Внешние и внутренние сетевые адаптеры для компьютера
Ни один современный персональный компьютер не может обойтись без такого элемента, как сетевая карта (сетевой или Ethernet-адаптер, сетевая плата). Что это такое, зачем нужна, принцип работы, основные характеристики модуля и многое другое, связанное с данным компонентом — в статье.
Ethernet-адаптер: что это и зачем нужен?
Сетевой модуль — важный узел персонального компьютерного устройства, позволяющий пользователю работать в интернете и (или) подсоединяться к локальной сети. Сетевые платы различаются между собой по типу, скорости, пропускным возможностям и другим характеристикам.
Кроме того существуют беспроводные сетевые адаптеры, позволяющие выполнить подключение к сети без использования проводов, по Wi-Fi. Скорость приёма/передачи при этом несколько снижается в сравнении с традиционным способом.

Принцип работы сетевой карты
Коротко принцип работы сетевой карты можно описать так:
- Компьютером, во время передачи, в память сетевой карты записывается информация, которую необходимо обработать. Чип сетевого адаптера постоянно проверяет ячейки своей памяти и обнаружив содержимое, начинает пересылать его на внешнее устройство. Информация при этом кодируется в набор нулей и единиц (так называемый «манчестерский код»).
- Во время приёма сигнал, появившийся на входе приёмника, дешифруется и переносится в память сетевой карты. Одновременно компьютер получает «извещение» о том, что принятые байты нужно срочно забрать и обработать.
- При наличии и при отсутствии приёма/передачи сетевой адаптер посылает контрольные сигналы-импульсы на коммутационное устройство с целью проверки связи.
Основные характеристики
Помимо форм-фактора и интерфейса для подключения, сетевые адаптеры имеют множество других характеристик. Важнейшей из них является скорость приёма/передачи данных, которая в современных моделях достигает 1000 Мбит в секунду.
Среди прочих параметров, наличие или отсутствие которых напрямую отражается на стоимости устройства, можно выделить:
- удалённое пробуждение (Wake-on-LAN) — даёт возможность удалённого включения компьютера;
- опция Jumbo Frame — увеличивает размер пакетов, обрабатываемых системой, снижая нагрузку на процессор;
- величина буферной памяти — чем она больше, тем производительней карта;
- совместимость драйверов — многие сетевые карты работают только с Windows не поддерживаются Linux-системами.
Типы Ethernet-устройств по способу подключения
Все современные сетевые адаптеры можно разделить на три типа по способу подключения: интегрированные, внутренние и внешние. Рассмотрим отдельно каждую категорию.
Интегрированные модули
Сегодня уже, наверное, невозможно встретить системную плату персонального компьютерного устройства без интегрированного сетевого контроллера. В зависимости от девайса, интегрированный модуль может иметь порт Ethernet (тип разъёма — RJ-45) для подключения кабелем либо содержать модуль Wi-Fi для беспроводной связи.
Несомненным плюсом встроенной карты является её хорошая совместимость с другим «железом», в частности, с узлами материнской платы. Среди других положительных сторон интегрированного сетевого контроллера можно выделить отсутствие проблем с драйверами, а также то, что он не занимает слоты расширения в системной плате и порты USB.
Существенным минусом встроенного адаптера является его фактическая неремонтопригодность в случае поломки. Даже если в сервисе и возьмутся за замену контроллера, ремонт может вылиться в круглую сумму. Выходом из ситуации является использование встраиваемых внутренних и внешних модулей.
Встраиваемые платы
Так же как и интегрированные модули, встраиваемые сетевые карты могут быть предназначены как для проводного, так и беспроводного соединения. В первом случае адаптер содержит, как правило, один разъём RJ-45, во втором его выделяет наличие антенны.
Существуют сетевые карты с устаревшим PCI и более современным PCI-E интерфейсом. Оба варианта предназначены для монтажа в соответствующие слоты материнской платы компьютера. Следует иметь в виду, что эти два стандарта не совместимы между собой, то есть карта с PCI-разъёмом не подойдёт к ПК с PCI-E-слотом, и наоборот.
Среди достоинств встраиваемых внутренних модулей — наличие опции автоматического определения и включения Plug and Play, большая база драйверов, широкий выбор устройств на рынке и их низкая стоимость. Среди недостатков — нужны некоторые знания для установки и настройки, кроме того драйвера многих встраиваемых карт пишутся программистами исключительно под Windows.
Внешний Ethernet-адаптер
Внешний сетевой адаптер представляет собой отдельное устройство в корпусе, подключаемое к USB-портам ПК или ноутбука. Такие модули бывают со стандартным портом Ethernet для проводного соединения и блоком Wi-Fi для беспроводного подключения. USB-сетевые карты с Wi-Fi в последние годы пользуются большой популярностью у пользователей благодаря мобильности, универсальности и простоте в использовании.
В современных операционных системах настройка внешнего адаптера для проводного подключения происходит в автоматическом режиме, что является несомненным плюсом таких карт. Ситуация с адаптерами Wi-Fi менее радужная, особенно в отношении среды Linux. Часто от пользователей требуются дополнительные шаги по их настройке.
Тем не менее, внешние сетевые карты — незаменимое решение во многих случаях. Например, когда сгорел интегрированный в устройство модуль, а в системном блоке все слоты уже заняты, либо просто необходимо подключение «по воздуху».

Выбор сетевой карты
Сегодня компьютерный рынок заполнен встраиваемыми и внешними сетевыми картами разных типов, конфигураций и ценовых диапазонов. Но прежде чем идти в магазин за адаптером, необходимо определиться с несколькими моментами:
- каким образом будет осуществляться доступ в сеть — по кабелю или через Wi-Fi;
- есть ли в компьютере или ноутбуке порты для подключения и какие — PCI, PCI-E, USB;
- финансовая составляющая.
Подключение карты через интерфейсы PCI, PCI-E в лучшую сторону отражается на скорости, однако для этого придётся разбирать системный блок и устанавливать модуль. Конечно, данную работу можно доверить специалисту, но за установку придётся платить. С подключением USB-адаптера справится даже начинающий пользователь.
Чем больше функций в адаптере (зачастую не нужных обычному пользователю), тем он дороже. Это также следует учитывать при покупке сетевой карты. Кроме того, потребитель часто и не всегда обосновано переплачивает за бренд.
Где расположен Ethernet-модуль?
Разыскать установленный сетевой адаптер в компьютере не сложно. В случае с проводной картой на ней присутствует стандартный порт формата RJ-45. Если модуль беспроводный, ориентироваться следует на антенну — обычно это штырьковый вариант, как на Wi-Fi роутере.
В интегрированном варианте перечисленные компоненты расположены на материнской плате. Встроенный модуль представляет собой плату, установленную в один из слотов расширения. USB-контроллер подключен в соответствующее гнездо системного блока ПК.
Как установить и настроить адаптер?
Установка USB модуля в ПК или ноутбук предельно проста — его нужно просто подключить к соответствующему порту. Монтаж внутренней карты немного сложнее — для этого необходимо снять крышку с системного блока, вставить плату в соответствующий слот и прикрутить монтажную планку винтом. Все манипуляции осуществляются при выключенном ПК.
Настройка беспроводного адаптера обычно сводится к введению кода доступа к сети. Иногда может потребоваться установка драйверов. Сделать это можно, воспользовавшись диском с программным обеспечением, прилагаемым к устройству, либо скачав софт с официального сайта производителя, действуя по инструкциям, которые обычно можно найти здесь же.
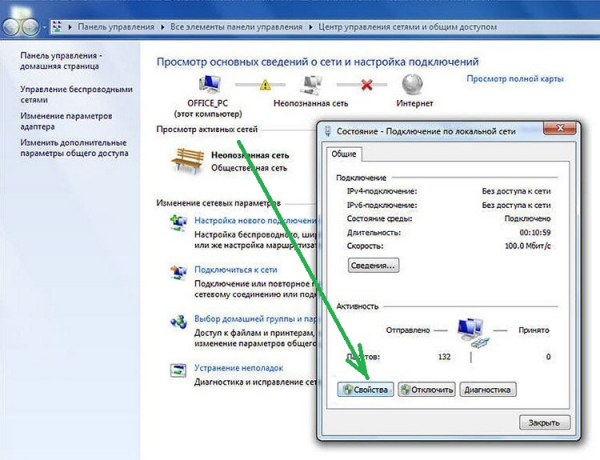
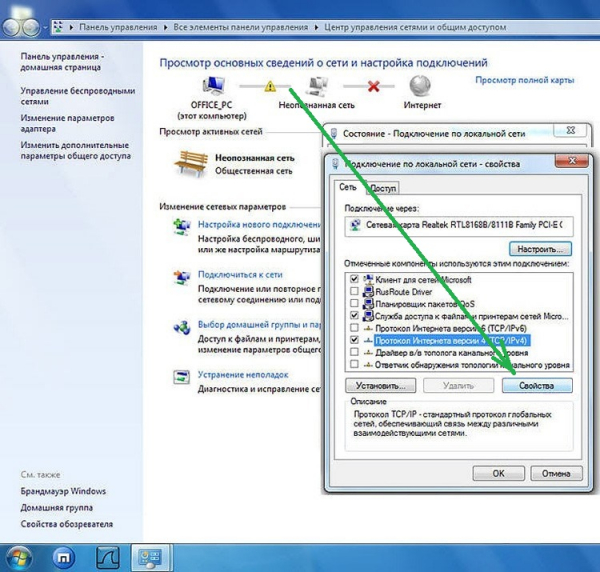
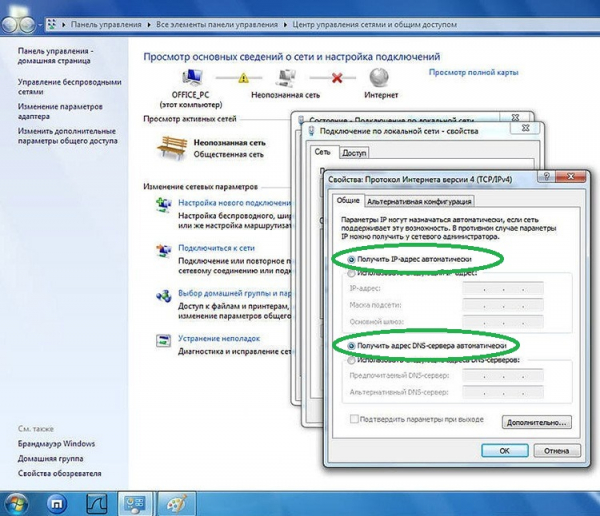
Настройка проводной карты заключается в получении IP-адреса. Сделать это можно как в ручном режиме, так и автоматическом. Ручная настройка при установке новой карты, как правило, не требуется, в данном случае предпочтительнее автоматический вариант:
-
Для автонастройки сетевой платы зайдите в «Панель управления» (сделать это можно через меню «Пуск»). Найдите и запустите «Центр управления сетями и общим доступом». Щёлкните по значку сетевого соединения и в новом окне нажмите кнопку «Свойства».
ПК не распознаёт девайс, что предпринять?
Ситуация, когда компьютер или ноутбук не видят сетевой модуль, весьма распространённая, и в большинстве случаев она может быть связана с драйверами. Кроме того, девайс может не распознать адаптер по следующим причинам:
- устройство отключено в БИОС;
- присутствуют механические неполадки (например, карта плохо вставлена в слот);
- на компьютере присутствуют вирусы.
Топ-10 популярных адаптеров
Статья про сетевые карты была бы неполной без рассмотрения лучших представителей данной категории девайсов. Информация ниже позволит вам сориентироваться в популярных моделях, их характеристиках и примерной стоимости.
Устройство Сетевой Карты

