нам не нужно перепланирование и мы можем просто выйти и продолжить выполнение потока. В случае же если требуется перепланирование, вызывается функция sched_switch, в которой выполняются действия необходимые планировщику и главное вызывается context_switch который мы рассматривали выше.
Если же поток собирается уснуть, находится в состоянии waiting, то он не попадает в очередь планировщика, и с него снимают метку ready.
В конце происходит обработка сигналов, но как я отмечала выше, это выходит за рамки данной статьи.
Проверка работы многопоточности
В качестве примера я использовала следующий код:
Собственно, это почти обычное приложение. Макрос EMBOX_EXAMPLE(run) задает точку входа в специфичный тип наших модулей. Функция thread_join дожидается завершения потока, пока я ее тоже не рассматривала. И так уже очень много получилось для одной статьи.
Результат запуска этого примера на qemu в составе нашего проекта следующий 
Как видно из результатов, сначала созданные потоки выполняются один за другим, планировщик дает им время по очереди. В конце некоторое расхождение. Я думаю, это следствие того, что у планировщика достаточно грубая точность (не сопоставимая с выводом одного символа на экран). Поэтому на первых проходах потоки успевают выполнить разное количество циклов.
В общем, кто хочет поиграться, можно скачать проект и попробовать все вышеописанное на практике.
Если тема интересна, я попробую продолжить рассказ о планировании, еще достаточно много тем осталось не раскрытыми.
Многозадачность компьютера — Computer multitasking
Одновременное выполнение нескольких процессов  Современные настольные операционные системы способны обрабатывать большое количество различных процессов одновременно. На этом снимке экрана показан Linux Mint, одновременно работающий Xfce среда рабочего стола, Firefox, программа-калькулятор, встроенный календарь, GIMP и VLC media player.
Современные настольные операционные системы способны обрабатывать большое количество различных процессов одновременно. На этом снимке экрана показан Linux Mint, одновременно работающий Xfce среда рабочего стола, Firefox, программа-калькулятор, встроенный календарь, GIMP и VLC media player. Возможности многозадачности Microsoft Windows 1.0 1, выпущенной в 1985 году, здесь показано выполнение программ MS-DOS Executive и Calculator
Возможности многозадачности Microsoft Windows 1.0 1, выпущенной в 1985 году, здесь показано выполнение программ MS-DOS Executive и Calculator
В вычислениях, многозадачность — это одновременное выполнение нескольких задач (также известных как процессы ) в течение определенного периода времени. Новые задачи могут прерывать уже начатые до их завершения, а не ждать их завершения. В результате компьютер выполняет сегменты множества задач с чередованием, в то время как задачи совместно используют общие ресурсы обработки, такие как центральные процессоры (CPU) и основная память. Многозадачность автоматически прерывает запущенную программу, сохраняя ее состояние (частичные результаты, содержимое памяти и содержимое регистров компьютера) и загружая сохраненное состояние другой программы и передавая ей управление. Этот «переключатель контекста » может быть инициирован через фиксированные интервалы времени (упреждающий многозадачный режим ), или выполняющаяся программа может быть закодирована так, чтобы сигнализировать управляющему программному обеспечению, когда она может быть прервана ( совместная многозадачность ).
Многозадачность не требует параллельного выполнения нескольких задач в одно и то же время; вместо этого он позволяет продвигаться более чем одной задаче за определенный период времени. Даже на многопроцессорных компьютерах многозадачность позволяет выполнять гораздо больше задач, чем есть ЦП.
Многозадачность — обычная черта компьютерных операционных систем. Это позволяет более эффективно использовать компьютерное оборудование; если программа ожидает какого-либо внешнего события, такого как ввод пользователя или передача ввода / вывода с периферийным устройством для завершения, центральный процессор все еще может использоваться с другой программой. В системе с разделением времени несколько человек-операторов используют один и тот же процессор, как если бы он был выделен для их использования, в то время как за кулисами компьютер обслуживает множество пользователей, выполняя их отдельные программы одновременно. В многопрограммных системах задача выполняется до тех пор, пока ей не придется ждать внешнего события или пока планировщик операционной системы принудительно не выгрузит текущую задачу из ЦП. Системы реального времени, например, системы, предназначенные для управления промышленными роботами, требуют своевременной обработки; один процессор может использоваться совместно для вычислений движения машины, обмена данными и пользовательского интерфейса.
Часто многозадачные операционные системы включают меры по изменению приоритета отдельных задач, так что важные задания получают больше процессорного времени, чем те, которые считаются меньшими значительное. В зависимости от операционной системы задача может быть такой же большой, как вся прикладная программа, или может состоять из более мелких потоков, которые выполняют части всей программы.
Процессор, предназначенный для использования с многозадачными операционными системами, может включать в себя специальное оборудование для безопасной поддержки нескольких задач, например защита памяти и защитные кольца, которые обеспечивают работу программного обеспечения надзора. не может быть поврежден или нарушен программными ошибками пользовательского режима.
Термин «многозадачность» стал международным термином, так как это же слово используется во многих других языках, таких как немецкий, итальянский, голландский, датский и норвежский.
Содержание
- 1 Мультипрограммирование
- 2 Кооперативная многозадачность
- 3 Вытесняющая многозадачность
- 4 Реальное время
- 5 Многопоточность
- 6 Защита памяти
- 7 Перестановка памяти
- 8 Программирование
- 9 См. Также
- 10 Ссылки
Мультипрограммирование
В первые дни вычислений время процессора было дорогим, а периферийные устройства работали очень медленно. Когда компьютер запускал программу, которой требовался доступ к периферийному устройству, центральный процессор (ЦП) должен был бы прекратить выполнение программных инструкций, пока периферийное устройство обрабатывает данные. Обычно это было очень неэффективно.
Первым компьютером, использующим систему мультипрограммирования, был британский Leo III, принадлежавший Дж. Lyons and Co. Во время пакетной обработки в память компьютера было загружено несколько различных программ, и первая из них начала выполняться. Когда первая программа достигла инструкции, ожидающей периферийного устройства, контекст этой программы сохранялся, а второй программе в памяти давалась возможность выполнить. Процесс продолжался до тех пор, пока все программы не завершили работу.
Использование мультипрограммирования было расширено с появлением технологии виртуальной памяти и виртуальной машины, которые позволили отдельным программам выполнять использование памяти и ресурсов операционной системы, как если бы другие одновременно выполняющиеся программы были для всех практических целей не существующими и невидимыми для них.
Мультипрограммирование не дает никаких гарантий, что программа будет выполняться своевременно. Действительно, первая программа вполне может работать часами, не требуя доступа к периферийным устройствам. Поскольку у интерактивного терминала не было пользователей, ожидавших результатов, это не было проблемой: пользователи передавали колоду перфокарт оператору и возвращались через несколько часов для распечатки результатов. Мультипрограммирование значительно сокращало время ожидания при обработке нескольких пакетов.
Совместная многозадачность
Ранние многозадачные системы использовали приложения, которые добровольно уступали время друг другу. Этот подход, который в конечном итоге был поддержан многими компьютерными операционными системами, сегодня известен как совместная многозадачность. Хотя сейчас она редко используется в более крупных системах, за исключением конкретных приложений, таких как CICS или JES2 подсистема, совместная многозадачность когда-то была единственной схемой планирования, используемой Microsoft Windows и Classic Mac OS для одновременного запуска нескольких приложений. Кооперативная многозадачность до сих пор используется в системах RISC OS.
Поскольку кооперативная многозадачная система полагается на то, что каждый процесс регулярно передает время другим процессам в системе, одна плохо спроектированная программа может потреблять все процессорного времени для себя, либо путем выполнения обширных вычислений, либо путем ожидание занятости ; оба приведут к зависанию всей системы. В серверной среде это опасность, которая делает всю среду неприемлемо хрупкой.