Сетевые карты отвечают за передачу информации между единицами сети. Любая сетевая карта состоит из разъема для сетевого проводника и микропроцессора, что кодирует\декодирует сетевые пакеты, а так же вспомогательных программно-аппаратных комплексов и служб. Каждая карта имеет свой Mac адрес — уникальный идентификатор устройства.
PCI BUS-Mastering
Данная функция относится не только к сетевым картам, и означает возможность пересылки данных устройством, без участия центрального процессора. С чисто практической точки зрения наличие Bus Mastering означает, что у вас будет меньше тормозить система при копировании данных по сети. При этом на сетевой карте должны быть распаяны схемы, позволяющие осуществлять прямую передачу информации, это усложняет конструкцию и повышает стоимость адаптера. Поэтому на некоторых дешевых сетевых адаптерах Bus Mustering отсутствует, чем-то это напоминает различие программных и аппаратных модемов. По возможности стоит приобретать сетевые карты, поддерживающие данную функцию, особенно на слабых системах, а так же на сервере, ему процессорные мощности пригодятся для других задач.
Совет: На некоторых сетевых картах имеется дополнительный сопроцессор, выполняющий основные функции по обработке сетевых пакетов, призванный дополнительно разгрузить CPU, однако по умолчанию в Windows 2000\XP он не задействован. Чтобы включить его, надо в разделе реестра
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters создать dword-параметр «DisableTaskOffload» и присвоить ему значение 0.
Или просто скачайте и подключите следующую ветку реестра: Lan_Cpu_setup.zip
BootRom
Возможность загрузки системы по сети заложена в виде Boot Rom сетевой карты. Это микросхема энергонезависимой памяти, где хранится код загрузчика.
Он выполняет поиск в сети сервера и запрашивает у него IP адрес, а так же путь, где можно получить образ операционной системы. После того, как образ загружен и размещен в оперативной памяти, дальнейшее управление загрузкой передается ему, точно так же, как при работе с обычной загрузочной дискетой или диском. Таким образом, при соответствующей настройке, ПК может работать вообще без жёсткого диска. Загрузка через сеть настраивается в BIOS материнских плат, которые поддерживают данную функцию. У дешёвых сетевых карт BootRom либо отсутствует вообще, либо под него есть разъем, но нет самой микросхемы. Как правило, эта функция в домашних сетях не требуется. BootRom применяется для создания системы терминалов, а так же реализации службы удаленной установки Windows.
Wake-on-Lan
Wake-on-lan — включение удалённой системы через сеть. Адаптер отслеживает сетевой траффик в ожидании специального Wake-пакета и при его получении пробуждает систему. При этом требуется, чтобы компьютер был с ATX-блоком питания, в настройках BIOS была разрешена активация компьютера по запросу с порта, на который установлена карта. Сетевая карта должна быть соединена соответствующим 3-жильным шнуром с Wol-разъемом на материнской плате. Местоположение разъема Wol различно на разных материнских платах, так что если не можете его найти, почитайте инструкцию. Если адаптер не комплектуется Wol-шнуром, вы можете купить его отдельно или сделать самостоятельно.
Русские Блоги
Сетевая интерфейсная карта (сокращенно NIC), также известная как сетевой адаптер, — это устройство, которое подключает компьютер к локальной сети. Будь то обычный компьютер или высокопроизводительный сервер, если он подключен к локальной сети, вам необходимо установить сетевую карту. При необходимости на компьютер также можно установить две и более сетевых карты одновременно.
Сетевая карта включает два уровня модели OSI, физический уровень и уровень канала передачи данных:
«1» Физический уровень определяет электрические и оптические сигналы, состояние линии, опорный сигнал, кодирование данных и схемы, необходимые для передачи и приема данных, и предоставляет стандартные интерфейсы для оборудования канального уровня.
«2» Уровень канала данных обеспечивает такие функции, как механизм адресации, построение фрейма данных, проверка ошибок данных, управление передачей и стандартный интерфейс данных с сетевым уровнем.
Два: роль группы сетевых карт
У сетевой карты две основные функции:
Первый — инкапсулировать компьютерные данные во фреймы и отправлять данные в сеть по сетевому кабелю (для беспроводных сетей это электромагнитные волны);
Второй — получить кадры от других устройств в сети, собрать кадры в данные и отправить их на компьютер, где они находятся.
Сетевая карта может принимать все сигналы, передаваемые по сети, но в обычных условиях она принимает только кадры и широковещательные кадры, отправленные на компьютер, и отбрасывает остальные. Затем он отправляется в ЦП системы для дальнейшей обработки. Когда компьютер отправляет данные, сетевая карта ждет подходящего времени, чтобы вставить пакет в поток данных. Принимающая система сообщает компьютеру, полностью ли доставлено сообщение, и, если есть проблема, она попросит другую сторону отправить его повторно.
Три: состав и принцип работы сетевой карты
В качестве примера возьмем наиболее распространенную сетевую карту с интерфейсом PCI:

Состав сетевой карты:
(1) Основная микросхема: основная микросхема управления сетевой карты является основным компонентом сетевой карты.Производительность и функции сетевой карты в основном зависят от качества микросхемы. Как показано ниже:

(2) Слот BOOTROM: разъем BOOTROM, также известный как интерфейс бездискового загрузочного ПЗУ, используется для создания бездисковых рабочих станций с помощью служб удаленной загрузки. Как показано ниже:

(3) Накачка данных: первая функция — передача данных; вторая — изоляция различных уровней между различными сетевыми устройствами, соединенными сетевым кабелем, и также может играть роль в защите устройства от молнии. Как показано ниже:

(4) Кварцевый генератор представляет собой кварцевый генератор, который обеспечивает опорную частоту, как показано на рисунке ниже:

(5) Светодиодный индикатор: используется для определения различного рабочего состояния сетевой карты, например, Link / Act означает состояние активности подключения, Full означает полный дуплекс, а Power означает источник питания.
(6) Интерфейс сетевого кабеля: есть интерфейс BNC и интерфейс RJ-45, в настоящее время в основном используется 8-ядерный интерфейс RJ-45.

(7) Интерфейс шины: используется для подключения сетевой карты к компьютеру, встроенная сетевая карта должна быть вставлена в слот расширения материнской платы компьютера через интерфейс шины, обычно известный как «золотой палец». В основном это ISA, PCI, PCMCIA и USB и др. Распространенными являются сетевые карты с интерфейсом шины PCI.
Четвертое: принцип работы сетевой карты
- Сетевая карта действует как физический интерфейс или соединение между компьютером и сетевым кабелем и отвечает за преобразование цифрового сигнала компьютера в электрический или оптический сигнал.
- Сетевая карта отвечает за преобразование между последовательными данными или параллельными данными.Данные передаются параллельно по компьютерной шине и передаются в последовательном потоке битов по физическому кабелю сети.
Микросхема канального уровня в карте Ethernet обычно называется контроллером MAC, а микросхема физического уровня называется PHY. Многие микросхемы сетевых карт реализуют функции MAC и PHY в одном чипе, например сетевая карта Intel 82559 и сетевая карта 3COM 3C905. Но механизмы MAC и PHY по-прежнему существуют отдельно, но внешний вид представляет собой одну микросхему. Конечно, есть также много сетевых карт, MAC и PHY которых выполняются отдельно, например, DFE-530TX от D-LINK.
1 MAC-контроллер канального уровня
Сначала поговорим о функции MAC-чипа Ethernet-карты. Уровень канала передачи данных Ethernet фактически включает в себя подуровень MAC (управление доступом к среде) и подуровень LLC (управление логическим каналом). Роль микросхемы MAC карты Ethernet заключается не только в реализации функций подуровня MAC и подуровня LLC, но и в обеспечении стандартизованного интерфейса PCI для обмена данными с хостом. После того, как MAC получает IP-пакеты данных (или пакеты данных других протоколов сетевого уровня) от шины PCI, он разделяет и переупаковывает их в кадр размером максимум 1518 байт и минимум 64 байта. Этот кадр включает MAC-адрес назначения, собственный MAC-адрес источника и тип протокола в пакете данных (например, тип пакета данных IP представлен как 80). Наконец, есть код CRC DWORD (4 байта). Но откуда взялся целевой MAC-адрес? Это включает протокол ARP (протокол между сетевым уровнем и уровнем канала данных). Когда данные определенного IP-адреса назначения передаются в первый раз, сначала будет отправлен ARP-пакет. MAC-адрес назначения является широковещательным адресом, и в нем говорится: «Кто является владельцем этого IP-адреса xxx.xxx.xxx.xxx?» "Поскольку это широковещательный пакет, все хосты в этой локальной сети получили этот запрос ARP. Хост, получающий запрос, сравнивает этот IP-адрес со своим собственным и игнорирует его, если он не совпадает, и отправляет пакет ответа ARP, если он такой же. В ответе ARP, на который узел этого IP-адреса отвечает после получения этого пакета запроса ARP, говорится: «Я являюсь владельцем этого IP-адреса». Этот пакет включает его MAC-адрес. Определяется MAC-адрес назначения последующих кадров для этого IP-адреса. (Другие протоколы, такие как IPX / SPX, также имеют соответствующие протоколы для выполнения этих операций.) Связь между IP-адресом и MAC-адресом хранится в хост-системе, называемой таблицей ARP, которая заполняется драйвером и операционной системой. В системе Microsoft вы можете использовать команду arp -a для просмотра таблицы ARP. То же самое верно и при получении кадра данных.После завершения CRC, если нет ошибки проверки CRC, заголовок кадра удаляется, а пакет данных вынимается и передается драйверу и отелю протокола верхнего уровня через стандартное оправдание, и, наконец, достигает нашего правильного применение. Есть также некоторые кадры управления, такие как кадры управления потоком, которые также требуют, чтобы MAC напрямую идентифицировал и выполнял соответствующие действия. Один конец микросхемы Ethernet MAC подключается к шине PCI компьютера, а другой конец — к микросхеме PHY. Физический уровень Ethernet включает в себя подуровень MII / GMII (независимый от среды интерфейс), подуровень PCS (подуровень физического кодирования), подуровень PMA (подключение к физической среде), подуровень PMD (связанный с физической средой) и подуровень MDI. Микросхема PHY является одним из важных функциональных устройств, которые реализуют физический уровень и реализуют все функции подуровня предыдущего физического уровня.
2 Физический уровень PHY
Когда PHY отправляет данные, он получает данные от MAC (для PHY нет концепции кадра, для него это данные независимо от адреса, данных или CRC), и обнаружение 1-битной ошибки добавляется на каждые 4 бита. Затем параллельные данные преобразуются в данные последовательного потока, и данные кодируются в соответствии с правилами кодирования физического уровня (кодирование 10Based-T NRZ или кодирование 100based-T Manchester), а затем преобразуются в аналоговые сигналы и отправляются. (Примечание: непросто понять, являются ли данные онлайн цифровыми или аналоговыми. Я скажу это в конце.) Процесс получения данных обратный. При отправке данных другой важной функцией PHY является реализация некоторых функций CSMA / CD. Он может определять, передаются ли данные по сети. Сетевая карта сначала слушает, есть ли на носителе носитель (носитель указывается напряжением), если да, считается, что другие станции передают информацию и продолжают прослушивать носитель. После того, как среда передачи данных не используется в течение определенного периода времени (называемого межкадровым интервалом IFG = 9,6 микросекунды), то есть она не занята другими станциями, начинается передача данных кадра, и среда передачи данных продолжает отслеживаться для обнаружения конфликтов. Во время передачи данных, если обнаруживается конфликт, передача немедленно останавливается, и на носитель отправляется сигнал «блокировки», чтобы сообщить другим станциям, что произошел конфликт, тем самым отбрасывая поврежденные данные кадра, которые, возможно, принимали, и ожидая Случайный период времени (алгоритм CSMA / CD для определения времени ожидания — это двоичный экспоненциальный алгоритм отсрочки передачи). После ожидания в течение случайного периода времени выполняется новая передача. Если конфликт все еще возникает после нескольких повторных передач (более 16 раз), откажитесь от отправки. При приеме сетевая карта просматривает каждый передаваемый на носителе фрейм.Если его длина меньше 64 байтов, он считается фрагментом конфликта. Если полученный кадр не является фрагментом конфликта, а адрес назначения является локальным адресом, проверяется целостность кадра. Если длина кадра превышает 1518 байт (так называемый jumbo-кадр, это может быть вызвано неправильным драйвером локальной сети или помехами) или Если он не проходит проверку CRC, считается, что кадр был искажен. Подтвержденный кадр считается действительным, и сетевая карта получает его для локальной обработки. Многие пользователи сети любят использовать сетевую карту с сильной «линией захвата» при доступе к широкополосному Интернету из-за метода расчета случайного времени после столкновения с различными PHY. Дизайн отличается, что делает некоторые сетевые карты более «полезными». Однако захват линии предназначен только для сетей широковещательного домена и не имеет смысла для соединений точка-точка с оборудованием центрального офиса, таким как коммутационные сети и ADSL. Более того, «хвататься за линию» — дело относительное, качественных изменений не будет.
3 О конфликтах между сетями
Популяризация коммутаторов в настоящее время способствует популяризации коммутационных сетей, что сокращает количество сетей доменов коллизий и значительно увеличивает пропускную способность сети. Однако, если вы используете концентратор или общую полосу пропускания для доступа к Интернету, это все равно будет сеть домена коллизий, и коллизии будут. Самая большая разница между коммутатором и концентратором заключается в следующем: один — это коммутационное оборудование LAN для построения двухточечной сети, а другой — оборудование для межсетевого взаимодействия LAN для построения сети конфликтного домена. Наш PHY также предоставляет важные функции для подключения к одноранговому устройству и сообщает нам текущее состояние подключения и рабочее состояние с помощью светодиодных индикаторов. Когда мы подключаем сетевую карту к сетевому кабелю, PHY непрерывно отправляет импульсные сигналы, чтобы определить, что на противоположном конце есть устройство. Они общаются через стандартный «язык», согласовывают друг с другом и определяют скорость соединения, дуплексный режим и использование управления потоком. Обычно результатом согласования является максимальная скорость и лучший дуплексный режим, которые могут одновременно поддерживаться двумя устройствами. Эта технология называется Auto Negotiation или NWAY, они означают одно — автоматическое согласование.
4 PHY выходная часть
Теперь давайте разберемся со следующей частью вывода PHY. Когда чип процесса CMOS работает, уровень генерируемого сигнала всегда больше 0 В (это зависит от требований к процессу и конструкции чипа), но такой сигнал будет отправлен в место на расстоянии 100 метров или более, будет иметь большой постоянный ток. Потеря веса. А если внешняя сеть напрямую подключена к микросхеме, электромагнитная индукция (гром) и статическое электричество могут легко повредить микросхему. Кроме того, метод заземления оборудования отличается, и среда электросети приведет к тому, что уровень 0 В обеих сторон будет несогласованным, так что сигнал будет передаваться от A к B, потому что уровень 0 В устройства A отличается от уровня 0 В точки B, что вызовет большой ток. Поток от оборудования с высоким потенциалом к оборудованию с низким потенциалом. Как решить эту проблему? В это время появилось устройство Transformer (разделительный трансформатор). Он фильтрует дифференциальный сигнал, отправляемый PHY, с помощью фильтра связи с дифференциальной катушкой связи для усиления сигнала и передается на другой конец соединительного сетевого кабеля посредством преобразования электромагнитного поля. Таким образом, нет физического соединения между сетевым кабелем и PHY, но сигнал передается, и составляющая постоянного тока в сигнале обрезается, и данные могут передаваться в устройства с разными уровнями 0 В. Сам развязывающий трансформатор рассчитан на напряжение от 2 до 3 кВ. Он также играет роль индукционной молниезащиты (лично я считаю, что молниезащита здесь неуместна) защиты. Сетевые устройства некоторых друзей легко сгорают во время грозы. Большинство из них вызвано неразумной конструкцией печатной платы, и большинство интерфейсов устройства сгорело. Сгорело несколько микросхем, а изолирующий трансформатор играет защитную роль.
5 О среде передачи
Изолирующий трансформатор сам по себе является пассивным компонентом, он просто передает сигнал PHY на сетевой кабель и не играет роли в усилении мощности. Так кто же решает, на какое расстояние будет передаваться сигнал сетевой карты? Максимальное расстояние передачи сетевой карты и совместимость соединения с одноранговым устройством в основном определяется PHY. Однако PHY, которые могут отправлять сигналы на расстояние более 100 метров, имеют относительно большую выходную мощность и более подвержены проблемам с электромагнитными помехами. В это время необходим подходящий Трансформатор для сотрудничества с ним. PHY Marvell, крупнейшей компании PHY, часто может передавать на расстояние от 180 до 200 метров, что намного превышает стандарт IEEE в 100 метров. Разъем RJ-45 обеспечивает соединение между сетевой картой и сетевым кабелем. В нем 8 медных листов, которые можно подключить к 4 парам витых пар (8) сетевого кабеля. Среди них 1 и 2 сети 100M предназначены для передачи данных, а 3 и 6 — для приема данных. Между 1, 2
Это пара дифференциальных сигналов, то есть их формы волны одинаковы, но разность фаз составляет 180 градусов, а амплитуды напряжения одновременно положительные и отрицательные. Такие сигналы могут передаваться дальше и обладают сильной защитой от помех. Точно так же 3 и 6 также являются дифференциальными сигналами. Сетевой кабель состоит из 8 проводов, каждые два провода скручены в пару. Когда мы делаем сетевой кабель, мы должны обратить внимание на то, чтобы сделать 1, 2 в одной паре, 3 и 6 в одной паре. В противном случае при использовании этого сетевого кабеля на большом расстоянии соединение будет невозможно или соединение будет очень нестабильным. Теперь новый PHY поддерживает функцию AUTO MDI-X (также требуется поддержка трансформатора). Он может реализовать автоматический обмен функциями сигнальных линий передачи на 1, 2 и сигнальных линий приема на 3 и 6 интерфейса RJ-45. Некоторые PHY даже поддерживают автоматический обмен положительными и отрицательными сигналами в паре линий. Таким образом, нам не нужно беспокоиться о том, использовать ли прямой или перекрестный кабель для подключения определенного устройства. Эта технология широко используется в коммутаторах и маршрутизаторах SOHO. В сети 1000Basd-T одним из наиболее распространенных методов передачи является использование всех 4 витых пар в сетевом кабеле, из которых 4, 5 и 7, 8 добавляются для совместной передачи и приема данных. Поскольку спецификация сети 1000Based-T включает функции AUTOMDI-X, невозможно строго определить их исходящие или принимающие отношения, в зависимости от конкретных результатов переговоров обеих сторон.
6 Как общаться между PHY и MAC
Давайте продолжим заботиться о том, как PHY и MAC взаимодействуют друг с другом. MAC и PHY подключаются через стандартный интерфейс MII / GigaMII (Media Independed Interfade), определенный IEEE. Этот интерфейс определен IEEE. Интерфейс MII передает все данные и данные управления сети. MAC определяет рабочее состояние PHY и управляет PHY, используя интерфейс SMI (последовательный интерфейс управления) для чтения и записи регистров PHY. Некоторые регистры в PHY также определены IEEE, так что PHY отражает его текущий статус в регистрах. MAC непрерывно считывает регистр состояния PHY через шину SMI, чтобы узнать текущее состояние PHY, например скорость соединения, дуплекс Способности и т. Д. Конечно, вы также можете настроить регистр PHY через SMI для достижения целей управления, таких как управление потоком открытия и закрытия, режим автосогласования или принудительный режим и т. Д. Мы видели, что как физически подключенный интерфейс MII, так и шина SMI или регистр состояния PHY и регистр управления соответствуют IEEE, поэтому MAC и PHY разных компаний могут работать вместе. Конечно, чтобы соответствовать некоторым уникальным функциям PHY различных компаний, драйвер необходимо соответствующим образом изменить.
7 Питание сетевой карты
Последняя часть — это блок питания. Большинство сетевых карт теперь используют напряжение 3,3 В или ниже. Некоторые имеют двойное напряжение. Следовательно, требуется схема преобразования энергии. Более того, чтобы реализовать функцию пробуждения сетевой карты в режиме ожидания, необходимо убедиться, что очень небольшая часть всего PHY и MAC всегда находится в заряженном состоянии, для чего требуется схема, которая преобразует напряжение ожидания 5 В на материнской плате в рабочее напряжение PHY. После включения хоста рабочее напряжение PHY должно быть заменено напряжением, преобразованным из 5 В, чтобы сэкономить потребление 5 В в режиме ожидания. (Многие некачественные сетевые карты этого не делают). Сетевая карта с функцией Wake on line обычно также имеет интерфейс WOL. Это связано с тем, что в PCI 2.1 раньше не было функции пробуждения хоста устройствами PCI, поэтому для реализации функции WOL необходимо подключить провод к южному мосту через интерфейс WOL на материнской плате. Комбинированная сетевая карта новой материнской платы обычно поддерживает PCI2.2 / 2.3 и расширяет функцию сигнала PME # .Функция пробуждения может быть реализована через шину PCI без этого интерфейса.
Сети для самых маленьких. Часть четырнадцатая. Путь пакета
Одно из удивительнейших достижений современности — это то, как, сидя в Норильске, человек может чатиться со своим другом в Таиланде, параллельно покупать билет на вечерний самолёт к нему, расплачиваясь банковской картой, в то время, как где-то в Штатах на виртуалочке его бот совершает сделки на бирже со скоростью, с которой его сын переключает вкладки, когда отец входит в комнату.
А через 10 минут он закажет такси через приложение на телефоне, и ему не придётся даже брать с собой в дорогу наличку.
В аэропорту он купит кофе, расплатившись часами, сделает видеозвонок дочери в Берлин, а потом запустит кинцо онлайн, чтобы скоротать час до посадки.
За это время тысячи MPLS-меток будут навешаны и сняты, миллионы обращений к различным таблицам произойдут, базовые станции сотовых сетей передадут гигабайты данных, миллиарды пакетов больших и малых в виде электронов и фотонов со скоростью света понесутся в ЦОДы по всему миру.
Это ли не электрическая магия?
В своём вояже к QoS, теме обещанной многократно, мы сделаем ещё один съезд. На этот раз обратимся к жизни пакета в оборудовании связи. Вскроем этот синий ящик и распотрошим его.