Вытесняющая многозадачность
Вытесняющая многозадачность позволяет компьютерной системе более надежно гарантировать каждому процессу регулярный «кусок» рабочего времени. Это также позволяет системе быстро обрабатывать важные внешние события, такие как входящие данные, которые могут потребовать немедленного внимания того или иного процесса. Операционные системы были разработаны для использования этих аппаратных возможностей и упреждающего запуска нескольких процессов. Вытесняющая многозадачность была реализована в PDP-6 Monitor и MULTICS в 1964 году, в OS / 360 MFT в 1967 году и в Unix в 1969 году и был доступен в некоторых операционных системах для компьютеров размером с PDP-8 от DEC; это основная функция всех Unix-подобных операционных систем, таких как Linux, Solaris и BSD с его производными, а также современные версии Windows.
В любой конкретный момент процессы можно сгруппировать в две категории: те, которые ожидают ввода или вывода (так называемые «привязка ввода-вывода »), и те, которые полностью используют ЦП («Ограничение ЦП «). В примитивных системах программное обеспечение часто «poll » или «busywait «, ожидая запрошенного ввода (такого как ввод с диска, клавиатуры или сети). В это время система не выполняла полезную работу. С появлением прерываний и вытесняющей многозадачности процессы, связанные с вводом-выводом, могли быть «заблокированы» или приостановлены в ожидании поступления необходимых данных, позволяя другим процессам использовать ЦП. Поскольку поступление запрошенных данных привело бы к прерыванию, заблокированным процессам можно было бы гарантировать своевременный возврат к выполнению.
Самой ранней операционной системой с вытесняющей многозадачностью, доступной домашним пользователям, была Sinclair QDOS на Sinclair QL, выпущен в 1984 году, но мало кто покупал машину. Commodore Amiga, выпущенная в следующем году, была первым коммерчески успешным домашним компьютером, использующим эту технологию, а его мультимедийные возможности сделали его явным предком современных многозадачных персональных компьютеров. Microsoft сделала вытесняющую многозадачность основной функцией своей флагманской операционной системы в начале 1990-х при разработке Windows NT 3.1, а затем Windows 95. Позже он был принят на Apple Macintosh в Mac OS X, которая, как Unix-подобная операционная система, использует вытесняющую многозадачность для всех собственных приложений.
Подобная модель используется в Windows 9x и семействе Windows NT, где собственные 32-разрядные приложения выполняют многозадачность с вытеснением. 64-разрядные версии Windows для архитектур x86-64 и Itanium больше не поддерживают устаревшие 16-разрядные приложения и, таким образом, обеспечивают вытесняющую многозадачность для всех поддерживаемых приложений.
Реальное время
Другая причина для многозадачности заключалась в разработке вычислительных систем в реальном времени, где есть ряд, возможно, не связанных внешних действий, которые необходимо контролировать однопроцессорная система. В таких системах иерархическая система прерываний сочетается с приоритизацией процессов, чтобы гарантировать, что ключевым действиям будет отведена большая часть доступного времени процесса.
Многопоточность
Поскольку многозадачность значительно повысила производительность компьютеров, программисты начали для реализации приложений как наборов взаимодействующих процессов (например, один процесс собирает входные данные, один процесс обрабатывает входные данные, один процесс записывает результаты на диск). Однако для этого потребовались некоторые инструменты, позволяющие процессам эффективно обмениваться данными.
Потоки возникли из идеи, что наиболее эффективным способом взаимодействия процессов для обмена данными было бы совместное использование всего их пространства памяти. Таким образом, потоки фактически являются процессами, которые выполняются в одном контексте памяти и совместно используют другие ресурсы со своими родительскими процессами, например, открытые файлы. Потоки описываются как облегченные процессы, поскольку переключение между потоками не связано с изменением контекста памяти.