Кликабельно и увеличабельно.
Сегодня:
- Коротко о судьбе и пути пакета
- Плоскости (они же плейны): Forwarding/Data, Control, Management
- Кто как и зачем обрабатывает трафик
- Типы чипов: от CPU до ASIC’ов
- Аппаратная архитектура сетевого устройства
- Путешествие длиною в жизнь
Итак, есть две плоскости весьма чёткое деление архитектуры сетевого устройства на две части: Control и Data Plane. Это элегантное решение, которое годы назад позволило абстрагировать путь трафика от физической топологии, зародив пакетную коммутацию, и которое является фундаментом всей индустрии сегодня.
Data Plane — это пересылка трафика со входных интерфейсов в выходные — чуть ближе к точке назначения. Data Plane руководствуется таблицами маршрутизации/коммутации/меток (далее будем называть их таблицами пересылок). Здесь мет места задержкам — всё происходит быстро.
Control Plane — это уровень протоколов, контролирующих состояние сети и заполняющих таблицы пересылок (BGP, OSPF, LDP, STP, BFD итд.). Тут можно помедленнее — главное — построить правильные таблицы.
Для чего такое разделение оказалось нужным, читайте в соответствующей главе.
Поскольку все предыдущие 14 частей СДСМ были так или иначе про плоскость управления, в этот раз мы будем говорить о плоскости пересылки.
И в первую очередь введём понятие транзитных и локальных пакетов.
Транзитные — это пакеты, обрабатывающиеся исключительно на Data Plane и не требующие передачи на плоскость управления. Они пролетают через узел быстро и прозрачно.
Преимущественно это пользовательские (клиентские) данные, адрес источника и назначения которых за пределами данного устройства (и, скорее всего, сети провайдера вообще).
Среди транзитного трафика могут быть и протокольные — внутренние для сети провайдера, но не предназначенные данному узлу.
Например, BGP или Targeted LDP.
Локальные делятся на три разных вида:
-
Предназначенные приложению на данном устройстве. То есть либо адрес назначения принадлежит ему (настроен на нём). Либо адрес назначения броадкастовый (ARP) или мультикастовый (OSPF Hello), который устройство должно прослушивать.
1. Коротко о судьбе и пути пакета
Под пакетом будем понимать PDU любого уровня — IP-пакеты, фреймы, сегменты итд. Для нас важно, что это сформированный пакет информации.
Всю статью мы будем рассматривать некий модульный узел, который пересылает пакеты. Для того, чтобы не запутать читателя, определим, что это маршрутизатор.
Все рассуждения данной статьи, с поправками на заголовки, протоколы и конкретные действия с пакетом, применимы к любым сетевым устройствам, будь то маршрутизатор, файрвол или коммутатор — их задача: передать пакет следующему узлу ближе к назначению.
Дабы избежать кривотолков и неуместной критики: автор отдаёт себе отчёт в том, что реальная ситуация зависит от конкретного устройства. Однако задача статьи — дать общее понимание принципов работы сетевого оборудования.
Следующую схему мы выберем в качестве отправной точки.
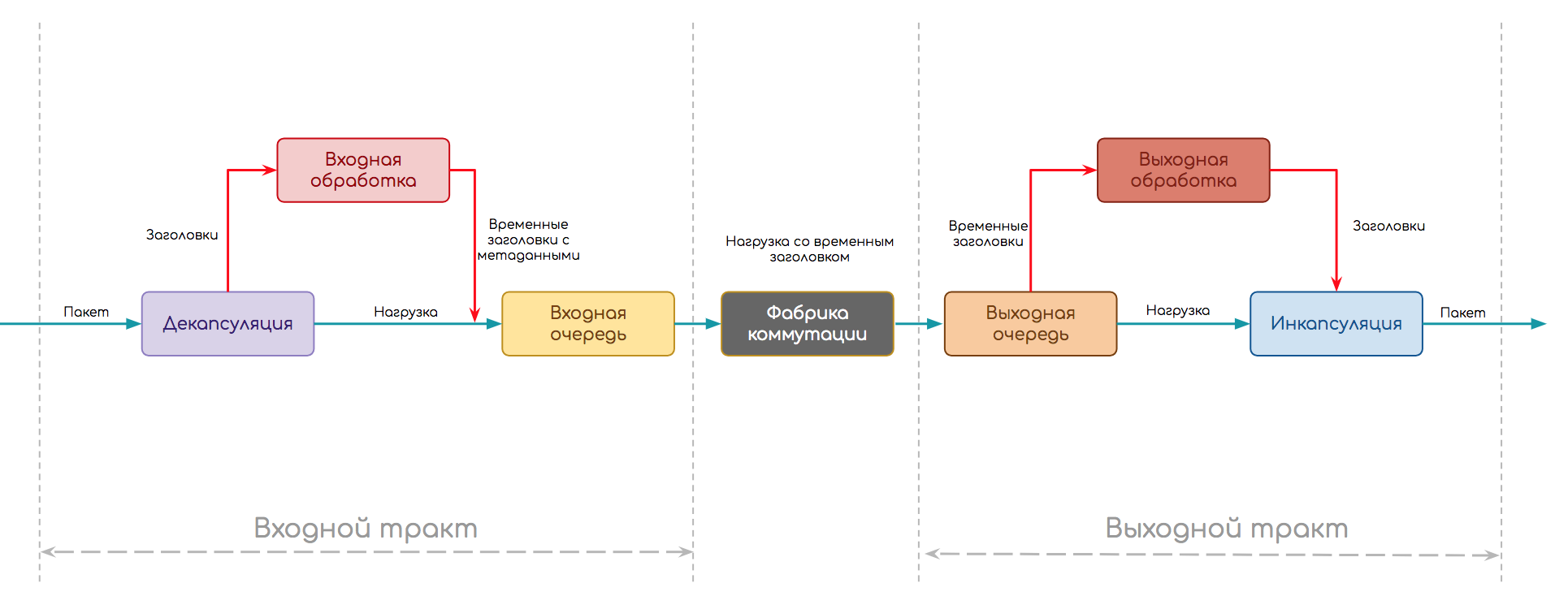
Независимо от того, что за устройство, как реализована обработка трафика, пакету нужно пройти такой путь.
- Путь делится на две части: входной и выходной тракты.
- На входе происходит сначала декапсуляция — отделение заголовка от полезной нагрузки и прочие присущие протоколу вещи (например, вычисление контрольной суммы)
- Далее стадия входной обработки (Ingress Processing) — сам пакет без заголовка (нагрузка) томится в буфере, а заголовок анализируется. Здесь могут к пакетам применяться политики, происходить поиск точки назначения и выходного интерфейса, создаваться копии итд.
- Когда анализ закончен, заголовок превращается в метаданные (временный заголовок), склеивается с пакетом и они передаются на входную очередь. Она позволяет не слать на выходной тракт больше, чем тот может обработать.
- Далее пакет может ждать (или запрашивать) явное разрешение на перемещение в выходную очередь, а может просто туда передаваться, а там, поди, разберутся.
- Выходных трактов может быть несколько, поэтому пакет далее попадает на фабрику коммутации, цель которой, доставить его на правильный.
- На выходном тракте также есть очередь — выходная. В ней пакеты ожидают выходной обработки (Egress Processing): политики, QoS, репликация, шейпинг. Здесь же формируются будущие заголовки пакета. Также выходная очередь может быть полезной для того, чтобы на интерфейсы не передавать больше, чем они могут пропустить.
- И завершающая стадия — инкапсуляция пакета в приготовленные заголовки и передача его дальше.
Тогда схема примет такой вид:
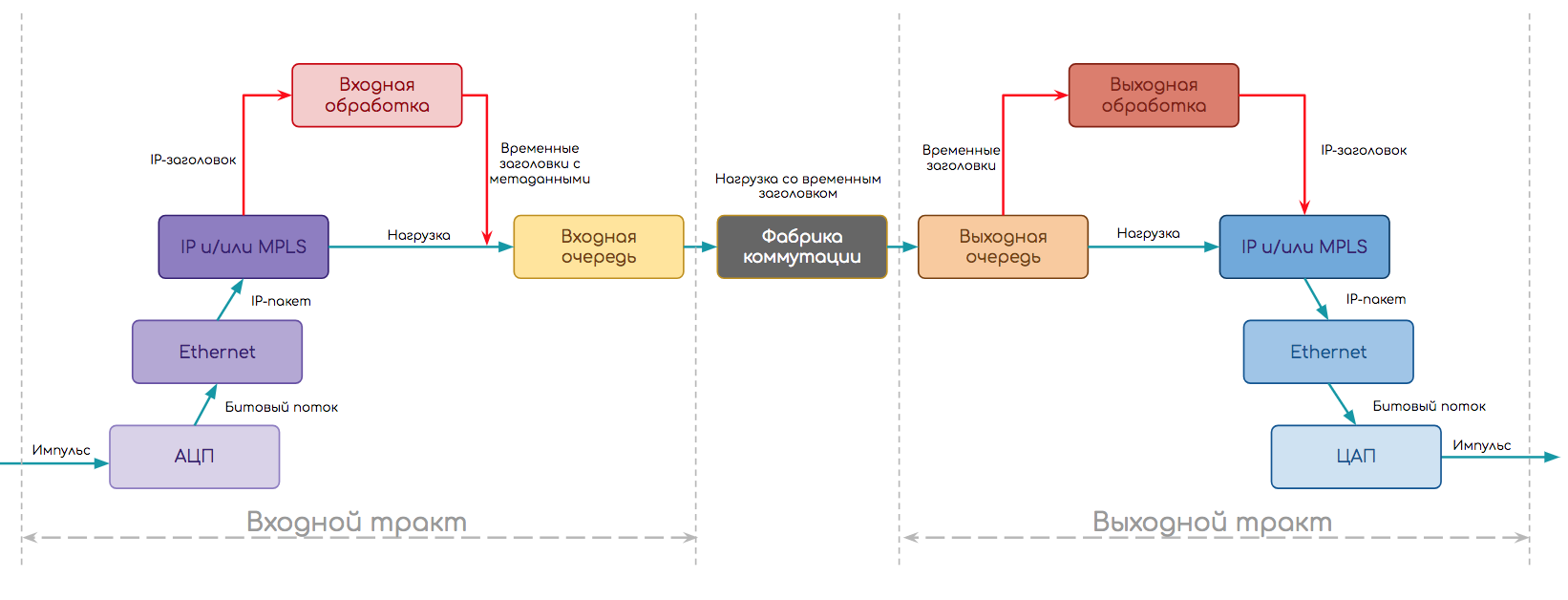
- Сначала отработал модуль физического уровня.
- С помощью АЦП восстановил поток битов — в некоторым смысле декапсуляция физического уровня.
- Работая на определённом типе порта (Ethernet), он понимает, что выходным интерфейсом будет модуль Ethernet.
- Далее происходит декапсуляция и Входная Обработка на Ethernet-модуле:
- Определение границ кадра, преамбулы, IFG, FCS
- Подсчёт контрольной суммы
- Снятие заголовков, разбор на поля
- Применение политик
- Определение адреса назначения — он локальный — и тогда выходной интерфейс — к модулю IP.
- Входная обработка IP:
- Снятие заголовков, разбор на поля
- Применение политик
- Анализ адреса назначения
- Поиск выходного интерфейса в Таблице Пересылки
- Формирование временных внутренних заголовков
- Склейка временных заголовков с данными и отправка пакета на выходной тракт.
- Обработка во входной очереди.
- Пересылка через фабрику коммутации.
- Обработка в выходной очереди.
- На выходном тракте модуль IP совершает Выходную Обработку:
- Применение политик, шейпинг
- Формирование конечного заголовка на основе метаданных (временного заголовка) и передача его модулю Ethernet.
- Далее Выходная Обработка на модуле Ethernet
- Поиск в ARP-таблице MAC-адреса следующего узла
- Формирование заголовка Ethernet
- Подсчёт контрольной суммы
- Применение политик
- Спуск на физический модуль.
- А модуль физического уровня в свою очередь разбивает поток битов на электрические импульсы и передаёт в кабель.
Все перечисленные выше шаги декомпозируются на сотни более мелких, каждый из которых должен быть реализован в железе или в ПО.
Вот и вопрос — в железе или ПО. Он преследует мир IP-сетей с момента их основания и, как это водится, развитие происходит циклически.
Есть вещи тривиальные, для которых элементная база существует… ммм… с 60-х. Например, АЦП, аппаратные очереди или CPU. А есть те, которые стали прорывом относительно недавно. Часть функций всегда была и будет аппаратной, часть — всегда будет программной, а часть — мечется, как та обезьяна.
2. Уровни и плоскости

Мы столько раз прежде использовали эти понятия, что пора им уже дать определения. В работе оборудования можно выделить три уровня/плоскости:
- Forwarding/Data Plane
- Control Plane
- Management Plane
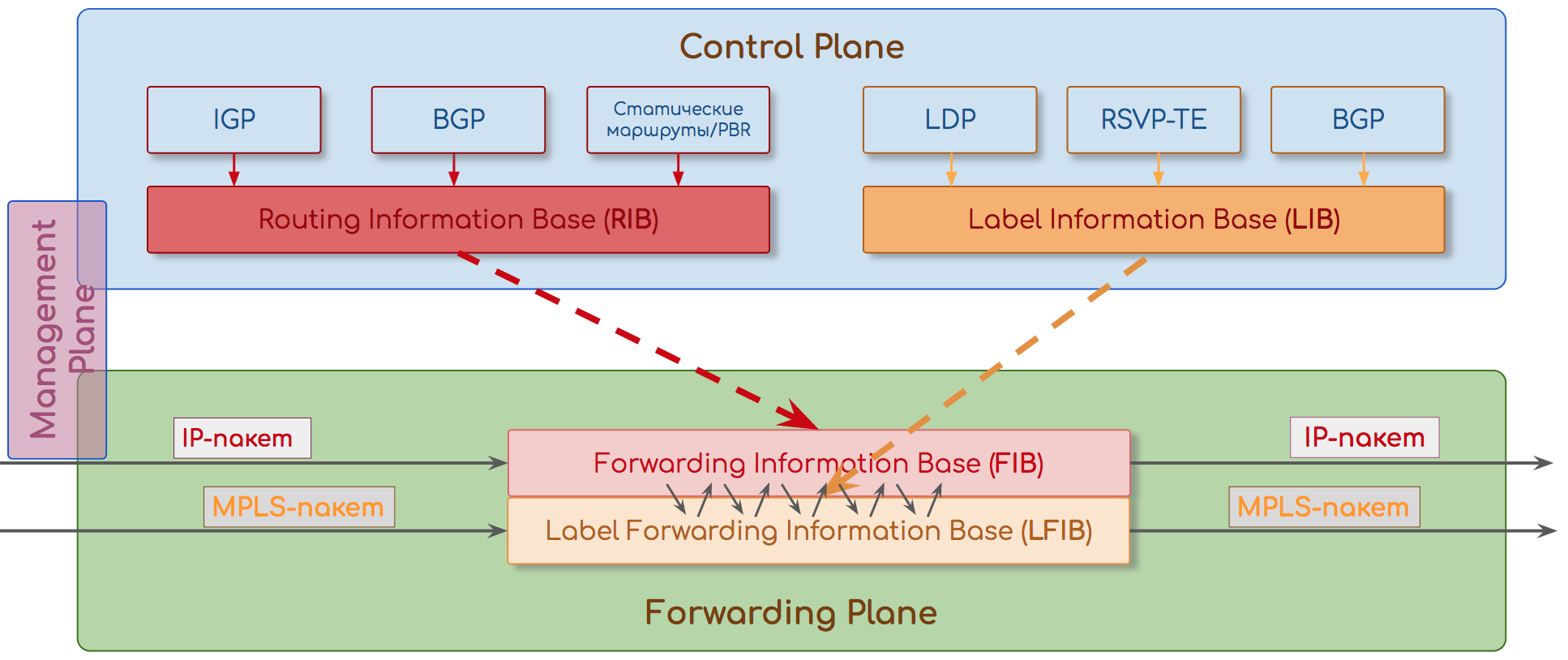
Forwarding/Data Plane
Главная задача сети — доставить трафик от одного приложения другому. И сделать это максимально быстро, как в плане пропускной способности, так и задержек.
Соответственно главная задача узла — максимально быстро передать вошедший пакет на правильный выходной интерфейс, успев поменять ему заголовки и применив политики.
Поэтому существуют заранее заполненные таблицы передачи пакетов — таблицы коммутации, таблицы маршрутизации, таблицы меток, таблицы соседств итд.
Реализованы они могут быть на специальных чипах CAM, TCAM, работающих на скорости линии (интерфейса). А могут быть и программными.
- Принять Ethernet-кадр, посчитать контрольную сумму, проверить есть ли SMAC в таблице MAC-адресов. Найти DMAC в таблице MAC-адресов, определить интерфейс, передать кадр.
- Принять MPLS-пакет, определить входной интерфейс и входную метку. Выполнить поиск в таблице меток, определить выходной интерфейс и выходную метку. Свопнуть. Передать.
- Пришёл поток пакетов. Выходным интерфейсом оказался LAG. Решение, в какие из интерфейсов их отправить, тоже принимается на Forwarding Plane.
В абсолютном большинстве случаев считается, что Data и Forwarding Plane — это одно и то же.
Однако иногда их разделяют.
Тогда Data Plane означает именно манипуляции с полезной нагрузкой: процесс доставки пакета от входного интерфейса к выходному и обработку его в буферах.
А Forwarding Plane — это обработка заголовков и принятие решения о пересылке.
Примерно так: 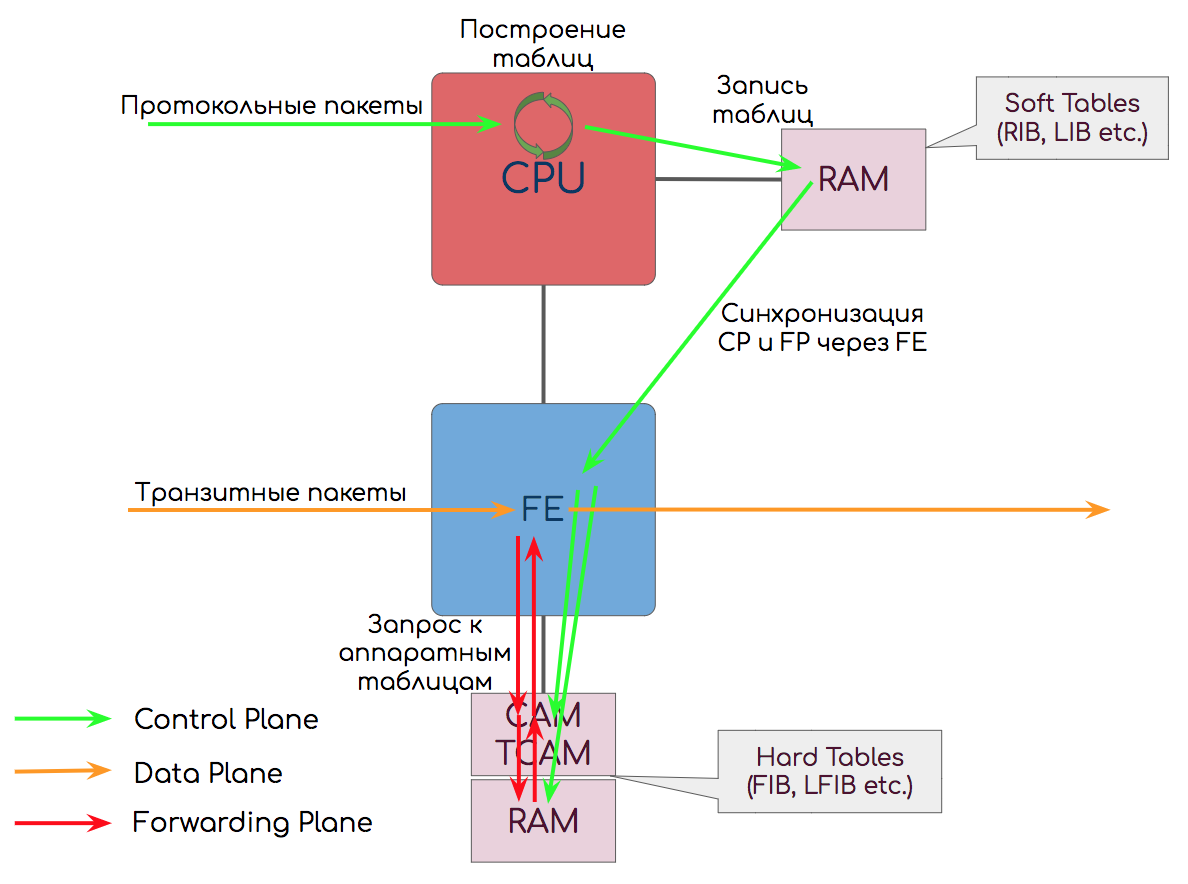
Control Plane
Всему голова. Она заранее заполняет таблицы, по которым затем будет передаваться трафик.
Здесь работают протоколы со сложными алгоритмами, которые дорого или невозможно выполнить аппаратно.
Например, алгоритм Дейкстры реализовать на чипе можно, но сложно. Так же сложно сделать выбор лучшего маршрута BGP или определение FEC и рассылку меток. Кроме того, для всего этого пришлось бы делать отдельный чип или часть чипа, которая практически не может быть переиспользована.
В такой ситуации лучше пожертвовать сабсекундной сходимостью в пользу удобства и цены.
Поэтому ПО запускается на CPU общего назначения.
Получается медленно, но гибко — вся логика программируема. И на самом деле скорость на Control Plane не важна. Однажды вычисленный маршрут инсталлируется в FIB, а дальше всё не скорости линии.
Вопрос скорости Control Plane возникает при обрывах, флуктуациях на сети, но он сравнительно успешно решается механизмами TE HSB, TE FRR, IP FRR, VPN FRR, когда запасные пути готовятся заранее на том же Control Plane.
- Запустили сеть с IGP. Нужно сформировать Hello, согласовать параметры сессий, обменяться базами данных, просчитать кратчайшие маршруты, инсталлировать их в Таблицу Маршрутизации, поддерживать контакт через периодические Keepalive.
- Пришёл BGP Update. Control Plane добавляет новые маршруты в таблицу BGP, выбирает лучший, инсталлирует его в Таблицу Маршрутизации, при необходимости пересылает Update дальше.
- Администратор включил LDP. Для каждого префикса создаётся FEC, назначается метка, помещается в таблицу меток, анонсы уходят всем LDP-соседям.
- Собрали два коммутатора в стек. Выбрать главный, проиндексировать интерфейсы, актуализировать таблицы пересылок — задача Control Plane.
Работа и реализация Control Plane универсальна: ЦПУ + оперативная память: работает одинаково хоть на стоечных маршрутизаторах, хоть на виртуальных сетевых устройствах.
Эта система — не мысленный эксперимент, не различные функции одной программы, это действительно физически разделённые тракты, которые взаимодействуют друг с другом.
Началось всё с разнесения плоскостей на разные платы. Далее появились стекируемые устройства, где одно выполняло интеллектуальные операции, а другое было лишь интерфейсным придатком.
Вчерашний день — это системы вроде Cisco Nexus 5000 Switch + Nexus 2000 Fabric Extender, где 2000 выступает в роли выносной интерфейсной платы для 5000.
Где-то в параллельной Вселенной тихо живёт SDN разлива 1.0 — с Openflow-like механизмами, где Control Plane вынесли на внешние контроллеры, а таблицы пересылок заливаются в совершенно глупые коммутаторы.
Наша реальность и ближайшее будущее — это наложенные сети (Overlay), настраиваемые SDN-контроллерами, где сервисы абстрагированы от физической топологии на более высоком уровне иерархии.
И несмотря на то, что с каждой статьёй мы всё глубже погружаемся в детали, мы учимся мыслить свободно и глобально.
Разделение на Control и Forwarding Plane позволило отвязать передачу данных от работы протоколов и построения сети, а это повлекло значительное повышение масштабируемости и отказоустойчивости.
Так один модуль плоскости управления может поддерживать несколько интерфейсных модулей.
В случае сбоя на плоскости управления механизмы GR, NSR, GRES и ISSU помогают плоскости пересылки продолжать работать будто ничего и не было.
Management Plane
- Температура
- Утилизация ресурсов
- Электропитание
- Скорость вращения вентиляторов
- Работоспособность плат и модулей.
- Упал интерфейс — генерируется авария, лог и трап на систему мониторинга
- Поднялась температура чипа — увеличивает скорость вращения вентиляторов
- Обнаружил, что одна плата перестала отвечать на периодические запросы — выполняет рестарт плат — вдруг поднимется.
- Оператор подключился по SSH для снятия диагнонстической информации — CLI также обеспечивается Control Plane’ом.
- Приехала конфигурация по Netconf — Management Plane проверяет и применяет её. При необходимости инструктирует Control Plane о произошедших изменениях и необходимых действиях.
Итак:
Forwarding Plane — передача трафика на основе таблиц пересылок — собственно то, из чего оператор извлекает прибыль.
Control Plane — служебный уровень, необходимый для формирования условий для работы Forwarding Plane.
Management Plane — модуль, следящий за общим состоянием устройства.
Вместе они составляют самодостаточный узел в сети пакетной коммутации.
Разделение на Control и Forwarding/Data Plane — не абстрактное — их функции действительно выполняют разные чипы на плате.
Так Control Plane обычно реализован на связке CPU+RAM+карта памяти, а Forwarding Plane на ASIC, FPGA, CAM, TCAM.
Но в мире виртуализации сетевых функций всё смешалось — эту ремарку я буду делать до конца статьи.
3. История способов обработки трафика
Сейчас с Forwarding Plane всё отлично: 10 Гб/с, 100 Гб/с — не составляют труда — плати и пользуйся. Любые политики без влияния на производительность. Но так было не всегда.
В чём сложности?
В первую очередь это вопрос организации вышеописанных трактов: что делать с электрическим импульсом из одного кабеля и как его передать в другой — правильный.
Для этого на сетевых устройствах есть букет разнообразных чипов.