Хотя потоки планируются с упреждением, некоторые операционные системы предоставляют вариант для потоков, называемых волокнами, которые являются планируется кооперативно. В операционных системах, которые не предоставляют волокна, приложение может реализовать свои собственные волокна, используя повторяющиеся вызовы рабочих функций. Волокна даже более легкие, чем потоки, и с ними несколько легче программировать, хотя они, как правило, теряют некоторые или все преимущества потоков на машинах с несколькими процессорами.
Некоторые системы напрямую поддерживают многопоточность на оборудовании.
Защита памяти
Для любой многозадачной системы важно безопасно и эффективно совместно использовать доступ к системным ресурсам. Доступ к памяти должен строго управляться, чтобы гарантировать, что ни один процесс не может случайно или намеренно прочитать или записать в области памяти за пределами адресного пространства процесса. Это делается с целью общей стабильности системы и целостности данных, а также безопасности данных.
В общем, управление доступом к памяти является обязанностью ядра операционной системы в сочетании с аппаратными механизмами, обеспечивающими вспомогательные функции, такими как блок управления памятью (MMU). Если процесс пытается получить доступ к области памяти за пределами своего пространства памяти, MMU отклоняет запрос и сигнализирует ядру о необходимости предпринять соответствующие действия; обычно это приводит к принудительному прекращению процесса нарушения. В зависимости от программного обеспечения и архитектуры ядра, а также от конкретной рассматриваемой ошибки пользователь может получить сообщение об ошибке нарушения прав доступа, такое как «ошибка сегментации».
В хорошо спроектированной и правильно реализованной многозадачной системе данный процесс никогда не может напрямую обращаться к памяти, принадлежащей другому процессу. Исключением из этого правила является общая память; например, в механизме межпроцессного взаимодействия System V ядро выделяет память для совместного использования несколькими процессами. Такие функции часто используются программным обеспечением для управления базами данных, например PostgreSQL.
Неадекватные механизмы защиты памяти, вызванные либо недостатками в их конструкции, либо плохой реализацией, допускают уязвимости системы безопасности, которые могут быть потенциально использованы вредоносным ПО.
Подкачка памяти
Использование файла подкачки или раздела подкачки — это способ для операционной системы предоставить больше памяти, чем физически доступно, за счет сохранения частей первичной памяти в вторичной памяти. Хотя многозадачность и подкачка памяти — это два совершенно не связанных между собой техники, они очень часто используются вместе, поскольку подкачка памяти позволяет загружать больше задач одновременно. Как правило, многозадачная система позволяет запускать другой процесс, когда выполняющийся процесс достигает точки, когда ему приходится ждать, пока некоторая часть памяти будет перезагружена из вторичного хранилища.
Программирование
Процессы, которые являются полностью независимые программы не представляют больших проблем для программирования в многозадачной среде. Большая часть сложности в многозадачных системах возникает из-за необходимости разделять ресурсы компьютера между задачами и синхронизировать работу взаимодействующих задач.
Для предотвращения потенциальных проблем используются различные параллельные вычисления. вызвано несколькими задачами, пытающимися получить доступ к одному и тому же ресурсу.
Более крупные системы иногда строились с центральным процессором (-ами) и некоторым количеством процессоров ввода-вывода, что-то вроде асимметричного многопроцессорность.
С годами многозадачные системы совершенствовались. Современные операционные системы обычно включают подробные механизмы для приоритезации процессов, в то время как симметричная многопроцессорная обработка привнесла новые сложности и возможности.
Иллюстрированный самоучитель по теории операционных систем
Если система программирования предполагает, что при вызове функции должны сохраняться определенные регистры (как, например, С-компиляторы для х86 сохраняют при вызовах регистры SI и DI (ESI/EDI в 1386)), то они также сохраняются в стеке. Поэтому предложенный нами вариант также будет автоматически сохранять и восстанавливать все необходимые регистры.