Это пример интерфейсной платы Cisco
Так, например, микросхемы (ASIC, FPGA) выполняют простые операции, вроде АЦП/ЦАП, подсчёта контрольных сум, буферизации пакетов.
Ещё нужен модуль, который умеет парсить, анализировать и формировать заголовки пакетов.
И модуль, который будет определять, куда, в какой интерфейс, пакет надо передать. Делать это нужно для каждого божьего пакета.
Кто-то должен также следить и за тем, можно ли этот пакет пропускать вообще. То есть проверить его на предмет подпадания под ACL, контролировать скорость потока и отбросить, если она превышена.
Сюда же можно вписать и более комплексные функции трансляции адресов, файрвола, балансировки итд.
Исторически все сложные действия выполнялись на CPU. Поиск подходящего маршрута в таблице маршрутизации был реализован как программный код, проверка на удовлетворение политикам — тоже. Процессор с этим справлялся, но только он с этим и справлялся.
Чем это грозит понятно: производительность будет падать тем сильнее, чем больше трафика устройство должно перемалывать и чем больше функций мы будем вешать на него. Поэтому одна за другой большинство функций были делегированы на отдельные чипы.
И из обычного x86-сервера маршрутизаторы превратились в специализированные сетевые коробки, набитые непонятными деталями и интерфейсами. А Ethernet-хабы переродились в интеллектуальные коммутаторы.
Функции по парсингу заголовков и их анализу, а также поиску выходного интерфейса взяли на себя ASIC, FPGA, Network Processor.
Обработка в очередях, обеспечение QoS, управление перегрузками — тоже специализированные ASIC.
Такие вещи, как стейтфул файрвол, остались на ЦПУ, потому что количество сессий несъедобное.
Другой вопрос: мы где-то должны хранить таблицы коммутации. В чём-то быстром.
Первое, что приходит в голову — это классическая оперативная память.
Проблема с ней в том, что обращение к ней идёт по адресу ячейки, а возвращает она уже её содержимое (или контент, не по-русски если).
Однако входящий пакет несёт в себе никак не адрес ячейки памяти, а только MAC, IP, MPLS.
Тогда бы нам пришлось иметь некий хэш алгоритм, который, задействуя CPU, высчитывал бы адрес ячейки и извлекал оттуда нужные данные.
Вот только пропускная способность порта в 10 Гб/с означает, что CPU должен передавать 1 бит каждые 10 нс. И у него есть порядка 80 мкс, чтобы передать пакет размером в один килобайт.
Впрочем, вычисление хэша — алгоритм очень простой, и любой мало-мальски уважающий себя ASIC с этим справится. Инженерам был адресован вопрос — а что дальше делать с хэшем?
Так появилась память CAM — Content Addressable Memory. Её адреса — это хэши значений. В своей ячейке CAM содержит или ответное значение (номер порта, например) или чаще адрес ячейки в обычной RAM.
То есть пришёл Ethernet-кадр, ASIC’и его разорвали на заголовки, вытащили DMAC — прогнали его через CAM и получили вожделенный исходящий интерфейс.
Подробнее о CAM дальше.
Что с тобой не так, IP?!
Я не зря взял в пример Ethernet-кадр. С IP совсем другая история.
MAC-коммутация — это просто: ни тебе агрегации маршрутов, ни тебе Longest Prefix Match — только 48 уникальных бит.
А вот в IP это всё есть. У нас может быть несколько маршрутов в Таблице Маршрутизации с разными длинами масок и выбрать нужно наидлиннейшую. Это базовый принцип IP-маршрутизации, с которым не поспоришь и не обойдёшь.
Кроме того есть сложные ACL с их Wildcard-масками.
Долгое время решения этой проблемы не существовало. На заре сетей с пакетной коммутацией IP-пакеты обрабатывались на CPU. И главная проблема этого — даже не коммутация на скорости линии (хотя и она тоже), а влияние дополнительных настроек на производительность. Вы и сейчас можете это увидеть на каком-нибудь домашнем микротике, если настроить на нём с десяток ACL — сразу заметите, как просядет пропускная способность.
Интернет разрастался, политик становилось всё больше, а требования к пропускной способности подпрыгивали скачкообразно, и CPU становился камнем преткновения. Тем более учитывая, что поиск маршрута подчас приходилось делать не один раз, а рекурсивно погружаться всё глубже.
Так в лихие 90-е зародился MPLS. Какая блестящая идея — построить заранее путь на Control Plane. Адресацией в MPLS будет метка фиксированной длины, и соответственно нужна единственная запись в таблице меток, что с пакетом дальше делать. При этом мы не теряем гибкости IP, поскольку он лежит в основе, и можем использовать CAM. Плюс заголовок MPLS — короток (4 байта против 20 в IP) и предельно прост.
Однако по иронии судьбы в то же время инженеры совершили прорыв, разработав TCAM — Ternary CAM. И с тех пор ограничений уже почти не было (хотя не без оговорок).
Подробнее от TCAM дальше.
Что же до MPLS, который ввиду данного события должен был скоропостижно скончаться, едва родившись, то он прорубил себе дверь в другой дом. Но об этом мы уже наговорились.
О дивный новый мир
- Нужна маршрутизация и коммутация в пределах одного сервера между различными виртуалками.
- Горизонтальная масштабируемость требует возможности запускать новые виртуалки в любой части сети, а соответственно и адаптировать её конфигурацию.
- Цепочка услуг (Service Chain), такая как Anti-DDoS, IDS/IPS, FW предполагает маршрутизацию, управляемую программно и автоматическую настройку сетевых узлов.
Поэтому большая часть сетевой инфраструктуры ЦОДов сейчас виртуализируется. А это предполагает переход от аппаратной архитектуры к гибридной. CAM, TCAM, NP, ASIC сейчас заменяются на связку DPDK с более умными сетевыми картами, которые тоже поддерживают виртуалиацию — SR-IOV — и забирают на свои чипы некоторую часть рутинной работы.
Кроме того, с развитием алгоритмических методов поиска, сегодня сокращается необходимость в CAM/TCAM на традиционных коммутаторах и маршрутизаторах.
Таким образом мы снова становимся свидетелями сдвига парадигмы в вопросе реализации Forwarding Plane.
Но мы пока остаёмся в сфере аппаратной пересылки и теперь давайте подробнее обо всех чипах.
4. Типов-чипов
Я не ставлю целью данной статьи описать все существующие чипы — только те, что используются в сетевом оборудовании.
CPU — Central Processing Unit
Самый медленный, но самый гибкий элемент устройства — центральный процессор.
Он занимается обработкой протокольных пакетов и сложного поведения.

Его прелесть в том, что он управляется запущенными приложениями и «многозадачен». Логику легко изменить, просто поправив программный код.
Такие вещи, как SPF, установка соседства по всем протоколам, генерация логов, аварий, подключение к пользовательским интерфейсам управления — все действия со сложной логикой — происходят на нём.
Собственно, поэтому, например, вы можете наблюдать, что при высокой загрузке CPU становится некомфортно работать в консоли. Хотя трафик при этом ходит уверенно.
CPU берёт на себя функции Control Plane.
На устройствах с программной пересылкой, участвует также и в Forwarding Plane.
CPU может быть один на весь узел, а может быть отдельно на каждой плате в шасси при распределённой архитектуре.
Результаты своей работы CPU записывает в оперативную память ↓.
RAM — Random Access Memory
Классическая оперативная память — куда без неё?

Мы ей адрес ячейки — она нам содержимое.
В ней хранятся, так называемые Soft Tables (программные таблицы) — таблицы маршрутизации, меток, MAC-адресов.
Когда вы выполняете команду «show ip route», запрос идёт именно в оперативку к Soft Tables.
CPU работает именно с оперативной памятью — когда он посчитал маршрут, или построил LSP — результат записывается в неё. А уже оттуда изменения синхронизируются в Hard Tables в CAM/TCAM↓.
Кроме того, периодически происходит синхронизация всего содержимого всех таблиц на случай, если вдруг по какой-то причине инкрементальные изменения не спустились корректно.
Soft Tables не может быть непосредственно использован для передачи данных, потому что слишком медленно — обращение к оперативке идёт через ЦПУ и требуется алгоритмический поиск, затратный по времени. С оговоркой на NFV.
Кроме того на чипах RAM (DRAM) реализованы очереди: входные, выходные, интерфейсные.
CAM — Content-Addressable Memory
Это особо-хитрый вид памяти.
Вы ей — значение, а она вам — адрес ячейки.
Content-Addressable означает, что адресация базируется на значениях (содержимом).

Значением, например, может быть, например DMAC. CAM прогоняет DMAC по всем своим записям и находит совпадение. В результате CAM выдаст адрес ячейки в классической RAM, где хранится номер выходного интерфейса. Дальше устройство обращается к этой ячейке и отправляет кадр, куда положено.
Для достижения максимальной скорости CAM и RAM располагаются очень близко друг к другу.
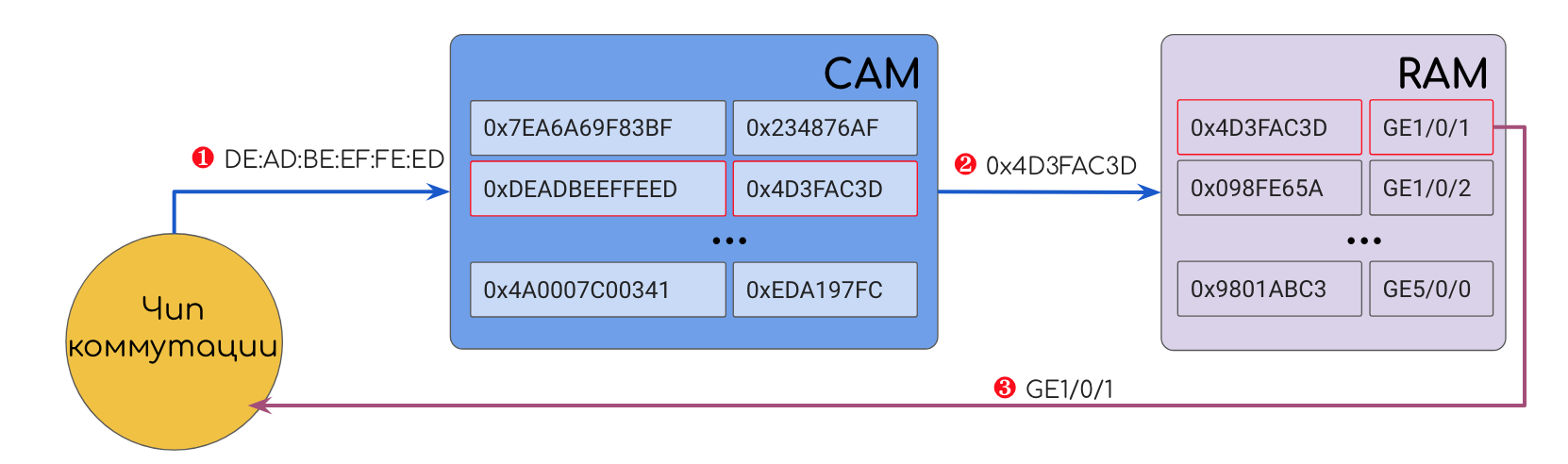
Прелесть CAM в том, что она возвращает результат за фиксированное время, не зависящее от количества и размера записей в таблице — О(1), выражаясь в терминах сложностей алгоритмов.
Достигается это за счёт того, что значение сравнивается одновременно со всеми записями. Одновременно! А не перебором.
На входе каждой ячейки хранения в CAM стоят сравнивающие элементы (мне очень нравится термин компараторы), которые могут выдавать 0 (разомкнуто) или 1 (замкнуто) в зависимости от того, что на них поступило и что записано.
В сравнивающих элементах записаны как раз искомые значения.
Когда нужно найти запись в таблице, соответствующую определённому значению, это значение прогоняется одновременно через ВСЕ сравнивающие элементы. Буквально, электрический импульс, несущий значения, попадает на все элементы, благодаря тому, что они подключены параллельно. Каждый из них выполняет очень простое действие, выдавая для каждого бита 1, если биты совпали, и 0, если нет, то есть замыкая и размыкая контакт. Таким образом та ячейка, адресом которой является искомое значение, замыкает всю цепь, электрический сигнал проходит и запитывает её.
Вот архитектура такой памяти:
Вот пример работы 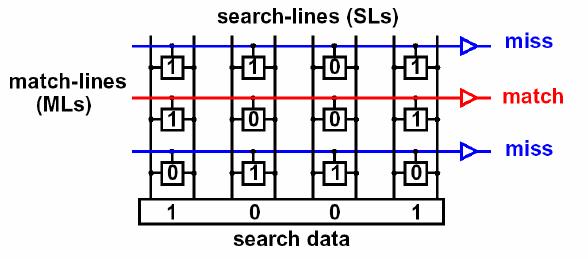
Картинка из прелюбопытнейшего документа.
А это схема реализации: 
Источник картинки.
Это чем-то похоже на пару ключ-замок. Только ключ с правильной геометрией может поставить штифты замка в правильные положения и провернуть цилиндр.
Вот только у нас много копий одного ключа и много разных конфигураций замков. И мы вставляем их все одновременно и пытаемся провернуть, а нужное значение лежит за той дверью, замок которой ключ откроет.
- Длина результата значительно меньше, чем у входных значений. Так пространство MAC-адресов длиной 48 бит можно отобразить в 16-ибитовое значение, тем самым в 2^32 раза уменьшив длину значений, которые нужно сравнивать, и соответственно, размер CAM.
Основная идея хэш-функции в том, что результат её выполнения для одинаковых входных данных всегда будет одинаков (например, как остаток от деления одного числа на другое — это пример элементарной хэш функции). - Результат её выполнения на всём пространстве входных значений — это ± плоскость — все значения равновероятны. Это важно для снижения вероятности конфликта хэшей, когда два значения дают одинаковый результат.
Конфликт хэшей, кстати, весьма любопытная проблема, которая описана в парадоксе дней рождения. Рекомендую почитать Hardware Defined Networking Брайна Петерсена, где помимо всего прочего он описывает механизмы избежания конфликта хэшей. - Независимо от длины исходных аргументов, результат будет всегда одной длины. То есть на вход можно подать сложное сочетание аргументов, например, DMAC+EtherType, и для хранения не потребуется выделять более сложную структуру памяти.
В этот принцип отлично укладывается также MPLS-коммутация, почему MPLS и сватали в своё время на IP.
- Пришёл самый первый Ethernet-кадр на порт коммутатора.
- Коммутатор извлёк SMAC, вычислил его хэш.
- Данный хэш он записал в сравнивающие элементы CAM, номер интерфейса откуда пришёл кадр в RAM, а в саму ячейку CAM адрес ячейки в RAM.
- Выполнил рассылку изначального кадра во все порты.
- Повторил пп. 1-5 .
- Заполнена вся таблица MAC-адресов.
- Приходит Ethernet-кадр. Коммутатор сначала проверяет, известен ли ему данный SMAC (сравнивает хэш адреса с записанными хэшами в CAM) и, если нет, сохраняет.
- Извлекает DMAC, считает его хэш.
- Данный хэш он прогоняет через все сравнивающие элементы CAM и находит единственное совпадение.
- Узнаёт номер порта, отправляет туда изначальный кадр.
- Ячейки CAM адресуются хэшами.
- Ячейки CAM содержат (обычно) адрес ячейки в обычной памяти (RAM), потому что хранить конечную информацию — дорого.
- Каждая ячейка CAM имеет на входе сравнивающий элемент, который сравнивает искомое значение с хэш-адресом. От этого размер и стоимость CAM значительно больше, чем RAM.
- Проверка совпадения происходит одновременно во всех записях, отчего CAM дюже греется, зато выдаёт результат за константное время.
- CAM+RAM хранят Hard Tables (аппаратные таблицы), к которым обращается чип коммутации.
TCAM — Ternary Content-Addressable Memory
- Как это в принципе реализовать?
- Как из нескольких подходящих маршрутов выбрать лучший (с длиннейшей маской)?