Понятно, что кроме указателей стека и стекового кадра, struct Thread должна содержать еще некоторые поля. Как минимум, она должна содержать указатель на следующую активную нить. Система должна хранить указатели на описатель текущей нити и на конец списка. При этом ThreadSwitch переставляет текущую нить в конец списка, а текущей делает следующую за ней в списке. Все вновь активизируемые нити также ставятся в конец списка. При этом список не обязан быть двунаправленным, ведь мы извлекаем элементы только из начала, а добавляем только в конец.
Часто в литературе такой список называют очередью нитей (thread queue) или очередью процессов. Такая очередь присутствует во всех известных автору реализациях многозадачных систем. Кроме того, очереди нитей используются и при организации очередей ожидания различных событий, например, при реализации семафоров Дейкстры.
Планировщик, основанный на Threadswitch, т. е. на принципе переключения по инициативе активной нити, используется в ряде экспериментальных и учебных систем. Этот же принцип, называемый кооперативной многозадачностью, реализован в библиотеках языков Simula 67 и Modula-2. MS Windows 3.x также имеют средство для организации кооперативного переключения задач – системный вызов GetNextEvent.
Часто кооперативные нити называют не нитями, а сопрограммами – ведь они вызывают друг друга, подобно подпрограммам. Единственное отличие такого вызова от вызова процедуры состоит в том, что такой вызов не иерархичен – вызванная программа может вновь передать управление исходной и остаться при этом активной.
Основным преимуществом кооперативной многозадачности является простота отладки планировщика. Кроме того, снимаются все коллизии, связанные с критическими секциями и тому подобными трудностями – ведь нить может просто не отдавать никому управления, пока не будет готова к этому.
С другой стороны, кооперативная многозадачность имеет и серьезные недостатки.
Во-первых, необходимость включать в программу вызовы Threadswitch усложняет программирование вообще и перенос программ из однозадачных или иначе организованных многозадачных систем в частности.
Особенно неприятно требование регулярно вызывать Threadswitch для вычислительных программ. Чаще всего такие программы исполняют относительно короткий внутренний цикл, скорость работы которого определяет скорость всей программы. Для "плавной" многозадачности необходимо вызывать Threadswitch из тела этого цикла. Делать вызов на каждом шаге Цикла нецелесообразно, поэтому необходимо будет написать код, похожий на приведенный в примере 8.2.
Пример 8.2. Внутренний цикл программы в кооперативно многозадачной среде.
Условный оператор и вызов функции во внутреннем цикле сильно усложняют работу оптимизирующим компиляторам и приводят к разрывам конвейера команд, что может очень заметно снизить производительность. Вызов функции на каждом шаге цикла приводит к еще большим накладным расходам и, соответственно, к еще большему замедлению.
Во-вторых, злонамеренная нить может захватить управление и никому не отдавать его. Просто не вызывать ThreadSwitch, и все. Это может произойти не только из-за злых намерений, но и просто по ошибке.
Поэтому такая схема оказывается непригодна для многопользовательских систем и часто не очень удобна для интерактивных однопользовательских.
Почему-то большинство коммерческих программ для Win16, в том числе и поставлявшиеся самой фирмой Microsoft, недостаточно активно использовали вызов GetNextEvent. Вместо этого такие программы монопольно захватывали процессор и рисовали известные всем пользователям этой системы "песочные часы". В это время система никак не реагирует на запросы и другие действия пользователя кроме нажатия кнопки RESET или клавиш CTRL + ALT + DEL.
В-третьих, кооперативная ОС не может исполняться на симметричной многопроцессорной машине, а приложения, написанные в расчете на такую ОС, не могут воспользоваться преимуществами многопроцессорности.
Простой анализ показывает, что кооперативные многозадачные системы пригодны только для учебных проектов или тех ситуаций, когда программисту на скорую руку необходимо сотворить многозадачное ядро. Вторая ситуация кажется несколько странной – зачем для серьезной работы может потребоваться быстро сделанное ядро, если существует много готовых систем реального времени, а также общедоступных (freeware или public domain) в виде исходных текстов реализаций таких ядер?