Ответом стал TCAM, в котором «T» означает «троичный»». Помимо 0 и 1 вводится ещё одно значение Х — «не важно» (CAM иногда называют BCAM — Binary, поскольку там значения два — 0 и 1).
Тогда результатом поиска нужной записи в таблице коммутации будет содержимое той ячейки, где самая длинная цепочка 1 и самая короткая «не важно».
Например, пакет адресован на DIP 10.10.10.10.
В Таблице Маршрутизации у нас следующие маршруты:
0.0.0.0/0
10.10.10.8/29
10.10.0.0/16
10.8.0.0/13
Другие.
В сравнивающие элементы TCAM записываются биты маршрута, если в маске стоит 1, и «не важно», если 0.
При поиске нужной записи TCAM, как и CAM, прогоняет искомое значение одновременно по всем ячейкам. Результатом будет последовательность 0, 1 и «не важно».
Только те записи, которые вернули последовательность единиц, за которыми следуют «не важно» участвуют в следующем этапе селекции.
Далее из всех результатов выбирается тот, где самая длинная последовательность единиц — так реализуется правило Longest prefix match.
Очевидно, что мы-то своим зорким взглядом, сразу увидели, что это будет маршрут 10.10.10.8/29.
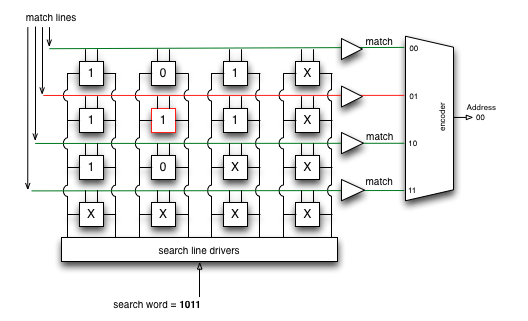
Источник картинки.
Решение на грани гениальности, за которое пришлось заплатить большую цену. Из-за очень высокой плотности транзисторов (у каждой ячейки их свой набор, а ячеек должны быть миллионы) они греются не меньше любого CPU — нужно решать вопрос отвода тепла.
Кроме того, их производство стоит очень дорого, и не будет лукавством сказать, что стоимость сетевого оборудования и раньше и сейчас определяется именно наличием и объёмом TCAM.
Внимательный читатель обратил внимание на вопрос хэш-функций — ведь она преобразует изначальный аргумент во что-то совершенно непохожее на исходник, как же мы будем сравнивать 0, 1 и длины? Ответ: хэш функция здесь не используется. Описанный выше алгоритм — это сильное упрощения реальной процедуры, за деталями этого любознательного читателя отправлю к той же книге Hardware Defined Networking.
Однако память — это память — всего лишь хранит. Сама она трафик не передаёт — кто-то с ней должен взаимодействовать.
Тот компонент, который занимается передачей пакетов, называется чипом коммутации — FE — Forwarding Engine. Именно он парсит заголовки, запрашивает информацию в TCAM и перенаправляет пакеты к выходному интерфейсу.
Работа с пакетом декомпозируется на множество мелких шагов, каждый из которых должен выполняться на скорости линии, и совокупное время отработки тракта должно быть адекватным требованиям сети.
Реализован FE может быть на Сетевых Процессорах (NP), FPGA и элементарных ASIC или их последовательности.
Вот с элементарных ASIC и начнём.
ASIC — Application Specific Integrated Circuit
Как следует из названия, это микросхема, решающая узкий спектр специфических задач. Алгоритм работы зашит в неё и не может быть изменён в дальнейшем.

Соответственно, на ASIC ложатся рутинные операции, которые никогда не поменяются со временем.
ASIC занимается: АЦП, подсчёт контрольной суммы кадра, восстановление синхросигнала из Ethernet, сбор статистики принятых и отправленных пакетов.
Например, мы наверняка знаем, где в кадре поле DMAC, его длину, как различить броадкастовые кадры, мультикастовые и юникастовые. Эти фундаментальные константы никогда не поменяются, поэтому функции, их использующие, могут быть алгоритмизированы аппаратно, а не программно.
Процесс разработки и отладки ASIC достаточно трудоёмок, поскольку в финальном чипе нет места ошибкам, зато когда он завершён, их можно отгружать камазами.
ASIC стоит дёшево, потому что производство простое, массовое, вероятность ошибки низкая, а рынок сбыта огромный.
Согласно документации Juniper, на части устройств их PFE (Packet Forwarding Engine) основан на последовательности ASIC’ов и не использует более сложных микросхем.
Programmable ASIC
В последние годы наблюдается тенденция к реализации большинства функций на ASIC. Однако хочется оставить возможность программировать поведение. Поэтому появились так называемые Программируемые ASIC, которые обладают низкой стоимостью, высокой производительность и некоторой грибкостью. 
FPGA — Field Programmable Gate Array
Не всё по силам ASIC’ам. Всё, что касается минимального интеллекта и возможности повлиять на поведение чипа — это к FPGA.
Это программируемая микросхема, в которую заливается прошивка, определяющая её роль в оборудовании.
Как и ASIC, FPGA изначально нацелен на решение какой-то задачи.
То есть FPGA для пакетной сети и для управления подачей топлива в инжектор двигателя — вещи разные и прошивкой одно в другое не превратишь.
Итак, имеем специализированный чип с возможностью управлять его поведением и модернизировать алгоритмы.
FPGA может использоваться для маршрутизации пакетов, перемаркировки, полисинга, зеркалирования.
Например, извне мы можем сообщить чипу, что нужно отлавливать все BGP и LDP пакеты, отправляемые на CPU, в .pcap файл.
- ситуация выше, где нужно заложить в него новое правило полисинга, зеркалирования, маркировки
- внедрения нового функционала
- активация лицензируемой опции
- модернизация существующих алгоритмов
- добавление нового правила для анализа полей заголовков, например, для обработки нового протокола.
Опять же, если обнаружена неисправность, то можно написать патч для ПО, который сможет её починить, и при этом обновить только конкретно данный чип, без влияния на всю остальную систему.
FPGA значительно дороже в разработке и производстве, главным образом из-за заранее заложенной гибкости.
NP — Network Processor
В оборудовании операторского класса, где требования как к пропускной способности, так и к протоколам, запущенным на устройстве, довольно высоки, часто используются специализированные чипы — сетевые процессоры — NP. В некотором смысле можно считать их мощными FPGA, направленными именно на обработку и передачу пакетов.

Крупные телеком-вендоры разрабатывают свои собственные процессоры (Cisco, Juniper, Huawei, Nokia), для производителей помельче существуют предложения от нескольких гигантов, вроде Marvell, Mellanox.
Вот например презентация нового NP-чипа Cisco 400Gb/s Full-duplex: тыц.
А это описание работы чипсета Juniper Trio, который однако позиционируется, как NISP (Network Instruction Set Processor), а не NP: тыц.
Немного маркетинга и суперэффектное видео о Nokia FP4: тыц
Задачи и возможности примерно те же, что и у FPGA. Дьявол кроется в деталях, куда мы уже не полезем.
5. Аппаратная архитектура коммутирующего устройства
Обычно всё-таки даже на недорогих коммутаторах не практикуют реализацию всего и вся на одном чипе. Это скорее, каскад из разных их типов, каждый из которых решает какую-то часть общей задачи.
Дальше мы посмотрим на референсную модель, как это «может» работать.
Для этой модели возьмём модульное шасси, состоящее из интерфейсных и управляющих модулей и фабрики коммутации.

Работать оно будет со стандартной связкой IP, Ethernet.
Общая шина
Общая шина (она же Back Plane, она же Midplane) устройства, связывающая друг с другом все модули.
Обычно, это просто батарея медных контактов без каких-либо микросхем.

Так выглядит задняя часть платы, которая вставляется в шину 